







目录
简介
前面介绍的动态规划算法是model-base的,其要求马尔可夫决策过程是已知的,即要求与智能体交互的环境是完全已知的(例如迷宫或者给定规则的网格世界)。
在此条件下,智能体其实并不需要和环境真正交互来采样数据,直接用动态规划算法就可以解出最优价值或最优策略。这就好比对于有监督学习任务,如果直接显式给出了数据的分布公式,那么也可以通过在期望层面上直接最小化模型的泛化误差来更新模型参数,并不需要采样任何数据点。
但这在大部分场景下并不现实,机器学习的主要方法都是在数据分布未知的情况下针对具体的数据点来对模型做出更新的。对于大部分强化学习现实场景(例如电子游戏或者一些复杂物理环境),其马尔可夫决策过程的状态转移概率是无法写出来的,也就无法直接进行动态规划。在这种情况下,智能体只能和环境进行交互,通过采样到的数据来学习,这类学习方法统称为无模型的强化学习(model-free reinforcement learning)。
不同于动态规划算法,无模型的强化学习算法不需要事先知道环境的奖励函数和状态转移函数,而是直接使用和环境交互的过程中采样到的数据来学习,这使得它可以被应用到一些简单的实际场景中。
本章将要讲解无模型的强化学习中的两大经典算法:Sarsa 和 Q-learning,它们都是基于时序差分(temporal difference,TD)的强化学习算法。同时,本章还会引入一组概念:在线策略学习和离线策略学习。
通常来说,在线策略学习要求使用在当前策略下采样得到的样本进行学习,一旦策略被更新,当前的样本就被放弃了,就好像在水龙头下用自来水洗手;而离线策略学习使用经验回放池将之前采样得到的样本收集起来再次利用,就好像使用脸盆接水后洗手。因此,离线策略学习往往能够更好地利用历史数据,并具有更小的样本复杂度(算法达到收敛结果需要在环境中采样的样本数量),这使其被更广泛地应用。
时序差分方法
时序差分是一种用来估计一个策略的价值函数的方法,它结合了蒙特卡洛和动态规划算法的思想。时序差分方法和蒙特卡洛的相似之处在于可以从样本数据中学习,不需要事先知道环境;和动态规划的相似之处在于根据贝尔曼方程的思想,利用后续状态的价值估计来更新当前状态的价值估计。回顾一下蒙特卡洛方法对价值函数的增量更新方式:
V
(
s
t
)
←
V
(
s
t
)
+
α
[
G
t
−
V
(
s
t
)
]
V\left(s_t\right) \leftarrow V\left(s_t\right)+\alpha\left[G_t-V\left(s_t\right)\right]
V(st)←V(st)+α[Gt−V(st)]
这里我们之前的
1
N
(
s
)
\frac{1}{N(s)}
N(s)1 替换成了
α
\alpha
α ,表示对价值估计更新的步长。可以将
α
\alpha
α 取为一个常数,此时更新方式不再像蒙特卡洛方法那样严格地取期望。蒙特卡洛方法必须要等整个序列结束之后才能计算得到这一次的回报
G
t
G_t
Gt ,而时序差分方法只需要当前步结束即可进行计算。
具体来说,时序差分算法用当前获得的奖励加上下一个状态的价值估计来作为在当前状态会获得的回报,
G
t
=
r
t
+
γ
V
(
s
t
+
1
)
G_t=r_t+\gamma V(s_{t+1})
Gt=rt+γV(st+1)即:
V
(
s
t
)
←
V
(
s
t
)
+
α
[
r
t
+
γ
V
(
s
t
+
1
)
−
V
(
s
t
)
]
V\left(s_t\right) \leftarrow V\left(s_t\right)+\alpha\left[r_t+\gamma V\left(s_{t+1}\right)-V\left(s_t\right)\right]
V(st)←V(st)+α[rt+γV(st+1)−V(st)]
其中
R
t
+
γ
V
(
s
t
+
1
)
−
V
(
s
t
)
R_t+\gamma V\left(s_{t+1}\right)-V\left(s_t\right)
Rt+γV(st+1)−V(st) 通常被称为时序差分(temporal difference,TD)误差(error),时序差分算法将TD误差与步长的乘积作为状态价值的更新量。可以用
r
t
+
γ
V
(
s
t
+
1
)
r_t+\gamma V\left(s_{t+1}\right)
rt+γV(st+1) 来代替
G
t
G_t
Gt 的原因是:
V
π
(
s
)
=
E
π
[
G
t
∣
S
t
=
s
]
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
∣
S
t
=
s
]
=
E
π
[
R
t
+
γ
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
]
=
E
π
[
R
t
+
γ
V
π
(
S
t
+
1
)
∣
S
t
=
s
]
\begin{aligned} V_\pi(s) & =\mathbb{E}_\pi\left[G_t \mid S_t=s\right] \\ & =\mathbb{E}_\pi\left[\sum_{k=0}^{\infty} \gamma^k R_{t+k} \mid S_t=s\right] \\ & =\mathbb{E}_\pi\left[R_t+\gamma \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} \mid S_t=s\right] \\ & =\mathbb{E}_\pi\left[R_t+\gamma V_\pi\left(S_{t+1}\right) \mid S_t=s\right] \end{aligned}
