







目录
一、coco128-seg数据集分析
这个博客中有数据集下载网盘链接。
1、配置文件 coco128-seg.yaml
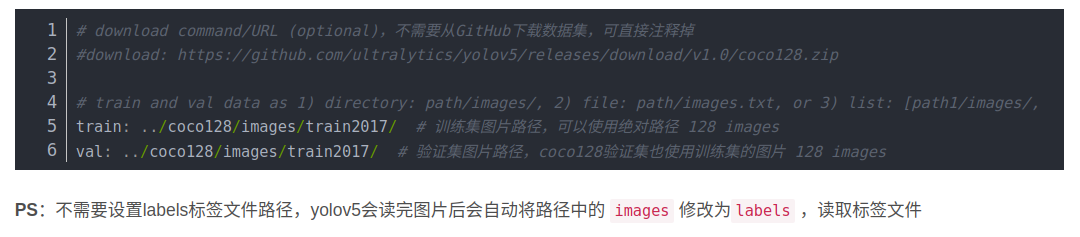
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# COCO128-seg dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: python train.py --data coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128-seg ← downloads here (7 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128-seg # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: person
1: bicycle
2: car
....
78: hair drier
79: toothbrush
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco128-seg.zip
这句话很重要:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
我选择2,即提供图片在的路径列表文件
2、coco128-seg数据集
数据集的结构
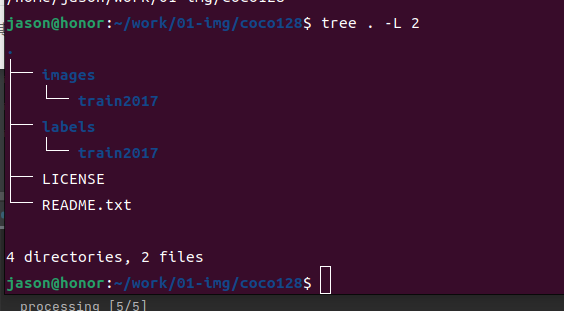
选择查看一个:如查看000000000030.jpg,与其对应的label的txt

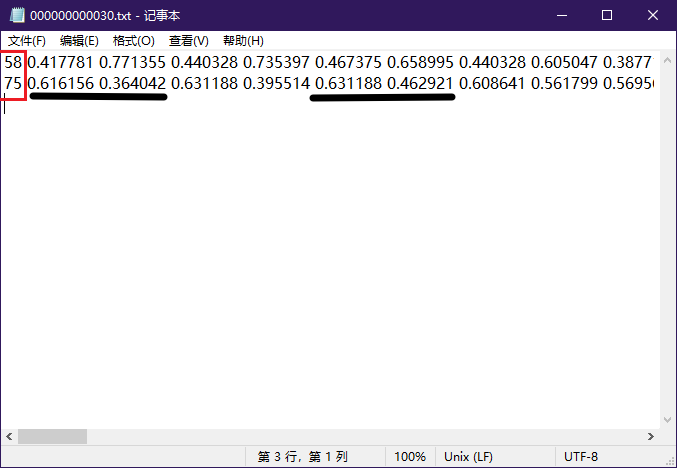
如图所示,txt中红色边框标注为label,75对应这yaml文件中的vase(花瓶),而黑色横线标记的就是一个坐标如(0.616156,0.364042),为了得到对应真实坐标,需要分别乘以宽和高,得到(0.616156*w,0.364042*h),即为标注的一个点;把后面坐标依次相连可的标注区域。
二、自己用anylabeling标注获得的json文件
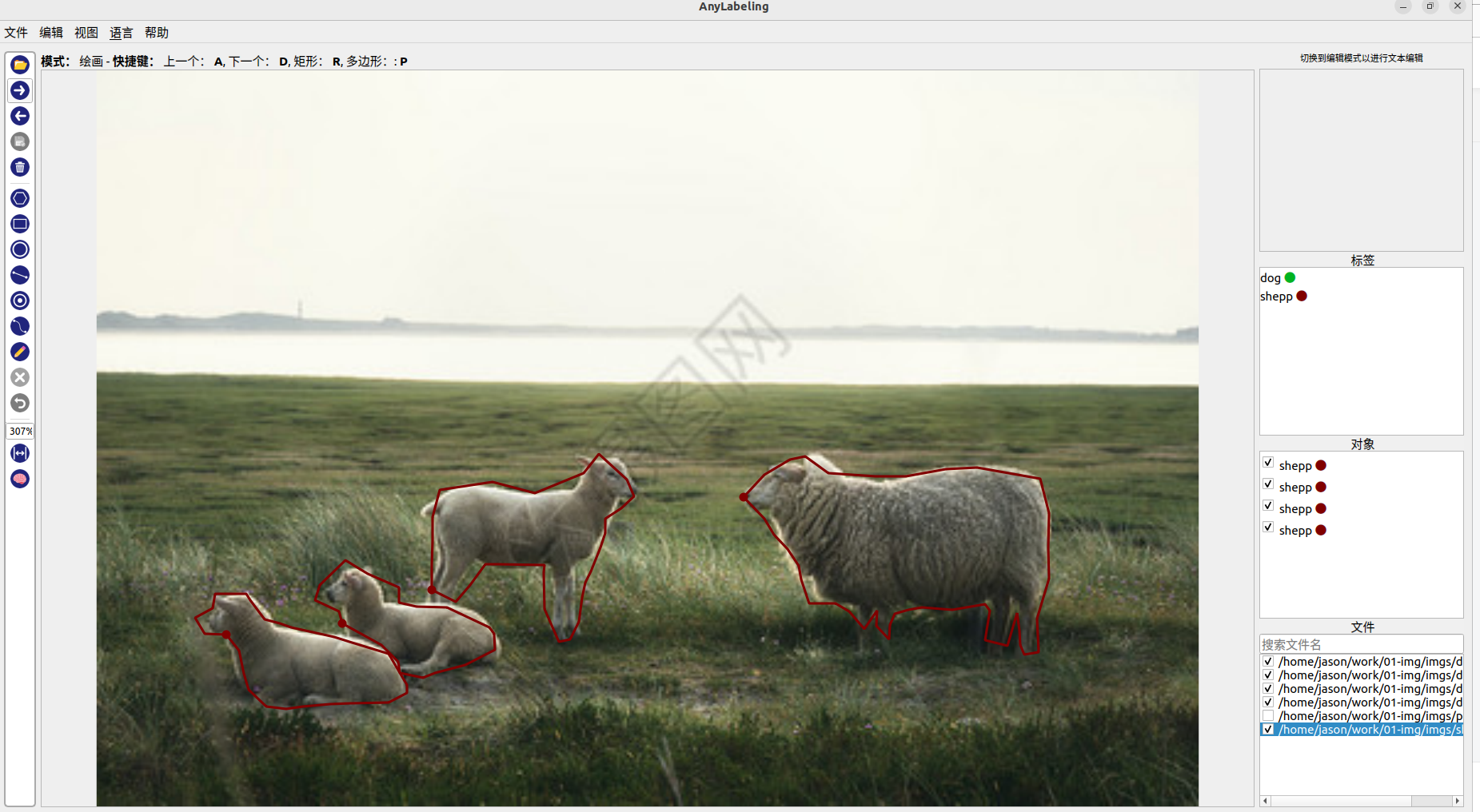
{
"version": "0.2.23",
"flags": {},
"shapes": [
{
"label": "sheep",
"text": "",
"points": [
[
52.83876221498372,
229.9674267100977
],
[
44.04397394136808,
229.6416938110749
],
[
58.05048859934854,
236.48208469055373
]
],
"group_id": null,
"shape_type": "polygon",
"flags": {}
},
{
"label": "sheep",
"text": "",
"points": [
[
100.0700325732899,
225.40716612377847
],
[
98.7671009771987,
220.52117263843647
],
[
88.99511400651465,
215.96091205211724
]
],
"group_id": null,
"shape_type": "polygon",
"flags": {}
},
{
"label": "sheep",
"text": "",
"points": [
[
136.55211726384363,
211.72638436482083
],
[
136.55211726384363,
201.62866449511398
],
[
136.87785016286645,
191.53094462540716
],
[
136.87785016286645,
182.0846905537459
]
],
"group_id": null,
"shape_type": "polygon",
"flags": {}
},
