








TMI2022 Domain Adaptation Meets Zero-Shot Learning: An Annotation-Efficient Approach to Multi-Modality Medical Image Segmentation
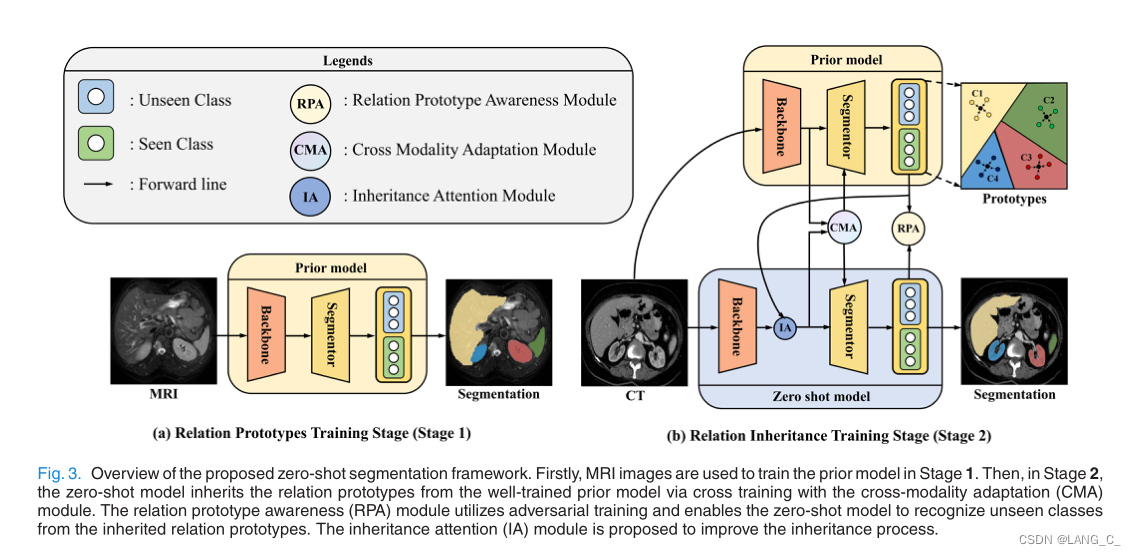
1. Overview of the proposed zero-shot segmentation framework
摘要
由于缺乏正确注释的医学数据,探索深度模型的泛化能力成为公众关注的问题。近年来出现的零样本学习(Zero-shot learning, ZSL)使深度模型具备了识别不可见类的能力。但现有的研究主要集中在自然图像上,利用语言模型提取辅助信息用于ZSL。将自然图像ZSL解决方案直接应用于医学图像是不现实的,因为医学术语具有很强的领域特异性,并且不容易获得医学术语的语言模型。在这项工作中,我们提出了一个新的范式的ZSL专门用于医学图像利用交叉模态信息。我们对所提出的范式做出了三个主要贡献。首先,我们从先验模型中提取分割目标的先验知识,称为关系原型,然后提出一个跨模态自适应模块来继承原型到零射击模型。其次,我们提出了关系原型感知模块,使零射击模型能够感知原型中包含的信息。最后,我们开发了一个继承注意模块来重新校准关系原型,以增强继承过程。在两个公共跨模式数据集(包括心脏数据集和腹部数据集)上评估所提出的框架。大量的实验表明,提出的框架明显优于目前的SOTA。
一、主要亮点
- 第一次将零样本学习应用在域适应领域,利用在一个域中学习到的先验知识,以一种新的方式提高另一个域中不可见类的分割性能,这是第一项利用跨模态图像先验作为辅助信息的研究,以弥补医学术语语言模型的缺失;
- 与SOTA UDA方法相比,我们的框架不需要任何数据,只需要一个训练有素的源模式模型,从而消除了源数据的隐私问题(像cyclegan是需要两个域的数据,就需要把图片暴露出来,无法消除隐私性);
- 我们提出了一种新的交叉模态适应(CMA)模块来校准公共投影语义空间,使关系原型从训练良好的先验模型继承到零样本模型,就是学习跨模态知识;
- 为了解决跨模态零样本分割中的灾难性遗忘问题——零样本模型在用一种新的模态训练见类时遗忘未见类,提出了一种关系原型感知(RPA)模块来增强其对未见类的记忆;
- 为了更好地继承不可见类,我们设计了一个继承注意(IA)模块来重新校准由零镜头模型提取的特征,一个注意力模块;
二、网络结构
1. Overview of the proposed zero-shot segmentation framework
2. RPA


