



系列文章目录
使用现代 Hopfield 网络对时间序列进行共形预测 NeurIPS 2023
文章目录
摘要
为了量化不确定性,共形预测方法越来越受到人们的关注,并已成功应用于各个领域。 然而,它们很难应用于时间序列,因为时间序列的自相关结构违反了共形预测所需的基本假设。 我们提出了 HopCPT,一种新颖的时间序列保形预测方法,它不仅可以处理时间结构,而且可以利用它们。 我们表明,我们的方法在理论上对于存在时间依赖性的时间序列是合理的。 在实验中,我们证明我们的新方法在来自四个不同领域的多个真实世界时间序列数据集上优于最先进的保形预测方法。https://github.com/ml-jku/HopCPT
提示:以下是本篇文章正文内容
一、引言
不确定性估计对于对复杂的瞬态系统进行可行的预测至关重要(例如,Gneiting & Katzfuss,2014;Zhu & Laptev,2017)。 这对于洪水预报等环境现象尤其明显(例如,Krzysztofowicz,2001),因为它们表现出明显的季节性。 保形预测(CP、Vovk 等人,1999)提供基于预测区间的不确定性估计。 它实现了有限样本边际覆盖,几乎没有任何假设,除了数据是可交换的(Vovk 等人,2005 年;Vovk,2012 年)。 然而,时间序列的 CP 并不是微不足道的,因为时间依赖性常常违反可交换性假设。
HopCPT. 对于预测给定系统的时间序列模型,误差通常特定于描述当前情况的输入。 为了应用 CP,HopCPT 使用连续的现代 Hopfield 网络 (MHN)。 MHN 对与当前情况相似的过去情况使用较大的权重,对与当前情况不同的过去情况使用接近于零的权重(图 1)。 CP 过程使用加权误差来构建接近所需覆盖水平的强不确定性估计。 这利用了类似的情况(我们称之为政权)往往遵循相同的错误分布。 即使在不可交换性和大型数据集上,HopCPT 也实现了新的最先进的效率。
我们的主要贡献是:
- 我们提出了 HopCPT,一种用于时间序列的 CP 方法,这是迄今为止 CP 苦苦挣扎的领域。
- 我们向CP引入了错误机制的概念,这软化了兴奋性要求并实现了时间序列的高效CP。
- HopCPT 使用 MHN 进行基于相似性的样本重新加权。 与现有方法相比,HopCPT 可以从大型数据集中学习并预测任意覆盖级别的间隔,而无需重新训练。
- HopCPT 在各种实际应用的保形时间序列预测任务中取得了最先进的结果。
- HopCPT 是第一个应用于水文预测应用的具有覆盖保证的算法,在水文预测应用中,不确定性在洪水预报和水电管理等任务中发挥着关键作用。
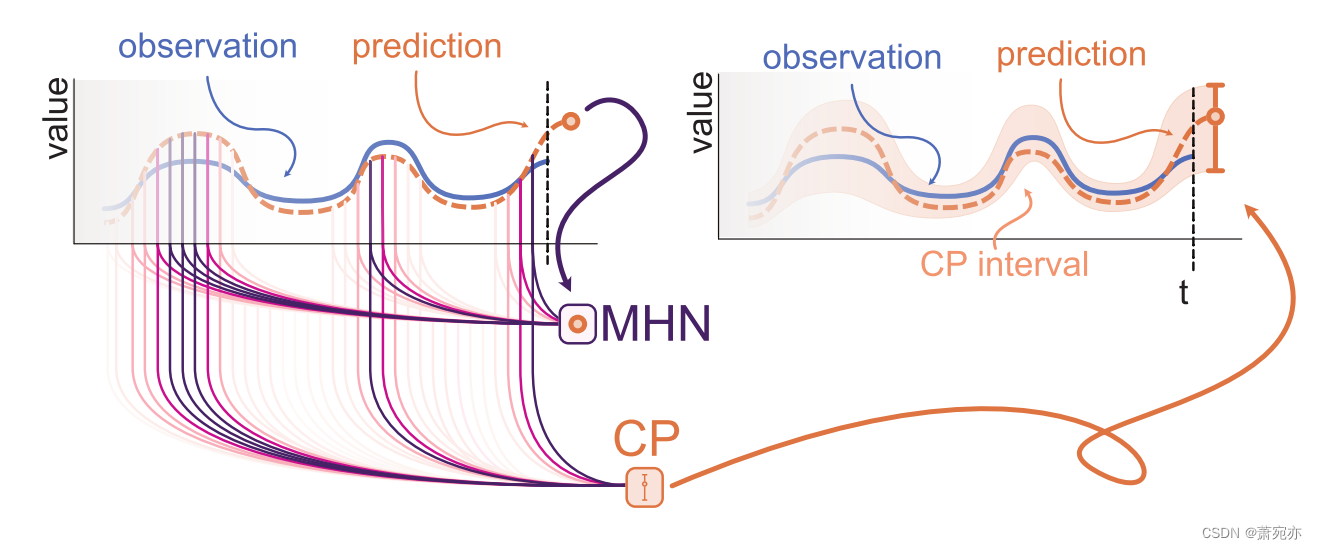
图 1:HopCPT 示意图。 现代霍普菲尔德网络 (MHN) 识别与当前类似的制度并提高它们的权重(彩色线)。 加权信息丰富了共形预测(CP)过程,以便可以导出预测区间。
1.1 Related Work
Regimes。 在非线性动态的世界中,不同的环境条件会导致基于这些条件进行预测的模型出现不同的误差特征。 如果我们不考虑这些不同的条件,时间变化可能会导致不必要的大预测间隔,即高度不确定性。 例如,太阳能产量在晴天高且稳定,在阴天波动,在夜间为零。 通常,当前的环境状况在之前的时间点已经被观察到。 因此,假设这些时间步长的误差与当前误差具有相同的分布。 遵循 Quandt (1958) 和 Hamilton (1990) 的说法,我们将具有相似环境条件的时间步集称为制度。 尽管条件 CP 通常是不可能的(Foygel Barber 等人,2021),但我们表明,对此类方案进行调节可以带来更好的预测区间,同时保留指定的覆盖范围。 Hamilton (1990) 将时间序列状态建模为离散马尔可夫过程,并以状态状态的经典自回归模型为条件。 桑克尔等人。 (2012) 使用平滑过渡方法对多状态时间序列进行建模。 塔杰纳等人。 (2021)提出了一种在包含多个时间序列的生态系统中发现和模拟状态转变的方法。 此外,马塞拉诺等人。 (2022)通过使用来自非均匀自适应采样的训练数据重新训练预测模型来处理分布变化。 尽管这些方法不是在 CP 环境中,但它们的工作在精神上是相似的,因为它们也遵循以具有相似状态的时间序列的部分为条件的总体思路。
