







论文信息
题目:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
作者:Chelsea Finn(伯克利大学),Pieter Abbeel ,Sergey Levine
年份:19
论文地址:论文地址
代码:maml-pytorch
基础补充
小样本学习(Few Shot Learing)概念
- N-way N-shot。N-way 的意思是N分类,N-shot是在学习的样本中,每个类只提供5个样本,比如说让你学习辨认一只猫,只有5张猫的照片供你学习。
内容
摘要
提出一种 meta-learning 算法,该算法是模型无关的,适用于任何利用梯度下降的方法来训练的模型,并且适用于任何任务,包括:classification,regression,and reinforcement learning. meta-learning ,目标是在不同的任务上训练一个模型,使得该模型可以仅仅利用少量的数据,就可以解决新的任务。在提出的方法中,该模型的参数,是显示的进行训练的,使得新任务中使用少量的梯度步和少量的训练数据就可以产生良好的泛化性能 效果上来说,我们的方法得到的模型更加容易进行微调。该论文表明这种方法可以在两个 few-shot image classification benchmarks 得到极好的效果,并且加速了策略梯度强化学习算法。
动机
动机:
- 快速的进行学习是最近机器学习领域的一个研究热点问题
- 人类可以根据已有的先验知识,就可以根据少量新的信息,快速的掌握一项新的技能
- 但是这种快速且灵活的学习任务对于机器来说,确是非常困难的
- 能不能是机器从少量样本中学习,然后应用于不同的新任务时也能表现出很好的能力
创新:(key idea)
- 该论文提出的方法是训练模型的初始参数,使模型在参数更新后对新任务具有最大的性能。用在来自新任务的少量数据进行,计算通过一个或多个梯度步骤,就能满足要求;
- 与前人的工作不同,他们通常基于 learn an update function or learning rule, 本论文的方法不会增加所需要学习参数的数量,也不会限制模型的框架,可以很容易与各种全连接,全卷积,或者循环神经网络。也可以与各种损失函数结合,如:可微分的监督损失函数,或者不可导的强化学习目标函数。
核心算法
从一个动态系统的角度,本论文的学习过程可以看做是:使新任务相对于参数的损失函数的灵敏度最大化:,当敏感度高的时候,对参数进行较小的局部改变可以带来任务损失上大的改善。找到某参数使得在多个任务上loss都发生较大改变,即找到灵敏性强的参数
算法1:
分为两步,
-
第一步是:在 T i \mathcal{T}_{i} Ti上训练得到 θ i \theta_{i} θi
θ i ′ = θ − α ∇ θ L T i ( f θ ) \theta_{i}^{\prime}=\theta-\alpha \nabla_{\theta} \mathcal{L}_{\mathcal{T}_{i}}\left(f_{\theta}\right) θi′=θ−α∇θLTi(fθ) -
第二步是:
θ ← θ − β ∇ θ ∑ T i ∼ p ( T ) L T i ( f θ i ′ ) \theta \leftarrow \theta-\beta \nabla_{\theta} \sum_{\mathcal{T}_{i} \sim p(\mathcal{T})} \mathcal{L}_{\mathcal{T}_{i}}\left(f_{\theta_{i}^{\prime}}\right) θ←θ−β∇θTi∼p(T)∑LTi(fθi′)
the meta-optimization 是通过 model parameters θ \theta θ 来实现的,其中,模型被用新的模型参数 θ ′ \theta' θ′ 进行计算。实际上,我们提出的模型,目标是优化模型的参数,使得 one or a small number of gradient steps on a new task will produce maximally effective behavior on that task.
其中, α , β α,β α,β分别是task中的进行梯度下降的学习率、和meta-learning过程的学习率, θ θ θ 是模型(神经网络的参数) f f f的权重参数。

算法2:



在一个task中,使用左边的训练集做5次SGD的过程,再使用右边的测试集计算test error,在meta-learning过程中,把一个batch的4个task的test error平均一下作为loss再去进行优化。这个过程结束后,神经网络的权重到达了下图中的P点

