







文章目录
论文阅读 Implementation of precise interrupts in pipelined processors
摘要
Precise Interrupt:如果保存的进程状态与程序执行的顺序模型(其中一条指令在下一条指令开始之前完成)相对应,则中断是精确的。
在流水线处理器中,精确的中断是很难实现的,因为一条指令可能在前面指令完成之前就被启动。本文讨论了五种解决方案。
研究背景与目的
大多数当前的计算机体系结构都基于程序执行的顺序模型,也就是说,软件看到的CPU是以顺序的方式执行程序的,即只有完成一条指令后,才会开始执行下一条指令。但是硬件实现可能是流水线的,即某个时刻会有多条指令处于流水线的不同阶段。当中断发生时,顺序模型和硬件流水线之间的差异就可能会导致一些问题,比如说在软件看来,发生中断时,进程现场的寄存器是不会被当前指令之后的指令修改的,但是由于硬件流水化,实际上之后的指令可能正在执行并且修改了寄存器,因此硬件在保存进程现场时,不能直接将当前的寄存器进行保存,因为此时的寄存器值和软件看来的寄存器值可能不一样。
- 进程状态主要包括PC,系统寄存器,用户寄存器和存储等,一般来说,进程现场的保存需要软件和硬件协同完成。
- Precise Interrupt其实就是说,硬件和软件在协同保存进程现场时,必须保证保存的现场和软件看到的进程现场是一样的(由于流水线的存在,中断发生时,硬件的寄存器等实际的值和软件看到的可能不一样)
准确来说,精确中断需要满足以下条件:
- 已保存的PC指向的指令之前的所有指令均已执行并且已正确修改进程状态
- 已保存的PC指向的指令之后的所有指令均未执行,并且未修改进程状态
- 如果中断是由程序中的指令引发的异常条件引起的,则保存的程序计数器指向被中断的指令。被中断的指令可能已执行,也可能未执行,具体取决于体系结构的定义和中断的原因。无论哪种情况,被中断的指令要么已完成,要么尚未开始执行。