Vπ(s)=Eπ[Gt∣St=s]=Eπ[k=0∑∞γkRt+k∣St=s]=Eπ[Rt+γk=0∑∞γkRt+k+1∣St=s]=Eπ[Rt+γVπ(St+1)∣St=s]
因此蒙特卡洛方法将上式第一行作为更新的目标,而时序差分算法将上式最后一行作为更新的目标。于是,在用策略和环境交互时,每采样一步,我们就可以用时序差分算法来更新状态价值估计。时序差分算法用到了 V ( s t + 1 ) V\left(s_{t+1}\right) V(st+1) 的估计值,可以证明它最终收敛到策略 π \pi π 的价值函数,我们在此不对此进行展开说明。
Sarsa算法
既然我们可以用时序差分方法来估计价值函数,那一个很自然的问题是,我们能否用类似策略迭代的方法来进行强化学习。
策略评估已经可以通过时序差分算法实现,那么在不知道奖励函数和状态转移函数的情况下该怎么进行策略提升呢?答案是时可以直接用时序差分算法来估计动作价值函数
Q
Q
Q :
Q
(
s
t
,
a
t
)
←
Q
(
s
t
,
a
t
)
+
α
[
r
t
+
γ
Q
(
s
t
+
1
,
a
t
+
1
)
−
Q
(
s
t
,
a
t
)
]
Q\left(s_t, a_t\right) \leftarrow Q\left(s_t, a_t\right)+\alpha\left[r_t+\gamma Q\left(s_{t+1}, a_{t+1}\right)-Q\left(s_t, a_t\right)\right]
Q(st,at)←Q(st,at)+α[rt+γQ(st+1,at+1)−Q(st,at)]
然后我们用贪婪算法来选取在某个状态下动作价值最大的那个动作,即:
arg
max
a
Q
(
s
,
a
)
\arg \max _a Q(s, a)
argamaxQ(s,a)
这样似乎已经形成了一个完整的强化学习算法:用贪婪算法根据动作价值选取动作来和环境交互,再根据得到的数据用时序差分算法更新动作价值估计。然而这个简单的算法存在两个需要进一步考虑的问题。
第一,如果要用时序差分算法来准确地估计策略的状态价值函数,我们需要用极大量的样本来进行更新。但实际上我们可以忽略这一点,直接用一些样本来评估策略,然后就可以更新策略了。我们可以这么做的原因是策略提升可以在策略评估未完全进行的情况进行,回顾一下,价值迭代是算法就是这样,这其实是广义策略迭代(generalized policy iteration)的思想。
第二,如果在策略提升中一直根据贪婪算法得到一个确定性策略,可能会导致某些状态动作对
(
s
,
a
)
(s, a)
(s,a) 永远没有在序列中出现,以至于无法对其动作价值进行估计,进而无法保证策略提升后的策略比之前的好。我们在之前的文章中对此有详细讨论。简单常用的解决方案是不再一味使用贪婪算法,而是采用一个
ϵ
\epsilon
ϵ-贪婪策略:有
1
−
ϵ
1-\epsilon
1−ϵ 的概率采用动作价值最大的那个动作,另外有
ϵ
\epsilon
ϵ 的概率从动作空间中随机采取一个动作,其公式表示为:
π
(
a
∣
s
)
=
{
ϵ
/
∣
A
∣
+
1
−
ϵ
如果
a
=
arg
max
a
′
Q
(
s
,
a
′
)
ϵ
/
∣
A
∣
其他动作
\pi(a \mid s)= \begin{cases}\epsilon /|\mathcal{A}|+1-\epsilon & \text { 如果 } a=\arg \max _{a^{\prime}} Q\left(s, a^{\prime}\right) \\ \epsilon /|\mathcal{A}| & \text { 其他动作 }\end{cases}
π(a∣s)={ϵ/∣A∣+1−ϵϵ/∣A∣ 如果 a=argmaxa′Q(s,a′) 其他动作
现在,我们就可以得到一个实际的基于时序差分方法的强化学习算法。这个算法被称为 Sarsa,因为它的动作价值更新用到了当前状态
s
s
s 、当前动作
a
a
a 、获得的奖励
r
r
r 、下一个状态
s
′
s^{\prime}
s′ 和下一个动作
a
′
a^{\prime}
a′ ,将这些符号
(
s
t
,
a
t
,
r
t
,
s
t
+
1
,
a
t
+
1
)
(s_t,a_t,r_{t},s_{t+1},a_{t+1})
(st,at,rt,st+1,at+1)拼接后就得到了算法名称。Sarsa 的具体算法如下:
- 初始化 Q ( s , a ) Q(s, a) Q(s,a)
- for 序列
e
=
1
→
E
e=1 \rightarrow E
e=1→E do:
- 得到初始状态 s s s
- 用 ϵ \epsilon ϵ-greedy 策略根据 Q Q Q 选择当前状态 s s s 下的动作 a a a
- for 时间步
t
=
1
→
T
t=1 \rightarrow T
t=1→T do :
- 得到环境反馈的 r , s ′ r, s^{\prime} r,s′
- 用 ϵ \epsilon ϵ-greedy 策略根据 Q Q Q 选择当前状态 s ′ s^{\prime} s′ 下的动作 a ′ a^{\prime} a′
