







算术逻辑单元ALU

运算器的内部除了包含一些必要的寄存器之外,用于实现运算的核心部件就是算术逻辑单元(ALU)。
ALU主要有以下功能:
- 算术运算:加、减、乘、除等
- 逻辑运算:与、或、非、异或等
- 辅助功能:移位、求补等
ALU的大致结构如下:

A
i
A_i
Ai和
B
i
B_i
Bi为输入信号,比如说要实现两个8比特二进制数的加法,那么其中一个从
A
i
A_i
Ai端输入,另一个从
B
i
B_i
Bi端输入,输入的本质是一些电信号(高低电平),输出信号(运算结果)从
F
i
F_i
Fi端输出,
K
i
K_i
Ki为控制信号,由控制单元CU发出。
例子:74181芯片

右边的
S
3
S
2
S
1
M
S_3 S_2 S_1 M
S3S2S1M是来自控制单元的控制信号,控制单元会负责解析指令的含义,然后根据这个指令的含义发出一些控制信号,如:
M
=
1
,
S
3
S
2
S
1
S
0
=
1001
M=1,S_3 S_2 S_1 S_0=1001
M=1,S3S2S1S0=1001时,做逻辑运算
A
⊕
B
A \oplus B
A⊕B,
S
3
S
2
S
1
S
0
S_3 S_2 S_1 S_0
S3S2S1S0有4比特信息,即对应
2
4
=
16
2^4=16
24=16中状态,说明此芯片支持16种算数运算或16种逻辑运算。
A
i
、
B
i
和
F
i
A_i、B_i和F_i
Ai、Bi和Fi与上一张图对应上分别为输入信号和输出信号。
机器字长,指计算机能够同时处理多少个比特位的整数运算,即ALU里面可以支持同时输入多少个比特的信息。一般来说,ALU可以处理多少比特的数据,通常就会把寄存器 X X X的位数和ALU的位数保持一致。上图种,ALU输入了两个4bit的信息,然后输出一个4bit的运算结果,这个结果要放回到某一个寄存器里面,为了能让ALU与寄存器能够完美地适配,ALU是多少位,寄存器也对应设计为多少位。
左边的输出信号和下边的 C − 1 C_{-1} C−1输入信号是为了和其他芯片进行串联而设计的。
最基本的逻辑运算

A和B是输入信号,Y是输出信号。比如说,对于与门,A输入5V的电信号为1,B输入1V的电信号为0,则Y会输出1V的电信号为0,即1和0相与得到0.
注:非门的电路图种右边有一个小圆圈。
类比乘法、加法
- 与运算和或运算的优先级:与>或(Eg:AB+CD先算 与 ,再算 或)
- A(C+D)=AC+AD ——分配律
- ABC=A(BC) ——结合律
- A+B+C=A+(B+C) ——结合律
这有何意义?
本质上,逻辑表达式是对电路的数学化描述,简化逻辑表达式,就是在简化电路,而这些器件是需要钱的,那么简化电路就是在省钱。
例子:
电路实现AC+AD=A(C+D)
可以看到,右边的实现方式比左边的实现方式少了一个与门。

