






【生物信息学学习】第二天:蛋白质数据库
本文内容均来自山东大学生物信息学课程
一级蛋白质数据库
蛋白质序列数据库
swissprot
swissprot是一个人工注释的蛋白质序列数据库,具有注释可信度高,冗余度小的优点。由欧洲生物信息学研究所与瑞士生物信息学研究所共同管理。
TrEMBL
TrEMBL:蛋白质序列数据库是计算机完成的,包括蛋白质编码的所有翻译产物,可惜可信度低且冗余度大。
PIR
蛋白质信息资源数据库(PIR)设立在美国乔治城大学医学中心,是一个支持基因组学,蛋白质组学和系统生物学研究的综合公共生物信息学资源。
UniProt
UniProt数据库: http://www.uniprot.org/
UniProt具有三个层次数据库:
1、UniParc:收录所有UniProt数据库子库中的蛋白质序列,量大,粗糙。
2、UniRef:归纳UniProt几个主要数据库并将重复序列剔除后的数据库。
3、 UniProtKB:有详细注释并与其他数据库有链接的数据库,分为UniProtKb/Swiss-Prot和UniProtKB/TrEMbL。其中我们最常用的是Swiss-Prot数据库。
昨天我们一直通过dUTPase进行学习,我们今天继续使用dUTPase来进行检索
在检索框内输入human dUTPase,出现以下界面:

我们可以从中发现很多条蛋白质序列,从名字中可以看到,第一条应该是我们需要的检索结果。
通过左侧黄色加星图标,我们可以了解到该序列是否被人工检查过
点击进入,我们可以得知该蛋白质的详细信息。
Swiss-Prot相关注释解读
Function:提供与蛋白质功能相关的信息

