







说明:
从PyTorch中经典的quickstart示例开始,从中学习神经网络构建和训练的过程,数据集是FashionMNIST数据集。
其中流程如下:
- 环境配置准备
- 数据预处理
- 构建模型
- 定制模型损失函数和优化器
- 训练并观察超参数
下面我们就一步步分解这个过程,其中也会学习认识到一些Pytorch为我们提供的框架内置对象和函数。该模块是Pytorch框架的入门,如果初次接触Pytorch框架,可能还不是很适应,所以以先完成完整的模型训练流程为重。后续再根据任务需求,一步步的扩展Pytorch的认知版图。
一、环境配置
该实验在jupyter notebook中完成。
需要安装matplotlib库和Pytorch库,其中库是安装指令是:
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
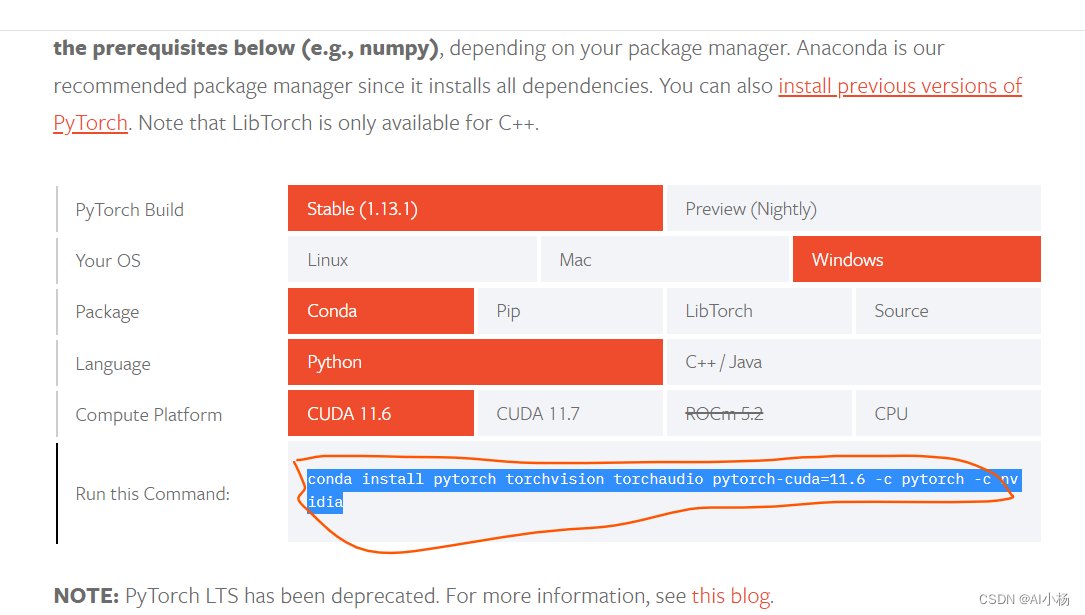
Pytorch框架移步到Pytorch官网,根据自己需要安装的版本来配置,比如说我选择的是Windows+Conda+Python+CUDA11.6,复制的指令如下:
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
安装好上述两个库后,在jupyter notebook中导入需要的库:
#导入需要库
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda, Compose
import matplotlib.pyplot as plt
- 运行截图:
PyTorch 有两个用于处理数据的工具:torch.utils.data.DataLoader 和 torch.utils.data.Dataset。 Dataset 存储的是数据样本和对应的标签,DataLoader 把Dataset包装成一个可迭代的对象。
本次的数据样本来自于Pytorch的TorchVision 数据集。
二、数据预处理
1、下载数据集
(1)下载训练集
下载的数据集文件会保存到当前用户目录的data子目录中。
参数root:数据集保存的文件夹路径,可以相对路径和绝对路径,该案例中root=‘data’:为相对路径,意思为保存到当前路径下的data文件夹中
绝对路径:例如:"D:\datasets\fashonMNIST\"一类的绝对路径
training_data=datasets.FashionMNIST(
root='data',
train=True,
download=True,
transform=ToTensor()
)
#查看训练集
training_data
- 运行截图:

(2) 测试集下载
#测试集也需要下载(下载测试集)
#代码和上面一样,但是参数train=False代表不是训练集(逻辑取反,就是测试集)