**CP and extensions.**为了全面介绍 CP,我们建议读者参考 Vovk 等人的基础工作。 (1999) 以及 Angelopoulos 和 Bates 最近发表的一篇介绍性论文 (2021)。 CP 存在多种“超越可交换性”的扩展(Vovk 等,2005)。 例如,Papadopoulos & Haralambous (2011) 将 CP 应用于最近邻回归设置,Teng 等人。 (2022) 将 CP 应用于模型的特征空间,Angelopoulos 等人。 (2020) 使用 CP 为图像分类任务生成不确定性集,Toccaceli 等人。 (2017) 使用标签条件变体将 CP 应用于生物活性预测。 我们特别感兴趣的是 Tibshirani 等人关于不可交换数据的研究。 (2019)和 Foygel Barber 等人。 (2022)。 两者都通过重新加权数据点来处理校准集和测试集之间的潜在变化。 提布希拉尼等人。 (2019)将自己限制在充分了解分布变化的环境中; 福伊格尔·巴伯等人。 (2022)依赖固定权重。 在我们的工作中,我们避免这种假设,因为此类信息通常在时间序列预测中不可用。 另一个重要的研究方向是归一化一致性分数的研究(参见 Fontana 等人,2023 年以及其中的参考文献)。 在此设置中,目标是通过不合格函数中的缩放因子来调整共形边界。 关于标准化一致性分数的工作并没有明确地根据时间序列调整他们的方法。
**CP for time series.**Gibbs & Candes (2021) 和 Zaffran 等人。 (2022)通过不断调整内部覆盖目标来解释顺序数据的变化。 像这样的基于适应的方法与 HopCPT 正交,可以作为增强。 Stankeviˇci˙e 等人。 (2021)在多步预测设置中将 CP 与循环神经网络结合使用,假设一系列观察是独立的。 因此,不需要对分数进行加权。 Sun & Yu (2022) 介绍了 CopulaCPTS,它将 CP 应用于具有多变量目标的时间序列。 他们根据目标变量的关联来保形预测,并在每个步骤中调整其校准集。 詹森等人。 (2022) 使用 bootstrap ensemble 在时间序列上启用 CP。 NexCP(Foygel Barber et al., 2022)使用指数衰减作为加权方法,认为最近的过去更有可能具有相同的误差分布。 HopCPT 可以学习这种策略,但不会先验地承诺它。 Xu & Xie (2022a) 提出了 EnbPI,它使用 k 个最近错误的分位数作为预测区间。 此外,他们还引入了一种新颖的留一法集成技术。 这是专门针对数据稀缺且难以用于较大数据集的设置,这就是我们不在实验中应用它的原因。 EnbPI 的设计理念是近期误差通常是独立且同分布的,因此是可交换的。 SPCI (Xu & Xie, 2022b) 通过利用随机森林的自相关结构来软化这一要求。 然而,它在每个时间步重新计算随机森林模型,这是一个计算负担,阻碍了其应用于大型数据集。 我们的方法进一步放宽了要求,因为我们不假设区间计算的数据与 k 个最近的错误有关。
Non-CP methods除了 CP 之外,还存在多种用于不确定性感知时间序列预测的方法。 例如,混合密度网络(Bishop,1994)直接估计混合分布的参数。 然而,它们需要分布假设并且不提供任何理论保证。 高斯过程(例如,Zhu et al., 2023;Corani et al., 2021;Sun et al., 2022)通过基于样本和先验计算后验函数来对时间序列进行建模,但对于大型和高维数据集在计算上受到限制 。
Continuous Modern Hopfield Networks. MHN 是基于能量的联想记忆网络。 他们通过新的能量函数引入连续查询和状态来推进传统的 Hopfield 网络(Hopfield,1982)。 新的能量函数导致存储容量呈指数级增长,同时可以通过一步更新进行检索(Ramsauer 等人,2021)。 Widrich 等人是 MHN 成功应用的例子。 (2020); 福斯特等人。 (2022); 董等人。 (2022); 桑切斯·费尔南德斯等人。 (2022); 派舍尔等人。 (2022); 沙夫尔等人。 (2022); 和徐等人。 (2022)。 MHN 与 Transformers 相关(Vaswani et al., 2017),因为它们的注意力机制与 MHN 中的关联机制密切相关。 事实上,拉姆绍尔等人。 (2021) 表明 Transformers 注意力是 MHN 关联的一个特例,当查询和状态映射到维度为 dk 的关联 Hopfield 空间,并且逆 softmax 温度设置为 β = 1 d k \beta=\frac{1}{\sqrt{d_{k}}} β=dk1 时,我们就达到了这种情况 。 然而,我们使用 MHN 框架是因为我们想强调联想记忆机制,因为 HopCPT 直接摄取编码的观察结果。 这个视角进一步允许 HopCPT 更新每个新观察的记忆。 有关更多详细信息,我们参考补充材料中的附录 H。
