







阅读报告2: Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation
本论文pdf和代码参考链接:https://cshizhe.github.io/projects/vln_duet.html
一,引言
之前的方法缺点
1,HAMT[15]存储导航和视觉记忆,以捕捉动作预测中的长期依赖性,但仅限于局部动作空间。也就是说,即使存储了历史view也只能进行局部行动。
2,基于graph的方法使用拓扑图来支持全局动作空间,但存在重复的导航记忆和粗略的视觉(压缩的视觉特征)表示。
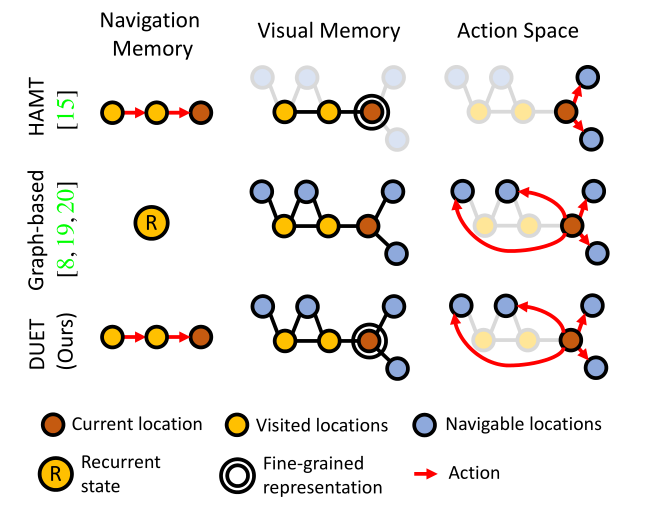
本文贡献
1,提出了结合拓扑图的graph transformer(DUET),它结合了当前位置的粗比例尺地图编码和精细比例尺编码,以有效规划全局行动。(实际上如何规划全局行动在于学习策略,不在于编码,粗细编码也是为全局决策做准备)
2,我们使用图变换器对拓扑图进行编码,并学习与指令的跨模态关系,以便动作预测可以依赖于远程导航记忆。
3,DUET在面向目标的VLN基准测试方面达到了最先进水平,在具有挑战性的REVERIE和SOON数据集上,成功率(SR)提高了20%以上。它也适用于细粒度VLN任务,即将R2R数据集的SR增加4%。
- 由于在奖励较少的任务中使用RL很困难,我们改为使用交互式演示来模拟专家并在连续培训中提供监督。模拟学习之行为克隆。
- 本文可以分类为对行动策略学习,而不是表征学习。注重于强调模型通过对全局的思考和并进行语言视觉的细粒度的表征学习,
- 之前的能够进行全局思考的方法视觉特征过于粗粒度(但细粒度会复杂),或者能够进行详细记忆存储的方法只能局部行动没有全局思考。本文方法对全局思考与细粒度表达的复杂性进行平衡
二,具体方法
2.1 节 对VLN任务及本节的拓扑图构建进行公式化定义,
2.2 节 本文主要创新点,用于总体行为预测的环境拓扑图的构建
2.3 节 整个双尺度的预训练VLN,包括文本编码,粗\细刻度交叉模式编码器,动态融合
2.4 节 训练与推理, 如何预训练,学习策略(行为克隆),推理(测试时)
2.1 Problem formulation
文中符号名词解释:
在离散环境的标准VLN设置中,环境是一个无向图 G = { V , E } \mathcal{G}=\{\mathcal{V},\mathcal{E} \} G={V,E} ,其中 V = { V i } i = 1 K \mathcal{V}=\{V_i \}^K_{i=1} V={Vi}i=1K 表示K个相邻的节点, E \mathcal{E} E
表示连接边。 W = { w i } i = 1 L \mathcal{W}=\{\mathcal{w}_i \}^L_{i=1} W={wi}i=1L 表示含有L个单词的指令的词嵌入。代理配备有RGB摄像机和GPS传感器,并在先前未看到的环境中的起始节点处进行初始化。代理的目标是解释自然语言指令,并将图形遍历到目标位置并找到指令指定的对象。在每个时间步 t t t,代理接收其当前节点 V t V_t Vt 的 全景视图 和 位置坐标。
每个全景图 R = { r i } i = 1 n \mathcal{R}=\{\mathcal{r}_i \}^n_{i=1} R={ri}i=1n 包含 n 张图片, 表示图片特征向量 r r r和独一无二的方向(具体来说每个位置节点有三个仰角和12旋转角度共36张图片)。
部分下游任务中,视觉语言导航需要细化识别场景中的某个物体,而不仅仅是导航到某个节点。因此每个全景图还包含m个目标物体特征 O = { o i } i = 1 m \mathcal{O}=\{\mathcal{o}_i \}^m_{i=1} O={oi}i=1m
V t V_t Vt 的相邻节点 N ( V t ) \mathcal{N}(V_t) N(Vt) 是全景图 R t \mathcal{R}_t Rt 的子集,因为有些图片没有节点(路)。 A t \mathcal{A}_t At表示 t t t 时的局部行为空间导航至 V t V_t Vt ∈ \in ∈ N ( V t ) \mathcal{N}(V_t) N(Vt) 并在 V t V_t Vt停止。
下图整体任务的流程图,总体来说,本文的主要创新点在于构建平衡复杂性的拓扑图进行全局的粗粒度预测(即 Topological Mapping和 Coarse-scale Cross-modal Encoder以及最后的动态融合)。
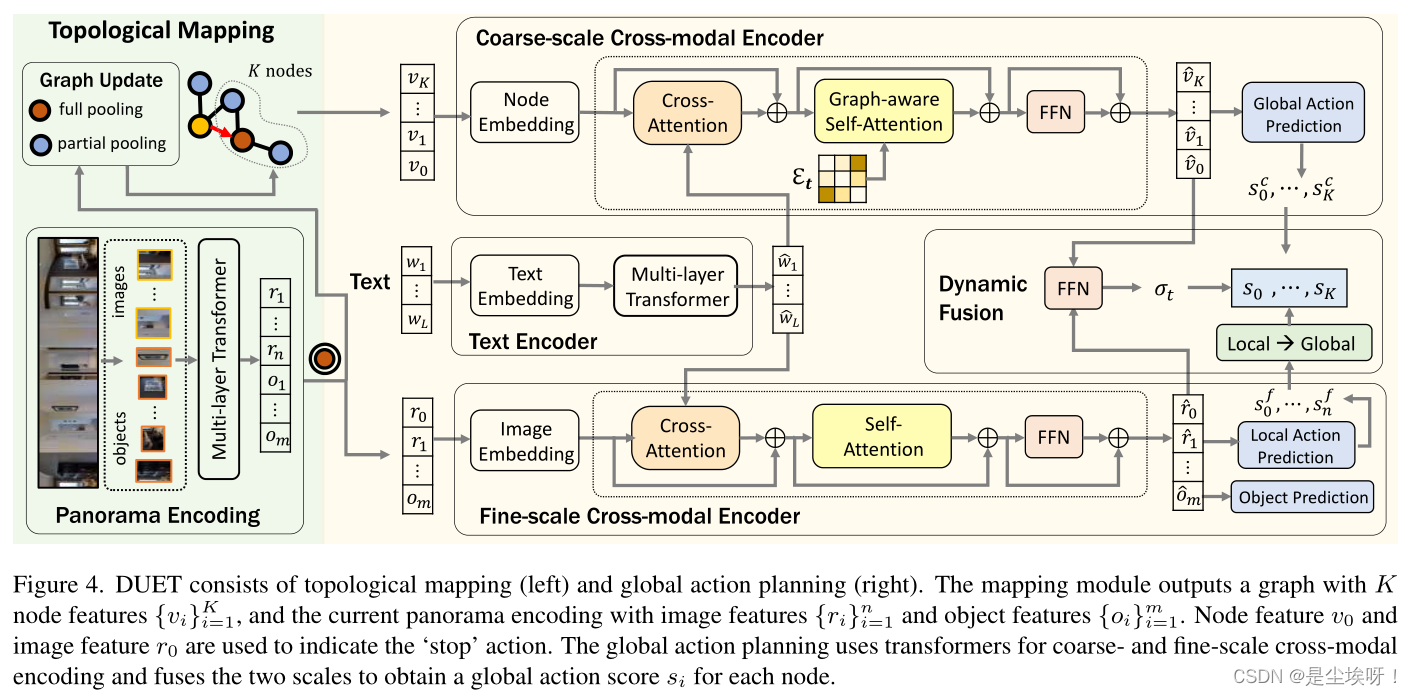
2.2 Topological Mapping
从零开始构建拓扑图,拓扑图构建完成后就包含了完整的历史信息.
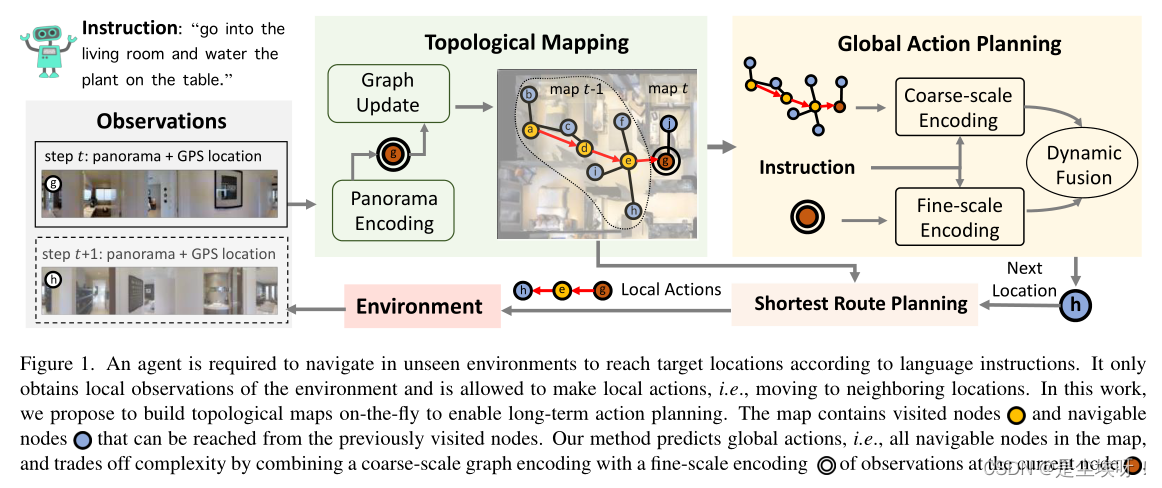

