









[2022]李宏毅深度学习与机器学习第十二讲(必修)-Reinforcement Learning RL
做笔记的目的
1、监督自己把50多个小时的视频看下去,所以每看一部分内容做一下笔记,我认为这是比较有意义的一件事情。
2、路漫漫其修远兮,学习是不断重复和积累的过程。怕自己看完视频不及时做笔记,学习效果不好,因此想着做笔记,提高学习效果。
3、因为刚刚入门深度学习,听课的过程中,理解难免有偏差,也希望各位大佬指正。
What is RL
当标注很困难的时候,或者我们也不知道什么是正确答案的时候(但是知道什么是好的什么是不好的),我们可以用RL。
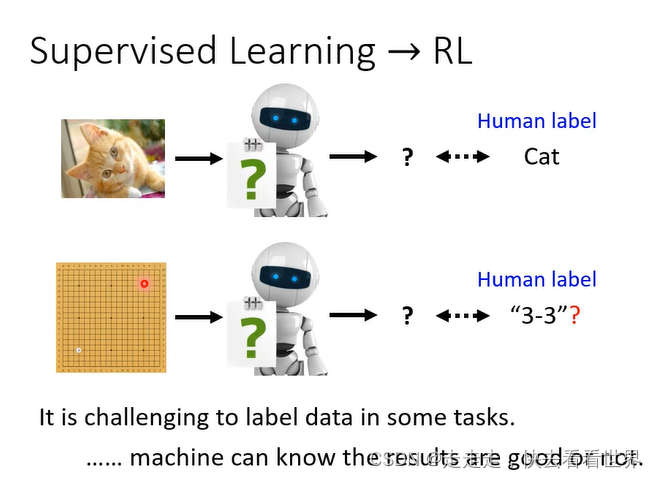
RL虽然和普通的网络有很大的差别,但是也是找一个function、定义损失,优化。RL的架构大体如下图。actor做一步,然后环境给出reward同时给机器observation。
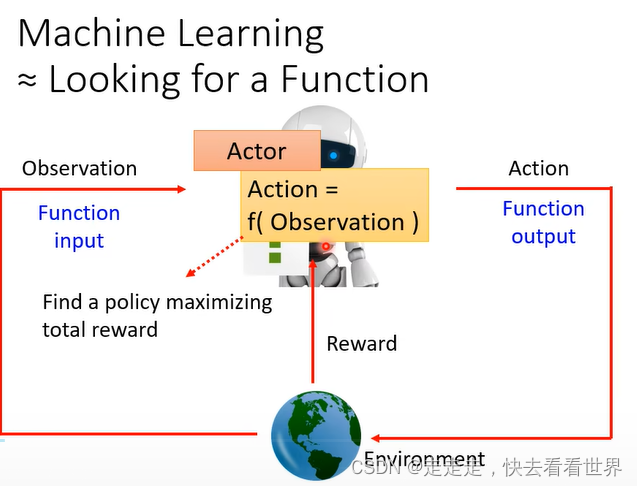
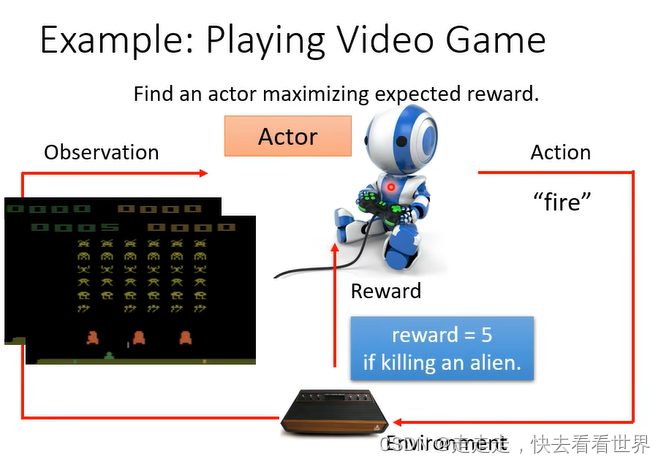
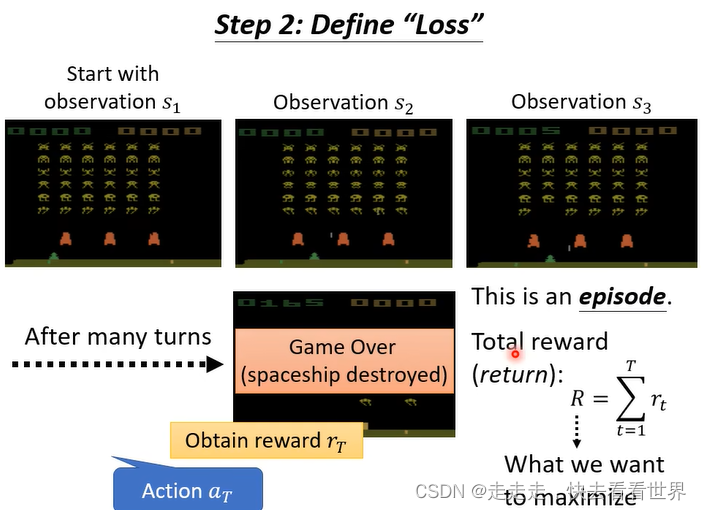