1.2 Setting
我们的设置由多元时间序列
{
(
x
t
,
y
t
)
}
,
t
=
1
,
…
,
T
\{(\boldsymbol{x}_t,y_t)\},t=1,\ldots,T
{(xt,yt)},t=1,…,T组成,特征向量
x
t
∈
R
m
x_t\in\mathbb{R}^m
xt∈Rm,目标变量
y
t
∈
R
y_t\in\mathbb{R}
yt∈R,以及给定的黑盒预测模型
μ
^
\hat{\mu}
μ^,该模型生成点预测
y
^
t
=
μ
^
(
X
t
)
\hat{y}_t=\hat{\mu}(\boldsymbol{X}_t)
y^t=μ^(Xt)。 输入特征矩阵
X
t
+
1
X_{t+1}
Xt+1可以包括所有先前和当前特征向量
{
x
i
}
i
=
1
t
+
1
\{\boldsymbol{x}_{i}\}_{i=1}^{t+1}
{xi}i=1t+1,以及所有先前目标
{
y
i
}
i
=
1
t
\{y_i\}_{i=1}^t
{yi}i=1t。 我们的目标是构造一个相应的预测区间
C
^
t
α
(
Z
t
+
1
)
\widehat{C}_t^\alpha(\boldsymbol{Z}_{t+1})
C
tα(Zt+1)) — 一个包含
y
t
+
1
y_{t+1}
yt+1 且至少具有指定概率 1 − α 的集合。 在其基本形式中,
Z
t
+
1
Z_{t+1}
Zt+1将仅包含
y
^
t
+
1
\hat{y}_{t+1}
y^t+1,但它也可以继承
X
t
+
1
X_{t+1}
Xt+1或其他有用的特征。 继 Vovk 等人之后。 (2005),我们将覆盖范围定义为
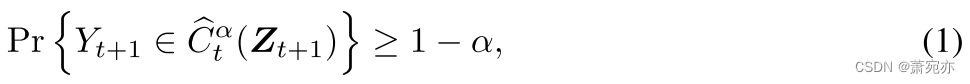
其中
Y
t
+
1
Y_{t+1}
Yt+1 是预测的随机变量。 无限宽的预测区间是 100% 可靠的,但不能提供不确定性信息。 因此,CP 的目标是最小化预测区间
C
^
t
α
\widehat{C}_{t}^{\alpha}
C
tα 的宽度,同时保留覆盖范围。 较小的预测间隔被称为更有效的间隔(Vovk et al., 2005),通常被评估为预测周期内间隔宽度的平均值(PI-Width)。
标准分割共形预测采用大小为 n 的校准集,该校准集尚未用于训练预测模型
μ
^
\hat{\mu}
μ^。 对于每个数据样本,它都会计算所谓的不合格分数(Vovk 等,2005)。 在回归设置中,该分数通常简单地对应于预测的绝对误差(例如,Foygel Barber 等人,2022)。 然后根据校准分数的经验 1 − α 分位数
Q
1
−
α
\mathrm{Q}_{1-\alpha}
Q1−α 计算预测区间:
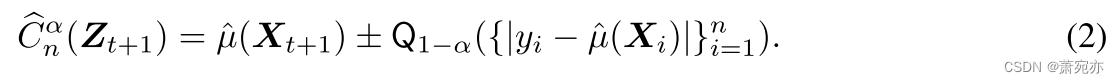
如果数据是可交换的并且 μ ^ \hat{\mu} μ^对称地对待数据点,则测试集上的误差遵循校准的分布。 因此,校准集和测试集的经验分位数将大致相等,并且保证间隔提供所需的覆盖范围。
实际边际错误覆盖率 α⋆ 基于测试集的观察样本。 如果指定的误覆盖 α 与评估中的 α⋆ 不同,我们将差异表示为覆盖差距 Δ Cov = α − α⋆。
本手稿的其余部分结构如下:在第 2 节中,我们介绍了 HopCPT、理论动机和展示该方法优点的综合示例。 在第 3 节中,我们根据最先进的 CP 方法评估性能并讨论结果。 第 4 节给出了我们的结论,并对未来潜在的工作进行了展望。
二、 HopCPT
HopCPT1 将共形分位数估计与基于学习相似性的 MHN 检索相结合。
2.1 Theoretical Motivation
MHN 检索的理论动机源于 Foygel Barber 等人。 (2022),他引入了带有加权分位数的 CP。 在分割共形设置中,相应的预测区间计算为
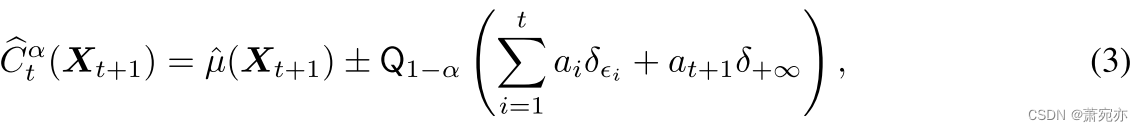
其中
μ
^
\hat{\mu}
μ^表示现有的点预测模型,
Q
τ
\mathbb{Q}_{\tau}
Qτ是分布的
τ
\tau
τ分位数,
δ
ϵ
i
\delta_{\epsilon_{i}}
δϵi是
∣
ϵ
i
∣
\left|\epsilon_{i}\right|
∣ϵi∣处的点质量。 (即,所有质量位于
∣
ϵ
i
∣
\left|\epsilon_{i}\right|
∣ϵi∣的概率分布),其中 ϵi 是由
ϵ
i
=
y
i
−
μ
^
(
X
i
)
.
\epsilon_i=y_i-\hat{\mu}(\boldsymbol{X}_i).