环境对于agent一开始是未知的,因此需要根据路径的观察构建环境图
G
\mathcal{G}
G,如上图所示黄色节点表示访问过的节点,
蓝
色
\blue{蓝色}
蓝色节点表示邻居节点,
红
色
\red{红色}
红色节点表示当前节点。在每个步骤t,我们将当前节点Vt及其相邻未访问节点N(Vt)添加到Vt−1,并更新Et−1。考虑到Vt处的新观察,我们还更新了当前节点和可导航节点的视觉表示
{
R
t
,
O
t
}
\{ \mathcal{R}_t, \mathcal{O}_t\}
{Rt,Ot}。在时间步t时,agent接受节点
V
t
V_t
Vt 的图像特征
R
t
\mathcal{R}_t
Rt 和对象特征
O
t
\mathcal{O}_t
Ot,使用多层transformer建模images
R
t
\mathcal{R}_t
Rt 和 objects
O
t
\mathcal{O}_t
Ot 之间的关系。
- 更新当前节点:通过平均池化 R t \mathcal{R}_t Rt 和 O t \mathcal{O}_t Ot
- 更新邻居节点:累积 R t \mathcal{R}_t Rt。如果邻居节点可以被从多个位置进行观察,则进行平均作为视觉表征。
这样的粗尺度表示能够在大型图上进行有效的推理,但可能无法为细粒度语言基础(尤其是对象)提供足够的信息。因此,我们将 R t , O t R_t,O_t Rt,Ot(没被池化的特征)作为当前节点Vt的细粒度视觉表表征(非本节),以支持细粒度的详细推理。
2.3 Global Action Planning
- 总体行为计划包括粗粒度的全局行为决策和细粒度的语言图像内容学习,以及最后的动态融合。
2.3.1 文本编码
略,上下文单词表示为 W ^ = { w ^ 1 ⋅ ⋅ ⋅ w ^ L } \hat{\mathcal{W}}=\{\hat{\mathcal{w}}_1 ··· \hat{\mathcal{w}}_L\} W^={w^1⋅⋅⋅w^L}
2.3.2 粗粒度跨模态编码
该模块是通过粗粒度的map
G
t
\mathcal{G}_t
Gt和指令
R
^
t
\hat{\mathcal{R}}_t
R^t,在全局行为空间上做出导航行为预测。
因此,这一部分需要弄明白:每个节点如何编码,如何基于图的transformer建模节点与指令之间的关系,最后进行全局行为预测。
Node embedding.
节点编码是将 位置编码 和 导航步编码 加入到节点视觉特征中
v
i
\mathcal{v}_i
vi:
- 位置编码:以自我为中心的视图嵌入map中节点的位置,相对于当前节点的方向和距离。
- 导航步编码:将访问过的节点嵌入最近访问过的节点中,0表示没有探索过的节点。
- 停止节点:表示一个停止动作,并连接其他所有节点。
Graph-aware cross-modal encoding
编码的节点与指令喂给多层graph-aware cross-modal transformer,每个transformer layer包含一个跨模态层来建模节点与指令之间的关系还一个编码环境布局的基于图的自注意层。
一般的视觉编码容易忽略了比远处节点更相关的附近节点,因此作者使用以下方式计算图注意力:

X
X
X 是节点表示,即
[
R
t
,
O
t
]
[\mathcal{R}_t, \mathcal{O}_t]
[Rt,Ot] ,
E
E
E是根据
E
t
\mathcal{E}_t
Et 构建的成对的距离矩阵。
Global action prediction
根据以下公式预测
/
m
a
t
h
c
a
l
G
t
/mathcal{G}_t
/mathcalGt的每个节点
V
i
V_i
Vi的导航分数。
s i c = F F N ( v ^ i ) s^c_i = FFN(\hat{v}_i) sic=FFN(v^i)
注意, s 0 c s^c_0 s0c表示stop scorce。 VLN一般不重复访问节点,所以一般都会mask访问过的节点分数。
2.3.3 细粒度跨模态编码
这一部分关注当前位置的节点 V t V_t Vt,该模块是通过细粒度的当前节点的视觉表示 { R t , O t } \{\mathcal{R}_t,\mathcal{O}_t \} {Rt,Ot} 和指令 W ^ t \hat{\mathcal{W}}_t W^t,在全局行为空间上做出导航行为预测 A t \mathcal{A}_t At。在最后一步识别object。
Visual Embedding
向
{
R
t
,
O
t
}
\{\mathcal{R}_t,\mathcal{O}_t \}
{Rt,Ot} 中加入两种位置嵌入,为停止行为添加停止标记
r
0
r_0
r0
- 相对于起始节点的当前位置,有助于理解绝对位置,
- 每个相邻节点与当前节点的相对位置, 有助于实现以自我为中心的方向,如右转
Fine-grained cross-modal reasoning
连接 { r 0 , R t , O t } \{r_0,\mathcal{R}_t,\mathcal{O}_t \} {r0,Rt,Ot}作为视觉标记,使用多层cross-modal transformer建模视觉和语言关系。输出标记为 r ^ 0 , R ^ t , O ^ t \hat{r}_0,\hat{\mathcal{R}}_t,\hat{\mathcal{O}}_t r^0,R^t,O^t
Local action prediction and object grounding
局部行为预测与全局导航预测类似,部分VLN任务是基于
O
t
\mathcal{O}_t
Ot用一个FFN获得object分数.
2.3.4 动态融合
- 粗粒度的编码预测与细粒度预测行为编码不匹配,因此转换局部行为分数 s i f ∈ s t o p , N ( V t ) s_i^f \in {stop,\mathcal{N}(V_t)} sif∈stop,N(Vt)加入全局action分数。为了导航到未与当前节点连接的其他未探索节点,代理需要通过其相邻访问节点进行回溯。因此,我们将 N ( V t ) \mathcal{N}(V_t) N(Vt) 中访问过的节点的得分相加,作为总体回溯得分。
局部行为预测分数转化为

在每一步,我们将粗尺度编码器的 v ^ 0 \hat{v}_0 v^0和细尺度编码器的 r ^ 0 \hat{r}_0 r^0连接起来,以预测融合的标量

最后的导航分数:

2.4 Training and Inference
2.4.1 预训练
我们首先基于离线专家演示和行为克隆以及其他常见的视觉和语言代理任务对模型进行预训练
行为克隆中,single-step action prediction (SAP) [15] and object grounding (OG)损失如下:

其中,
a
t
∗
a^*_t
at∗是部分演示路径
P
<
t
∗
\mathcal{P}^*_{<t}
P<t∗ 的专家action,
o
∗
o^*
o∗最新位置
P
T
\mathcal{P}_T
PT 的 groundtruth object。
这一部分还不是很明白需要查看补充材料和代码
2.4.2 通过互动演示器的策略学习
行为克隆受到训练和测试之间分布变化的影响。因此,我们建议在伪交互式演示器(PID)π的监督下进一步训练。在训练期间,我们可以访问环境图G,因此π∗ 可以利用G来选择下一个目标节点,即从当前节点到最终目的地的总距离最短的可导航节点。在每次迭代中,我们使用当前策略对轨迹P进行采样,并使用π∗ 为了获得伪监督