具体来说就是让分数总和最大。
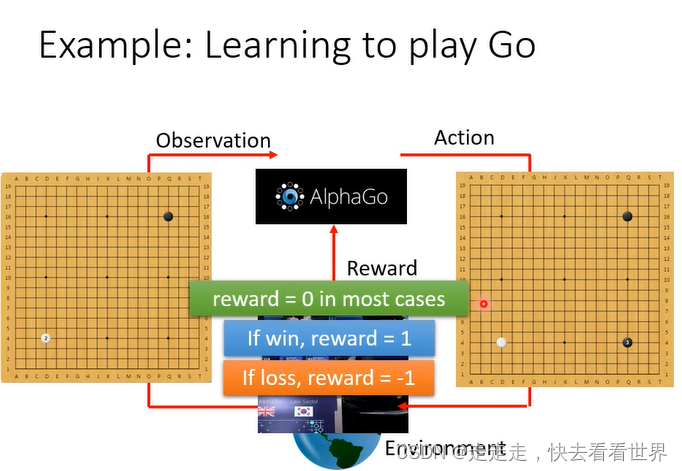
在下围棋中就是赢一局reward+1,否则-1
步骤如下图:
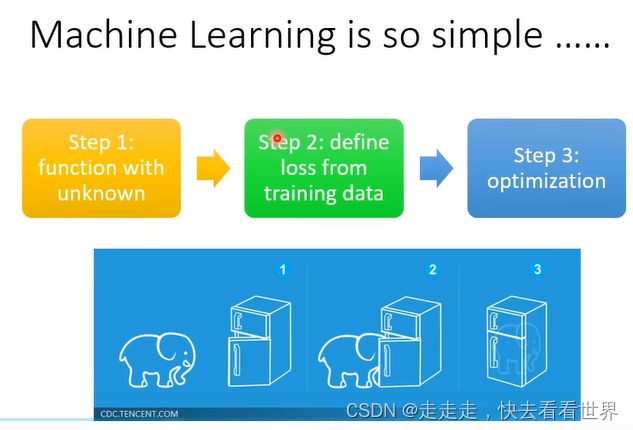
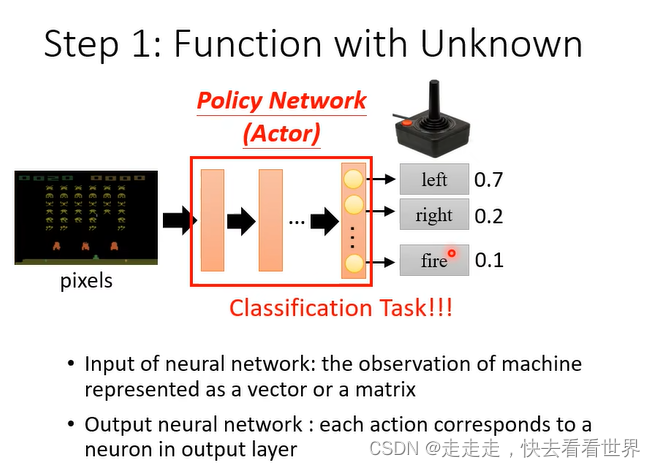
第一步找到一个Function,相当于一个普通的分类器。RL大部分都是采取sample,这种随机性在游戏里面是比较重要的。
定义损失,也就是让reward最大。
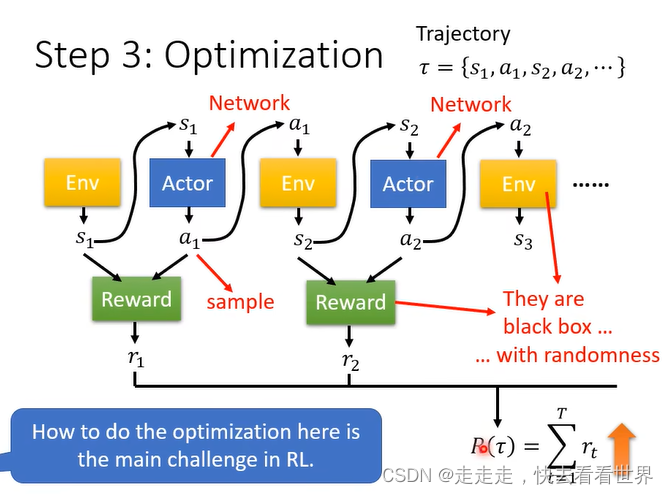
进行优化找打最大的R,但是训练起来应该比较困难,因为这个network输出每次不一样、Env不是一个network是一个黑盒子同时也具有随机性、reward是一个规则也不是一个network,好像不能用普通的随机梯度下降来做。
Policy Gradient
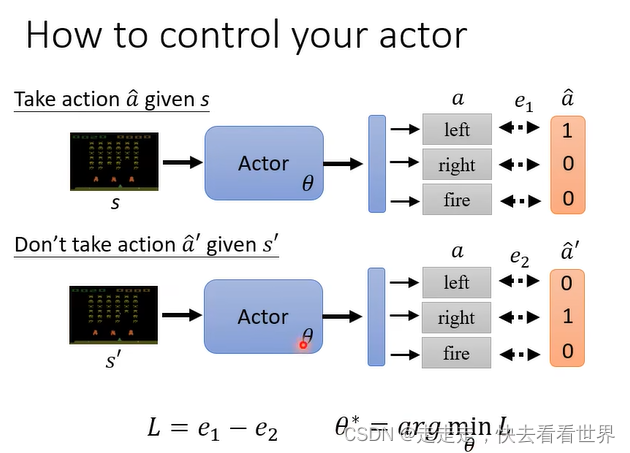
有一点像监督学习,定义做有利则大于0,做没有好处就小于0,所以我们就需要Training Data来做模型的训练。那么如何产生Traing Data那,重点在于如何定于A。