本文描述并比较了在流水线处理器中实现精确中断的方法。简单的方法强制所有指令按照指令顺序来更新进程状态。其他更复杂的方法则保存部分进程状态,以便在发生中断时硬件可以恢复正确的状态。
Preliminaries
之后的讨论基于以下几个假设:
- no operand cache.
- condition codes are not used
模型架构如下所示:

不精确中断的示例:在一条浮点加法指令后紧跟着一条整数加法指令,整数加法指令可能会在浮点指令之前完成并修改程序状态(寄存器),但是可能浮点指令的溢出异常还没有被检测,也就是可能溢出异常发生时,整数指令已经修改了寄存器,因此会导致不精确中断。
狭义上来说,中断是外部导致的,异常是指令本身导致的。
类似于上面的架构,存在一个指令发射部件,用于完成取指、译码和指令发射。如果认为恰好要发射的指令就是软件看到的PC指向的指令,对于中断,硬件可以认为被中断的指令就是恰好要发射的指令,此时只要停止发射,并执行完所有已发射的指令即可;对于可以在取指译码阶段检测出来的异常,比如说特权指令错误和未实现的指令,也可以采取类似的方式来解决
论文后面只考虑指令发出后检测到异常的情况,并且指令发射都是顺序发射的,且指令执行过程中的异常都是统一在结果总线上进行检查。
In-order Instruction Completion
使用这个方法,只有已知所有已发射的指令不会出现异常情况时,指令才会修改进程状态。换句话说,当一条指令要结束时,要么它前面的指令都已经完成了,要么可以确定前面未完成的指令不会发生异常。
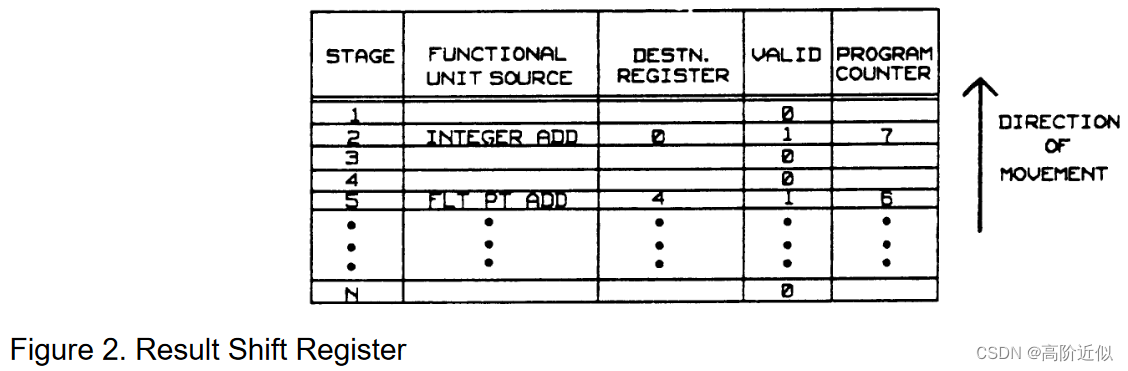
无论是否实现精确中断,都可以通过一个 result shift register来控制结果总线,如下图所示。需要执行
i
i
i 个时钟周期的指令在发射时保留在结果移位寄存器的第
i