{
"label": "sheep",
"text": "",
"points": [
[
263.58794788273616,
173.94136807817588
],
[
272.057003257329,
164.82084690553745
],
[
282.4804560260586,
158.6319218241042
],
[
288.66938110749186,
157.32899022801303
]
],
"group_id": null,
"shape_type": "polygon",
"flags": {}
}
],
"imagePath": "sheep2.png",
"imageData": null,
"imageHeight": 300,
"imageWidth": 449
}三、json文件转coco128-seg格式
效果:
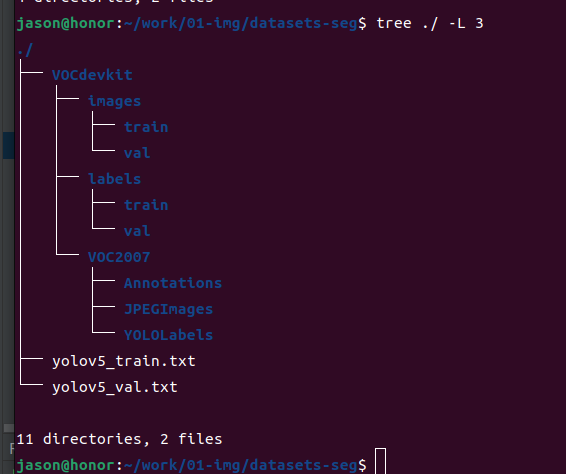
目录解释可以看之前写的博客:
VOC标签格式转yolo格式并划分训练集和测试集_爱钓鱼的歪猴的博客-CSDN博客
代码:
这里json文件和图片在同一目录哦
import json
import os
import shutil
import random
labels = ['person', 'bicycle', 'car', 'motorbike', 'aeroplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'sofa', 'pottedplant', 'bed', 'diningtable', 'toilet', 'tvmonitor', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
def generate_diretorys(wd):
data_base_dir = os.path.join(wd, "VOCdevkit/")
try:
shutil.rmtree(data_base_dir)
print("{} exist, will delete it".format(data_base_dir))
except:
print("{} does exist, does not need to delete!".format(data_base_dir))
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
os.mkdir(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
os.mkdir(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
os.mkdir(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
os.mkdir(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
os.mkdir(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
os.mkdir(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
os.mkdir(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
os.mkdir(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
os.mkdir(yolov5_labels_test_dir)
print("创建VOC数据集格式多级目录完成\n")
def convert(jsonfile, yoloPath):
"""
Args:
jsonfile: anylabeling标注的结果文件 ,需要转化成coco128-seg数据集标注文件格式
yoloPath:
Returns:
"""
assert os.path.exists(yoloPath), "'{}' does not exits".format(yoloPath)