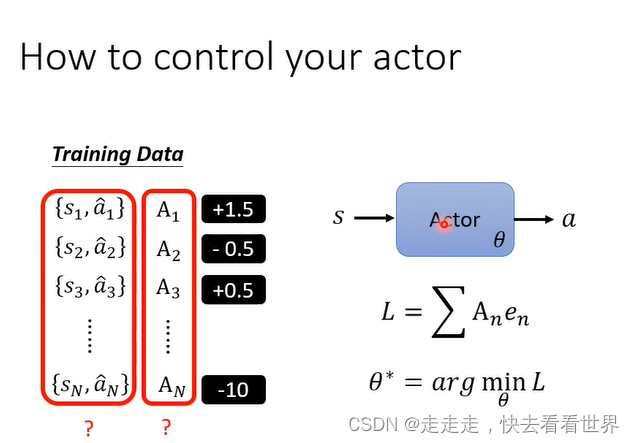
Version 1
将未来的reward加起来衡量这一步的好坏,但是设计到一个问题,如果游戏很长,那么
r
n
r_n
rn不一定依赖于
a
1
a_1
a1。

Version 2
在前面乘以一个
γ
<
1
\gamma<1
γ<1这样远距离就影响小了。但是这个可能应该也需要归一化的操作,不然有些太大有些太小。

Version 3
这里涉及到一个问题就是如何衡量b。

之后就可以去用梯度下降的方法去做了,主要是如何设计A。

每次更新一次之后资料就要重新收集,这样非常合理,所以RL非常的耗时。
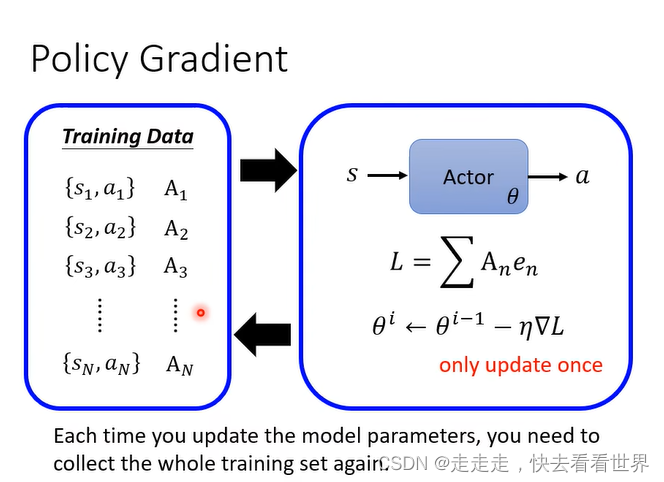
我们也有一些方法可以收集一次资料更新好几次,技术是PPO。

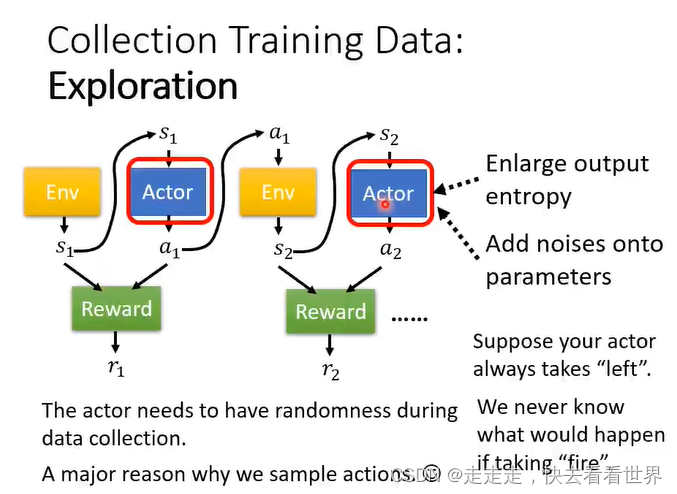
整个过程需要随机性,不然一些action可能从来没有执行过,Exploration也是一个比较重要的步骤。
Actor-Critic
Critic评价actor的好坏,未卜先知,Value function 直接预测动作的奖励,但如如何训练出来那?