我们使用平衡因子λ将原始专家演示与政策学习中的伪演示结合起来
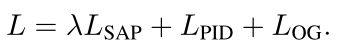
2.4.3 推理
在测试期间的每个时间步骤,我们更新第3.1节中介绍的拓扑图,然后预测第3.2节中解释的全局动作。如果是导航动作,则最短路线规划模块使用Floyd算法获得从当前节点到给定地图的预测节点的最短路径,否则代理将在当前位置停止。如果超过最大操作步骤,代理将被迫停止。在这种情况下,它将返回到具有最大停止概率的节点作为其最终预测。在停止位置,代理选择具有最大对象预测得分的对象。
Floyd算法
适用于有向、无向加权图,求解最短路径
三,实验结果
3.1 实验设置
数据集
- REVERIE,包含目标位置和对象的指令,指令平均长度21个单词。专家路径的长度为4到7步。给定为每个全景提供的预定义对象边界框,代理应在导航路径的末端选择正确的对象边界框
- SOON,提供包含目标房间和对象的指令,专家路径的平均长度为9.5步。SOON不提供对象框,并要求代理预测全景中的对象中心位置。因此,我们使用自动对象检测器[46]来获得候选对象框。
- R2R,一个广泛使用的VLN基准,不需要进行对象定位。step-by-step导航指令,平均长度32个词,专家路径的平均长度为6步
评价指标
评价指标可以简单分为 三类:导航距离(越小越好),导航成功率和执行远程命令(识别objects)的成功率(都是越大越好)
-
轨迹长度(TL):平均路径长度,单位为米;
-
导航误差(NE):代理的最终位置与目标之间的平均距离(米)
-
成功率(SR):与NE的路径比率小于3米
-
Oracle SR(OSR):给定Oracle停止策略的SR;
-
(SPL)是SR由路径长度惩罚:SPL越大表明成功率越大,路径越少。能够衡量总体性能。
-
远程grounded成功率(RGS):成功执行指令的比例
-
(RGSPL) RGS penalized by Path Length
实验细节
- 图像特征:对于图像,我们采用在ImageNet上预训练的ViT-B/16[50]来提取特征。对于对象,我们在REVERIE数据集中使用相同的ViT,因为它提供了边界框,而在SOON数据集中使用BUTD对象检测器。方位特征[11]包含航向和仰角的sin(·)和cos(·)值
- 模型架构:我们分别在文本编码器、全景编码器、粗尺度交叉模式编码器和精细尺度交叉模式编码中使用9、2、4和4个变换器层。其他超参数的设置与LXMERT[47]中的相同,例如,隐藏层大小为768。我们使用预训练的LXMERT进行初始化
- 训练细节:在REVERIE数据集上,我们首先使用2个Nvidia Tesla P100 GPU,对DUET进行预处理,批大小为32,迭代次数为100k。我们自动生成合成指令来扩充数据集[10]。然后,我们使用等式(12)对单个特斯拉P100上的20k次迭代的批大小为8的策略进行微调。SPL在val seen split上选择最佳的epoch。补充材料中提供了更多细节
3.2 消融实验
3.2.1 粗粒度vs细粒度编码

细粒度视觉表示对于确定指令中指定的目标位置至关重要,精细编码器的OSR得分较低,这表明由于动作空间有限,它缺乏探索性。粗比例尺编码器反而受益于构建的地图,并且能够有效地探索具有高OSR和SPL度量的更多区域
3.2.2 双尺度融合策略
由于细尺度编码器和粗尺度编码器是互补的,我们在表1的底部比较了融合两个编码器的不同方法。这两种融合方法在很大程度上都优于细尺度和粗尺度编码。与平均融合相比,我们提出的动态融合实现了更有效的探索,SPL提高了1.79%。
3.2.3 基于图的自注意
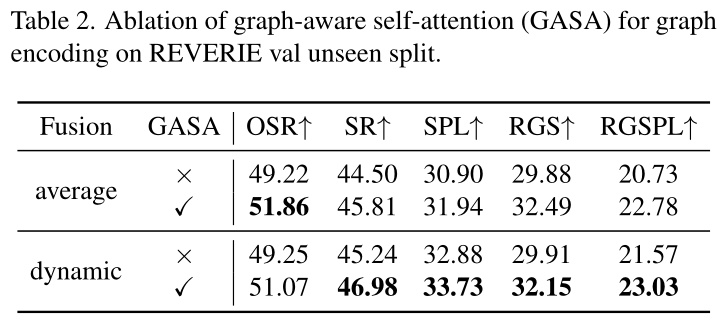
表2消融方程(3)中变压器中编码有或没有图形拓扑GASA的模型。结果表明,对图形结构的认知更有利于提高SPL分。
3.2.4 训练损失