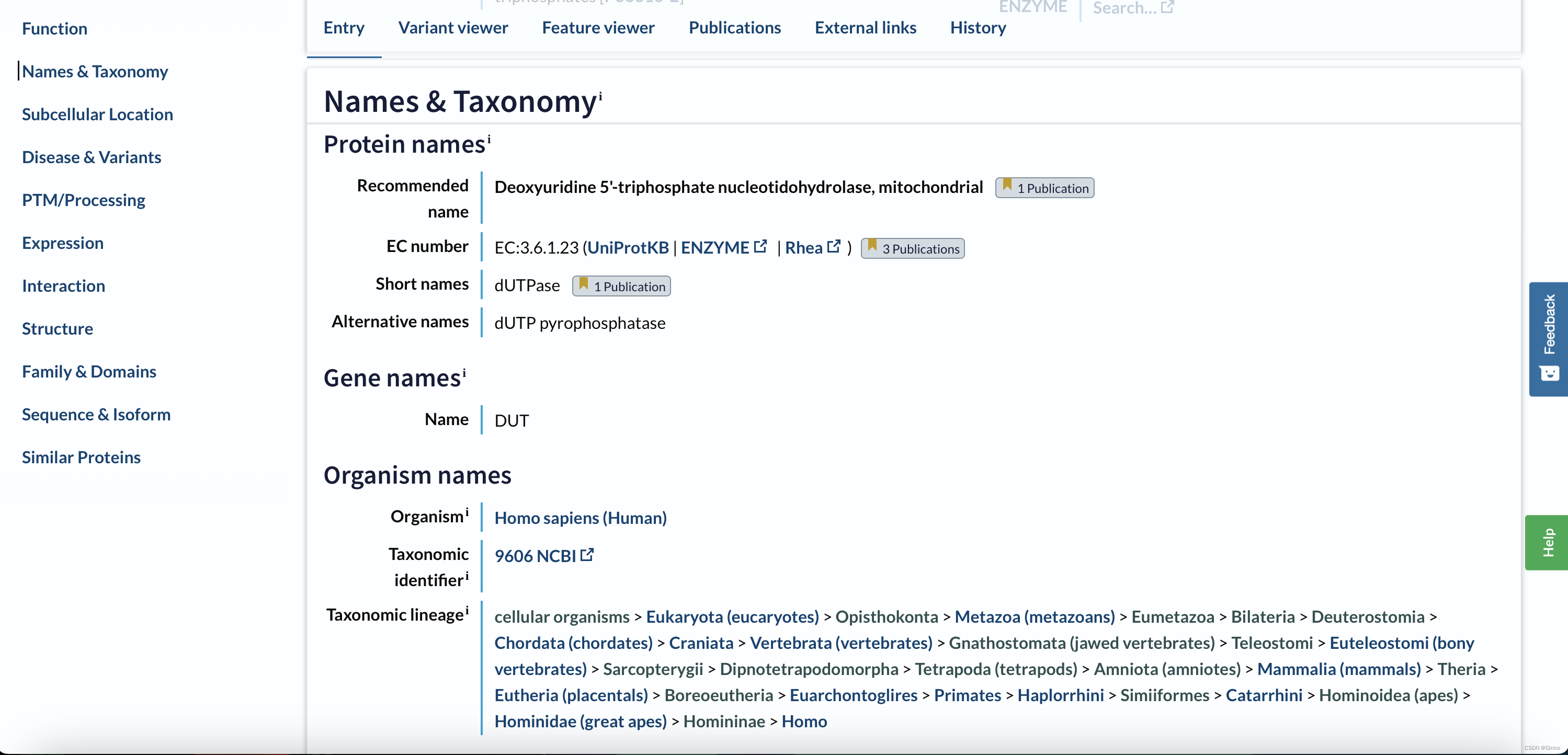
Names & Taxonomy:蛋白质的名字,所属物种的分类学信息等基本信息
Subcellular Location:提供蛋白质亚细胞定位的信息(重要)
亚细胞定位:蛋白质在细胞内不同组分中的定位,对蛋白质的生理功能有着直接的影响。
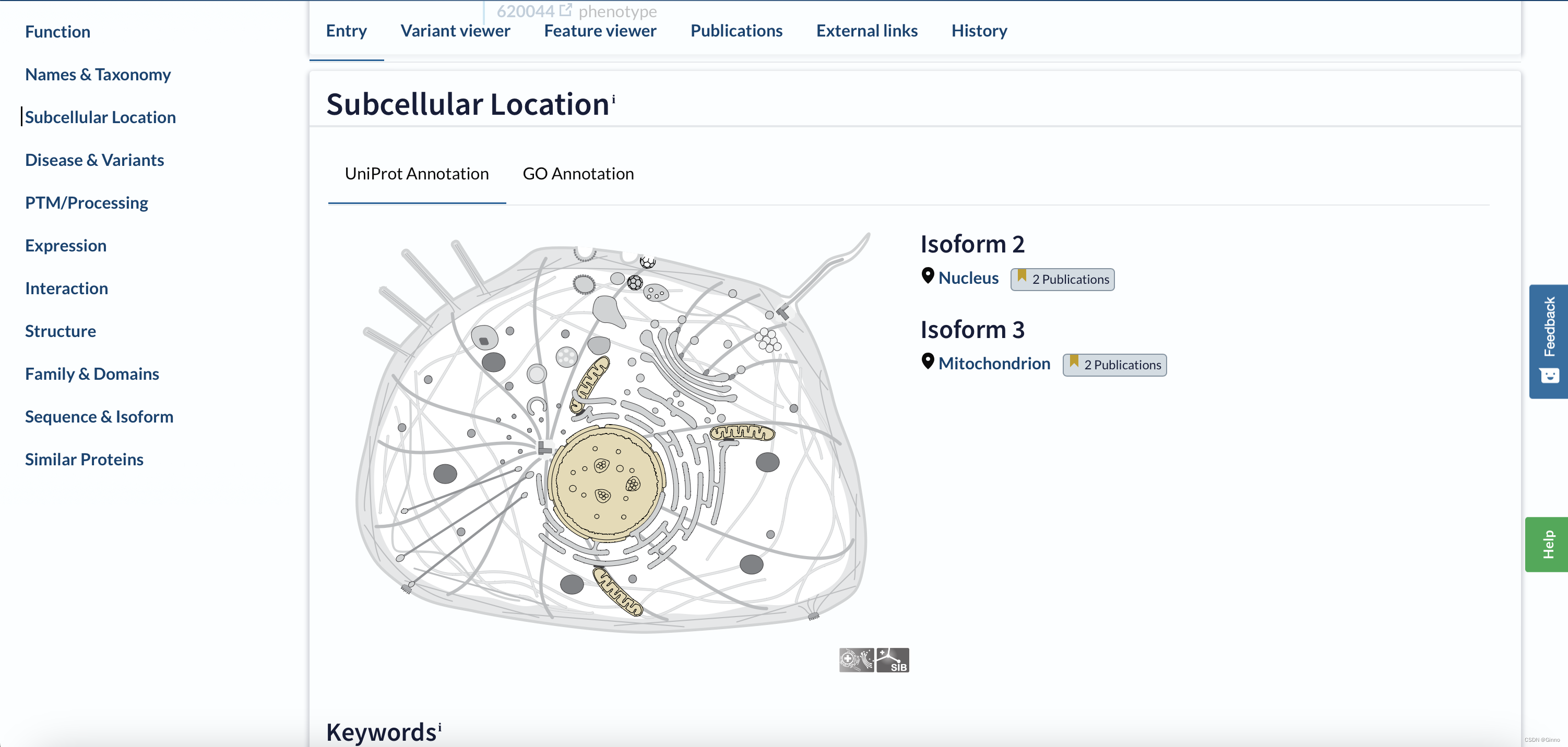
成熟的蛋白质需要在特定的细胞部位才能发挥其生物学功能。
目前研究亚细胞定位的数据来源基本都来源于Swiss-Prot数据库。
通过昨天的学习,我们了解了dUT基因具有两种剪切方式,其中一种会保留前端端一段信号肽。信号肽将蛋白质定位于线粒体,而没有信号肽的蛋白质则留在了细胞核。
mRNA join(<282..561,1034..1172,2395..2486,3113..3157,