assert os.path.isfile(jsonfile), "'{}' does not exits".format(jsonfile)
# 读取json标注文件
with open(jsonfile, 'r') as load_file:
load_dict = json.load(load_file)
# 准备yolo标注输出文件
fileName = jsonfile.split("/")[-1]
file_id, extension = os.path.splitext(fileName)
output_fileName = file_id + ".txt"
outputPath = os.path.join(yoloPath, output_fileName)
outputFile = open(outputPath, 'w')
# print("\r jason文件名字:%s" %fileName)
#json2yolo
height = load_dict["imageHeight"]
width = load_dict["imageWidth"]
for item in load_dict["shapes"]:
# print(item)
label_int = labels.index(item["label"])
row_str = ""
row_str += str(label_int)
if not item["points"]:
continue
for point in item["points"]:
x = round(float(point[0])/width, 6) #小数保留6位
y = round(float(point[1])/height, 6) #小数保留6位
row_str += " " + str(x) + " " + str(y)
row_str+="\n"
outputFile.write(row_str)
outputFile.close()
def json2yolo(inputPath, output_path, val_ratio):
"""
Args:
inputPath: json标注文件与图片所在的目录
output_path: 输出目录,会在该目录下生成VOC数据集格式多级目录
val_ratio: 验证集占比
Returns:
"""
#
assert os.path.exists(inputPath), "'{}' does not exist".format(inputPath)
assert os.path.exists(output_path), "'{}' does not exist".format(output_path)
generate_diretorys(wd=output_path)
wd = output_path
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
val_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
val_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
val_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
# 检查图片与标签文件一一对应
raw_files = os.listdir(inputPath)
json_files = [] # jason文件完整路径
img_files = [] # 图片文件完整路径
for file in raw_files:
fileName, extension = os.path.splitext(file)
if extension in ['jpg','jpeg','ico','tiff', '.png','.bmp']:
json_file = fileName + ".json"
json_path = os.path.join(inputPath, json_file)
if os.path.exists(json_path):
