







文章目录
本文首先对AXI4总线协议进行了一个简单的介绍,然后使用vivado提供的模板创建了一个AXI4-Full Slave的接口,并生成了一个具有Master和Slave的代码实例,阅读该示例代码,进行修改后用于自己的项目。
官方手册里,Master 称为 Manager,Slave 称为 Subordinate
AXI4总线协议
概述
这一部分可以参考我之前的一篇博客 AXI4-Lite 实战,这里不再赘述
AXI4-Full 接口
首先是AXI4-Full接口的五个通道,VALID 和 READY 信号的握手,以及突发传输的基本概念,这部分可以参考我之前的一篇博客 AXI4-Lite 实战 里对AXI4-Lite接口的描述,这里不再赘述。
此外,AXI4-Full 接口和 Lite 接口的一个不同点在于,前者支持 Transaction Identififiers,也就是给每个读/写事务赋予一个 ID,具有相同 ID 的事务的顺序不能打乱,不同 ID 的事务的顺序可以打乱(即重排序),这个东西的作用是即使当前还有事务没有完成,Master 可以发出新事务(新事物的ID和未完成事务的ID要不一样),可以提高系统性能
Slave 可以不支持重排序,如果 Slave 不支持重排序但是有 ID 信号,那么一定要将信号 BID 的值赋值为 AWID,将信号 RID 的值赋值为 ARID,因为 Master 可能会用到不同的 ID 号,而此时 Master 需要通过 BID 和 RID 与 AWID 和 ARID 进行对应
下面主要讲解AXI-Full Slave接口,在讲解时,是直接把一个主设备和一个从设备连接在一起,从而忽略总线的仲裁和地址译码,重点关注协议内容。
创建代码实例
这一部分可以参考我之前的一篇博客 AXI4-Lite 实战,这里不再赘述,需要注意的是,接口类型选择 Full,接口模式选择 Slave 。
代码分析
接下来主要是分析官方给的Slave示例,即 s_axi4_full_v1_0_S00_AXI.v。
模块参数
| 名称 | 解释 |
|---|---|
| C_S_AXI_ID_WIDTH | ID 信号的宽度 |
| C_S_AXI_DATA_WIDTH | 数据宽度 |
| C_S_AXI_ADDR_WIDTH | 地址宽度 |
| C_S_AXI_AWUSER_WIDTH | 写地址通道中可选的用户定义的信号的宽度 |
| C_S_AXI_ARUSER_WIDTH | 读地址通道中可选的用户定义的信号的宽度 |
| C_S_AXI_WUSER_WIDTH | 写数据通道中可选的用户定义的信号的宽度 |
| C_S_AXI_RUSER_WIDTH | 读数据通道中可选的用户定义的信号的宽度 |
| C_S_AXI_BUSER_WIDTH | 写响应通道中可选的用户定义的信号的宽度 |
输入输出
其他参数
| 名称 | 解释 |
|---|---|
| S_AXI_ACLK | 时钟 |
| S_AXI_ARESETN | 复位信号,低电平复位 |
写地址通道
| 名称 | 解释 |
|---|---|
| input wire [C_S_AXI_ID_WIDTH-1 : 0] S_AXI_AWID | 写地址ID,示例代码的 Slave 不支持重排序 |
| input wire [C_S_AXI_ADDR_WIDTH-1 : 0] S_AXI_AWADDR | 写地址 |