i
i 级。如果第
i
i
i 级的VALID位为1,则将发射保留到下一个时钟周期,并再次检查第
i
i
i 级。指令发射时会将控制信息放入结果移位寄存器中。在每个时钟周期,控制信息向第一级上移一级。当到达第一级时,它在下一个时钟时会用于控制结果总线,从而将对应指令的结果写回正确的寄存器。
假设浮点加法的功能单元需要6个周期完成计算,整数加法需要2个周期,因此浮点加法和整数加法分别放置在阶段6和阶段2中。下图展示了整数加法发射后结果移位寄存器的状态。需要注意的是,浮点加法此时处于阶段5,因为从浮点加法发射以来已经过去了一个时钟周期。
寄存器
采取的方法是:假设当前要发射的指令需要执行 j j j 个周期(即应该保留在Stage j j j)中,在将该指令保留在Stage j j j 中时,控制逻辑需要“保留”(即写入空控制信息)所有级数小于 j j j 且没有指令保留的Stages,也就是说,在指令保留在Stage j j j 中后,Stage 1到Stage (j-1)中空闲的Stage都不能再存入其他指令。
结果总线上有逻辑会在指令完成时检查指令中的异常情况。如果指令包含非屏蔽异常条件,则控制逻辑会“取消”结果总线上的所有后续指令,以便它们不会修改进程状态。
一个改进方法是,如果可以在指令完成之前确定指令是否存在异常条件,那么仅需要保留在检测到异常之前完成的结果移位寄存器阶段(除了控制结果的阶段之外)。比如说,一条指令需要计算5个周期,假设可以在第2个周期检测到是否有异常,那么只需要保留Stage1和Stage2即可,Stage3和Stage4不需要保留(可以提高性能),如果没有异常发生,正常执行即可,如果有异常发生,只需要增加控制逻辑使得Stage3和Stage4中在该指令之后的指令不会写回寄存器即可(比如可以使用空控制信息覆盖)
主存
- 方案一:强制store指令在发出之前等待结果移位寄存器为空。