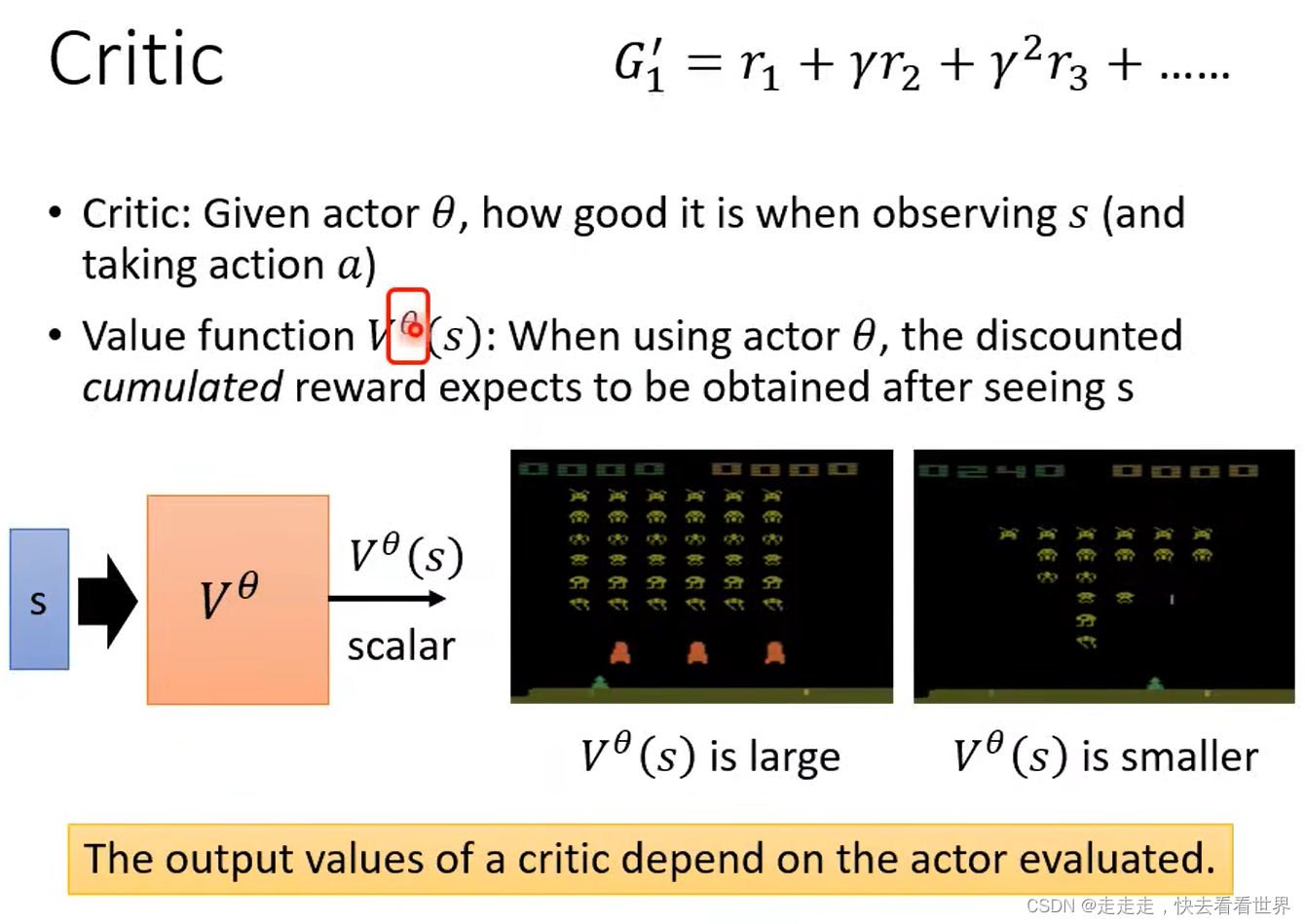
也是玩游戏,然后进行数据收集之后在训练。有MC和TD两种方法。MC的方法是上一部分Version 3 的计算公式。TD是计算公式更加巧妙如下面的第二个图。
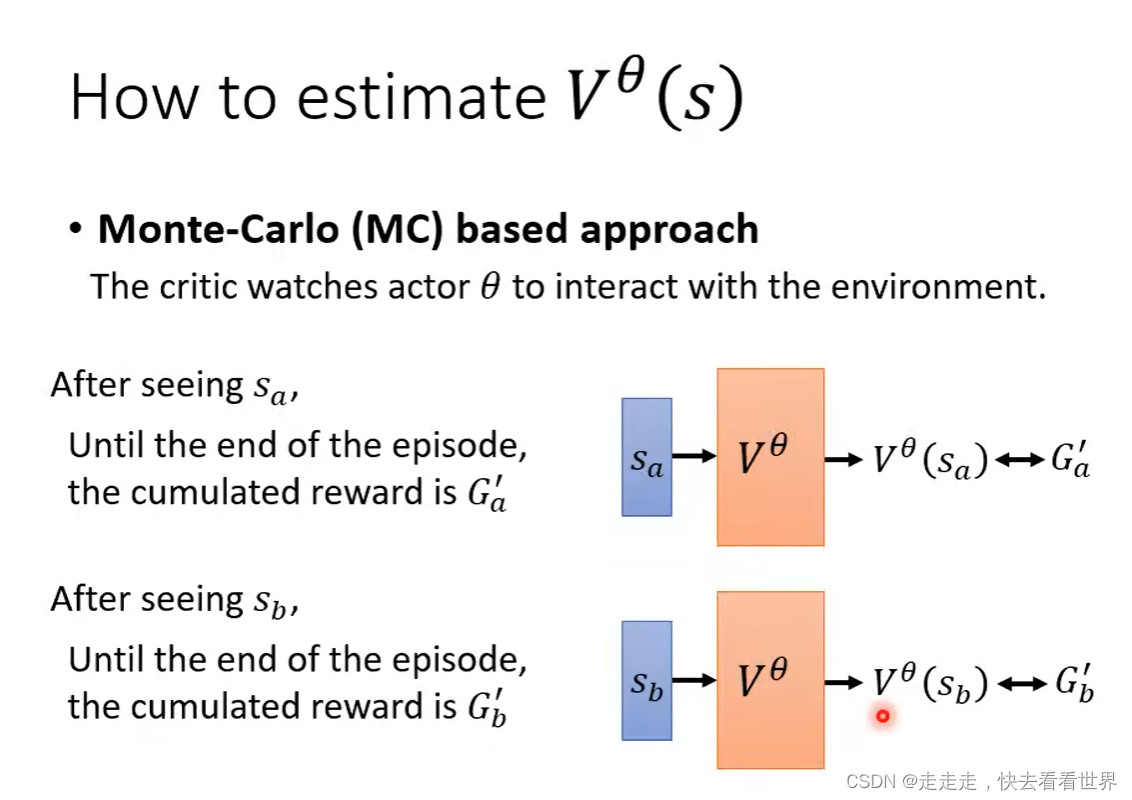

虽然两个计算的有差异但是都是对的。

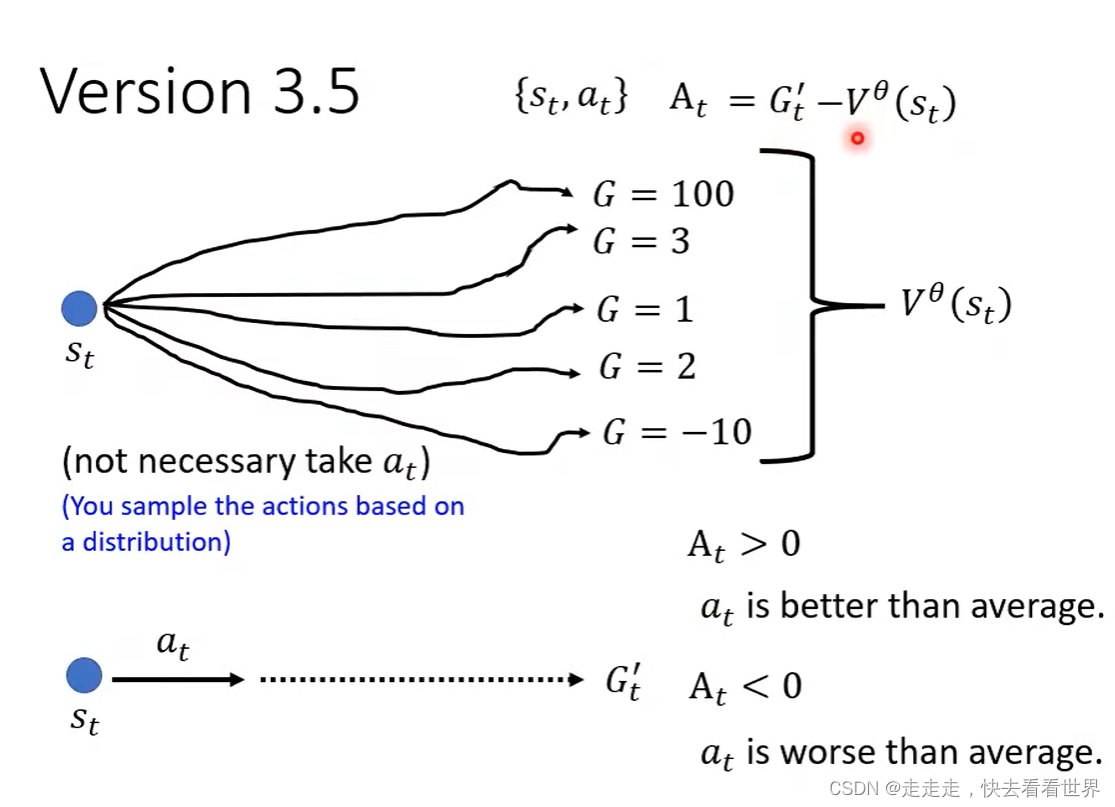