| input wire [7 : 0] S_AXI_AWLEN | 突发长度(Burst length),给出了突发中传输(Transfer)的数量 |
| input wire [2 : 0] S_AXI_AWSIZE | 突发大小,给出了突发中每次传输的大小 |
| input wire [1 : 0] S_AXI_AWBURST | 突发类型,AWBURST 和 AWSIZE 决定了此处突发中每次传输的地址是如何计算的 |
| input wire S_AXI_AWLOCK | 锁类型(Lock Type),示例代码没用这个信号,这里不管它的作用 |
| input wire [3 : 0] S_AXI_AWCACHE | 存储类型,示例代码没用这个信号,这里不管它的作用 |
| input wire [2 : 0] S_AXI_AWPROT | 保护类型,示例代码没用这个信号,这里不管它的作用 |
| input wire [3 : 0] S_AXI_AWQOS | 服务质量(Quality of Service),示例代码没用这个信号,这里不管它的作用 |
| input wire [3 : 0] S_AXI_AWREGION | 区域标识符(Region identifier),允许 Slave 的单个物理接口用于多个逻辑接口,示例代码没用这个信号,这里不管它的作用 |
| input wire [C_S_AXI_AWUSER_WIDTH-1 : 0] S_AXI_AWUSER | 写地址通道中可选的用户定义的信号,示例代码没用这个信号 |
| input wire S_AXI_AWVALID | 写地址有效 |
| output wire S_AXI_AWREADY | 写地址准备 |
下面主要解释一下 S_AXI_AWLEN、S_AXI_AWSIZE 和 S_AXI_AWBURST
突发长度(S_AXI_AWLEN):一次突发中可能会有多次数据的传输,该信号给出了传输的次数,需要注意的是,实际传输的次数是 S_AXI_AWLEN + 1,比如该信号的值是2,那么实际上一共有三次传输,即会对三个地址处的值进行写入
需要注意的是
- 对于 Wrapping Burst(一种突发类型,后面会介绍),长度只能是 2、4、8 或 16,即 AWLEN 的值只能为 1、3、7 或 16
- 对于 Fixed Burst(一种突发类型,后面会介绍),长度可以从 1 到 16,即 AWLEN 的值可以从 0 到 15
- 事务不得跨越 4KB 地址边界
突发大小(S_AXI_AWSIZE ):该信号给出了每次传输的数据的大小,需要注意的是,该信号给出的数据大小不能超过数据宽度(即 C_S_AXI_DATA_WIDTH),下表是该信号的值与其表示的传输数据大小的对应关系
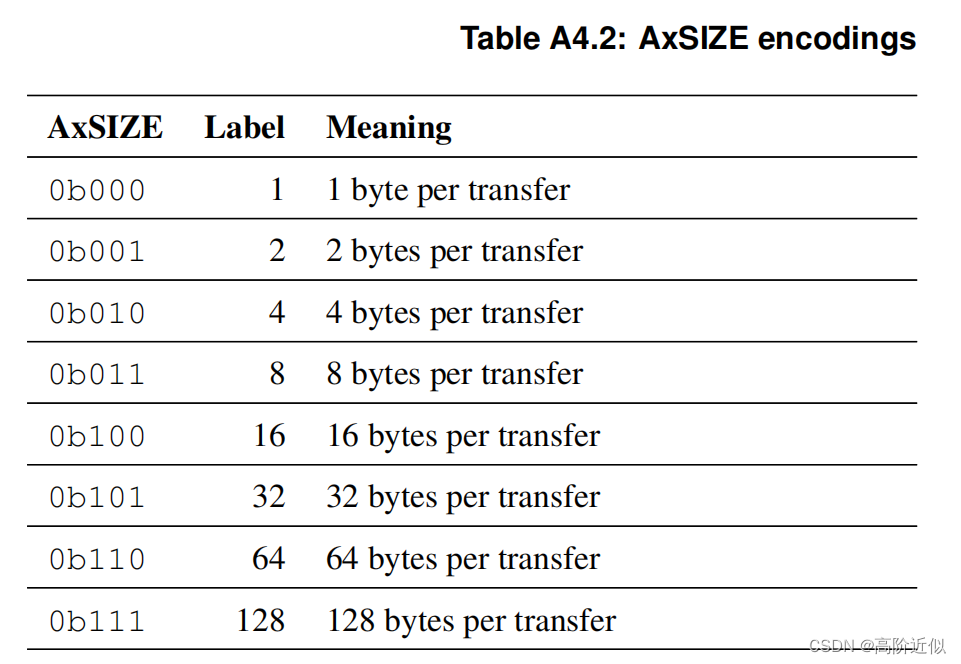
比如,如果数据宽度是32位,那么 AxSIZE 的值只能为 0b000, 0b001 或 0b010
在示例中,输入给 Slave 的 AxSIZE 的值恒为 0b010
突发类型(S_AXI_AWBURST):AWBURST 和 AWSIZE 决定了此处突发中每次传输的地址是如何计算的,下表给出了该信号的值与突发类型的对应关系
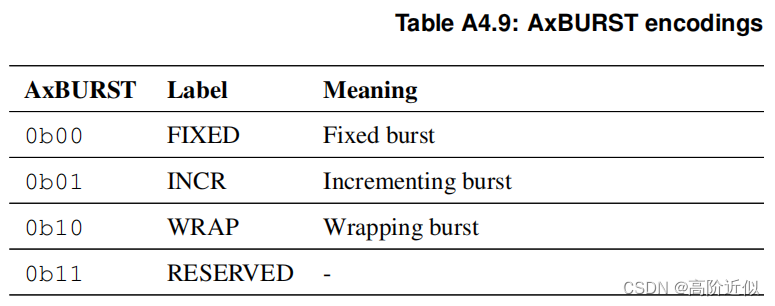