- 方案二:store指令可以发出并保存在访存流水线中,在已知所有前面的指令都没有异常后,才可以写内存。与上面类似,store指令发出时也需要保留对应的Stage以及该Stage之前所有的Stages。如果前面的指令没有异常,store指令的控制信息才会到达stage1。在到达stage1时,所有先前的指令均已完成,无异常,可以向访存流水线发送信号从而写内存。如果store指令本身包含异常,则该指令被取消,所有之后的load/store指令被取消,并且存储单元向流水线控制发出信号,使得在store指令之后发出的所有指令被取消。
PC
当带有异常条件的指令出现在结果总线上时,其结果移位寄存器中的PC值即为保存的PC。
The Reorder Buffer
In-order Instruction Completion 的缺点在于,后面的快速指令可能被停留在发射寄存器中无法发射,尽管可能并不存在依赖;并且后面本可以发射出去的更慢的指令也会由于前面的快指令占据了发射寄存器而无法发射。
解决上述问题的一个方法是,允许指令乱序完成,但是在指令改变进程状态前使用一个叫做 reorder buffer 的缓冲来对指令重排序。
基本方法
该方法的总体结构如下所示
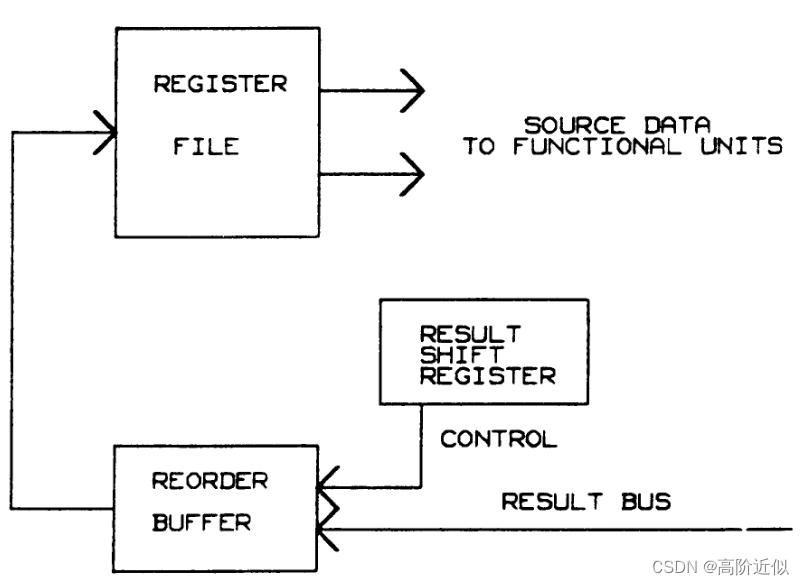
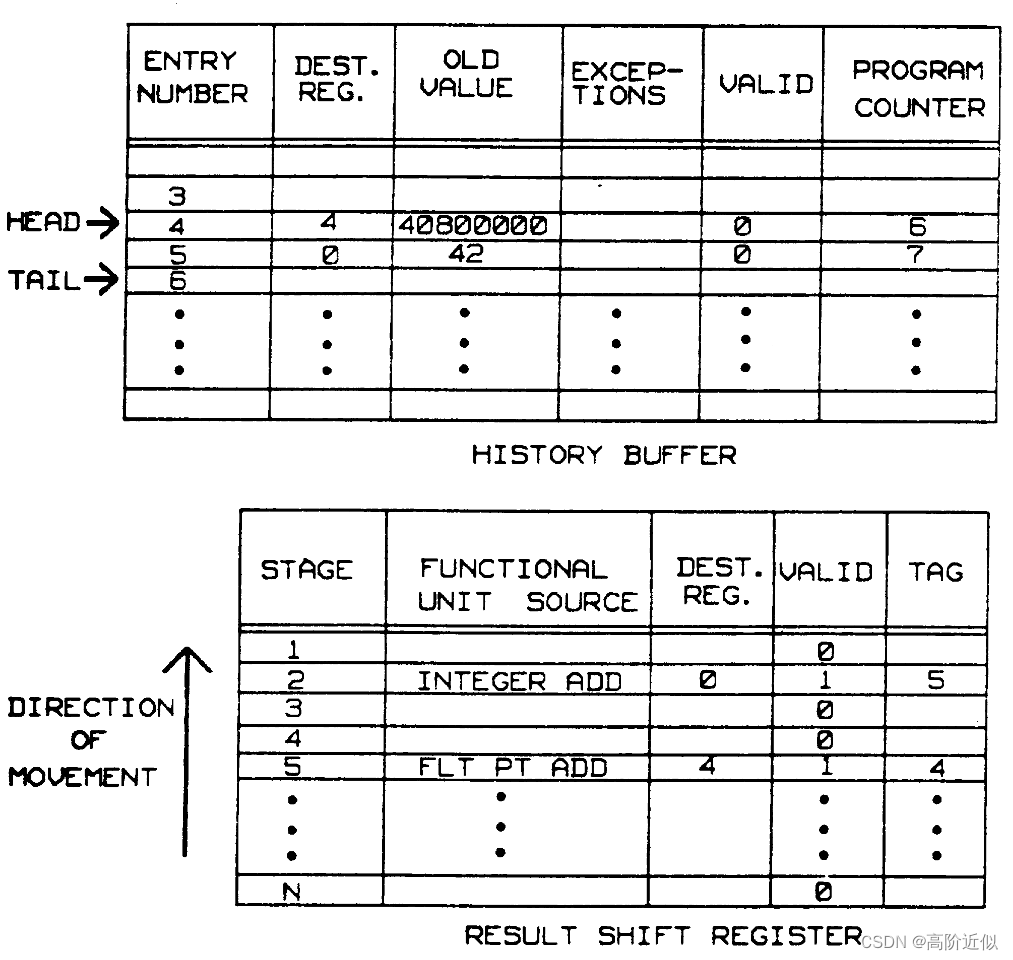
重排序缓冲和结果移位寄存器的结构如下所示
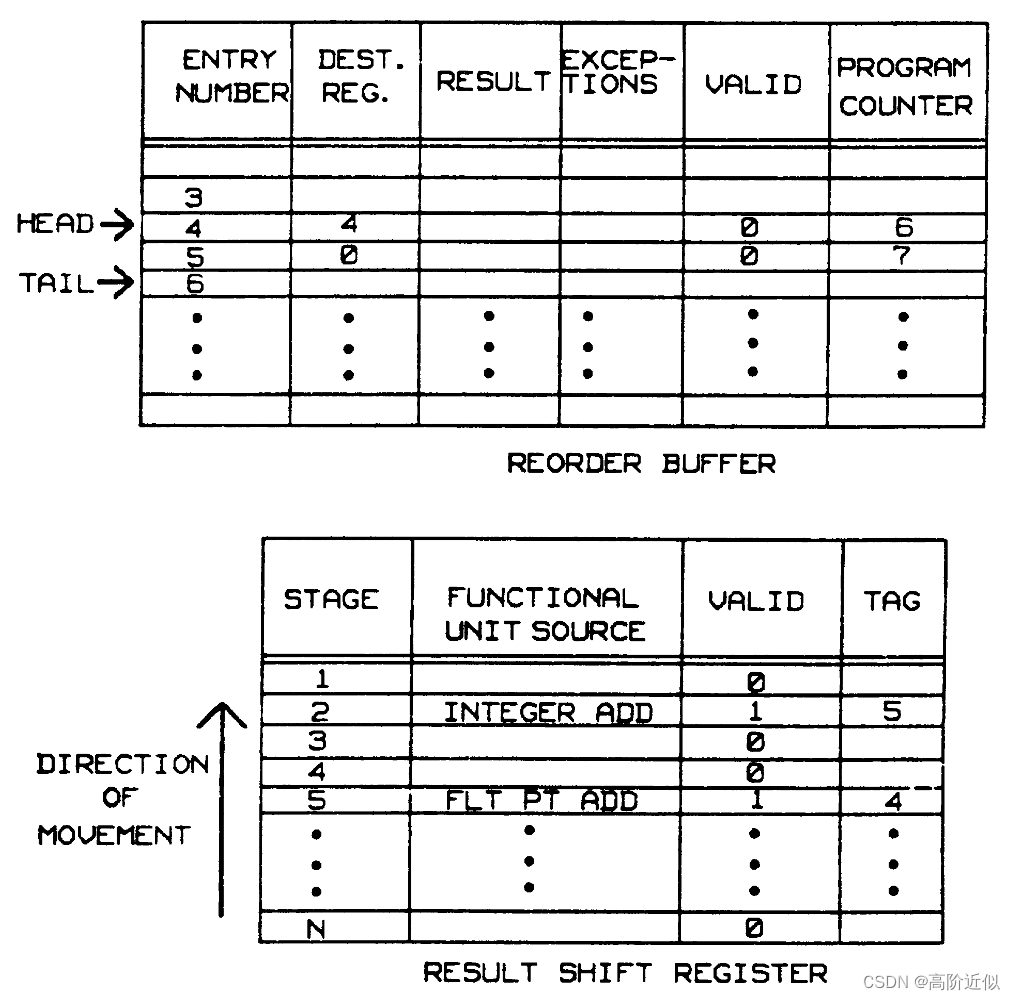
重排序缓冲是一个循环缓冲,有一个头指针(head)和尾指针(tail),[head, tail) 中的每个条目都代表了每个已经发射出去并且尚未完成计算或者已经完成计算但结果没有写回的指令的信息,VALID为0则表示该指令尚未完成计算,反之该指令已经完成计算并且结果已经写入重排序缓冲。当一条指令发射时,将尾指针指向的条目提供给发出指令,尾指针的值用作tag存储在结果移位寄存器中,并且指令的有关信息会写入到该条目中,然后尾指针递增。