Version 3.5

为什么减掉V是合理的那?因为这样能衡量进行这一步所比随机走一步要好(坏)多少。
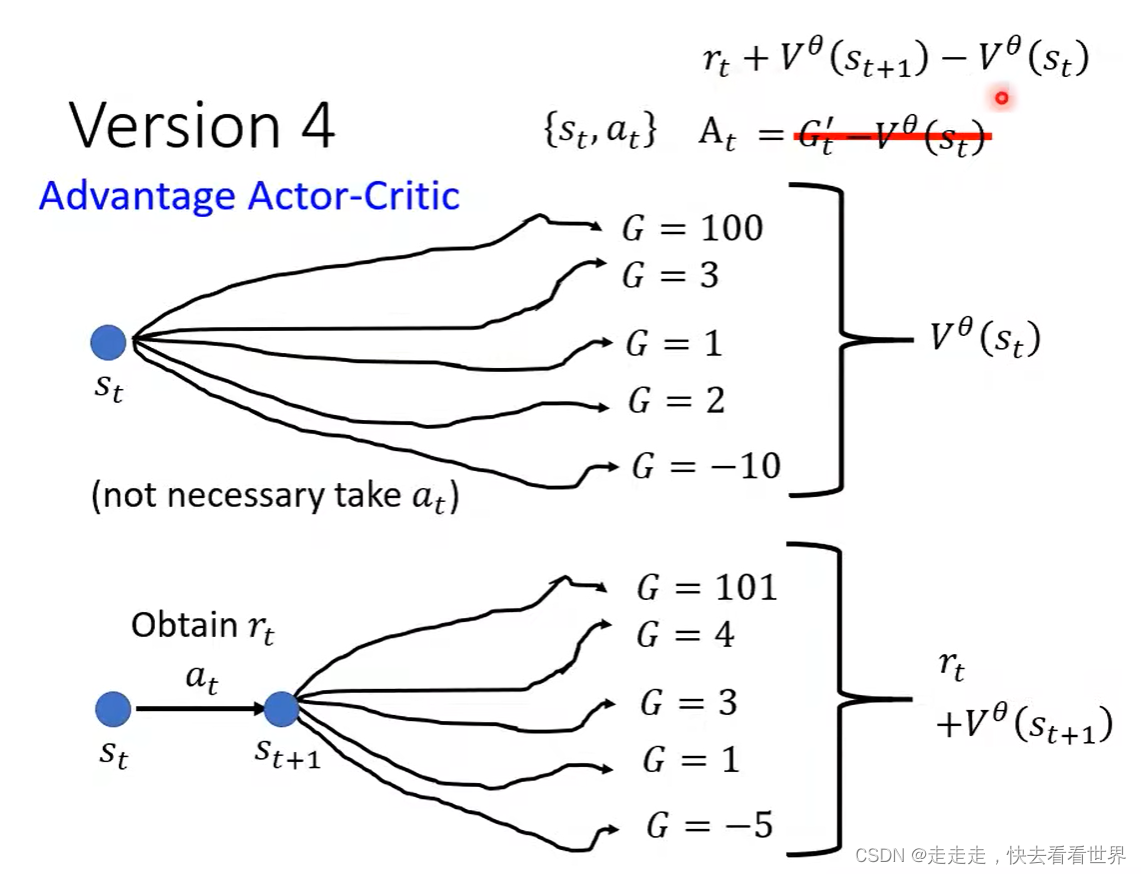
Version 4
可以看公式就是,进行当前这一步,比随机走一步要好多少,设计的非常合理。
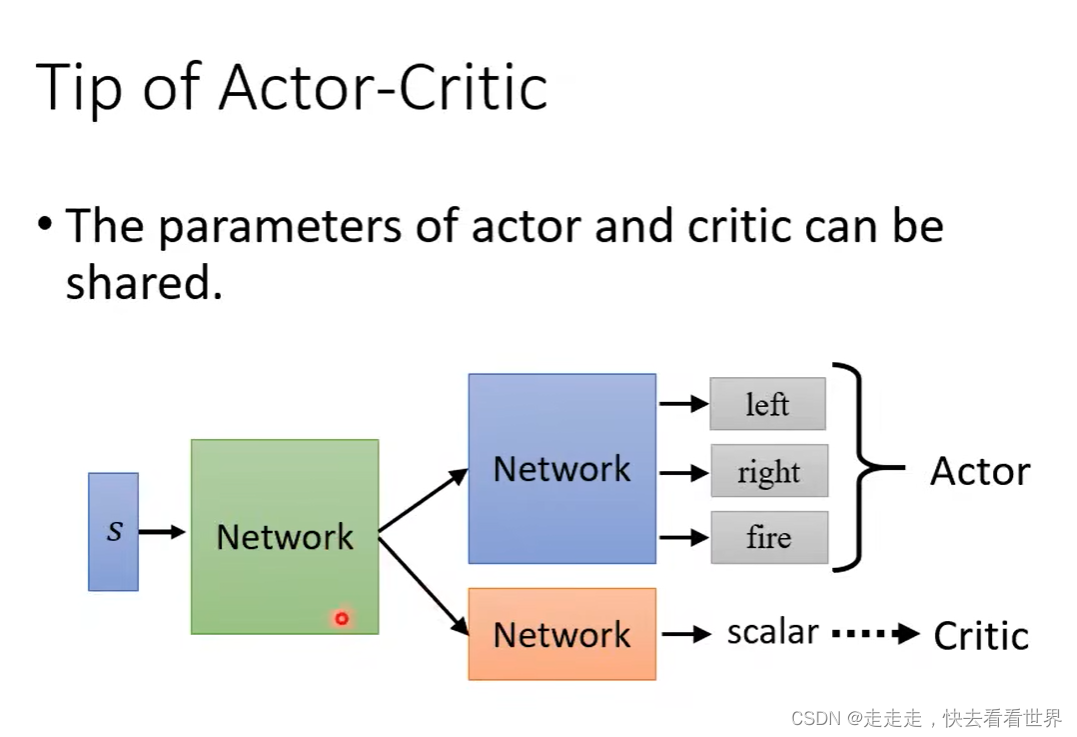
Tip of actor-Critic
可以共用一些Network。