在表3中,我们比较了DUET的不同训练损失。第一行仅在行为克隆中使用LSAP。由于它没有针对对象基础进行训练,我们可以忽略RGS和RGSPL度量。第二行增加了培训中的对象监督。它还提高了导航性能,这表明额外的跨模态监控(如单词和对象之间的关联)可能有利于VLN任务。在第三行中,我们在训练中添加了常见的辅助代理任务MLM和MRC,这对对象基础更有帮助。
由于REVERIE中的说明主要描述了最终目标,这两个损失与物体接地更为相关。
我们进一步使用强化学习(RL)[14,15]或最后两行中的PID对模型进行微调,以解决行为克隆中的分布移位问题。RL和PID都实现了显著的改进,PID优于RL
3.2.5 使用合成指令进行数据扩充。

这一步怎么做的参考补充材料
我们评估用合成指令补充训练数据的贡献。表4的上部方框显示了有或无增强数据的预训练结果。我们可以看到,合成数据在预训练阶段是有益的,SPL和RGSPL分别提高了1.63%和1.76%。基于第2行中模型的初始化,我们使用PID来进一步改进策略。
然而,合成数据并不能改善性能。
我们假设预训练中的辅助代理任务有助于从有噪声的合成数据中获益,但策略学习仍然需要更干净的数据。
3.3 Comparison with SOTAs
总体来说,本文在多项指标上大幅度领先其他之前的方法,导航长度却增加了(个人认为这个是可以改进的)
3.3.1 REVERIE,
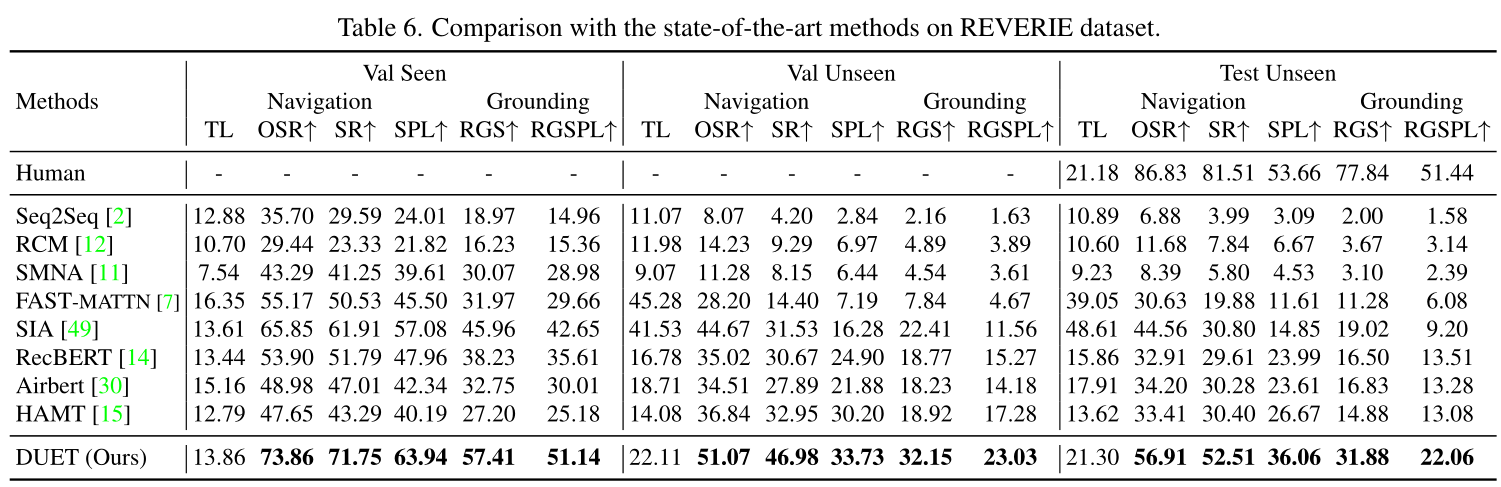
表6将我们的最终模型与REVERIE数据集上的最先进模型进行了比较。我们的模型在三个分割的所有评估指标上都明显优于最先进的水平。例如,在val seen split中,我们的模型在SR、SPL和RGSPL上分别比之前的最佳模型HAMT[15]表现出14.03%、3.53%和5.75%的优势。我们的模型也能更好地概括测试未发现的分裂,其中我们在SR上比HAMT提高了22.11%,在SPL上提高了9.39%,在RGSPL上改进了8.98%。这清楚地证明了我们使用拓扑图的双尺度行动规划模型的有效性。请注意,以前的方法都没有使用graph map来导航此数据集。
3.3.2 SOON