ϵi=yi−μ^(Xi).定义的现有预测模型的误差。 数据样本 i 的归一化权重
a
i
a_{i}
ai为
其中 ωi 是样本的未归一化权重。 在
ω
1
=
…
=
ω
t
=
1
\omega_1=\ldots=\omega_t=1
ω1=…=ωt=1的情况下,这对应于标准分裂CP。 鉴于此框架,Foygel Barber 等人。 (2022) 表明 Δ Cov 可以在不可交换的数据设置中受到限制:设
D
=
(
(
X
1
,
Y
1
)
,
…
,
(
X
t
+
1
,
Y
t
+
1
)
)
D=((\boldsymbol{X}_1,Y_1),\ldots,(\boldsymbol{X}_{t+1},Y_{t+1}))
D=((X1,Y1),…,(Xt+1,Yt+1))为数据集,其中最后一个条目表示 测试样本,
D
i
D_i
Di 是 D 的排列,将 t+1 处的测试样本与第 i 个样本交换。 然后,ΔCov 可以从下面以这些排列之间的总变异距离
d
T
V
d_{TV}
dTV 的加权和为界:
如果 D 是多个体系的组合,并且测试样本与校准样本 i 来自相同的体系,则 D 和 Di 之间的距离很小。 相反,如果校准样本来自不同的体系,则距离可能很大。 在 HopCPT 中,MHN 关联类似于 ai 的直接估计——动态地为来自相似机制的样本分配高值。
附录 B 提供了扩展的理论讨论,将 HopCPT 与 Foygel Barber 等人的工作联系起来。 (2022) 和 Xu & Xie (2022a),他们为我们 CP 区间的理论分析提供了基础。 后者计算误差本身的预测区间上限和下限的各个分位数,这与仅使用最高绝对误差分位数的标准 CP 不同。 在相应误差分布内 E [ ϵ ] ≠ 0 \begin{aligned}E[\epsilon]\neq0\end{aligned} E[ϵ]=0的情况下,这可以提供更有效的间隔。 将此原理应用于 HopCPT,其中误差分布以误差状态为条件,并假设 HopCPT 可以成功识别这些状态(附录:假设 B.3),我们得出条件渐近覆盖界限(附录:定理 B.8)并且 渐近边际覆盖范围(附录:定理 B.9)。
2.2 Associative Soft-selection for CP
我们使用 MHN 来识别时间序列中条件误差分布相似的部分:对于时间步 t + 1,我们查询过去的记忆并寻找匹配模式。 然后 MHN 提供一个关联向量 at+1,允许软选择存储器的相关周期。 选择过程类似于用于硬选择的k近邻分类器,但它的优点是可以学习相似性度量。 正式地,软选择定义为:
其中 m 是一个编码网络(第 2.3 节),它将当前步骤
Z
t
+
1
Z_{t+1}
Zt+1的原始时间序列特征转换为查询模式,并将内存
Z
1
:
t
\boldsymbol{Z}_{1:t}
Z1:t 转换为存储的关键模式;
W
q
\boldsymbol{W}_{q}
Wq和
W
k
\boldsymbol{W}_{k}
Wk 是在将查询与内存关联之前应用的学习变换; β 是控制 softmax 温度的超参数。 如上所述,HopCPT 使用 softmax 来放大可能遵循相似误差分布的数据样本的影响,并减少遵循不同分布的样本的影响(参见第 2.1 节)。 这种误差加权不仅可以在我们的实验中带来更有效的预测区间,而且还可以减少错误覆盖(第 3.2 节)。
通过软选择的时间步,我们可以使用g观察到的误差e来推导CP间隔。继Xu&Xie(2022 a)之后,我们使用各个分位数来计算预测区间的上下限,并根据误差本身计算。 hop CPT计算时间步长t+1的预测区间 C ^ t α \widehat{C}_t^\alpha C tα以下列方式进行:
其中
q
(
τ
,
Z
t
+
1
)
=
Q
τ
(
E
t
+
1
)
a
n
d
E
t
+
1
q(\tau,\boldsymbol{Z}_{t+1})=\mathbb{Q}_\tau(E_{t+1})\mathrm{~and~}E_{t+1}
q(τ,Zt+1)=Qτ(Et+1) and Et+1 是通过从
[
ϵ
i
]
i
=
1
t
[\epsilon_i]_{i=1}^t
[ϵi]i=1t中绘制 n 次而创建的多重集,相应概率为
[
a
t
+
1
,
i
]
i
=
1
t
[a_{t+1,i}]_{i=1}^t
[at+1,i]i=1t。
