







Constructing Stronger and Faster Baselines for Skeleton-based Action Recognition
Abstract
针对该任务的复杂性和计算代价过高的情况,提出了一种新的有效的图卷积网络基线模型EfficientGCN,并设计了一种复合缩放策略,用于扩展模型的宽度和深度,最终获得一个高准确性、可训练参数较少的高效GCN基线模型。
1.INTRODUCTION
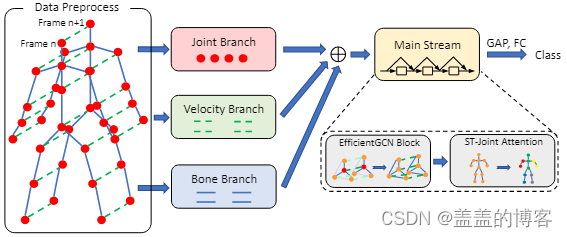
图1 整体框架
首先,本文构建了一个早期融合的多输入分支(MIB)架构,从骨架序列中关节的空间配置和时间动态中捕获丰富的特征。MIB 旨在减少多流 GCN 模型的模型参数和计算成本,以实现更有效的基于骨架的动作识别。
具体来说,在整个网络的早期阶段融合了关节位置(相对和绝对)、运动速度(一个或两个时间步长)和骨骼特征(长度和角度)三个输入分支,而不是在大多数多流GCN模型中传统后期融合。最优融合阶段是通过穷举搜索选择的。
其次,除了 ST-GCN中提出的基本层之外,还在 CNN 中扩展了四种卷积层,即瓶颈层 (BottleLayer) 、可分离层 (SepLayer)、扩展可分离层 (EpSepLayer) 和沙漏层 (SGLayer) 到 GCN 网络,用于提取时间动态并压缩模型大小。这四个层可以明显减少训练中参数调整成本的数量,并在测试中加速模型推理。
第三,为了确定每个块的结构超参数,采用了复合缩放方法。修改了原始缩放策略以适应图数据,通过删除分辨率缩放因子并重新构建宽度和深度因子之间的约束。这种策略以有效的方式提高了模型的性能。
最后,提出了关节注意(ST-JointAtt),并将其插入到模型的每个块中。该注意力模块旨在从整个骨架序列中找到最基本的关节,最终增强了模型提取判别特征的能力。与其他注意力模块(如 STC-attention (STCAtt) 和 Part-wise Attention (PartAtt) )相比,这个新模块共同处理空间和时间注意力,而 STCAtt 是异步的,PartAtt 忽略了时间差异。此外,与之前的 PartAtt 模块相比ST-JointAtt 模块无需手动划分骨架图中的部分,从而消除了在每个部分关节上设计适当的池化规则的需要。
2.RELATED WORK
2.1Efficient Models
模型效率通常由可训练参数的数量和每秒浮点运算 (FLOPs) 表示。