当指令完成时,结果和异常条件都被发送到重排序缓冲。结果移位寄存器中的tag用于找到重排序缓冲对应的条目。当重排序缓冲头部的条目的VALID为1时,将检查其异常。如果没有,则将结果写入寄存器,删除该条目(head指针递增)。如果检测到异常,停止发射并准备中断,所有后续写寄存器的操作都被禁止。
主存
- 方案一:类似于
In-order Instruction Completion,强制store指令在已知所有先前的指令都没有异常为止后才会发射。 - 方案二:当从重排序缓冲中删除store指令对应的条目时,存储信号被发送到访存部件。在等待其对应的条目时,store指令可以发出和并阻塞在访存部件中。
PC
PC值存储在重排序缓冲区
重排序缓冲中的条目数量可能非常小,而结果移位寄存器的长度必须与最长的流水线级一样长,可能会包括更多的条目。因此PC值存储在重排序缓冲区中,可以减小总体的硬件开销
Bypass Paths
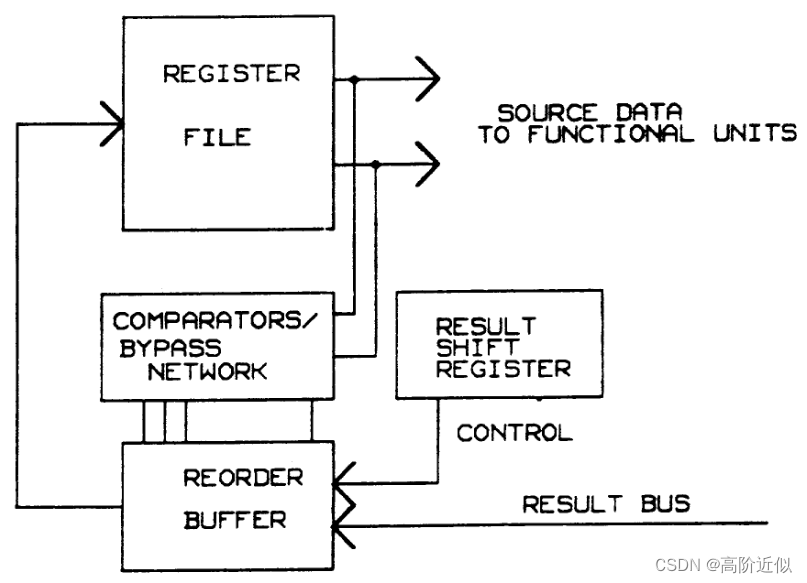
乱序产生的计算结果会暂存在重排序缓冲中,直到它之前的指令完成并写回寄存器。但是这会导致依赖于暂存在重排序缓冲的指令结果的指令无法发出。比如说,考虑指令序列 FLOAT_ADD, INT_ADD1, INT_ADD2,其中INT_ADD2需要用到INT_ADD1的结果,INT_ADD1的计算结果会暂存在重排序缓冲中,直到FLOAT_ADD完成并写回寄存器。所以这会导致INT_ADD2必须先等待FLOAT_ADD完成并写回,且INT_ADD1写回后,才能发射。
可以使用旁路的技术来解决该问题,如下图所示。如果被检查发出的指令的源寄存器与重排序缓冲中的目的寄存器匹配,则使用多路选择器将数据从重排序缓冲中选通到寄存器输出锁存器。在不存在其他阻塞条件的情况下,允许发出指令,并且在将来自重排序缓冲的数据写入寄存器之前使用该数据作为发出指令的操作数。