- Q ( s , a ) ← Q ( s , a ) + α [ r + γ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a)+\alpha\left[r+\gamma Q\left(s^{\prime}, a^{\prime}\right)-Q(s, a)\right] Q(s,a)←Q(s,a)+α[r+γQ(s′,a′)−Q(s,a)]
- s ← s ′ , a ← a ′ s \leftarrow s^{\prime}, a \leftarrow a^{\prime} s←s′,a←a′
- end for
- end for
我们仍然在悬崖漫步环境下尝试 Sarsa 算法。首先来看一下悬崖漫步环境的代码,这份环境代码和第 4 章中的不一样,因为此时环境不需要提供奖励函数和状态转移函数,而需要提供一个和智能体进行交互的函数step(),该函数将智能体的动作作为输入,输出奖励和下一个状态给智能体。
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm # tqdm是显示循环进度条的库
class CliffWalkingEnv:
def __init__(self, ncol, nrow):
self.nrow = nrow
self.ncol = ncol
self.x = 0 # 记录当前智能体位置的横坐标
self.y = self.nrow - 1 # 记录当前智能体位置的纵坐标
def step(self, action): # 外部调用这个函数来改变当前位置
# 4种动作, change[0]:上, change[1]:下, change[2]:左, change[3]:右。坐标系原点(0,0)
# 定义在左上角
change = [[0, -1], [0, 1], [-1, 0], [1, 0]]
self.x = min(self.ncol - 1, max(0, self.x + change[action][0]))
self.y = min(self.nrow - 1, max(0, self.y + change[action][1]))
next_state = self.y * self.ncol + self.x
reward = -1
done = False
if self.y == self.nrow - 1 and self.x > 0: # 下一个位置在悬崖或者目标
done = True
if self.x != self.ncol - 1:
reward = -100
return next_state, reward, done
def reset(self): # 回归初始状态,坐标轴原点在左上角
self.x = 0
self.y = self.nrow - 1
return self.y * self.ncol + self.x
然后我们来实现Sarsa算法,主要维护一个表格Q_table(),用来储存当前策略下所有状态动作对的价值,在用Sarsa算法和环境交互时,用e-贪婪策略进行采样,在更新Sarsa算法时,使用时序差分的公式。我们默认终止状态时所有动作的价值都是 0,这些价值在初始化为 0 后就不会进行更新。
class Sarsa:
""" Sarsa算法 """
def __init__(self, ncol, nrow, epsilon, alpha, gamma, n_action=4):
self.Q_table = np.zeros([nrow * ncol, n_action]) # 初始化Q(s,a)表格
self.n_action = n_action # 动作个数
self.alpha = alpha # 学习率
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # epsilon-贪婪策略中的参数
def take_action(self, state): # 选取下一步的操作,具体实现为epsilon-贪婪
if np.random.random() < self.epsilon:
action = np.random.randint(self.n_action)
else:
action = np.argmax(self.Q_table[state])
return action
def best_action(self, state): # 用于打印策略
Q_max = np.max(self.Q_table[state])
a = [0 for _ in range(self.n_action)]
for i in range(self.n_action): # 若两个动作的价值一样,都会记录下来
if self.Q_table[state, i] == Q_max:
a[i] = 1
return a
def update(self, s0, a0, r, s1, a1):
td_error = r + self.gamma * self.Q_table[s1, a1] - self.Q_table[s0, a0]
self.Q_table[s0, a0] += self.alpha * td_error
接下来我们就在悬崖漫步环境中运行 Sarsa 算法,一起来看看结果吧!