MobileNet 的模型家族主要通过可分离卷积切割模型大小,它将标准卷积分解为单独应用于每个通道的深度卷积和 1×1 逐点卷积来组合深度卷积的输出。为了进一步确定神经网络中的结构超参数,提出了复合缩放来构建effecentnet模型。
3.PRELIMINARY TECHNIQUES
3.1 Data Preprocessing
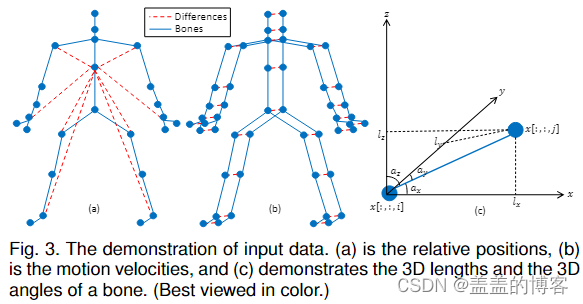
图 3 显示了三个输入的计算图。
3.2 Separable Convolution
可分离卷积将标准卷积分解为深度卷积和逐点卷积。具体来说,对于深度卷积,卷积滤波器只应用于一个对应的通道,而逐点卷积使用 1×1 卷积层来组合深度卷积的输出并调整输出通道的数量。标准卷积和可分离卷积的比较如图4所示。
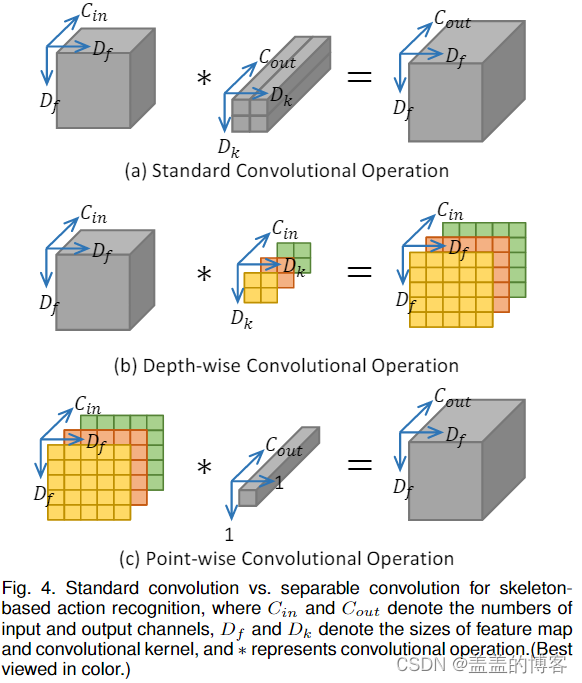
具体来说,假设输入特征大小为Df ×Df,核大小为Dk × Dk,输入和输出通道数为Cin和Cout,则标准卷积的计算过程如图4的第一行所示。这带来了一批可训练参数,编号为Dk × Dk × Cin × Cout × Df × Df。对于图4底部两行所示的可分离卷积,计算成本改为dk × Dk × Cin × Df × Df + Cin × Cout × Df × Df。请注意,大多数可训练参数都包含在逐点卷积中,这是通过1 × 1 卷积实现的。因此,如果输入和输出通道的数量足够大,例如 > 256,那么与标准卷积相比,可分离计算的计算成本将降低近 Dk × Dk 倍。
4 EFFICIENTGCN
4.1 Model Architecture
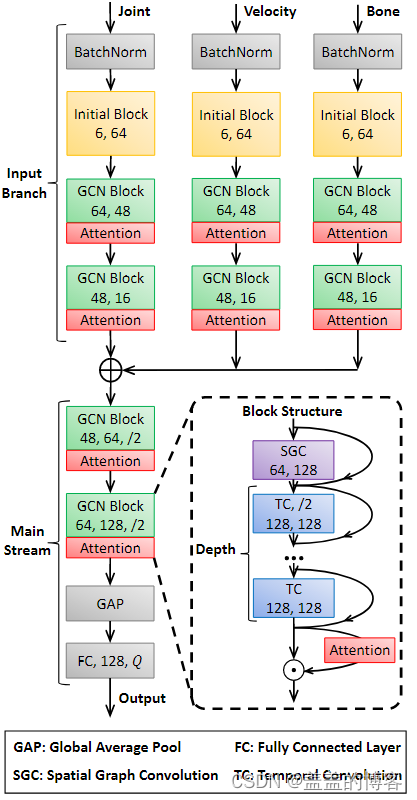
图5 EfficientGCN 模型的框架
为了进一步降低模型的复杂性,根据瓶颈结构和可分离卷积设计了四个TC层。
4.2 Block Details
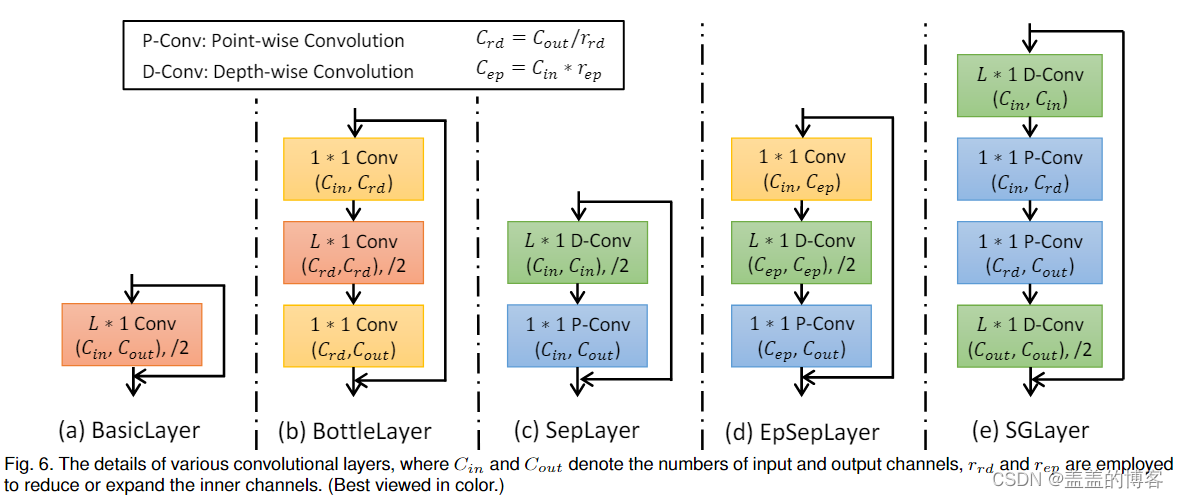
图6 各种卷积层的详细信息
4.3 Scaling Strategy
扩大网络的宽度和深度有利于提高性能。通常,模型的宽度和深度被定义为通道数和层数。这两个因素通常独立考虑,并由手工调整确定。
平衡网络的所有维度是至关重要的,例如宽度/深度/分辨率,本文在此基础上提出了一种复合缩放策略,以一组固定的缩放系数缩放网络宽度、深度和分辨率。获得的 EfficientNets 明显优于其他卷积网络,但模型大小要小得多。受此启发,在去除分辨率因子后,本文提出了一种新的基于骨架的动作识别缩放策略,通过该策略以原则性的方式构建一系列模型:

其中 mw 和 md 是宽度和深度乘数,φ 是表示模型缩放可用资源的复合系数,α 和 β 都是用于控制资源分配给模型宽度和深度的超参数。在本文中,α 和 β 通过小型网格搜索设置为 1.2 和 1.35(参见第 5.4 节)。由于预定义的骨架结构,省略了分辨率因子。骨架分辨率的修改会破坏图卷积操作。
4.4 Spatial Temporal Joint Attention
提出了一种新的注意模块,称为时空关节注意(ST-JointAtt),将某些帧中的信息量最大的关节与整个骨架序列进行区分。
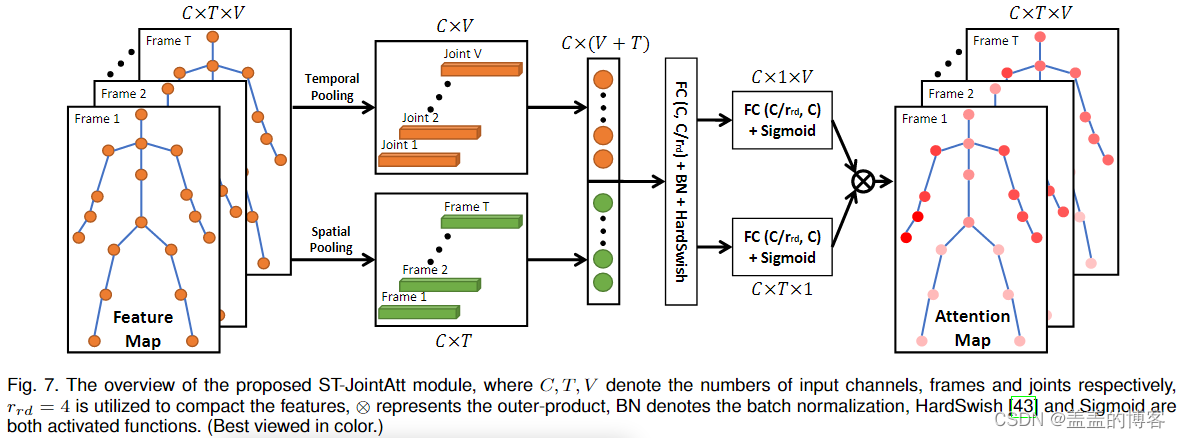
所提出的 ST-JointAtt 模块的概述如图 7 所示,其中输入特征首先在帧和关节级别平均。然后,将这些池化的特征向量连接在一起并通过 FC 层馈送到紧凑信息。接下来,利用两个独立的 FC 层来获得帧维度和联合维度的两组注意力分数。最后,帧和关节的分数乘以通道外积,结果可以看作是整个动作序列的注意力分数。所提出的 ST-JointAtt 模块可以表述为:
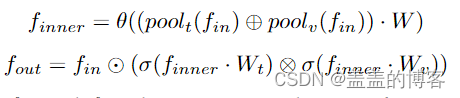
4.5 Discussion
首先,在 TC 层中使用可分离卷积会给模型带来高效率,EfficientGCN 显着降低了模型参数和 FLOP。需要注意的是,可分离引起的参数约简卷积可能并不总是会损害模型性能,因为可分离卷积已被证明可以捕获标准卷积最有效的部分,同时丢弃其他冗余部分。
EfficientGCN取得的高精度,主要归功于复合缩放策略和ST-JointAtt模块,前者基于cnn的视觉识别的经验经验,仔细平衡网络深度、宽度和分辨率可以带来更好的性能,后者通过使GCN关注动作序列中这些信息关节和帧,进一步增强了时空关节特征的学习。
5 EXPERIMENTAL RESULTS
5.1 Ablation Studies
5.1.1 Comparisons of TC Layers