2.3 Encoding Network
我们使用带有 ReLU 激活的 2 层全连接网络 m L m^L mL 嵌入 Z t Z^t Zt,并通过时间编码特征 z T , t t i m e z_{T,t}^{\mathrm{time}} zT,ttime 增强表示。 完整的编码网络可以表示为 m ( Z t ) = [ m L ( Z t ) ∣ ∣ z T , t t i m e ] m(\boldsymbol{Z}_t)=[m^L(\boldsymbol{Z}_t)\mid\mid\boldsymbol{z}_{T,t}^\mathrm{time}] m(Zt)=[mL(Zt)∣∣zT,ttime],其中 z T , t t i m e z_{T,t}^{\mathrm{time}} zT,ttime是一种简单的时间编码,它使得时间相关的相似性概念可学习(例如,EnbPI 的窗口方法或 NexCP 的指数衰减加权方案)。 具体来说,我们使用 z T , t t i m e = t T z_{T,t}^{\mathrm{time}}=\frac{t}{T} zT,ttime=Tt 。 一般来说,我们发现我们的方法对确切的编码策略(例如层数)不是很敏感,这就是为什么我们在所有实验中都保持简单的选择。
2.4 训练流程
我们将分割的保形校准数据划分为训练集和验证集。 用分位数训练 MHN 很困难,这就是我们使用辅助任务的原因:我们不直接应用等式 6 中的关联机制,而是使用绝对误差作为 MHN 的值模式。 通过这种方式,MHN 学会将时间步长的误差与相似的状态属性对齐。 直观上,从这些时间步长观察到的误差应该最能预测当前的绝对误差。 我们使用均方误差作为损失函数(公式 8)。 为了实现高效的训练,我们同时计算训练分割内所有 T 时间步彼此之间的关联。 我们将关联从一个时间步屏蔽到自身。 每一步到每一步得到的关联为
A
1
:
T
,
1
:
T
,
\boldsymbol{A}_{1:T,1:T},
A1:T,1:T,,损失函数L为
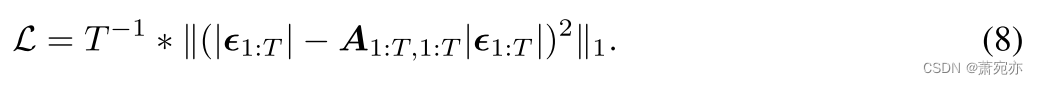
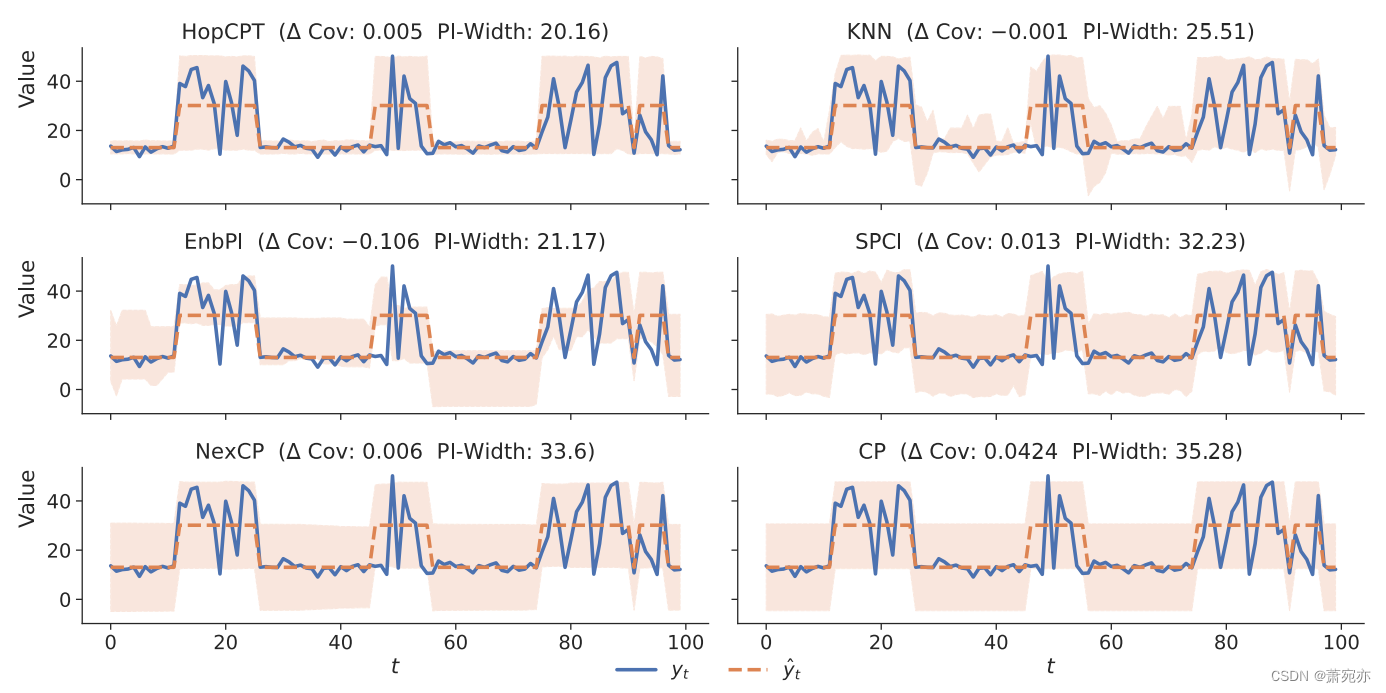
图 2:综合示例评估。 HopCPT 具有最小的预测区间宽度 (PIwidth),同时保持保证的覆盖范围(即,Δ Cov 为正且接近于零)。
这会激励网络学习一种表示,以便最终的软选择集中于具有相似误差分布的时间步长。 或者,可以使用基于 softmax 采样的损失。 这将更接近于推理过程。 然而,它降低了训练效率,因为每个训练步骤仅携带有关 ϵ i \epsilon_{i} ϵi单个值的信息。 相反,L 会带来更有效的样本训练。 选择 L 假设它会导致从适当的机制中检索错误,而不是混合不相关的错误。 第 3.2 节和附录 A.3 提供了经验证明这一点的证据。
2.5 Synthetic Example综合实例
下面的综合例子说明了HopCPT关联机制的优点。 我们对双变量时间序列 D = { ( x t , y t ) } t = 1 T D=\{(x_t,y_t)\}_{t=1}^T D={(xt,yt)}t=1T 进行建模。 y t y_{t} yt作为目标变量, x t x_{t} xt 代表我们预测中的特征。 该序列由两种不同的机制组成:目标值由 y t = 10 + x t + N ( 0 , x t 2 ) or y t = 10 + x t + U ( − x t , x t ) \begin{aligned}y_t=10+x_t+\mathcal{N}(0,\frac{x_t}{2})\text{or}y_t=10+x_t+U(-x_t,x_t)\end{aligned} yt=10+xt+N(0,2xt)oryt=10+xt+U(−xt,xt) 生成。 x t x_t xt 在某个范围内是常数(分别为 x = 3 和 x = 21)。 政权交替。 对于每个状态,我们从离散均匀分布 U(1, 25) 中采样时间步数。 我们创建 1,000 个时间步长,并将数据平均分为训练集、校准集和测试集。 我们使用岭回归模型作为预测模型 μ ^ \hat{\mu} μ^。 HopCPT 可以识别相关机制的时间步长,从而创建有效的预测区间,同时仍保留覆盖范围(图 2)。 EnbPI、SPCI 和 NexCP 仅关注最近的时间步长,因此无法将其间隔基于来自正确机制的信息。 每当状态从小误差变为高误差时,EnbPI 就会传播小误差信号,从而失去覆盖范围。 同样,它对小误差范围的预测区间效率低下(图 2,第 3 行)。 SPCI、NexCP 和标准 CP 也无法正确选择相关的时间步长。 它们不会丢失覆盖范围,但会为所有时间步产生较宽的间隔(图 2,第 4 行和第 5 行)。 最后,如果我们用 kNN 替换 MHN,它可以从类似的体系中检索信息。 然而,其简单的检索机制无法关注信息丰富的特征,因为它无法学习它们(图 2,第 2 行)。