ncol = 12
nrow = 4
env = CliffWalkingEnv(ncol, nrow)
np.random.seed(0)
epsilon = 0.1
alpha = 0.1
gamma = 0.9
agent = Sarsa(ncol, nrow, epsilon, alpha, gamma)
num_episodes = 500 # 智能体在环境中运行的序列的数量
return_list = [] # 记录每一条序列的回报
for i in range(10): # 显示10个进度条
# tqdm的进度条功能
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)): # 每个进度条的序列数
episode_return = 0
state = env.reset()
action = agent.take_action(state)
done = False
while not done:
next_state, reward, done = env.step(action)
next_action = agent.take_action(next_state)
episode_return += reward # 这里回报的计算不进行折扣因子衰减
agent.update(state, action, reward, next_state, next_action)
state = next_state
action = next_action
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0: # 每10条序列打印一下这10条序列的平均回报
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Sarsa on {}'.format('Cliff Walking'))
plt.show()
Iteration 0: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 1113.33it/s, episode=50, return=-119.400]
Iteration 1: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 1221.50it/s, episode=100, return=-63.000]
Iteration 2: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 1474.46it/s, episode=150, return=-51.200]
Iteration 3: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2089.03it/s, episode=200, return=-48.100]
Iteration 4: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 1671.08it/s, episode=250, return=-35.700]
Iteration 5: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2385.76it/s, episode=300, return=-29.900]
Iteration 6: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2506.85it/s, episode=350, return=-28.300]
Iteration 7: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2638.92it/s, episode=400, return=-27.700]
Iteration 8: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2506.25it/s, episode=450, return=-28.500]
Iteration 9: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2638.69it/s, episode=500, return=-18.900]
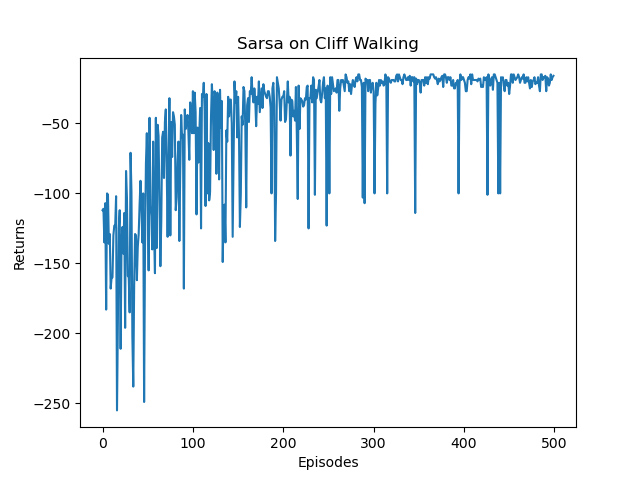 |  |
|---|
我们发现,随着训练的进行,Sarsa 算法获得的回报越来越高。在进行 500 条序列的学习后,可以获得 −20 左右的回报,此时已经非常接近最优策略了。然后我们看一下 Sarsa 算法得到的策略在各个状态下会使智能体采取什么样的动作。
def print_agent(agent, env, action_meaning, disaster=[], end=[]):
for i in range(env.nrow):
for j in range(env.ncol):
if (i * env.ncol + j) in disaster:
print('****', end=' ')
elif (i * env.ncol + j) in end:
print('EEEE', end=' ')
else:
a = agent.best_action(i * env.ncol + j)
pi_str = ''
for k in range(len(action_meaning)):
pi_str += action_meaning[k] if a[k] > 0 else 'o'
print(pi_str, end=' ')
print()
action_meaning = ['^', 'v', '<', '>']
print('Sarsa算法最终收敛得到的策略为:')
print_agent(agent, env, action_meaning, list(range(37, 47)), [47])
可以发现 Sarsa 算法会采取比较远离悬崖的策略来抵达目标。
50000的Sarsa算法最终收敛得到的策略为:
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo ovoo
^ooo ^ooo ^ooo ^ooo ooo> ^ooo ^ooo ^ooo ooo> ooo> ooo> ovoo
^ooo oo<o ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
5000的Sarsa算法最终收敛得到的策略为:
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo ooo> ooo> ovoo
^ooo ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ooo> ^ooo ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
500的Sarsa算法最终收敛得到的策略为:
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo ooo> ^ooo ooo> ooo> ooo> ooo> ^ooo ^ooo ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