我们的模型也取得了明显优于先前基于图的方法GBE[8]的性能,在测试未发现的分割上,SR和SPL分别提高了20.54%和12.19%。然而,结果远低于REVERIE的结果
3.3.3 R2R

如表7所示,DUET的成功率(SR)分别比最先进的方法高6%和4%。然而,它在SPL上实现了相当的性能。这可以通过以下事实来解释:对于基于地图的方法,鼓励回溯,这使得轨迹长度更长。我们进一步将粗尺度DUET与之前不使用精细尺度编码器的基于图的方法[8,19,20]进行比较,以便进行公平比较。即使没有使用精细尺度表示,DUET仍然比它们表现出一定的优势,这表明了我们的图形变换器的有效性。这也证明了DUET能够更有效地回溯
示例

四,总结与思考
我们提出了基于在线构造拓扑图的视觉和语言导航(VLN)的双尺度图变换器(DUET)。它使用图形变换器对长期行动计划的粗比例尺地图表示和细粒度语言基础的细比例尺局部表示进行推理。这两个尺度在导航策略中动态组合。DUET在VLN基准REVERIE、SOON和R2R上实现了最先进的性能。然而,我们的方法并不总是成功的,正如可见和不可见环境之间的差距所表明的那样,并且仅限于离散环境。今后的工作将解决这些问题。我们工作的应用应考虑到安全和隐私风险。
本文是笔者第一篇详读的方法型VLN论文,所以注重理解,没有太多的想法。但有些愚见:
- 内容复杂,感觉就是各种模态用transformer训练,这当然有效也值得借鉴,但是不具体的。不清楚到底那一部分起作用,位置,图像,指令,缺乏解释感觉应该有更有效的方式或策略。总体来说就是各种融合,对任务本身不具有针对性训练。
- 还有就是作者在Conclusion说明了目前的VLN任务具有一些固有的缺点。
- 按理说,本文的构建的环境 G \mathcal{G} G 可以更新节点后得到更短的导航路径。
五,补充材料
说实话,只看上面的内容可以知道这篇文章做了什么,还需要参考代码和以下内容理解怎么做的。(简要介绍)
A. Model Details
Pretraining Objectives
如第3.3节所述,除了行为克隆任务SAP(单步动作预测)和OG(对象基础)外,我们还使用了两个辅助代理任务进行预训练。在下面,我们描述了两个辅助任务:屏蔽语言建模(MLM)和屏蔽区域分类(MRC)。两个任务的输入是指令
W
\mathcal{W}
W和演示路径
P
\mathcal{P}
P.
Speaker Model for Data Augmentation
我们训练一个说话者模型,根据REVERIE数据集的视觉观察合成指令。由于REVERIE提供带注释的对象类,Matterport3D也包含带注释的房间类,我们利用这些语义标签来缓解视觉和语言之间的差距。我们的说话人模型由全景编码器和句子解码器组成。全景编码器被馈送全景的图像特征、目标对象和目标房间的语义标签以及房间的级别。我们将所有输入特征投影到同一个维度中,并使用一个具有自我关注的变换器来捕捉每个令牌的关系。然后,句子解码器顺序地生成对编码标记进行调节的单词。我们使用LSTM作为解码器,并遵循show-atten-tell图像字幕模型中的架构
请注意,我们只使用REVERIE培训分割中的数据来学习说话人模型。我们使用预训练的GloV e嵌入来初始化编码器和解码器中的单词嵌入[54],并训练50个时期的说话人模型。
我们使用经过训练的说话人模型为REVERIE训练分割中的每个注释对象合成指令,总共得到19636条指令。我们将训练集的大小从10466对指令路径扩展到30102对
B. Experimental Setups
Dataset
Data Processing for SOON Dataset
SOON数据集不为每个全景提供带注释的对象边界框。它只注释每个指令的目标对象边界框的位置,包括对象中心点的方向以及左上角、右上角、左下角和右下角的方向。SOON数据集中的对象接地设置是预测对象中心点的方向。
然而,我们观察到,虽然注释对象的中心点质量良好,但它们对四个角的注释却相当嘈杂2。因此,我们建议在训练中清理对象边界框,并提供更自动检测到的对象作为细粒度视觉上下文来表示每个全景。
具体来说,我们使用在VisualGenome上预训练的BUTD检测器[46]来检测每个全景图中的对象,它涵盖1600个对象和场景类。我们为SOON数据集过滤一些不重要的类,如“背景”、“地板”、“天花板”、“墙壁”、“屋顶”等。然后,根据对象类的语义相似性和对象中心点与注释目标对象的欧几里德距离,选择其中一个检测到的对象作为伪目标。通过这种方式,我们将SOON数据集中的对象基础设置转换为类似于REVERIE数据集中的设置,其目标是从所有候选对象中选择一个对象。在推断中,我们利用所选对象的方向作为我们的对象基础预测
Evaluation Metrics**
B.4. Training Details
C. Additional Ablations
C.1. Balance factor λ in fine-tuning objective