History Buffer
本节和下一节中介绍的方法旨在减少或消除简单重排序缓冲所经历的性能损失,但不需要多个旁路所需的所有控制逻辑。这些方法主要直接将计算结果写回寄存器文件中,但保留足够的状态信息,以便在发生异常时可以恢复精确的状态。
下图给出了使用History Buffer的总体结构。
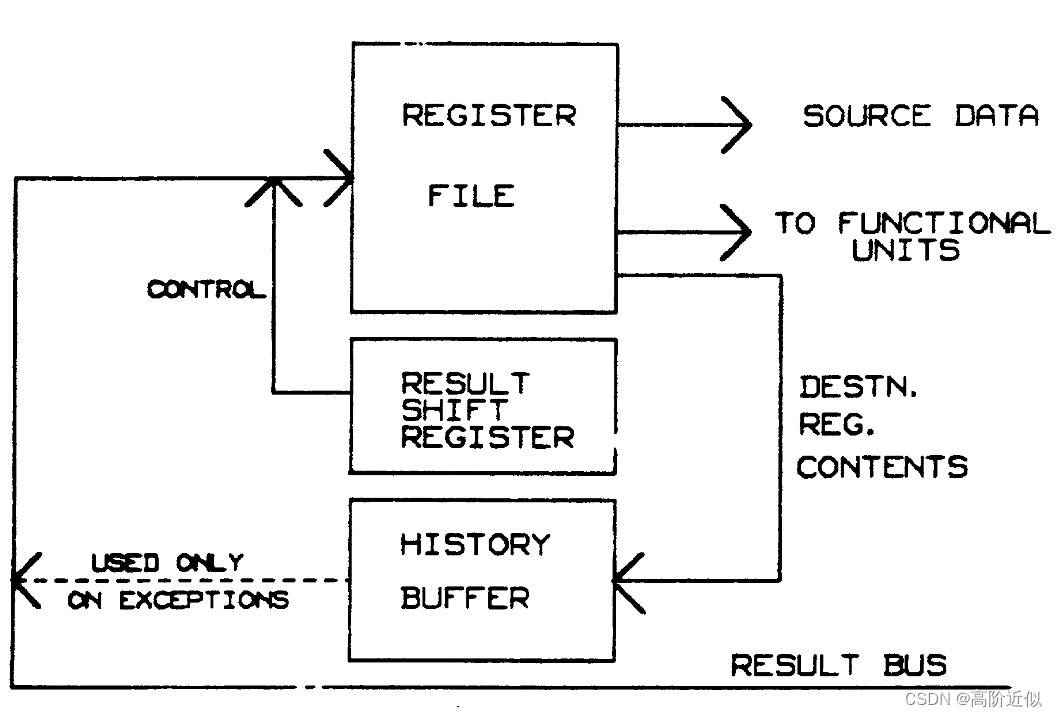
下图给出了History Buffer和结果移位寄存器的结构
History Buffer的组织方式与重排序缓冲非常相似。在指令发射时,与重排序缓冲一样,在tail指向的条目中加载控制信息,但同时也会写入目标寄存器的值。当一条指令完成时,结果将通过结果总线直接写回寄存器,异常报告将写入历史缓冲区。与重排序缓冲一样,通过使用结果移位寄存器中的tag将异常报告写入对应History Buffer的条目。当History Buffer的头部对应的指令无异常且完成时(VALID为1且EXCEPTION为0),可以删除该条目(头指针递增)。
- 与重排序缓冲区一样,History Buffer的条目数可以短于流水线的级数。如果所有History Buffer条目都被使用,则必须阻止指令发射。当缓冲区足够长时,这种情况就很少发生。历史缓冲区对性能的影响在后面讨论。
- 该方法所需的额外硬件是使用大缓存来存储历史信息。此外,寄存器文件必须具有三个读取端口,因为必须在发出时读取目标以及源寄存器的值。此外,如果基本实现在寄存器文件周围绕过结果总线,则会出现一个小问题。在这种情况下,旁路也必须连接到历史缓冲区。
存在的问题:指令执行完直接将结果存入寄存器,如果有条先执行的长指令要将结果存入R1后执行的短指令也将结果存入R1,若短指令先执行完,那最终结果不是会被长指令覆盖,导致出错?