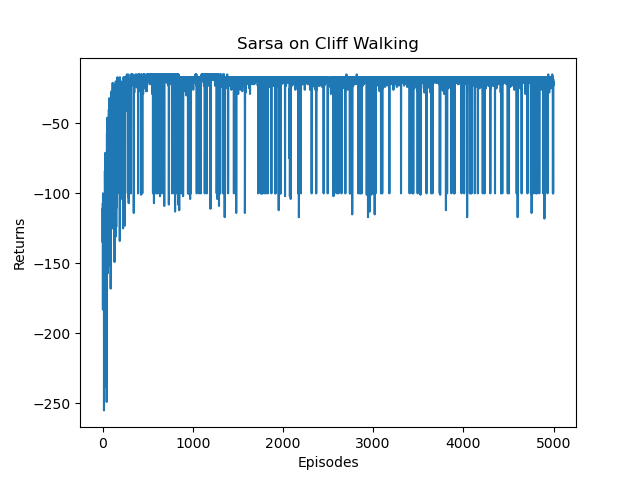
发现把epslion=0的话,结果竟然更好:
Iteration 0: 100%|██████████| 500/500 [00:00<00:00, 8748.05it/s, episode=500, return=-13.000]
Iteration 1: 100%|██████████| 500/500 [00:00<00:00, 10690.16it/s, episode=1000, return=-13.000]
Iteration 2: 100%|██████████| 500/500 [00:00<00:00, 11020.99it/s, episode=1500, return=-13.000]
Iteration 3: 100%|██████████| 500/500 [00:00<00:00, 10237.20it/s, episode=2000, return=-13.000]
Iteration 4: 100%|██████████| 500/500 [00:00<00:00, 10648.90it/s, episode=2500, return=-13.000]
Iteration 5: 100%|██████████| 500/500 [00:00<00:00, 10671.39it/s, episode=3000, return=-13.000]
Iteration 6: 100%|██████████| 500/500 [00:00<00:00, 11170.16it/s, episode=3500, return=-13.000]
Iteration 7: 100%|██████████| 500/500 [00:00<00:00, 10820.27it/s, episode=4000, return=-13.000]
Iteration 8: 100%|██████████| 500/500 [00:00<00:00, 10712.60it/s, episode=4500, return=-13.000]
Iteration 9: 100%|██████████| 500/500 [00:00<00:00, 10365.83it/s, episode=5000, return=-13.000]
Sarsa算法最终收敛得到的策略为:
^ooo ovoo ovoo ooo> ^ooo ooo> ooo> ^ooo ooo> ooo> ovoo ovoo
ooo> ooo> ^ooo ooo> ooo> ooo> ooo> ovoo ovoo ovoo ovoo ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
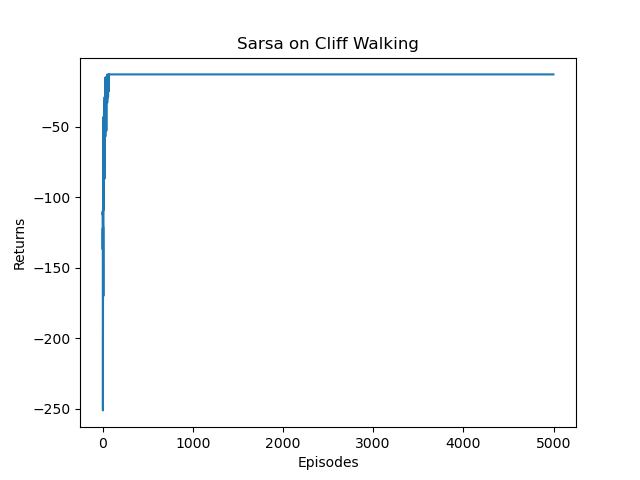
多步Sarsa算法
蒙特卡洛方法利用当前状态之后每一步的奖励而不使用任何价值估计,时序差分算法只利用一步奖励和下一个状态的价值估计。那它们之间的区别是什么呢?
总的来说,蒙特卡洛方法是无偏(unbiased)的,但是具有比较大的方差,因为每一步的状态转移都有不确定性,而每一步状态采取的动作所得到的不一样的奖励最终都会加起来,这会极大影响最终的价值估计;时序差分算法具有非常小的方差,因为只关注了一步状态转移,用到了一步的奖励,但是它是有偏的,因为用到了下一个状态的价值估计而不是其真实的价值。那有没有什么方法可以结合二者的优势呢?
答案是多步时序差分!多步时序差分的意思是使用步的奖励,然后使用之后状态的价值估计。
用公式表示,将
G
t
=
r
t
+
γ
Q
(
s
t
+
1
,
a
t
+
1
)
G_t=r_t+\gamma Q\left(s_{t+1}, a_{t+1}\right)
Gt=rt+γQ(st+1,at+1)
替换成
G
t
=
r
t
+
γ
r
t
+
1
+
⋯
+
γ
n
Q
(
s
t
+
n
,
a
t
+
n
)
G_t=r_t+\gamma r_{t+1}+\cdots+\gamma^n Q\left(s_{t+n}, a_{t+n}\right)
Gt=rt+γrt+1+⋯+γnQ(st+n,at+n)
于是,相应存在一种多步 Sarsa 算法,它把 Sarsa 算法中的动作价值函数的更新公式
Q
(
s
t
,
a
t
)
←
Q
(
s
t
,
a
t
)
+
α
[
r
t
+
γ
Q
(
s
t
+
1
,
a
t
+
1
)
−
Q
(
s
t
,
a
t
)
]
Q\left(s_t, a_t\right) \leftarrow Q\left(s_t, a_t\right)+\alpha\left[r_t+\gamma Q\left(s_{t+1}, a_{t+1}\right)-Q\left(s_t, a_t\right)\right]
Q(st,at)←Q(st,at)+α[rt+γQ(st+1,at+1)−Q(st,at)]
替换成
Q
(
s
t
,
a
t
)
←
Q
(
s
t
,
a
t
)
+
α
[
r
t
+
γ
r
t
+
1
+
⋯
+
γ
n
Q
(
s
t
+
n
,
a
t
+
n
)
−
Q
(
s
t
,
a
t
)
]
Q\left(s_t, a_t\right) \leftarrow Q\left(s_t, a_t\right)+\alpha\left[r_t+\gamma r_{t+1}+\cdots+\gamma^n Q\left(s_{t+n}, a_{t+n}\right)-Q\left(s_t, a_t\right)\right]
Q(st,at)←Q(st,at)+α[rt+γrt+1+⋯+γnQ(st+n,at+n)−Q(st,at)]
接下来用代码实现多步( n n n 步)Sarsa 算法。在 Sarsa 代码的基础上进行修改,引入多步时序差分算法。
class nstep_Sarsa:
""" n步Sarsa算法 """
def __init__(self, n, ncol, nrow, epsilon, alpha, gamma, n_action=4):
self.Q_table = np.zeros([nrow * ncol, n_action])
self.n_action = n_action
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon
self.n = n # 采用n步Sarsa算法
self.state_list = [] # 保存之前的状态
self.action_list = [] # 保存之前的动作
self.reward_list = [] # 保存之前的奖励
def take_action(self, state):
if np.random.random() < self.epsilon:
action = np.random.randint(self.n_action)
else:
action = np.argmax(self.Q_table[state])
return action
def best_action(self, state): # 用于打印策略
Q_max = np.max(self.Q_table[state])
a = [0 for _ in range(self.n_action)]
for i in range(self.n_action):
