







三维目标检测算法
One-stage目标检测算法概述
1、什么是One-stage
直接回归物体的类别概率和位置坐标值(无region proposal),但准确度低,速度相遇two-stage快。

](https://i-blog.csdnimg.cn/blog_migrate/532d916dc588df3ec22d8c267aef4def.png)
目前常用的典型的One-stage目标检测网络
YOLOv1、YOLOv2、YOLOv3
SSD、DSSD等
Retina-Net等
Two-stage目标检测方法概述
对于Two-stage的目标检测网络,主要通过一个卷积神经网络来完成目标检测过程,其提取的是CNN卷积特征,在训练网络时,其主要训练两个部分,第一步是训练RPN网络,第二步是训练目标区域检测的网络。网络的准确度高、速度相对One-stage慢。
wo-stage算法的代表R.Girshick et al等人在2014年提出的R-CNN到Faster R-CNN网络。
Two-stage目标检测网络的基本流程

流程分析
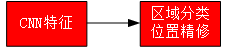
首先输入一张图片,接着经过卷积神经网络,通过卷积神经网络对图片进行深度特征的提取,这个卷积神经网络称之为主干网络,典型的主干网络有VGGNet、ResNet 、Zenet等一些经典的卷积神经网络结构;接着通过RPN网络来进行候选区域产生的操作,同时也会完成区域的分类,即将图片分为背景和目标这样两种的不同的类别,并且也会对目标的位置进行初步的预测。
RoI是Region of Interest的简写,是指对一张图片的“感兴趣区域”,用于RCNN系列算法当中,输入图片在经过卷积网络得到feature maps后,利用选择搜索或者RPN算法来得到多个目标候选框,这些以输入图片为参考坐标的候选框在feature maps上的映射区域,即为目标检测中所说的RoI
接下来对候选区域中的位置进行精确定位和修正,使用Roi_pooling层,可以将此层理解为抠图的操作,接着将抠图所得到的候选目标对应到特征图(feature map)上相应的特征区域,然后经过一个全连接层(fc),并得到相应的特征向量,最后通过分类和回归这样两个分支,来实现对这个候选目标类别的判定和目标位置的确定(也就是最后矩形框的四个点的坐标,(x,y,w,h):(x,y)为左上角顶点的坐标,w,h是矩形框的长和宽)。

1.基于局部特征的目标识别
基于局部特征的物体识别方法主要是通过局部来识别整体。该方法无需对处理数据进行分割,往往通过提取物体的关键点、边缘或者面片等局部特征并进行比对来完成物体的识别。其中,特征提取是物体识别中非常关键的一步,它将直接影响到物体识别系统的性能。基于局部特征的方式对噪声和遮挡有更好的鲁棒性,同时不受颜色和纹理信息缺乏的限制。由于局部特征描述子仅使用参考点邻域信息,所以不对场景进行分割即可处理复杂场景。但是局部特征描述子维度较高,需要消耗更多的内存,同时存在计算复杂度高,实时性差等问题。
点特征直方图(PFH)和快速点特征直方图(FPFH)是Rusu R B等人提出的相对早期的局部特征描述子。采用统计临近点对夹角的方式构造特征描述子,这也是局部特征描述子构造的典型方式,在此基础上形成了基于局部特征匹配的目标识别和位姿估计的经典框架,如下图所示。表1对典型的局部三维描述符进行了总结,并对不同方法的性能进行了比较。
2.基于全局特征的目标识别方法
基于全局特征的方法需要从背景中将目标物体分割出来,通过描述和比对三维物体形状中的全部或者最显著的几何特征来完成物体的识别,这类方法被广泛地应用于3D物体的表示匹配和分类中。全局特征将视角作为一个特征,建立多视角下的2.5D 模型特征库,目标识别结果和位姿由这些模板给出,基于全局特征的识别框架如图所示。这种方式的缺陷是需要对场景进行分割,分割的好坏会直接影响识别定位的结果。

3.基于激光雷达点云的3D目标检测算法
1.基于鸟瞰图(Bird-Eye-View)的方法:
此类方法将点云投射到鸟瞰图上,利用BEV图生成proposal区域进而结合多个模态RGB/Front-View点云进行3D bbox的预测. 其中代表性的方法有MV3D[1] 和AVOD[2]。
2.基于Voxel Grid的方法:
基于体素的方法将整个场景的点云转换为体素网格(Voxel Grid),并使用3D CNN作为backbone进行proposal和后续物体bbox回归和分类。由于3D卷积由于多了一个深度/时间通道的存储和计算成本很高,以最基本的kernel size为例 3D (3x3x3) 参数量是2D (3x3) 的三倍, 在三维空间中进行卷积操作的扫描窗口数相比二维卷积也多了很多,所以通常基于3D卷积的方法计算成本通常相当高。目前基于Voxel的检测/分割方法有3D-FCN[4] 和SparseConv[5]等
3.基于原始点云的方法:
说到直接基于点云的方法就不得不提PointNet[8]和PointNet++[9], 点云数据具有一些显著的特点——数据点无序性、数据点数量可变性等,无序就表示网络必须能够在改变数据点顺序的情况下输出相同的结果,数量可变就表示网络必须能够处理不同数量的采样点。
1、End-to-End Multi-View Fusion for 3D Object Detection in Lidar Point Clouds(Waymo和Google联合提出)
2.LaserNet: An Efficient Probabilistic 3D Object Detector for Autonomous Driving(Uber提出, CVPR2019)
3.BirdNet: a 3D Object Detection Framework from LiDAR information
4、LMNet: Real-time Multiclass Object Detection on CPU using 3D LiDAR(英特尔提出)
5、PIXOR: Real-time 3D Object Detection from Point Clouds(Uber和多伦多大学提出)
6、PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud(香港大学提出,CVPR2019)
7、YOLO3D: End-to-end real-time 3D Oriented Object Bounding Box Detection from LiDAR Point Cloud
8、FVNet: 3D Front-View Proposal Generation for Real-Time Object Detection from Point Clouds(上海交大&腾讯优图)
物体分类和定位

目标检测解决的核心问题
1.目标可能出现在图像的任何位置。
2.目标有各种不同的大小。
3.目标可能有各种不同的形状。
如果用矩形框来定义目标,则矩形有不同的宽高比。由于目标的宽高比不同,因此采用经典的滑动窗口+图像缩放的方案解决通用目标检测问题的成本太高。
目标检测的指标IoU
交并比(IoU, Intersection-over-Union),是一种测量在特定数据集中检测相应物体准确度的一个标准。IOU表示了产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率或者说重叠度,也就是它们的交集与并集的比值。相关度越高该值。最理想情况是完全重叠,即比值为1。

参考文章:https://zhuanlan.zhihu.com/p/78758569?utm_source=qq&utm_medium=social&utm_oi=994376702662836224















 2135
2135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