C.2. Backtrack ratio in inference
回溯动作指示代理不从本地动作空间中选择相邻节点,而是通过全局动作空间跳到先前部分观察到的节点。我们计算DUET的回溯比。在REVERIE val看到的分裂中,DUET仅在13.7%的预测轨迹中回溯;而在REVERIE val seen split上,DUET的回溯率为其预测轨迹48.6%。
由于智能体具有记忆所见环境中房屋结构的能力,因此它可以直接找到目标位置,而无需在所见环境进行太多探索。但是,当代理部署在看不见的环境中时,它必须进行更多的探索,以找到高级指令指定的目标位置。当在R2R数据集中给出分步指令时,我们观察到,在val未发现的拆分上,回溯比率显著降低至23.2%,这与我们的预期相符。
C.3. Fusion weights of coarse and fine scales
我们观察到,代理通常在导航的开始和结束时将更多权重放在细尺度模块上,而在中间的粗尺度模块在中间。从数量上讲,粗尺度模块的平均权重在开始时为0.36,中间为0.45,最后为0.42。代理可能不需要在早期阶段回溯,因此它更多地依赖于本地精细规模模块
然后,代理需要进行探索,因此全局粗尺度模块得到更多关注。在决定停止位置时,代理应识别目标对象,并再次强调精细缩放模块
C.4. Failure analysis
我们对REVERIE数据集进行了额外的定量评估。对于导航,我们测量代理是在目标房间类型(例如浴室)还是在正确的位置停止。我们得到以下结果:(a)房间类型不正确:29.82%;(b) 正确的房间类型+错误的位置:23.20%;(c) 正确定位:46.98%。这表明,细粒度场景理解仍然具有挑战性。关于对象接地,一旦代理到达正确位置,68.43%的时间可以正确定位对象
D. Qualitative Examples

图6展示了我们在REVERIE数据集上的DUET和最先进的HAMT[15]模型的一些示例。在这两种情况下,特工在第一次尝试时都会探索错误的方向。然而,DUET能够有效地探索通往目标的另一个方向。图7显示了R2R数据集的一些示例。尽管提供了分步说明,但说明仍然可能不明确。例如,图7顶部示例中起点的两个方向都可以“离开大厅”。当DUET发现后续指令与视觉观察不匹配时,它也更善于纠正之前的决定。
我们在图8中进一步提供了REVERIE和R2R数据集中的一些故障案例。在图8的顶部示例中,房子中有几个浴室,我们的DUET模型到达了其中一个浴室。但是,到达的浴室不包含指令中指定的细粒度对象。这表明我们的模型仍然需要改进细粒度的对象基础能力。下面的示例给出了R2R数据集上相同轨迹的三个不同指令。代理成功地遵循了第一条指令,但其他两条指令失败。我们观察到,在不同的语言指令中,预测并不十分可靠。

















 2194
2194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