寄存器
当异常条件到达缓冲区的头部时,缓冲区将被保留,指令发射立即停止,并等待流水线完成。然后,缓冲区条目从尾部到头部被清空,历史值被加载回其原始寄存器。
主存
当一个store指令的条目写入History Buffer时,一个信号会被发送来表明该store指令可以写内存。后续的store指令可以在发射寄存器中等待,也可以在访存部件中阻塞。
PC
History Buffer头部中的PC即为精确的PC
Future File
Future File类似于history buffer,其架构如下所示,但是它使用了两个分离的寄存器文件。一个寄存器文件(architectural file)反映了架构(顺序)机器的状态。第二个寄存器文件(future file)用于和功能单元连接,一旦指令完成,该寄存器文件就会被更新。
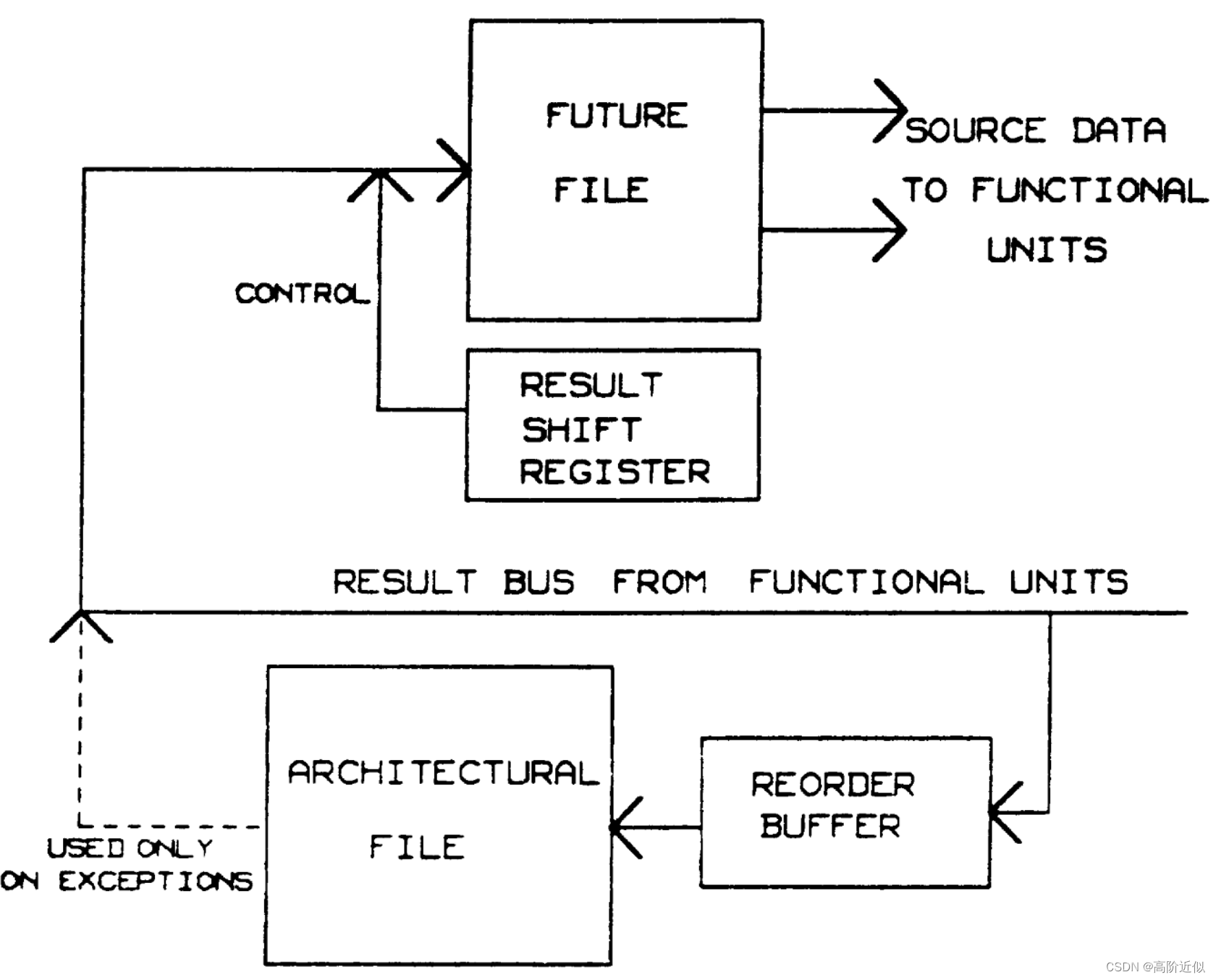
指令可以将结果乱序写回到Future File。此外还有一个重排序缓存,用于接收指令执行的结果。当头指针对应的指令执行完(VALID为1)时,对应的结果将写回architectural file中。
使用Future File的好处有两点:
- 不需要在重排序缓存上建立多个旁路