4447..4521,4673..4743,5180..>5236)
/gene="DUT"
/product="dUTPase"
/note="alternatively spliced; encodes mitochondrial form
of the protein"
mRNA join(<1018..1172,2395..2486,3113..3157,4447..4521,
4673..4743,5180..>5236)
/gene="DUT"
/product="dUTPase"
/note="alternatively spliced; encodes nuclear form of the
protein"
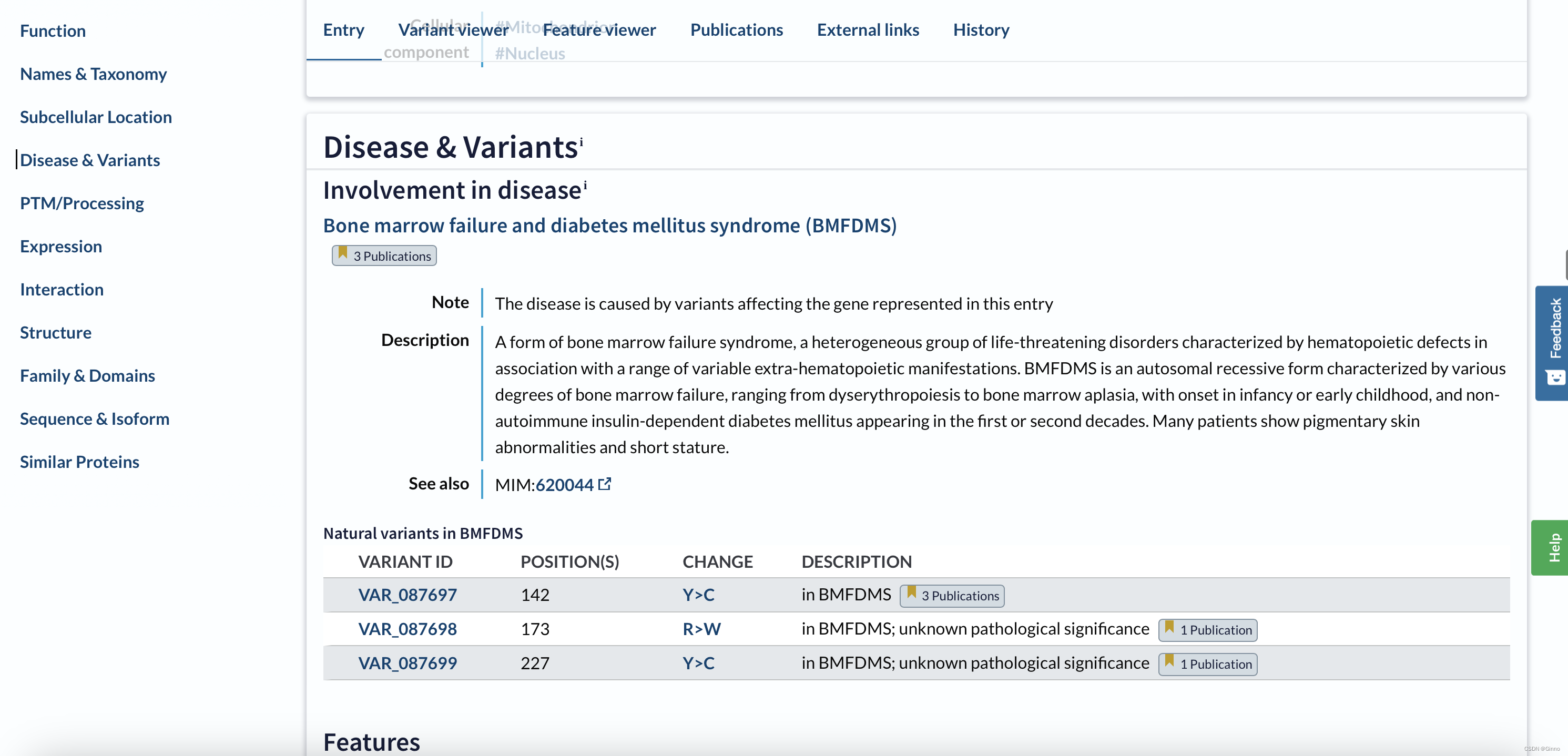
Disease & Variants:提供蛋白质突变或缺失导致的疾病及表型信息
PTM/Processing:提供蛋白质翻译后修饰或翻译后加工的相关信息
Expression:提供了基因在mRNA水平上的表达信息,或者在细胞中蛋白质水平上的表达信息,或者在不同器官组织中的表达信息。
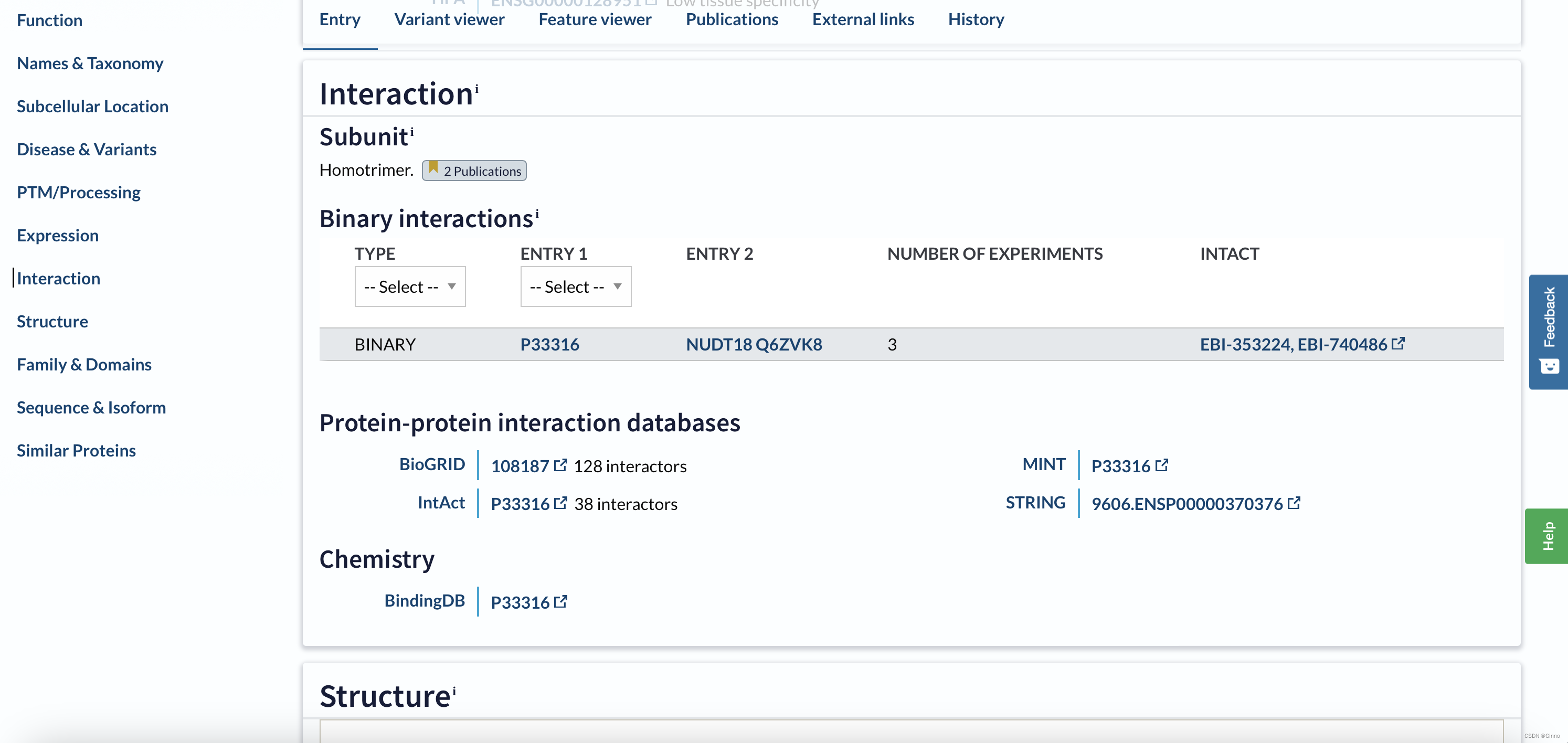
Interaction:提供了蛋白质之间相互作用的信息
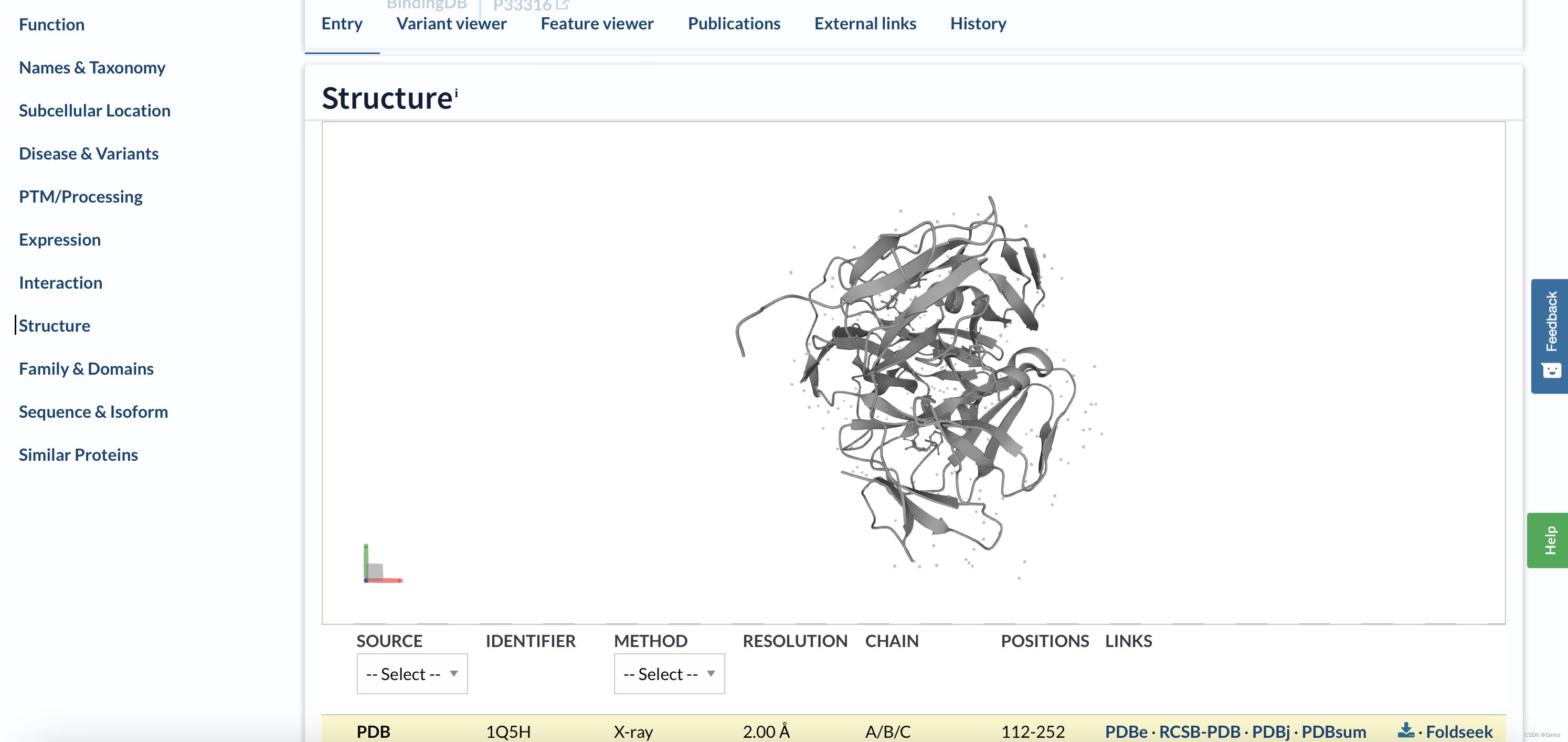
Structure:提供蛋白质二级结构和三级结构的信息
Family & Domains:提供蛋白质家族及结构域信息
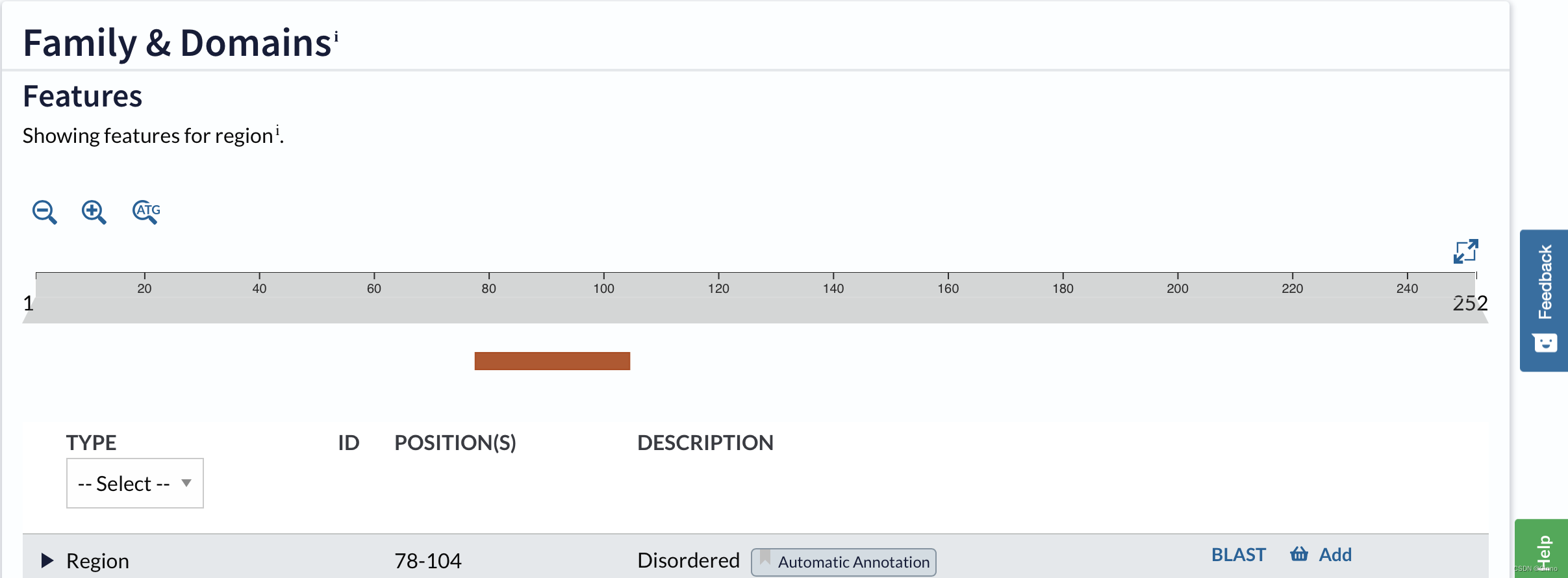
Sequence:提供蛋白质氨基酸序列信息。多个isoform(亚型)会显示多条序列。
蛋白质结构数据库(PDB)(未完善)
蛋白质结构可以分为四级:
1、一级结构:氨基酸序列
2、二级结构:周期性的结构现象
3、三级结构:整条多肽链的三位空间结构
4、四级结构:几个蛋白质分子(亚基)形成的复合体
蛋白质结构数据库(PDB)是全世界唯一存储生物大分子3D结构的数据库。这些生物大分子除了蛋白质以外还包括核酸及两者的复合物。只有通过试验方法获得的3D结构才会被收入其中。
PDB数据库: http://www.rcsb.org/















 1800
1800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









