






多GPU卡训练/预测使用指定GPU
Pytorch下使用指定GPU:
比如想用2,3,4,5号卡
os.environ["CUDA_VISIBLE_DEVICES"] = "2,3,4,5,6,7,0,1"
torch.nn.DataParallel(MODEL, device_ids=[0,1,2,3])
MODEL为你的模型,device_ids=[0,1,2,3]可以填写单个或多个。
例如想用2号卡
os.environ["CUDA_VISIBLE_DEVICES"] = "2,3,4,5,6,7,0,1"
torch.nn.DataParallel(MODEL, device_ids=[0])
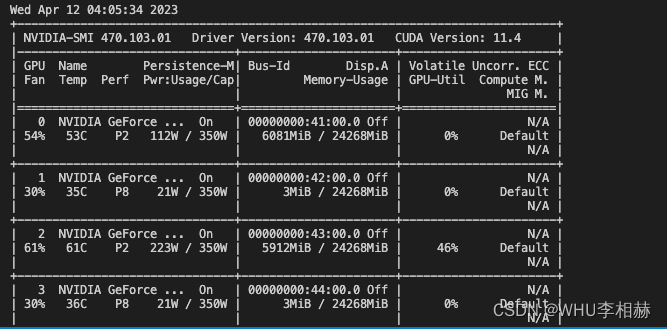
成功只使用2号















 3384
3384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