2.6 Limitations
HopCPT建立在CP的形式保证之上,但它能够放宽CP的数据可交换性假设,这对于时间序列数据来说是有问题的。 也就是说,HopCPT 仍然依赖于如何学习识别各自的错误机制和机制内的可交换性的假设(参见第 2.1 节和附录 B)。 我们广泛的实证评估表明这些假设在实践中成立。 HopCPT 通常非常适合很长的时间序列,因为推理中的内存需求仅与内存大小成线性比例。 然而,对于非常大的数据集,可能出现的情况是并非所有历史时间步都可以再保存在 Hopfield 内存中。 与现有方法类似,HopCPT 可以通过从内存中删除最旧的条目来忽略时间步长,或者使用子采样策略。 另一方面,对于数据非常稀缺的数据集,可能很难学习有用的时间步长嵌入。 在这种情况下,使用 kNN 可能比使用 MHN 学习相似性更好(附录 D)。 附录 I 总结了有关该方法潜在社会影响的其他考虑因素。
三、 Experiments
本节对HopCPT进行比较评价并分析其关联机制。
3.1 Setup
数据集。 我们使用来自四个不同领域的数据集:(a)来自美国国家太阳辐射数据库的三个太阳辐射数据集(Sengupta 等人,2018)。 最小的一个由 84 天内来自不同地点的 8 个时间序列组成。 Xu & Xie (2022a,b) 也使用了该数据集。 此外,我们还评估了 1 年和 3 年的数据集,每个数据集有 50 个时间序列。 (b) 中国北京的空气质量数据集(Zhang et al., 2017)。 它由 12 个时间序列组成,每个时间序列都来自不同的测量站,历时 4 年。 该数据集有两个预测目标,PM10(如 Xu & Xie,2022a,b)和 PM2.5 浓度,我们分别对其进行评估。 © 来自 Sapfluxnet 数据项目的液流 2 测量值(Poyatos 等人,2021 年)。 由于各个测量序列的长度相当不同,因此我们使用 24 个时间序列的子集,每个时间序列具有 15,000 到 20,000 个数据点和不同的采样率。 (d) Streamflow,美国大陆 531 条河流的水流测量值和相应气象观测数据集(Newman 等人,2015 年;Addor 等人,2017 年)。 测量时间跨度为 28 年(按日计算)。 有关数据集的更多详细信息,请参阅附录 C。
预测模型。 我们对太阳辐射、空气质量和树液通量数据集使用四种预测模型,以确保我们的结果具有概括性:随机森林、LightGBM、岭回归和长短期记忆 (LSTM) (LSTM; Hochreiter 和 Schmidhuber,1997)模型。 对于前三个模型,我们遵循相关工作(Xu & Xie, 2022a,b;Foygel Barber et al., 2022),并为每个单独的时间序列训练一个单独的预测模型。 随机森林和 LightGBM 模型通过 darts 库实现(Herzen 等人,2022),岭回归模型通过 sklearn 实现(Pedregosa 等人,2011)。 对于 LSTM 模型,我们在数据集的所有时间序列上训练全局模型,这是最先进的深度学习模型的标准(例如,Oreshkin 等人,2020;Salinas 等人,2020; 斯迈尔,2020)。 LSTM 使用 PyTorch 实现(Paszke et al., 2019)。 对于水流数据集,我们偏离了这个方案,而是只使用最先进的模型,这也是一个 LSTM 网络(Kratzert 等人,2021,参见附录 C)。