Reward Shaping
有很多任务,可能获得奖励需要很长时间,甚至获得不了奖励。这个时候我们可能就需要自己设计一些规则。
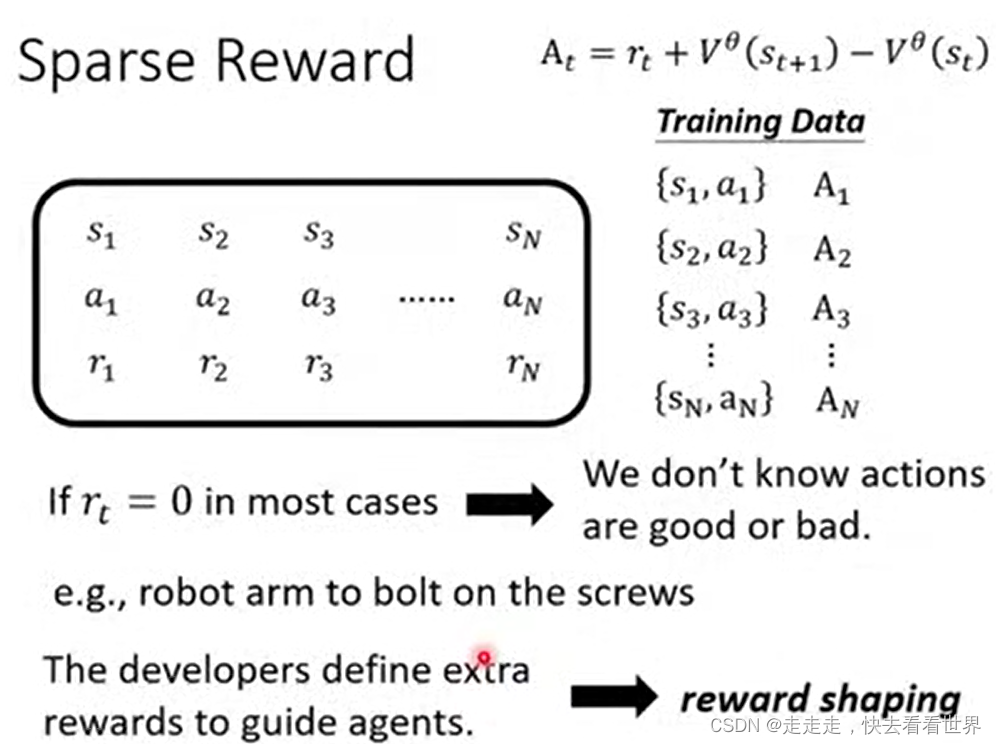
就像是下面的游戏,我们人为的自己设计一些规则。但是Reward Shaping要我们自己对游戏有理解


我是我们也需要考虑好奇心,遇到一些新的事物,这个新要有意思。

No Reward
reward设计的不合理,机器人可能有神逻辑,同时人定的reward可能并不是最好的。