复合逻辑运算

反演率(德摩根率):
A
+
B
‾
=
A
‾
⋅
B
‾
,
A
⋅
B
‾
=
A
‾
+
B
‾
\overline{A+B}=\overline{A}\cdot \overline{B},\overline{A\cdot B}=\overline{A}+\overline{B}
A+B=A⋅B,A⋅B=A+B
任何使用与、或、非实现异或运算?
->A和B不同则为1
->A=0且B=1 或者 A=1且B=0
->
A
‾
⋅
B
+
A
⋅
B
‾
\overline{A}\cdot {B}+{A}\cdot \overline{B}
A⋅B+A⋅B
电路实现:
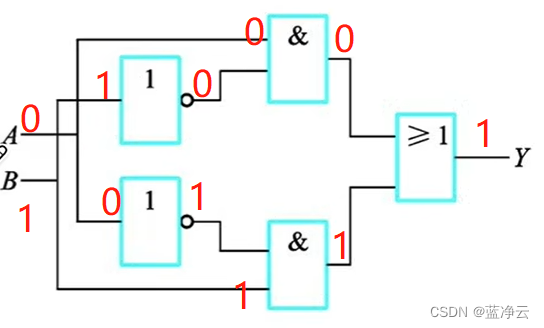
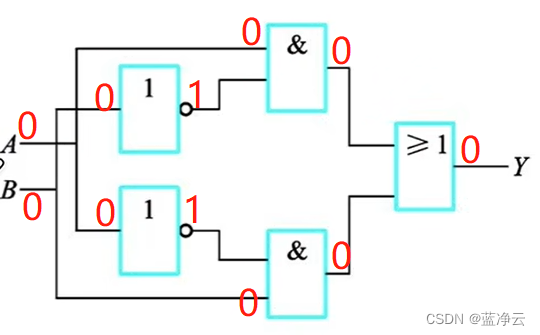
用门电路求偶校验位
“异或”的天然逻辑:“加法”“奇偶校验”
偶校验就是当我们加入了这个校验位之后,整体来看,1的数量总共有偶数个。

偶校验的逻辑和异或的逻辑对应,对偶数个1进行异或,最终得到的结果是0,对应于偶校验需要得到的校验位。奇校验的逻辑和异或的逻辑对应,对奇数个1进行异或,最终得到的结果是0,对应于奇校验需要得到的校验位。

下面位求偶校验位的电路图:

一位全加器
异或门如何实现加法运算?
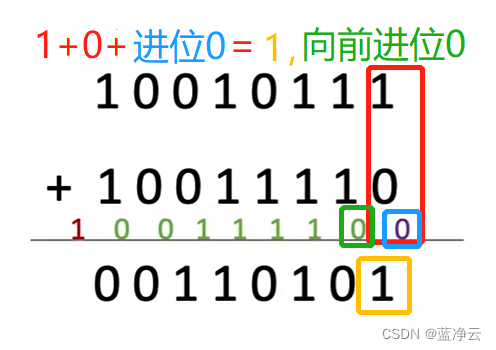
首先从手算加法出发。

S
i
和
C
i
S_i和C_i
Si和Ci如何确定?
输入中有奇数个1时,
S
i
S_i
Si为1(异或)
S
i
=
A
i
⊕
B
i
⊕
C
i
−
1
S_i=A_i \oplus B_i \oplus C_{i-1}
Si=Ai⊕Bi⊕Ci−1;有两种情况
C
i
C_i
Ci为1,第一种是两个本位为1,即
A
i
B
i
A_iB_i
AiBi都为1,即
A
i
B
i
=
1
A_iB_i=1
AiBi=1,另一种情况是两个本位中有一个1,且来自低位的进位
C
i
−
1
C_{i-1}
Ci−1是1,即
(
A
i
⊕
B
i
)
C
i
−
1
=
1
(A_i \oplus B_i )C_{i-1}=1
(Ai⊕Bi)Ci−1=1。

根据这两个逻辑表达式就可以得到与之相对应的电路,如下图

这就是一位全加器,根据两个本位和低位的进位作为输入,可以确定本位和
S
i
S_i
Si和向高位的进位
C
i
C_i
Ci,将上图简化,屏蔽它内部的电路细节,如下图

串行加法器
接下来看一下如何用一位全加器来实现多位加法。
顾名思义,所谓串行就是一位一位地加,增加一个进位触发器,用来保存进位位,以此来实现一位一位地加。

A
i
B
i
C
i
−
1
A_iB_iC_{i-1}
AiBiCi−1经过一位全加器可以确定
S
i
S_i
Si和
C
i
C_i
Ci,
C
i
C_i
Ci保存到进位触发器中,接下来就可以输入更高位的信息
A
i
+
1
B
i
+
1
C
i
A_{i+1}B_{i+1}C_i
Ai+1Bi+1Ci,
C
i
C_i
Ci的值来自于进位触发器作为输入信号,以此类推。
串行加法器:只有一个全加器,数据逐位串行送入加法器进行运算。进位触发器用来寄存进位信号,以便参与下次运算。
如果操作数长n位,加法就要分n次进行,每次产生一位和,并且并且串行逐位送回寄存器,所以这种串行加法器的效率是比较低的。
并行加法器