比较方法。 我们将 HopCPT 与时间序列数据的不同最先进的 CP 方法进行比较:EnbPI (Xu & Xie, 2022a)、SPCI (Xu & Xie, 2022b)、NexCP (Foygel Barber et al., 2022)、CopulaCPTS ( Sun 和 Yu,2022),以及 AdaptiveCI3(Gibbs 和 Candes,2021)。 此外,标准分割 CP (CP) 的结果作为基线,对于 LSTM 基础预测器,对应于我们设置中的 CFRNN (Stankeviˇci˙e et al., 2021)(一步、单变量目标) 多变的)。 附录 A.1 描述了我们对每种方法的超参数搜索。 对于 SPCI,需要对原始算法进行调整,以便为更大的数据集提供可扩展性。 附录 A.2 包含更多细节和经验论证。 附录 G 评估了添加 AdaptiveCI(Gibbs & Candes,2021)作为 HopCPT 和其他时间序列 CP 方法的增强功能。 附录 A.3 给出了与非 CP 方法的比较。 最后,附录 D 提供了与 kNN 的补充比较,显示了 HopCPT 中学习到的相似性表示的优越性。
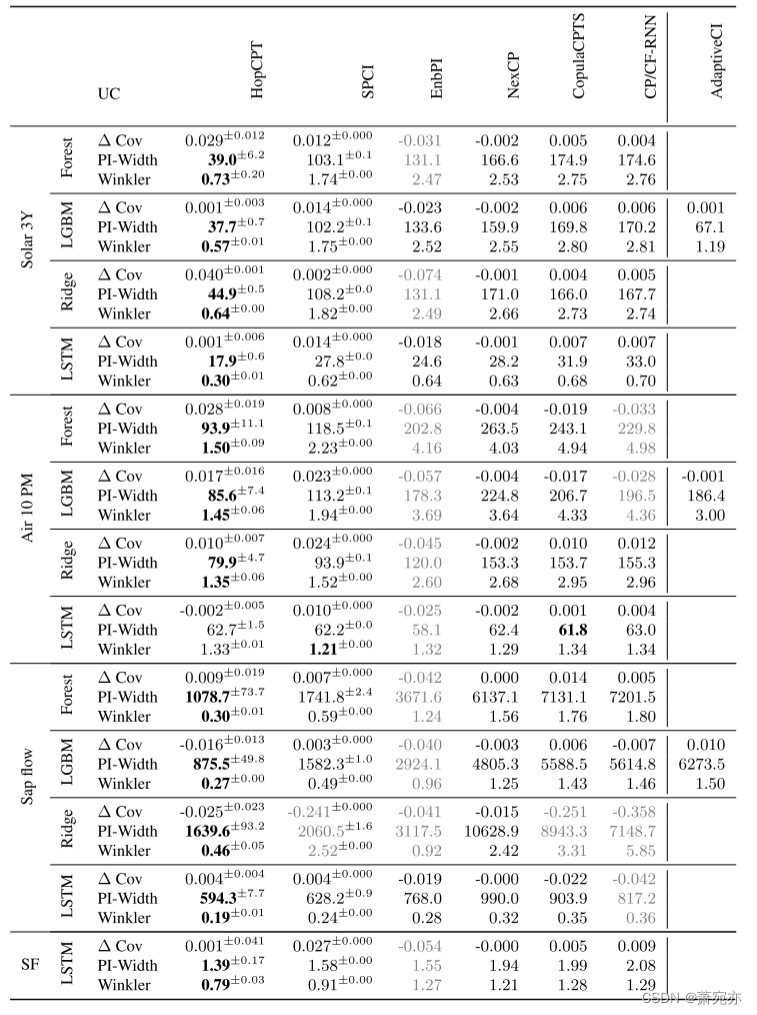
表 1:针对太阳 (3Y)、空气质量 (10PM)、液流和溪流 (SF) 数据集评估的 CP 算法的性能。 所有实验的指定错误覆盖水平均为 α = 0.1。 FC 列指定用于实验的预测算法(Forest:随机森林,LGBM:LightGBM,Ridge:岭回归,LSTM:LSTM 神经网络)。 粗体数字对应于实验中各个指标的最佳结果(PI-Width 和 Winkler 分数),假设 ΔCov ≥ -0.25α,即特定算法至少达到近似覆盖范围(否则结果呈灰色)。 误差项表示使用不同种子重复运行的标准偏差(没有误差项的结果来自确定性模型)。
指标。 在我们的分析中,我们计算每个时间序列和误覆盖水平的 Δ Cov、PI-Width 和 Winkler 分数(Winkler,1972)。 Winkler 分数在单个指标中联合引发错误覆盖和区间宽度:
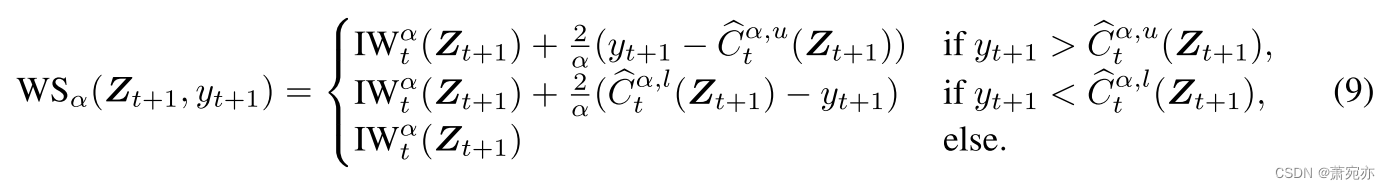
分数是根据时间步长 t 和误覆盖水平 α 计算的。 当观测值
y
t
y_t
yt 位于
C
^
t
α
(
Z
t
+
1
)
\widehat{C}_t^{\alpha}(\boldsymbol{Z}_{t+1})
C
tα(Zt+1)的上界
C
^
t
α
,
u
(
Z
t
+
1
)
\widehat{C}_t^{\alpha,u}(\boldsymbol{Z}_{t+1})
C
tα,u(Zt+1) 和下界
C
^
t
α
,
l
(
Z
t
+
1
)
\widehat{C}_t^{\alpha,l}(\boldsymbol{Z}_{t+1})
C
tα,l(Zt+1)之间时,它对应于区间宽度
I
W
t
α
=
C
^
t
α
,
u
−
C
^
t
α
,
l
\mathrm{IW}_{t}^{\alpha}=\widehat C_{t}^{\alpha,u}-\widehat C_{t}^{\alpha,l}
IWtα=C
tα,u−C
tα,l。 如果
y
t
+
1
y_{t+1}
yt+1 超出这些界限,则会对间隔宽度添加惩罚。 我们评估所有时间步长的平均温克勒分数。
我们用 12 种不同的种子重复了每个实验。 为简洁起见,我们仅在主论文中显示 α = 0.1 时每个域一个数据集的平均性能(这是 CP 文献中最常报告的值;例如 Xu & Xie,2022b;Foygel Barber 等人,2022) 吉布斯和坎德斯,2021)。 附录 A.3 提供了所有数据集和更多 α 水平的附加结果。
3.2 Results & Discussion
HopCPT 对每个域都有最有效的预测区间 - 对于评估的错误覆盖水平 (α = 0.1),只有一个例外(表 1;使用 Mann-Whitney U 检验在 p < 0.005 处测试显着性)。 在多个实验(Solar (3Y)、Solar (1Y))中,HopCPT 预测区间的宽度不到第二小 PI 宽度方法的一半。 第二有效的间隔最常由 SPCI 预测。 这一排名也适用于 Winkler 分数,其中 HopCPT 获得了最好(即最低)的 Winkler 分数,而 SPCI 在大多数实验中排名第二。 值得注意的是,这些结果反映了每种不确定性估计方法对数据集提出的日益增长的要求(第 1.1 节)。