test_data=datasets.FashionMNIST(
root='data',
train=False,
download=False,
transform=ToTensor(),
)
#查看测试集
test_data
- 运行截图:

2、对已加载的数据集进行封装
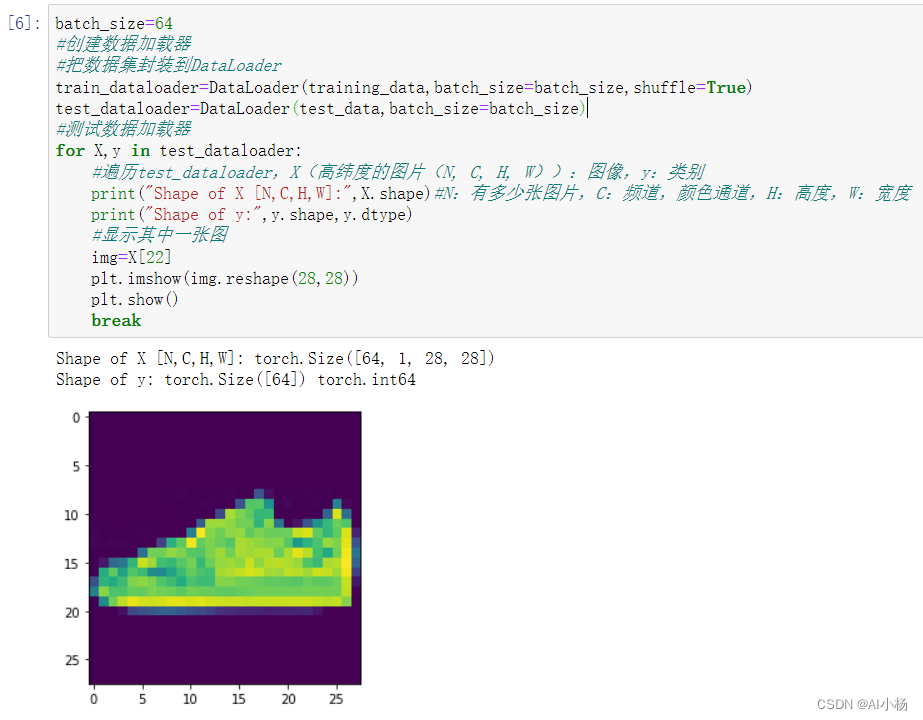
下一步就是对已加载数据集的封装,把Dataset 作为参数传递给 DataLoader。这样,就在我们的数据集上包装了一个迭代器(iterator),这个迭代器还支持自动批处理、采样、打乱顺序和多进程数据加载等这些强大的功能。这里我们定义了模型训练期间,每个批次的数据样本量大小为64,即数据加载器在迭代中,每次返回一批 64 个数据特征和标签。
batch_size=64
#创建数据加载器
#把数据集封装到DataLoader
train_dataloader=DataLoader(training_data,batch_size=batch_size,shuffle=True)
test_dataloader=DataLoader(test_data,batch_size=batch_size)
#测试数据加载器
for X,y in test_dataloader:
#遍历test_dataloader,X(高纬度的图片(N, C, H, W)):图像,y:类别
print("Shape of X [N,C,H,W]:",X.shape)#N:有多少张图片,C:频道,颜色通道,H:高度,W:宽度
print("Shape of y:",y.shape,y.dtype)
#显示其中一张图
img=X[22]
plt.imshow(img.reshape(28,28))
plt.show()
break
- 运行截图:
三、构建模型
1、构建模型
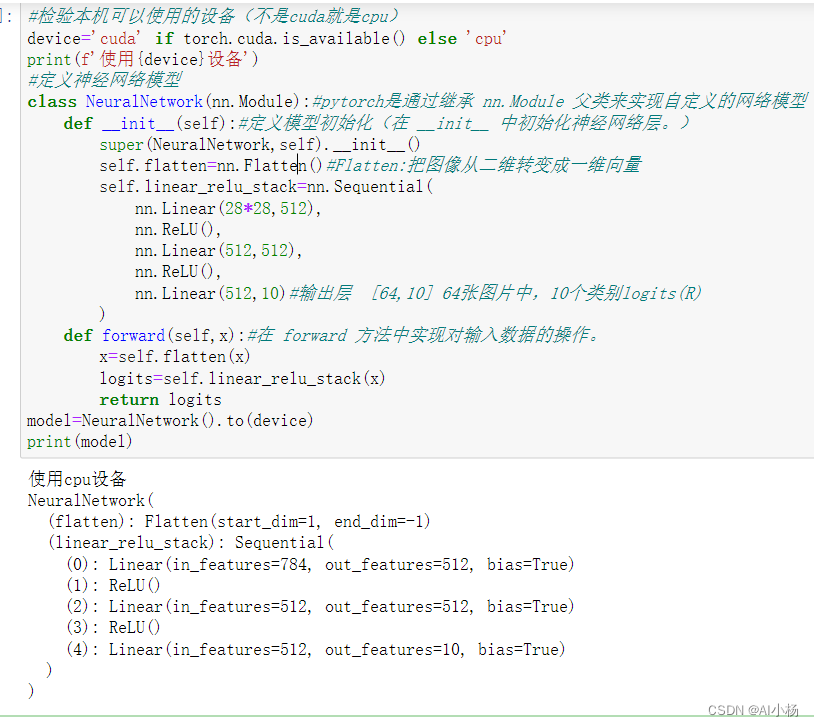
为了在 PyTorch 中定义神经网络,我们创建了一个继承自 nn.Module 的类。我们在 init 函数中定义网络层,并在 forward 函数中指定数据将如何通过网络。为了加速神经网络中的操作,我们将其移至 GPU(如果可用)。
#检验本机可以使用的设备(不是cuda就是cpu)
device='cuda' if torch.cuda.is_available() else 'cpu'
print(f'使用{device}设备')
#定义神经网络模型
class NeuralNetwork(nn.Module):#pytorch是通过继承 nn.Module 父类来实现自定义的网络模型
def __init__(self):#定义模型初始化(在 __init__ 中初始化神经网络层。)
super(NeuralNetwork,self).__init__()