我们再使用这个模型或者测试这个模型的准确度怎么用呢?我们说把100类图片分成了3个子集被划分成了train(64)、test(20)、val(16)三个子集。train中有64个类,用于上述的meta-learning。现在要将这个模型用在新的任务集具有16个类的test数据集上。仔细一想,训练好的模型并没有看见过test数据集中任何类啊。现在就是要说title中的Fast Adaptation的关键字了,在5-way 5-shot设定中,在测试的时候从test数据集中随机抽取5个类,每个类抽取N(>5)张照片,其中每个类抽取5张照片,用来微调模型中的参数,比如说在一个新任务下,把模型的参数调整至 θ 3 ∗ \theta_{3}^{∗} θ3∗的位置,就是task做的事,即在新任务下只用5张照片来学习一下,用剩下的照片来计算精度
实验
实验1:
在使用MAML的方法,与直接使用使用数据进行预训练对比
- 可以看出使用了maml方法在k为5都能得到比较好的效果
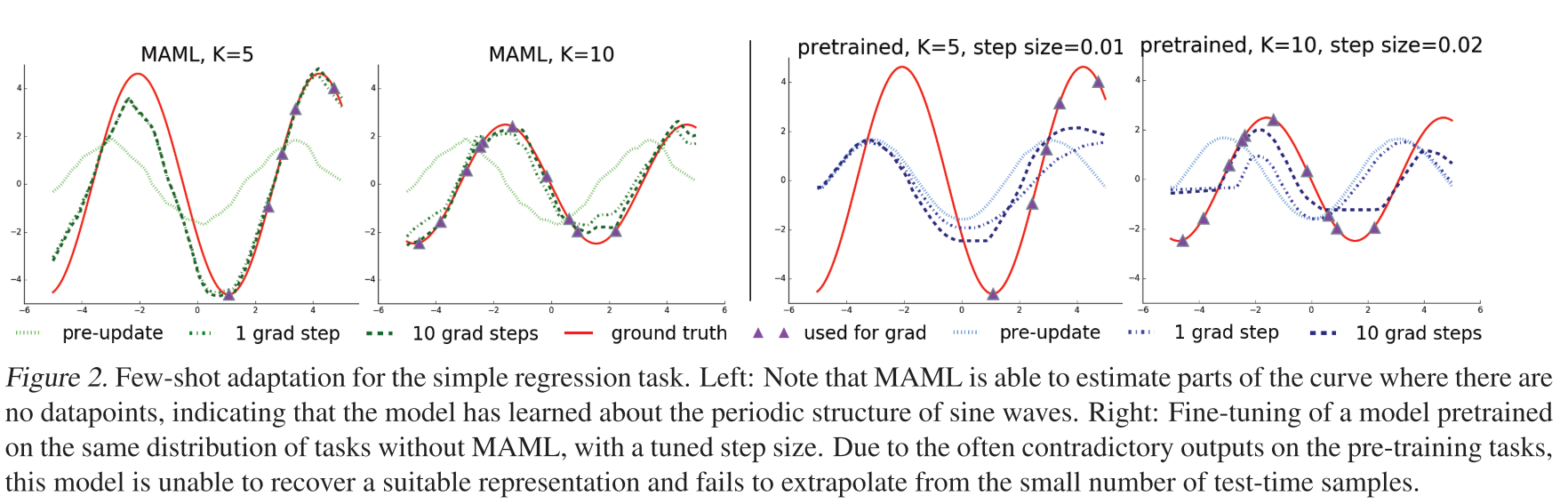
实验2:

结论
Model-Agnostic(与模型无关的)是说,可以把task换成其他可以进行SGD过程的模型;Deep Networks(深度网络)可以适用于所有的深度学习模型。提出的MAML能在不同的任务上训练一个模型,使得该模型可以仅仅利用少量的数据,就可以解决新的任务。
可借鉴地方
- 算法很经典有效,可以用于PINN等网络预训练作为初始化参数,将会加速训练收敛
参考
小样本学习论文















 990
990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