此外,当我们在其他数据集和不同的错误覆盖水平上进行评估时,HopCPT 在 Winkler 评分和 PI-Width 方面均优于其他方法(参见附录 A.3)。 在绝大多数情况下,HopCPT 是效果最好的方法。 不同太阳能数据集大小的变化(附录 A.3 中 Solar (1Y) 和 Solar (3M) 的结果)表明,当有更多数据可用时,HopCPT 尤其会增加其领先优势。 我们假设这是因为 MHN 可以通过更多数据学习更通用的检索模式。 然而,数据稀缺并不是基于相似性的 CP 的限制。 事实上,HopCPT 的简化且几乎无参数的变体(用 kNN 检索代替 MHN)在最小的太阳数据集上表现最佳,正如我们在附录 D 中演示的那样。
大多数方法在几乎所有实验中的覆盖差距都接近于零——它们大约达到了指定的边际覆盖水平。 大多数评估中 Winkler 分数和 PI-Width 的排名一致也反映了这一点。 附录 A.4 提供了本地覆盖范围的补充分析。 非 CP 方法的结果显示出不同的情况(参见附录 A.3 和表 7)。 在这里,非 CP 模型通常表现出非常窄的预测区间,但代价是高误报率。
有趣的是,标准 CP 还以低效的预测间隔为代价实现了所有实验的良好覆盖。 有一个值得注意的例外:对于采用岭回归的液流数据集,我们发现 Δ Cov = −0.358。 在这种情况下,我们认为标准 CP 的糟糕性能是由于严重违反(必需的)可交换性假设而导致的。 具体来说,误差的趋势会导致分布随时间变化(如附录 A.3、图 4 所示)。 HopCPT 和 NexCP 可以应对这种转变,而不会造成覆盖范围的重大损失。 SPCI 的较差覆盖范围可能是受到较大数据集修改的影响(参见附录 A.2)。
不同数据集之间的方法之间的性能差距有很大差异,但在预测模型之间通常是一致的。 最好和最差方法之间的最大差异存在于太阳流 (3Y) 和液流中,可能是由于这些数据集中的独特机制所致。 Streamflow 数据中可以看到最小(但仍然显着)的差异。 在此数据集上,我们还评估了该领域最先进的非 CP 不确定性模型(Klotz 等人,2022,参见附录 A.3),发现 HopCPT 在效率方面优于它。
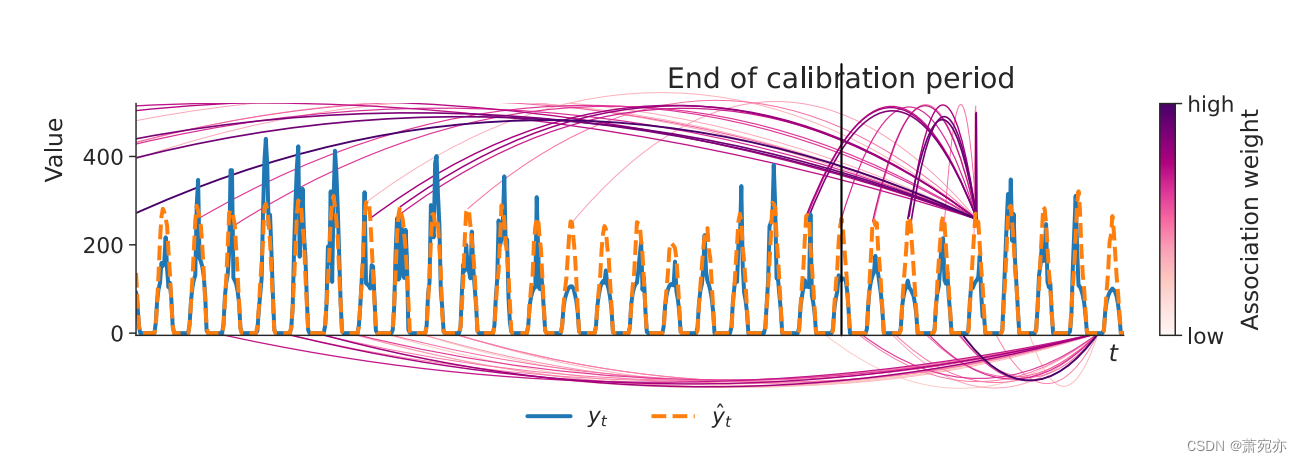
图 3:MHN 在先前时间步骤上放置的 30 个最高关联权重的示例可视化(有些位于内存的可视化部分之前)。 HopCPT 在估计峰值时检索相似的峰值,在估计小值时检索相似的小值。
就计算资源而言,SPCI 要求最高,其次是 HopCPT,因为与其他方法相比,这两种方法都需要学习步骤。 详细概述请参见附录 A.6。
为了评估 HopCPT 是否在制度内学习有意义的关联,我们对 Solar (3Y) 数据集进行了定性研究。 图 3 显示 HopCPT 从具有相似机制的时间步中检索最高加权的误差。 所示的具有低预测值的时间步长的加权检索也处于低值状态的先前时间步长。 同样,图 5(附录 A.3)表明学习到的区别对应于错误机制,这对于 HopCPT 至关重要。
四、 Conclusions
我们引入了 HopCPT,一种用于时间序列任务的新颖的 CP 方法。 HopCPT 使用连续的现代 Hopfield 网络根据先前看到的具有类似误差分布机制的事件构建预测区间。 我们利用相似的特征导致相似的错误。 将特征与错误相关联可以识别具有相似错误分布的状态。 HopCPT 在现代 Hopfield 网络中学习这种关联,该网络根据当前状态动态调整其对存储的先前特征的关注。 我们对已建立的和新颖的数据集的实验表明,HopCPT 达到了最先进的水平:它比现有的 CP 方法生成更有效的预测区间,并且即使在时间序列等不可交换的场景中,也能大致保留覆盖范围。 HopCPT 在 CP 框架内提供了正式的保证,可用于实际应用(例如水流预测)中的不确定性估计。 此外,HopCPT 可以很好地扩展到大型数据集,在校准后提供多个覆盖级别,并在数据集中的各个时间序列之间共享信息。 未来的工作包括:(a)在推理阶段从多个时间序列中提取数据。 HopCPT 已经在整个数据集上立即进行了训练,但在推理过程中利用更多信息也可能是有利的。 (b) 调查基于学习的 CP 可能受益的直接培训目标。 © 在时间序列之外使用 HopCPT,因为不可交换性也是其他领域的一个问题,限制了现有 CP 方法的适用性。

















 1717
1717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