img_path = os.path.join(inputPath,file)
json_files.append(json_path)
img_files.append(img_path)
another_img_path = os.path.join(wd,"VOCdevkit","VOC2007","JPEGImages")
another_jason_path = os.path.join(wd,"VOCdevkit","VOC2007","Annotations")
shutil.copy(json_path, another_jason_path)
shutil.copy(img_path, another_img_path)
num = len(json_files)
random.seed(0)
eval_json_files = random.sample(json_files, k=int(num*val_ratio))
i = 0
for json_path in json_files:
another_yolo_path = os.path.join(wd,"VOCdevkit","VOC2007","YOLOLabels")
json_file_names_info = json_path.split("/")[-1]
json_file_name_id, ext= os.path.splitext(json_file_names_info)
yolo_file_name = json_file_name_id + ".txt"
index = json_files.index(json_path)
img_file_path = img_files[index]
img_file_name = img_file_path.split("/")[-1]
# print("\r json_file_name_id:{} yolo_file_name :{}".format(json_file_name_id,yolo_file_name))
if json_path in eval_json_files:
index = json_files.index(json_path)
img_path = img_files[index]
val_img_path = os.path.join(wd,"VOCdevkit","images","val")
val_json_path = os.path.join(wd,"VOCdevkit","labels","val")
yolo_file = os.path.join(val_json_path, yolo_file_name)
convert(jsonfile=json_path, yoloPath=val_json_path)
shutil.copy(img_path, val_img_path)
shutil.copy(yolo_file, another_yolo_path)
val_file.write(os.path.join(val_img_path, img_file_name) + '\n')
else:
index = json_files.index(json_path)
img_path = img_files[index]
train_img_path = os.path.join(wd,"VOCdevkit","images","train")
train_json_path = os.path.join(wd,"VOCdevkit","labels","train")
yolo_file = os.path.join(train_json_path, yolo_file_name)
convert(jsonfile=json_path, yoloPath=train_json_path)
shutil.copy(img_path, train_img_path)
shutil.copy(yolo_file, another_yolo_path)
train_file.write(os.path.join(train_img_path, img_file_name) + '\n')
i+=1