self.flatten=nn.Flatten()#Flatten:把图像从二维转变成一维向量
self.linear_relu_stack=nn.Sequential(
nn.Linear(28*28,512),
nn.ReLU(),
nn.Linear(512,512),
nn.ReLU(),
nn.Linear(512,10)#输出层 [64,10] 64张图片中,10个类别logits(R)
)
def forward(self,x):#在 forward 方法中实现对输入数据的操作。
x=self.flatten(x)
logits=self.linear_relu_stack(x)
return logits
model=NeuralNetwork().to(device)
print(model)
- 运行截图:
2、对上述的“构建模型”功能块进行拆分讲解
为了方便分解 FashionMNIST 模型中的各个层进行说明,我们取一个由 3 张大小为 28x28 的图像组成的小批量样本,看看当它们通过网络传递时会发生什么。
```python
input_image=torch.rand(3,28,28)
print(input_image.size())
- 运行截图:

nn.Flatten
我们初始化 nn.Flatten 层,将每个28x28 大小的二维图像转换为 784 个像素值的连续数组(保持小批量维度(dim=0))。
flatten=nn.Flatten()
flat_image=flatten(input_image)
print(flat_image.size())
- 运行截图:

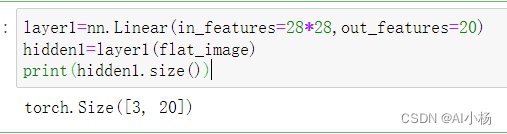
nn.Linear
linear layer线性层是一个模块,它使用其存储的权重和偏置对输入应用线性变换。
layer1=nn.Linear(in_features=28*28,out_features=20)
hidden1=layer1(flat_image)
print(hidden1.size())
- 运行截图:
nn.ReLU
为了在模型的输入和输出之间创建复杂映射,我们使用非线性激活。激活函数在线性变换之后被调用,以便把结果值转为非线性,帮助神经网络学习到各种各样的关键特征值。 在这个模型中,线性层之间使用了 nn.ReLU,其实还有很多激活函数可以在模型中引入非线性。
print(f"ReLU 之前的数据: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"ReLU 之后的数据: {hidden1}")
#可以发现把负数转换为0
- 运行截图:

nn.Sequential
nn.Sequential 是一个有序的模块容器。数据按照容器中定义的顺序通过所有模块。我们可以使用顺序容器来组合一个像 seq_modules 这样的快速处理网络。
