






softmax和分类模型
softmax的基本概念
分类问题
一个简单的图像分类问题,输入图像的高和宽均为2像素,色彩为灰度。
图像中的4像素分别记为 x1,x2,x3,x4 。
假设真实标签为狗、猫或者鸡,这些标签对应的离散值为 y1,y2,y3 。
我们通常使用离散的数值来表示类别,例如 y1=1,y2=2,y3=3 。
权重矢量
o1=x1w11+x2w21+x3w31+x4w41+b1
o2=x1w12+x2w22+x3w32+x4w42+b2
o3=x1w13+x2w23+x3w33+x4w43+b3
神经网络图
下图用神经网络图描绘了上面的计算。softmax回归同线性回归一样,也是一个单层神经网络。由于每个输出 o1,o2,o3 的计算都要依赖于所有的输入 x1,x2,x3,x4 ,softmax回归的输出层也是一个全连接层。
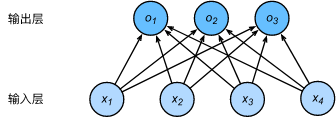
softmax回归是一个单层神经网络
既然分类问题需要得到离散的预测输出,一个简单的办法是将输出值 oi 当作预测类别是 i 的置信度,并将值最大的输出所对应的类作为预测输出,即输出 argmaxioi 。例如,如果 o1,o2,o3 分别为 0.1,10,0.1 ,由于 o2 最大,那么预测类别为2,其代表猫。
输出问题
直接使用输出层的输出有两个问题:
一方面,由于输出层的输出值的范围不确定,我们难以直观上判断这些值的意义。例如,刚才举的例子中的输出值10表示“很置信”图像类别为猫,因为该输出值是其他两类的输出值的100倍。但如果 o1=o3=103 ,那么输出值10却又表示图像类别为猫的概率很低。
另一方面,由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。
softmax运算符(softmax operator)解决了以上两个问题。它通过下式将输出值变换成值为正且和为1的概率分布:
y1,y2,y^3=softmax(o1,o2,o3)
其中
y1=exp(o1)∑3i=1exp(oi),y2=exp(o2)∑3i=1exp(oi),y^3=exp(o3)∑3i=1exp(oi).
容易看出 y1+y2+y^3=1 且 0≤y1,y2,y^3≤1 ,因此 y1,y2,y^3 是一个合法的概率分布。这时候,如果 y^2=0.8 ,不管 y^1 和 y^3 的值是多少,我们都知道图像类别为猫的概率是80%。此外,我们注意到
argmaxioi=argmaxiy^i
因此softmax运算不改变预测类别输出。
计算效率
单样本矢量计算表达式
为了提高计算效率,我们可以将单样本分类通过矢量计算来表达。在上面的图像分类问题中,假设softmax回归的权重和偏差参数分别为
W=⎡⎣⎢⎢⎢w11w21w31w41w12w22w32w42w13w23w33w43⎤⎦⎥⎥⎥,b=[b1b2b3],
设高和宽分别为2个像素的图像样本 i 的特征为
x(i)=[x(i)1x(i)2x(i)3x(i)4],
输出层的输出为
o(i)=[o(i)1o(i)2o(i)3],
预测为狗、猫或鸡的概率分布为
y(i)=[y(i)1y(i)2y(i)3].
softmax回归对样本 i 分类的矢量计算表达式为
o(i)y^(i)=x(i)W+b,=softmax(o(i)).
小批量矢量计算表达式
为了进一步提升计算效率,我们通常对小批量数据做矢量计算。广义上讲,给定一个小批量样本,其批量大小为 n ,输入个数(特征数)为 d ,输出个数(类别数)为 q 。设批量特征为 X∈Rn×d 。假设softmax回归的权重和偏差参数分别为 W∈Rd×q 和 b∈R1×q 。softmax回归的矢量计算表达式为
OY^=XW+b,=softmax(O),
其中的加法运算使用了广播机制, O,Y^∈Rn×q 且这两个矩阵的第 i 行分别为样本 i 的输出 o(i) 和概率分布 y^(i) 。
交叉熵损失函数
对于样本 i ,我们构造向量 y(i)∈Rq ,使其第 y(i) (样本 i 类别的离散数值)个元素为1,其余为0。这样我们的训练目标可以设为使预测概率分布 y^(i) 尽可能接近真实的标签概率分布 y(i) 。
平方损失估计
Loss=|y^(i)−y(i)|2/2
然而,想要预测分类结果正确,我们其实并不需要预测概率完全等于标签概率。例如,在图像分类的例子里,如果 y(i)=3 ,那么我们只需要 y^(i)3 比其他两个预测值 y^(i)1 和 y^(i)2 大就行了。即使 y^(i)3 值为0.6,不管其他两个预测值为多少,类别预测均正确。而平方损失则过于严格,例如 y(i)1=y(i)2=0.2 比 y(i)1=0,y(i)2=0.4 的损失要小很多,虽然两者都有同样正确的分类预测结果。
改善上述问题的一个方法是使用更适合衡量两个概率分布差异的测量函数。其中,交叉熵(cross entropy)是一个常用的衡量方法:
H(y(i),y(i))=−∑j=1qy(i)jlogy(i)j,
其中带下标的 y(i)j 是向量 y(i) 中非0即1的元素,需要注意将它与样本 i 类别的离散数值,即不带下标的 y(i) 区分。在上式中,我们知道向量 y(i) 中只有第 y(i) 个元素 y(i)y(i) 为1,其余全为0,于是 H(y(i),y(i))=−logyy(i)(i) 。也就是说,交叉熵只关心对正确类别的预测概率,因为只要其值足够大,就可以确保分类结果正确。当然,遇到一个样本有多个标签时,例如图像里含有不止一个物体时,我们并不能做这一步简化。但即便对于这种情况,交叉熵同样只关心对图像中出现的物体类别的预测概率。
假设训练数据集的样本数为 n ,交叉熵损失函数定义为
ℓ(Θ)=1n∑i=1nH(y(i),y^(i)),
其中 Θ 代表模型参数。同样地,如果每个样本只有一个标签,那么交叉熵损失可以简写成 ℓ(Θ)=−(1/n)∑ni=1logy^(i)y(i) 。从另一个角度来看,我们知道最小化 ℓ(Θ) 等价于最大化 exp(−nℓ(Θ))=∏ni=1y^(i)y(i) ,即最小化交叉熵损失函数等价于最大化训练数据集所有标签类别的联合预测概率。
模型训练和预测
在训练好softmax回归模型后,给定任一样本特征,就可以预测每个输出类别的概率。通常,我们把预测概率最大的类别作为输出类别。如果它与真实类别(标签)一致,说明这次预测是正确的。在3.6节的实验中,我们将使用准确率(accuracy)来评价模型的表现。它等于正确预测数量与总预测数量之比。















 1537
1537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