print("\r processing [{}/{}]".format(i, num), end="")
if __name__ == "__main__":
outputdir = "/home/jason/work/01-img/datasets-seg"
inputdir = "/home/jason/work/01-img/imgs"
json2yolo(inputPath=inputdir, output_path=outputdir, val_ratio=0.5)这份代码其实就是把之前写的博客,目标检测json转yolo代码中的convert函数修改了一下
四、实例分割训练
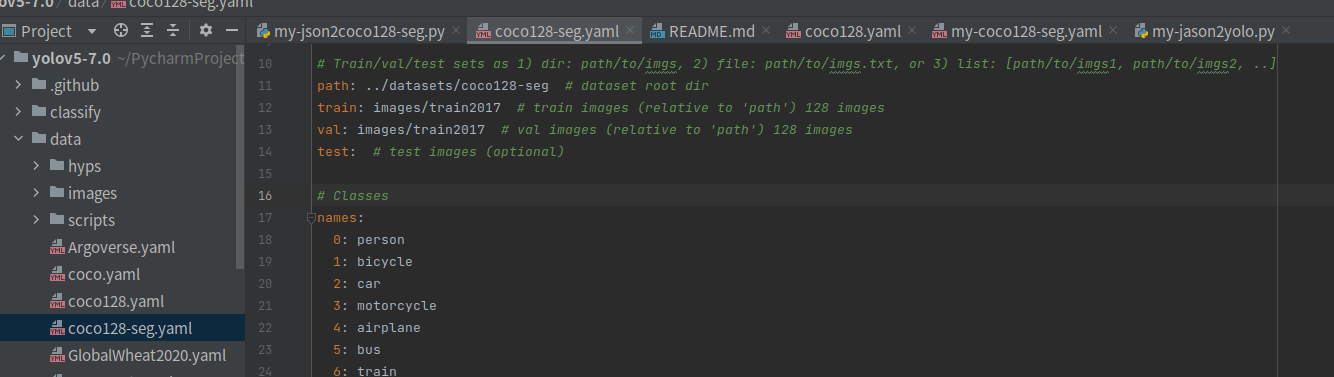
1、修改数据配置文件 coco128-seg.yaml
首先修改数据路径
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/jason/work/01-img/datasets-seg # dataset root dir
train: yolov5_train.txt # train images (relative to 'path') 128 images
val: yolov5_val.txt # val images (relative to 'path') 128 images
test: # test images (optional)
也可这样:
也就是修改成这样:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/jason/work/01-img/datasets-seg/VOCdevkit # dataset root dir
train: VOCdevkit/images/train # train images (relative to 'path') 128 images
val: VOCdevkit/images/val # val images (relative to 'path') 128 images
test: # test images (optional)另外coco128-seg.yaml文件中的类别信息,也要根据需要做修改,我这里不用动,因为我在转格式的时候类别列表用的就是coco 80 类别
2、训练
在项目下执行
python segment/train.py --data my-coco128-seg.yaml --weights yolov5n-seg.pt --img 640 --batch-size 16 --epochs 1 --device cpu输出:
(yolo) jason@honor:~/PycharmProjects/pytorch_learn/yolo/yolov5-7.0$ python segment/train.py --data my-coco128-seg.yaml --weights yolov5n-seg.pt --img 640 --batch-size 16 --epochs 1
segment/train: weights=yolov5n-seg.pt, cfg=, data=my-coco128-seg.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=1, batch_size=16, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train-seg, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, mask_ratio=4, no_overlap=False
github: skipping check (not a git repository), for updates see https://github.com/ultralytics/yolov5
requirements: YOLOv5 requirement "tensorboard>=2.4.1" not found, attempting AutoUpdate...