seq_modules=nn.Sequential(
flatten,
layer1,
nn.ReLU(),
nn.Linear(20,10)
)
input_image=torch.rand(3,28,28)
logits=seq_modules(input_image)
- 运行截图:

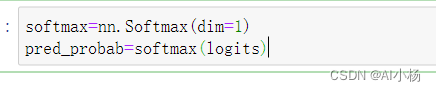
nn.Softmax
神经网络的最后一个线性层返回的是 logits类型的值,它们的取值是[-∞, ∞]。 把这些值传递给 nn.Softmax 模块。 logits的值将会被缩放到 [0, 1] 的取值区间,代表模型对每个类别的预测概率。 dim 参数指示我们在向量的哪个维度中计算softmax的值(和为1)。
softmax=nn.Softmax(dim=1)
pred_probab=softmax(logits)
- 运行截图:
注意:标题“三、模型构建”模块下的标题1为模型构建,标题2为模型构建的模型分解。
四、打印模型参数
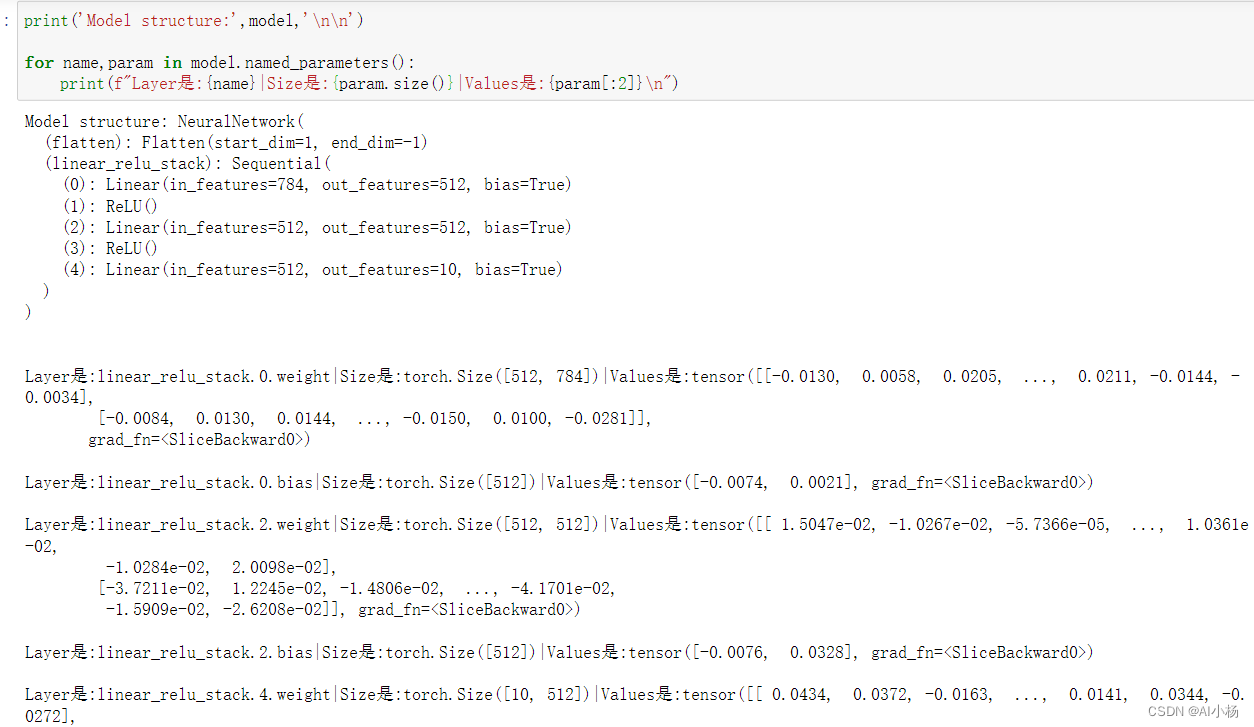
神经网络内的许多层都是包含可训练参数的,即具有在训练期间可以优化的相关权重(weight)和偏置(bias)。子类 nn.Module 可以自动跟踪模型对象中定义的所有参数字段。使用模型的 parameters() 或 named_parameters() 方法可以访问模型中所有的参数。 下面的代码可以迭代模型中的每一个参数,并打印出它们的大小和它们的值。
print('Model structure:',model,'\n\n')
for name,param in model.named_parameters():
print(f"Layer是:{name}|Size是:{param.size()}|Values是:{param[:2]}\n")
- 运行截图:
五、 定制模型损失函数和优化器
训练模型之前,我们需要为模型定制一个损失函数loss function和一个优化器 optimizer。
loss_fn=nn.CrossEntropyLoss()#交叉熵损失函数
optimizer=torch.optim.SGD(model.parameters(),lr=1e-3)# 使用随机梯度下降方法的优化器
- 运行截图:

六、训练并观察超参数
在单个训练循环中,模型对训练数据集进行预测(分批输入),并反向传播预测误差以调整模型参数。
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练数据样本总量
model.train() # 设置模型为训练模式
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device) # 张量加载到设备