找到一个expert的示范,来学习。
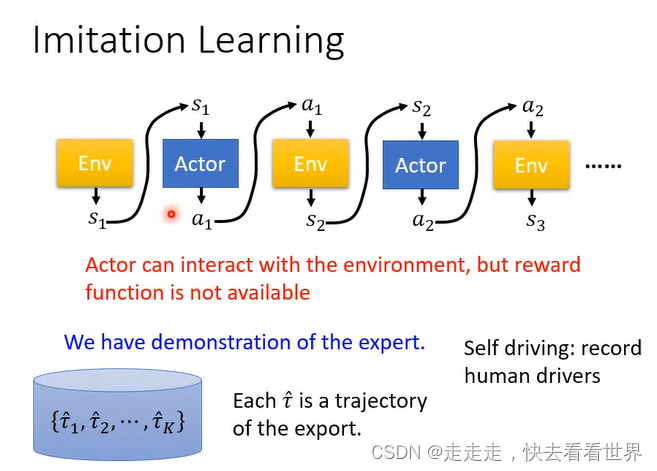
我们并不能把他看成监督学习来做,因为机器人可能遇不到特殊情况,同时有些行为可能不需要模仿,如果这样机器的能力可能是有限的。
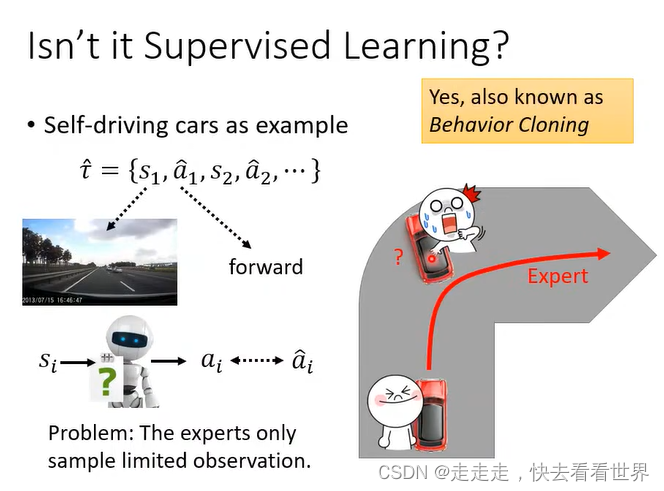
本来不知道reward function,通过expert来反推,简单的reward 不一定会导致简单的actor。