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ReadTimeoutError("HTTPSConnectionPool(host='pypi.org', port=443): Read timed out. (read timeout=15)")': /simple/google-auth/
^CERROR: Operation cancelled by user
YOLOv5 🚀 2022-11-22 Python-3.8.13 torch-2.0.0+cu117 CPU
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
TensorBoard: Start with 'tensorboard --logdir runs/train-seg', view at http://localhost:6006/
from n params module arguments
0 -1 1 1760 models.common.Conv [3, 16, 6, 2, 2]
1 -1 1 4672 models.common.Conv [16, 32, 3, 2]
2 -1 1 4800 models.common.C3 [32, 32, 1]
3 -1 1 18560 models.common.Conv [32, 64, 3, 2]
4 -1 2 29184 models.common.C3 [64, 64, 2]
5 -1 1 73984 models.common.Conv [64, 128, 3, 2]
6 -1 3 156928 models.common.C3 [128, 128, 3]
7 -1 1 295424 models.common.Conv [128, 256, 3, 2]
8 -1 1 296448 models.common.C3 [256, 256, 1]
9 -1 1 164608 models.common.SPPF [256, 256, 5]
10 -1 1 33024 models.common.Conv [256, 128, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 90880 models.common.C3 [256, 128, 1, False]
14 -1 1 8320 models.common.Conv [128, 64, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 22912 models.common.C3 [128, 64, 1, False]
18 -1 1 36992 models.common.Conv [64, 64, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 74496 models.common.C3 [128, 128, 1, False]
21 -1 1 147712 models.common.Conv [128, 128, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 296448 models.common.C3 [256, 256, 1, False]
24 [17, 20, 23] 1 234397 models.yolo.Segment [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], 32, 64, [64, 128, 256]]
Model summary: 225 layers, 1991549 parameters, 1991549 gradients, 7.2 GFLOPs
Transferred 367/367 items from yolov5n-seg.pt
optimizer: SGD(lr=0.01) with parameter groups 60 weight(decay=0.0), 63 weight(decay=0.0005), 63 bias
train: Scanning /home/jason/work/01-img/datasets-seg/yolov5_train... 2 images, 0 backgrounds, 0 corrupt: 100%|██████████| 2/2 00:00
train: New cache created: /home/jason/work/01-img/datasets-seg/yolov5_train.cache
val: Scanning /home/jason/work/01-img/datasets-seg/yolov5_val... 2 images, 0 backgrounds, 0 corrupt: 100%|██████████| 2/2 00:00
val: New cache created: /home/jason/work/01-img/datasets-seg/yolov5_val.cache
AutoAnchor: 2.50 anchors/target, 1.000 Best Possible Recall (BPR). Current anchors are a good fit to dataset ✅
Plotting labels to runs/train-seg/exp/labels.jpg...
Image sizes 640 train, 640 val
Using 2 dataloader workers
Logging results to runs/train-seg/exp
Starting training for 1 epochs...
Epoch GPU_mem box_loss seg_loss obj_loss cls_loss Instances Size
0/0 0G 0.01272 0.02035 0.02096 0.09775 6 640: 100%|██████████| 1/1 00:01
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 1/1 00:00
all 2 4 1 0.957 0.995 0.768 1 0.957 0.995 0.778
1 epochs completed in 0.000 hours.
Optimizer stripped from runs/train-seg/exp/weights/last.pt, 4.3MB
Optimizer stripped from runs/train-seg/exp/weights/best.pt, 4.3MB
Validating runs/train-seg/exp/weights/best.pt...
Fusing layers...
Model summary: 165 layers, 1986637 parameters, 0 gradients, 7.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 1/1 00:00
all 2 4 1 0.958 0.995 0.768 1 0.958 0.995 0.778
dog 2 4 1 0.958 0.995 0.768 1 0.958 0.995 0.778
Results saved to runs/train-seg/exp
至此,yolov5 实例分割训练记录完毕
如有帮助,不妨点个赞哦!
本文第一部分摘抄自第一篇参考博客,仅作笔记,无疑冒犯
参考:
coco128-seg数据集分析_coco128数据集_犟小孩的博客-CSDN博客
coco128数据集网盘分享 yolov5使用coco128完成第一次训练_coco128下载_GreenHand_Zhao的博客-CSDN博客


















 5509
5509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