# 计算预测的误差
pred = model(X) # 调用模型获得结果(forward时被自动调用)
loss = loss_fn(pred, y) # 计算损失
# 反向传播 Backpropagation
model.zero_grad() # 重置模型中参数的梯度值为0
loss.backward() # 计算梯度
optimizer.step() # 更新模型中参数的梯度值
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
我们还要依赖测试数据集来检查模型的性能,以确保它的学习优化效果。
def test(dataloader,model,loss_fn):
size=len(dataloader.dataset)
num_batches=len(dataloader)
model.eval()#模型设置为评估模型,代码等效于model.train(False)
test_loss,correct=0,0
with torch.no_grad():
for X,y in dataloader:
X,y=X.to(device),y.to(device)
pred=model(X)
test_loss+=loss_fn(pred,y).item()
correct+=(pred.argmax(1)==y).type(torch.float).sum().item()
test_loss/=num_batches
correct/=size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
默认情况下,所有 requires_grad=True 属性值的张量都会被跟踪,以便于根据上一次的值来支持对梯度计算。但是,在某些情况下我们并不需要这样做,例如,当我们训练了模型但只想将其应用于某些输入数据的时。或者说白了就是我们只想通过网络进行前向计算时。我们可以把所有计算代码写在 torch.no_grad() 下面来停止跟踪计算。
训练过程在多轮迭代(epochs)中进行。在每个epoch中,模型通过学习更新内置的参数,以期做出更好的预测。我们在每个epochs打印模型的准确率和损失值;当然,最希望看到的,就是每个 epoch 过程中准确率的增加而损失函数值的减小。
epochs = 100
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
print("训练完成!")
- 运行截图:
基于Pytorch框架的神经网络实现入门讲解到此结束。
















 6249
6249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