if self.Q_table[state, i] == Q_max:
a[i] = 1
return a
def update(self, s0, a0, r, s1, a1, done):
self.state_list.append(s0)
self.action_list.append(a0)
self.reward_list.append(r)
if len(self.state_list) == self.n: # 若保存的数据可以进行n步更新
G = self.Q_table[s1, a1] # 得到Q(s_{t+n}, a_{t+n})
for i in reversed(range(self.n)):
G = self.gamma * G + self.reward_list[i] # 不断向前计算每一步的回报
# 如果到达终止状态,最后几步虽然长度不够n步,也将其进行更新
if done and i > 0:
s = self.state_list[i]
a = self.action_list[i]
self.Q_table[s, a] += self.alpha * (G - self.Q_table[s, a])
s = self.state_list.pop(0) # 将需要更新的状态动作从列表中删除,下次不必更新
a = self.action_list.pop(0)
self.reward_list.pop(0)
# n步Sarsa的主要更新步骤
self.Q_table[s, a] += self.alpha * (G - self.Q_table[s, a])
if done: # 如果到达终止状态,即将开始下一条序列,则将列表全清空
self.state_list = []
self.action_list = []
self.reward_list = []
np.random.seed(0)
n_step = 5 # 5步Sarsa算法
alpha = 0.1
epsilon = 0.1
gamma = 0.9
agent = nstep_Sarsa(n_step, ncol, nrow, epsilon, alpha, gamma)
num_episodes = 500 # 智能体在环境中运行的序列的数量
return_list = [] # 记录每一条序列的回报
for i in range(10): # 显示10个进度条
#tqdm的进度条功能
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)): # 每个进度条的序列数
episode_return = 0
state = env.reset()
action = agent.take_action(state)
done = False
while not done:
next_state, reward, done = env.step(action)
next_action = agent.take_action(next_state)
episode_return += reward # 这里回报的计算不进行折扣因子衰减
agent.update(state, action, reward, next_state, next_action,
done)
state = next_state
action = next_action
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0: # 每10条序列打印一下这10条序列的平均回报
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('5-step Sarsa on {}'.format('Cliff Walking'))
plt.show()
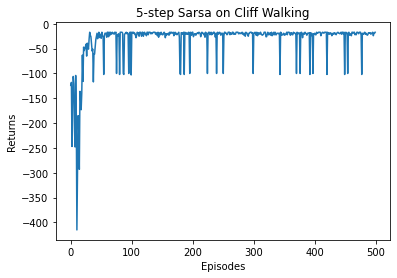
Iteration 0: 100%|████████████████████████████████████████| 50/50 [00:00<00:00, 781.85it/s, episode=50, return=-26.500]
Iteration 1: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2179.81it/s, episode=100, return=-35.200]
Iteration 2: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2179.02it/s, episode=150, return=-20.100]
Iteration 3: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2179.88it/s, episode=200, return=-27.200]
Iteration 4: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 1856.81it/s, episode=250, return=-19.300]
Iteration 5: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2088.82it/s, episode=300, return=-27.400]
Iteration 6: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2005.60it/s, episode=350, return=-28.000]
Iteration 7: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 1928.19it/s, episode=400, return=-36.500]
Iteration 8: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2179.54it/s, episode=450, return=-27.000]
Iteration 9: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2278.89it/s, episode=500, return=-19.100]
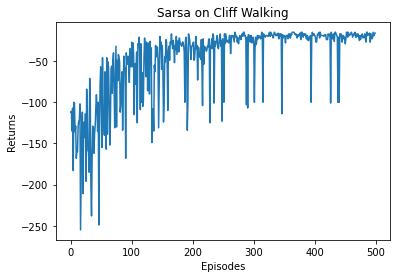 |  |
|---|
通过实验结果可以发现,5 步 Sarsa 算法的收敛速度比单步 Sarsa 算法更快。我们来看一下此时的策略表现。
action_meaning = ['^', 'v', '<', '>']
print('5步Sarsa算法最终收敛得到的策略为:')
print_agent(agent, env, action_meaning, list(range(37, 47)), [47])
5步Sarsa算法最终收敛得到的策略为:
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo ^ooo ^ooo oo<o ^ooo ^ooo ^ooo ^ooo ooo> ooo> ^ooo ovoo
ooo> ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ooo> ooo> ^ooo ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