其中 rrd 和 rep 表示相应层中减少和扩展通道的比率。如表中所示,虽然EpSepLayer (rep = 4)获得了最高的平均精度(90.1%),但rrd = 2的SGLayer在性能和计算成本之间实现了最优权衡,因此选择 rrd = 2 的 SGLayer 来构建基线模型。
5.1.2 Comparisons of Attention Modules
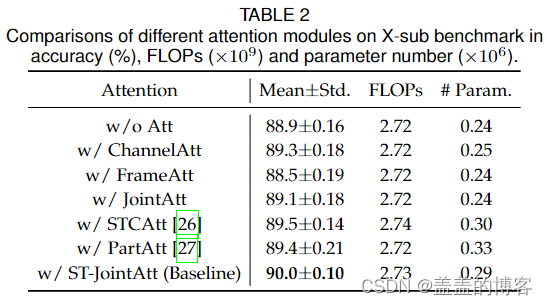
这表明插入注意力模块的重要性以及 ST-JointAtt 模块在整个骨架序列中找到信息量最大的关节和帧的有效性。
5.1.3 Necessity of Data Preprocessing

随着分支的增加,模型性能得到了提高。
5.1.4 Necessity of Early Fused Architecture
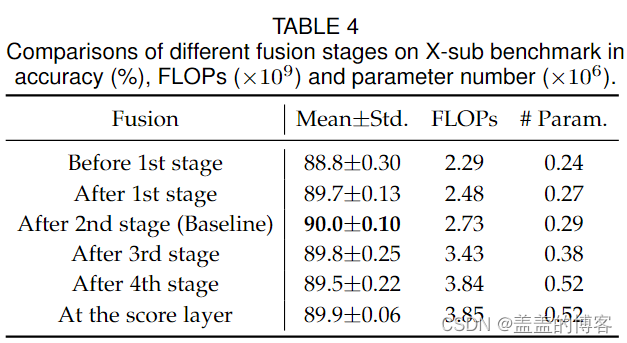
在第二阶段之后的融合是精度参数曲线的拐点,这是平衡精度和复杂性的最佳模型。
5.2 Comparisons of Compound Scaling Strategies

当 α = 1.2 和 β = 1.35 时,EfficientGCN-B4 获得了最好的性能。另外,仅仅增加宽度或深度可能会损害模型性能,其使用 EfficientGCN-B4 的准确度明显低于复合缩放策略的准确度。
5.3 Comparisons with SOTA Methods

结果表明 EfficientGCN 是一个具有竞争性能的强大基线。复合缩放策略在平衡模型精度和复杂性方面具有优越性,可以构建更广泛和更深的模型,并获得更好的性能。此外,所提出的 STJointAtt 模块有助于模型的准确性,这使得模型容易发现信息量最大的关节。
6 CONCLUSION
EfficientGCN在早期阶段融合了三个输入分支,明显消除了冗余参数。
为了进一步降低模型的复杂性,根据瓶颈结构和可分离卷积设计了四个TC层,显著节省计算成本。
利用复合缩放策略对模型宽度和深度进行统一缩放,进一步降低了模型的复杂性。















 1097
1097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