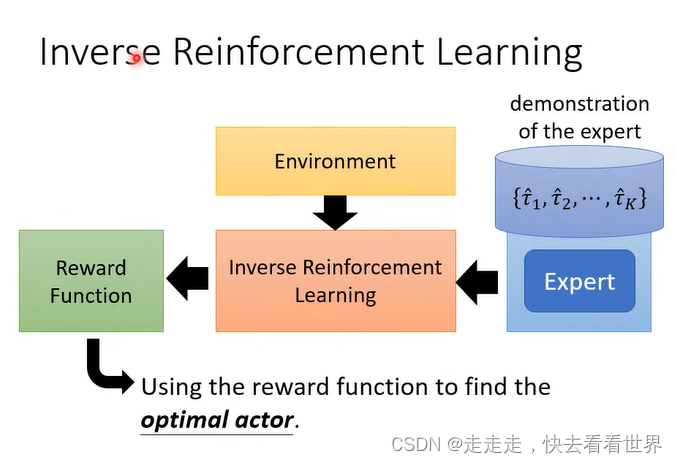
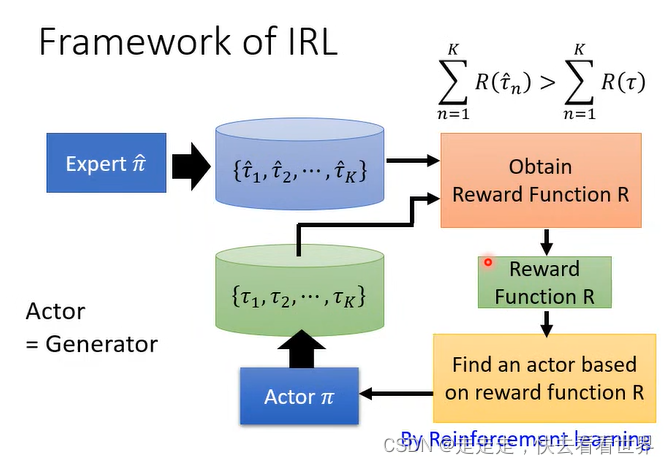
IRL的步骤如下

这就很像GAN,IRL经常用来训练机械手臂。















 2777
2777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