此时多步 Sarsa 算法得到的策略会在最远离悬崖的一边行走,以保证最大的安全性。
Q-learning算法
除了 Sarsa,还有一种非常著名的基于时序差分算法的强化学习算法-Q-learning。Q-learning和 Sarsa 的最大区别在于 Q-learning 的时序差分更新方式为
Q
(
s
t
,
a
t
)
←
Q
(
s
t
,
a
t
)
+
α
[
R
t
+
γ
max
a
Q
(
s
t
+
1
,
a
)
−
Q
(
s
t
,
a
t
)
]
Q\left(s_t, a_t\right) \leftarrow Q\left(s_t, a_t\right)+\alpha\left[R_t+\gamma \max _a Q\left(s_{t+1}, a\right)-Q\left(s_t, a_t\right)\right]
Q(st,at)←Q(st,at)+α[Rt+γamaxQ(st+1,a)−Q(st,at)]
实际上,Q-Learning是在求解一个贝尔曼最优方程。Q-learning 算法的具体流程如下:
- 初始化 Q ( s , a ) Q(s, a) Q(s,a)
- for 序列
e
=
1
→
E
e=1 \rightarrow E
e=1→E do:
- 得到初始状态 s s s
- for 时间步
t
=
1
→
T
t=1 \rightarrow T
t=1→T do:
- 用 ϵ \epsilon ϵ-greedy 策略根据 Q Q Q 选择当前状态 s s s 下的动作 a a a
- 得到环境反馈的 r , s ′ r, s^{\prime} r,s′
- Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a)+\alpha\left[r+\gamma \max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime}\right)-Q(s, a)\right] Q(s,a)←Q(s,a)+α[r+γmaxa′Q(s′,a′)−Q(s,a)]
- s ← s ′ s \leftarrow s^{\prime} s←s′
- end for
- end for
用价值迭代的思想来理解 Q-learning,即 Q-learning 是直接在估计
Q
∗
Q^*
Q∗ ,因为动作价值函数的贝尔曼最优方程是
Q
∗
(
s
,
a
)
=
r
(
s
,
a
)
+
γ
∑
s
′
∈
S
P
(
s
′
∣
s
,
a
)
max
a
′
Q
∗
(
s
′
,
a
′
)
Q^*(s, a)=r(s, a)+\gamma \sum_{s^{\prime} \in \mathcal{S}} P\left(s^{\prime} \mid s, a\right) \max _{a^{\prime}} Q^*\left(s^{\prime}, a^{\prime}\right)
Q∗(s,a)=r(s,a)+γs′∈S∑P(s′∣s,a)a′maxQ∗(s′,a′)
而 Sarsa 估计当前 ϵ \epsilon ϵ-贪婪策略的动作价值函数。需要强调的是,Q-learning 的更新并非必须使用当前贪心策略 arg max a Q ( s , a ) \arg \max _a Q(s, a) argmaxaQ(s,a) 采样得到的数据,因为给定任意 ( s , a , r , s ′ ) \left(s, a, r, s^{\prime}\right) (s,a,r,s′) 都可以直接根据更新公式来更新 Q Q Q ,为充分探索环境,通常使用一个 ϵ \epsilon ϵ-贪婪策略来与环境交互。
Sarsa 必须使用当前
ϵ
\epsilon
ϵ-贪婪策略采样得到的数据,因为它的更新中用到的
Q
(
s
′
,
a
′
)
Q\left(s^{\prime}, a^{\prime}\right)
Q(s′,a′) 的
a
′
a^{\prime}
a′ 是当前策略在
s
′
s^{\prime}
s′ 下的动作。由上可知, Sarsa 是在线策略(on-policy)算法,称 Q-learning 是离线策略(off-policy)算法,这两个概念强化学习中非常重要。
在线策略算法与离线策略算法
我们称采样数据的策略为行为策略(behavior policy),称用这些数据来更新的策略为目标策略
(target policy)。
在线策略(on-policy)算法表示行为策略和目标策略是同一个策略;而离线策略(off-policy)算法表示行为策略和目标策略不是同一个策略。Sarsa 是典型的在线策略算法,而 Q-learning 是典型的离线策略算法。判断二者类别的一个重要手段是看计算时序差分的价值目标的数据是否来自当前的策略,如下图所示。
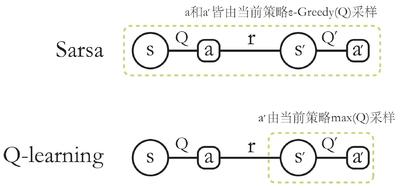
- 对于
Sarsa,它的更新公式必须使用来自当前策略采样得到的五元组 ( s , a , r , s ′ , a ′ ) \left(s, a, r, s^{\prime}, a^{\prime}\right) (s,a,r,s′,a′) ,因此它是在线策略学习方法; - 对于
Q-learning,它的更新公式使用的是四元组 ( s , a , r , s ′ ) \left(s, a, r, s^{\prime}\right) (s,a,r,s′) 来更新当前状态动作对的价值 Q ( s , a ) Q(s, a) Q(s,a) ,数据中的 s s s 和 a a a 是给定的条件, r r r 和 s ′ s^{\prime} s′ 皆由环境采样得到,该四元组并不需要一定是当前策略采样得到的数据,也可以来自行为策略,因此它是离线策略算法。
在本书之后的讲解中,我们会注明各个算法分别属于这两类中的哪一类。如前文所述,离线策略算法能够重复使用过往训练样本,往往具有更小的样本复杂度,也因此更受欢迎。
我们接下来仍然在悬崖漫步环境下来实现 Q-learning 算法。
class QLearning:
""" Q-learning算法 """
def __init__(self, ncol, nrow, epsilon, alpha, gamma, n_action=4):
self.Q_table = np.zeros([nrow * ncol, n_action]) # 初始化Q(s,a)表格
self.n_action = n_action # 动作个数
self.alpha = alpha # 学习率
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # epsilon-贪婪策略中的参数
def take_action(self, state): #选取下一步的操作
if np.random.random() < self.epsilon:
action = np.random.randint(self.n_action)
else:
action = np.argmax(self.Q_table[state])
return action
def best_action(self, state): # 用于打印策略
Q_max = np.max(self.Q_table[state])
a = [0 for _ in range(self.n_action)]