只将
看做正样本,其余为负样本来训练判别器,将。
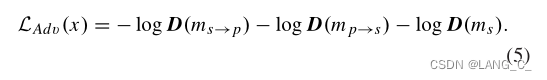
3. IA

4. Cross-Modality Adaptation

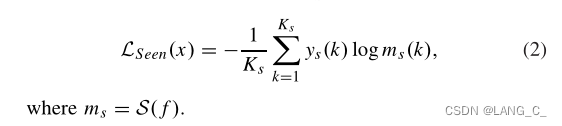
三、实验部分
1.
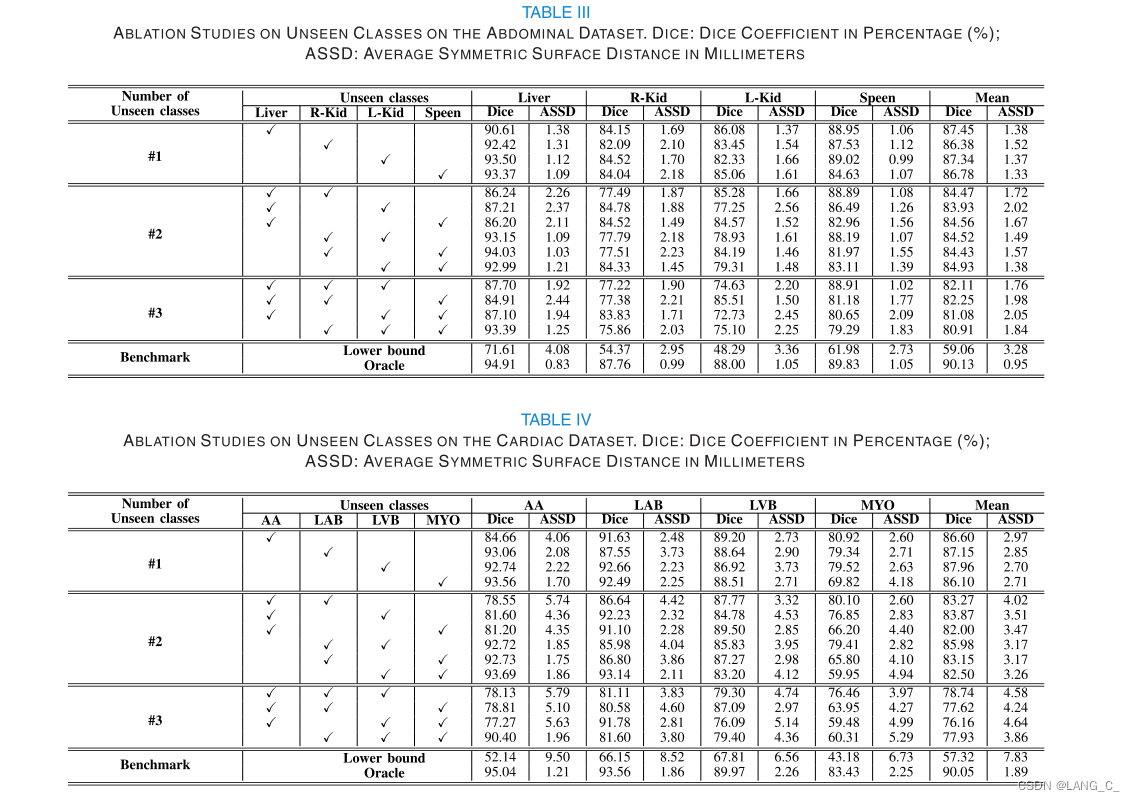
2.
3.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