串行进位的并行加法器:把n个全加器串接起来,就可以进行两个n位数的相加。
这样就可以同时输入两个n位的数,A和B这两个操作数都有n位,每一组对应的位都会用全加器进行相加,并且低位的加和产生的进位会作为下一个全加器的输入信号,虽然刚开始我们就可以同时输入A和B这两个数的各个数值位信息,电器的实际运行速度很快,然而,这些电信号的传递依然是需要时间的,也就是说,只有更低位的运算执行结束之后,才可以确定应该往高位进一个什么样的信号,如果往高位进的信号发生了改变,高位的和还有往更高位的进位信号也会发生改变。所以,这种并行加法器称为串行进位的并行加法器,进位信息都是串行着一位一位往前进的。
串行进位行波进位,每一位进位直接依赖于前一级的进位,即进位信号是逐位形成的,所以这种加法器的运算速度很大程度上依赖于每一位进位的产生速度和传输速度。那这个问题如何优化呢?
ALU的改进
如何更快地产生进位呢?让我们将进位
C
i
C_i
Ci的表达式展开:

如果把
C
i
C_i
Ci一直展开,总有一天可以展开到
C
0
C_0
C0,而
C
0
C_0
C0是最开始就拥有的信息。
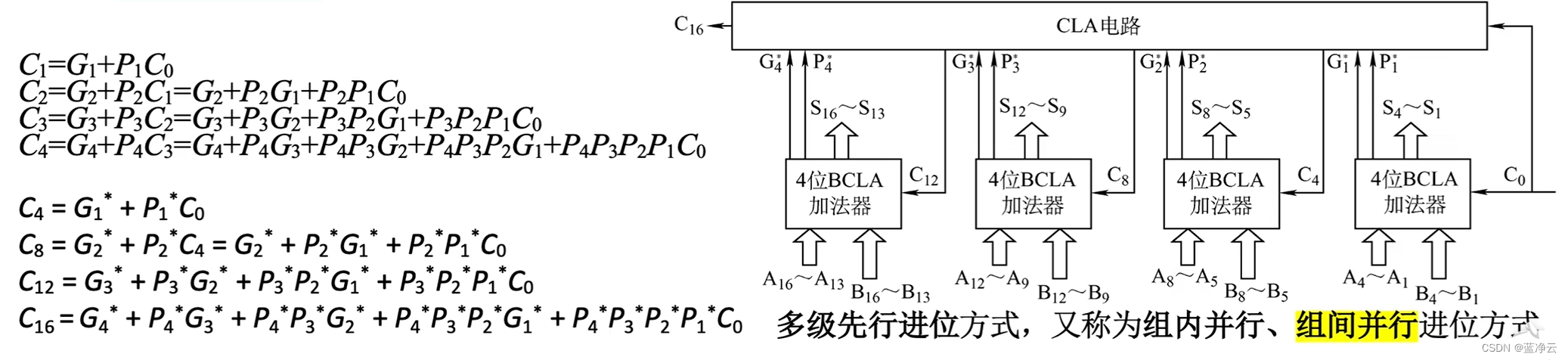
结论:第i位向更高位的进位 C i C_i Ci可根据被加数和加数的第1~i位,再结合 C 0 C_0 C0即可确定。
记
G
i
=
A
i
B
i
,
P
i
=
A
i
⊕
B
i
G_i=A_iB_i,P_i=A_i\oplus B_i
Gi=AiBi,Pi=Ai⊕Bi,得到以下表达式:


从以上展开式可以看出,即使我们要计算的是
C
4
C_4
C4这个进位信息,刚开始就把所有的计算所需要的数据都准备好了,那么只需要根据表达式设计相应的电路就可以在第4个全加器那里直接算出全加器的值。这样的设计方案几乎每一位的进位信息都是同时产生的,无需再像之前的设计那样要等待后面的进位一位一位地往上传,所以这种加法器的计算速度会快很多。我们把它称为并行进位的并行加法器:各级进位信号同时产生,有称为先行进位、同时进位。