- 在进入中断处理函数时,软件会将寄存器保存在内存中,并将新的值加载到寄存器中。这种情况下,Architectural File可以立即被软件读取并写入内存,而基于History Buffer的方法则需要等寄存器先恢复。此外,使用Future File也没有History Buffer中的旁路问题。
寄存器
当重排序缓冲头部的指令无异常地完成时,其结果被写回architectural file中。如果它完成时出现异常,则根据头指针和尾指针之间的条目中存储的目的寄存器,从architectural file读取对应的值来恢复Future File。
主存
和重排序缓冲一样
PC
和重排序缓冲一样
拓展
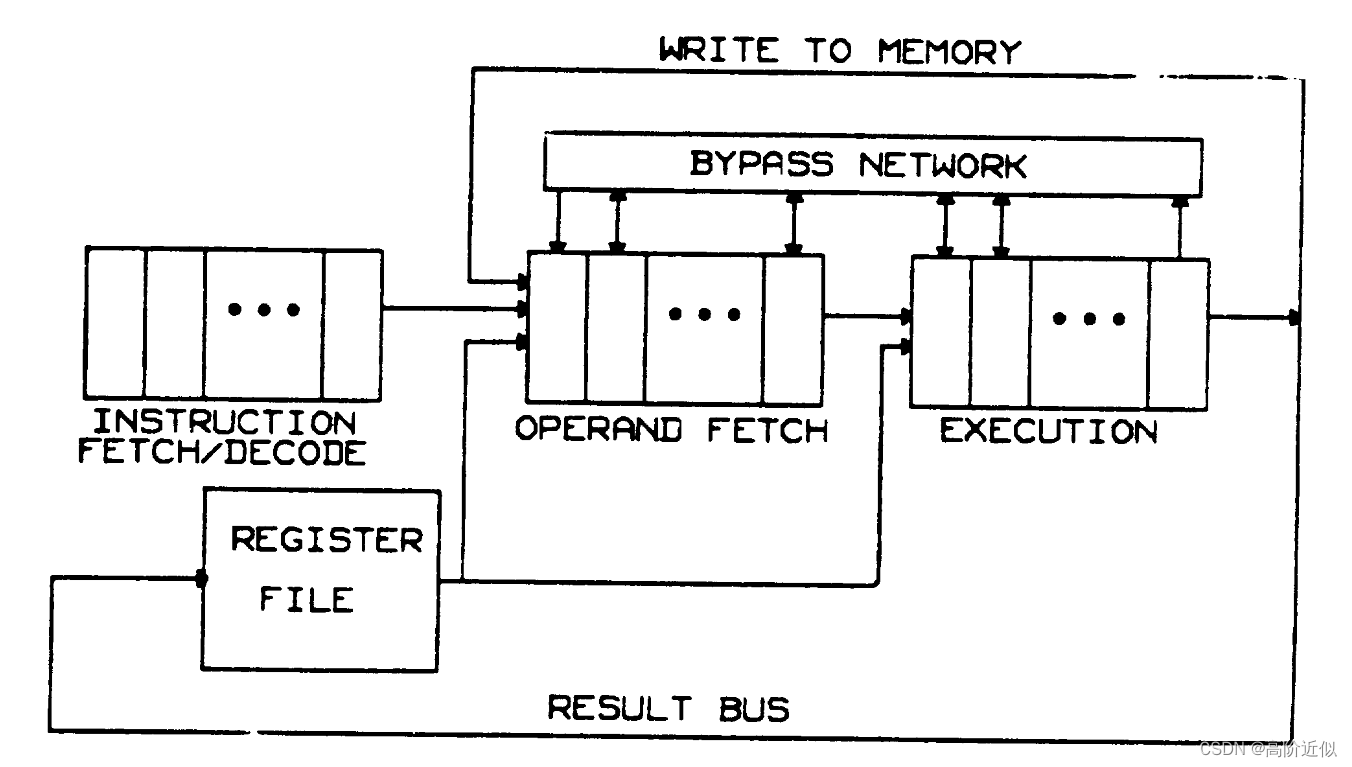
线性流水线结构
下图给出了线性流水线结构,具有指令获取/解码阶段、操作数获取阶段和执行阶段,其中任何阶段都可以由一个或多个流水线阶段组成。一般来说,在此类结构中,执行后重新排序指令并不是一个重要的问题,因为指令在通过流水线时保持顺序是很自然的。因此,流水线本身充当一种重排序缓冲区。为了实现精确,PC的值也可以沿着流水线流动,以便在出现异常时使用。线性流水线通常具有连接中间流水线级的多个旁路路径。使用本文的术语,线性流水线结构通过使用具有旁路的重新排序缓冲区方法来实现精确的中断。















 215
215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









