







最近有小伙伴和我留言想学python爬虫,那么就搞起来吧。

准备阶段
爬虫有什么用呢?举个最简单的小例子,你需要《战狼2》的所有豆瓣影评。最先想的做法可能是打开浏览器,进入该网站,找到评论,一个一个复制到文本中,保存,翻页,接着复制,直到翻到最后一页。而爬虫只要写脚本,执行,泡杯咖啡,坐等他执行完。
首先需要在电脑上装好 python3 和 pip 。此外还需要知道python的一些基本语法。这些内容网上搜索有许多教程(例如廖雪峰),这边就不再细说了。
我们这次需要使用的是 正则表达式 re 库和第三方的 requests 库,以下是安装方法。
pip3 install requests
引入库。
import requests
import re
爬虫可以简单的分为获取数据,分析数据,存储数据三个步骤。
下载数据
简单来说一个网页是由一个html文件解析构成,我们需要获取这个文本内容。
每个浏览器都可以通过开发者工具获取到文本内容,以chrome为例,打开网页后,右键->检查。
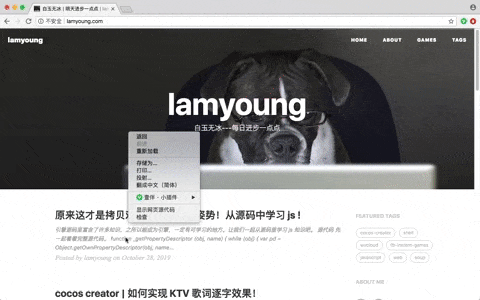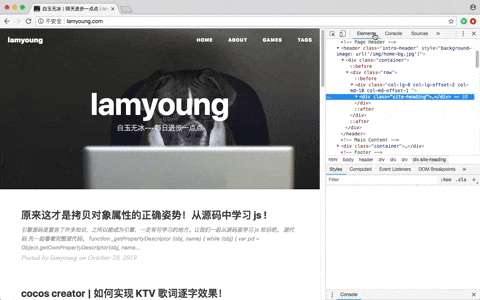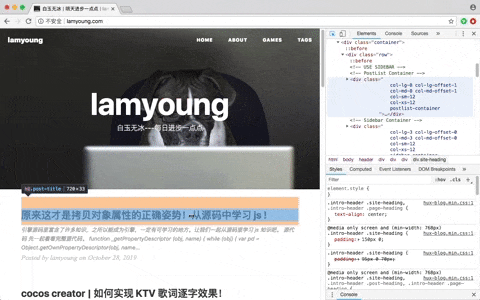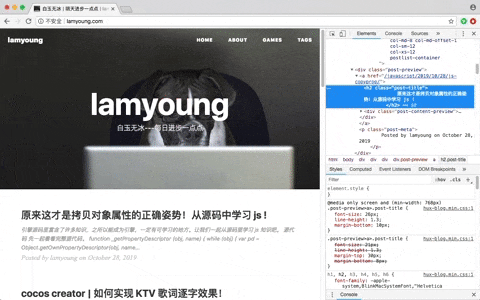
右边的 Elements 就是我们要下载的数据。
让我们看看 requests 是如何获取这个数据的。
url='http://lamyoung.com/';
html=requests.get(url);
if 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