这种设计的缺陷:从
C
1
到
C
4
C_1到C_4
C1到C4我们一度往下套娃,套得越深,逻辑表达式就越长,电路就越复杂。
比较经典你的做法是,套到
C
4
C_4
C4的位置,即可以支持4位加4位的运算。

如果我们需要更多的比特位进行加法,只需要将4位CLA加法器进行串联即可。
并行加法器的优化
单级先行进位方式,又称为组内并行、组间串行进位方式。

组内进位可同时得出,但组间的进位又会产生之前的问题,即要先确定第一组的
C
4
C_4
C4,第二组的
C
8
S
8
S
7
S
6
S
5
C_8S_8S_7S_6S_5
C8S8S7S6S5才可以确定,要一步一步往前传,那么如何优化此问题呢?
继续套娃!!!
记
G
1
∗
=
G
4
+
P
4
G
3
+
P
4
P
3
G
2
+
P
4
P
3
P
2
G
1
;
G_{1}^{*}=G_4+P_4G_3+P_4P_3G_2+P_4P_3P_2G_1;
G1∗=G4+P4G3+P4P3G2+P4P3P2G1;
P
1
∗
=
P
4
P
3
P
2
P
1
P_{1}^{*}=P_4P_3P_2P_1
P1∗=P4P3P2P1


核心特性:根据本组的4×2个输入位即可确定本组的
G
i
∗
P
i
∗
G_{i}^{*}P_{i}^{*}
Gi∗Pi∗。

组间进位信息的运算规则与组内进位信息的运算规则完全可以对应上,也就是说,把
G
1
∗
、
P
1
∗
、
G
2
∗
、
P
2
∗
、
G
3
∗
、
P
3
∗
、
G
4
∗
、
P
4
∗
G_{1}^{*}、P_{1}^{*}、G_{2}^{*}、P_{2}^{*}、G_{3}^{*}、P_{3}^{*}、G_{4}^{*}、P_{4}^{*}
G1∗、P1∗、G2∗、P2∗、G3∗、P3∗、G4∗、P4∗作为CLA的输入,那么CLA内部的电路就可以帮我们完成对
C
4
、
C
8
、
C
12
、
C
16
C_4、C_8、C_{12}、C_{16}
C4、C8、C12、C16的运算。
ALU芯片的优化
把上面的电路进行改造,将每4个比特进行一个分组,进行4bit+4bit的运算,将CLA的内部线路进行改造(BCLA),让它输出这个分组的
G
i
∗
和
P
i
∗
G_{i}^{*}和P_{i}^{*}
Gi∗和Pi∗,然后
G
i
∗
和
P
i
∗
G_{i}^{*}和P_{i}^{*}
Gi∗和Pi∗作为CLA电路的输入,而CLA内部则可以并行得出
C
4
、
C
8
、
C
12
、
C
16
C_4、C_8、C_{12}、C_{16}
C4、C8、C12、C16的值,即每一个分组在计算本位和的时候需要作为参考的进位信息不需要像之前那样等着从后面一个一个往前传,所以采用这种思想来实现电路,可以实现组内并行、组间并行的进位方式,每一组所需的进位信息都是并行产生的,因此电路的运算效率再一次提升。
74181芯片支持实现4位的加法运算,下图中
C
n
+
4
C_{n+4}
Cn+4为两个4位的比特信息相加之后向更高位的进位,
C
−
1
C_{-1}
C−1是来自低位的进位。

所以利用线路把4个74181串行起来就可以实现16位的组内并行、组间串行的进位ALU。

如果再接上一个SN74182芯片,那么我们就可以实现16位的组内并行、组间并行的进位ALU。

总结:串行加法器→串行进位的并行加法器→组内并行、组间串行进位的加法器→组内并行、组间并行进位的加法器
学习参考
王道考研:https://www.bilibili.com/video/BV1BE411D7ii?p=27&vd_source=795c0ddf50db35d4812a24c0bc3c09f4


















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