for i in range(self.n_action):
if self.Q_table[state, i] == Q_max:
a[i] = 1
return a
def update(self, s0, a0, r, s1):
td_error = r + self.gamma * self.Q_table[s1].max(
) - self.Q_table[s0, a0]
self.Q_table[s0, a0] += self.alpha * td_error
np.random.seed(0)
epsilon = 0.1
alpha = 0.1
gamma = 0.9
agent = QLearning(ncol, nrow, epsilon, alpha, gamma)
# 智能体在环境中运行的序列的数量
num_episodes = 500
# 记录每一条序列的回报
return_list = []
# 显示10个进度条
for i in range(10):
# tqdm的进度条功能
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
# 每个进度条的序列数
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done = env.step(action)
# 这里回报的计算不进行折扣因子衰减
episode_return += reward
agent.update(state, action, reward, next_state)
state = next_state
return_list.append(episode_return)
# 每10条序列打印一下这10条序列的平均回报
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Q-learning on {}'.format('Cliff Walking'))
plt.show()
action_meaning = ['^', 'v', '<', '>']
print('Q-learning算法最终收敛得到的策略为:')
print_agent(agent, env, action_meaning, list(range(37, 47)), [47])
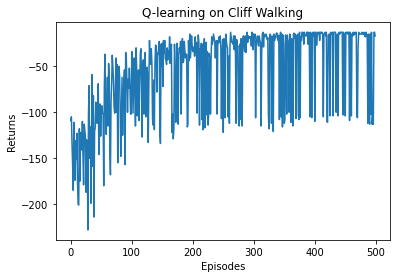
Iteration 0: 100%|███████████████████████████████████████| 50/50 [00:00<00:00, 759.53it/s, episode=50, return=-105.700]
Iteration 1: 100%|███████████████████████████████████████| 50/50 [00:00<00:00, 964.28it/s, episode=100, return=-70.900]
Iteration 2: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 1253.54it/s, episode=150, return=-56.500]
Iteration 3: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 1474.54it/s, episode=200, return=-46.500]
Iteration 4: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 1821.22it/s, episode=250, return=-40.800]
Iteration 5: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 1856.86it/s, episode=300, return=-20.400]
Iteration 6: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2089.23it/s, episode=350, return=-45.700]
Iteration 7: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2387.31it/s, episode=400, return=-32.800]
Iteration 8: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2506.76it/s, episode=450, return=-22.700]
Iteration 9: 100%|██████████████████████████████████████| 50/50 [00:00<00:00, 2638.76it/s, episode=500, return=-61.700]
Q-learning算法最终收敛得到的策略为:
^ooo ovoo ovoo ^ooo ^ooo ovoo ooo> ^ooo ^ooo ooo> ooo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ^ooo ooo> ooo> ooo> ooo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
需要注意的是,打印出来的回报是行为策略在环境中交互得到的,而不是 Q-learning 算法在学习的目标策略的真实回报。我们把目标策略的行为打印出来后,发现其更偏向于走在悬崖边上,这与 Sarsa 算法得到的比较保守的策略相比是更优的。
但是仔细观察 Sarsa 和 Q-learning 在训练过程中的回报曲线图,我们可以发现,在一个序列中 Sarsa 获得的期望回报是高于 Q-learning 的。这是因为在训练过程中智能体采取基于当前 Q ( s , a ) Q(s,a) Q(s,a)函数的-贪婪策略来平衡探索与利用,Q-learning 算法由于沿着悬崖边走,会以一定概率探索“掉入悬崖”这一动作,而 Sarsa 相对保守的路线使智能体几乎不可能掉入悬崖。
小结
本文介绍了无模型的强化学习中的一种非常重要的算法-时序差分算法。时序差分算法的核心思想是用对未来动作选择的价值估计来更新对当前动作选择的价值估计,这是强化学习中的核心思想之一。
本章重点讨论了 Sarsa 和 Q-learning 这两个最具有代表性的时序差分算法。当环境是有限状态集合和有限动作集合时,这两个算法非常好用,可以根据任务是否允许在线策略学习来决定使用哪一个算法。
值得注意的是,尽管离线策略学习可以让智能体基于经验回放池中的样本来学习,但需要保证智能体在学习的过程中可以不断和环境进行交互,将采样得到的最新的经验样本加入经验回放池中,从而使经验回放池中有一定数量的样本和当前智能体策略对应的数据分布保持很近的距离。如果不允许智能体在学习过程中和环境进行持续交互,而是完全基于一个给定的样本集来直接训练一个策略,这样的学习范式被称为离线强化学习(offline reinforcement learning),后续会介绍离线强化学习的相关知识。
参考资料
《动手学强化学习》



















 1442
1442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