Fixed Burst:每次传输的地址是固定的,即为 S_AXI_AWADDR。该类型主要用于读或者清空 FIFO。
INCR (incrementing) Burst:每次传输的地址等于上一次传输的地址加上传输的大小(即S_AXI_AWSIZE信号所给出的传输的字节数),需要注意的是,Master 给出的初始地址必须是对齐的,比如说如果 AxSIZE 的值为 0b010,那么起始地址必须要是4字节对齐。该类型主要用于访问一般的存储器。
WRAP (wrapping) Burst:根据起始地址和传输大小,可以计算出一个
lower address和upper address,Wrapping Burst 下每次传输地址的计算和 Incrementing Burst 是相似的,除了当地址增加到upper address时,下次传输的地址需要回落到lower address。需要注意的是,起始地址必须是和 AxSIZE 对齐的,而且突发长度只能为2、4、8或16。lower address必须与此次突发中所有传输的字节总数(即突发大小 * 突发长度)是对齐的,现在举个例子说明lower address和upper address如何计算的。例如,突发长度为 8(即AxLEN的值为7),突发大小为 4 字节(即AxSIZE为0b010),那么此次突发中传输的总字节数是 32,因此lower address必须是32的整数倍。假如起始地址是 72(必须和突发大小是对齐的),相邻两个32字节对齐、并且起始地址位于其间的地址是 64 和 96,因此lower address便是 64,upper address便是 96-4=92 (即减去突发大小),因此此次突发的地址依次是72, 76, 80, 84, 88, 92, 64, 68,需要注意的是传输地址中不包括96这个地址。Wrapping Burst 主要用于 cache line 的访问,当我们访问 cache line 中的某个地址时,如果发生缺失,需要从内存中搬整个 line 大小的数据放到这个 cache line 中来,我们访问的地址不一定就是 cache line 的边界地址,此时便可以用 Wrapping Burst 来方便地解决这个问题:如果 cache line 的大小是 32 字节,便可设置突发长度为 8,突发大小为 4 字节,突发类型为 Wrapping Burst
Reserved:这个官方没有定义,用户可以根据需求自己定义
写数据通道
| 名称 | 解释 |
|---|---|
| input wire [C_S_AXI_DATA_WIDTH-1 : 0] S_AXI_WDATA | 写数据 |
| input wire [(C_S_AXI_DATA_WIDTH/8)-1 : 0] S_AXI_WSTRB | 写数据选通 |
| input wire S_AXI_WLAST | 写最后,表示当前传输是突发中的最后一个传输 |
| input wire [C_S_AXI_WUSER_WIDTH-1 : 0] S_AXI_WUSER | 写数据通道中可选的用户定义的信号,示例代码没用这个信号 |
| input wire S_AXI_WVALID | 写数据有效 |
| output wire S_AXI_WREADY | 写数据准备 |
在进行最后一次传输的时候,S_AXI_WLAST 信号要拉高
写响应通道
| 名称 | 解释 |
|---|---|
| output wire [C_S_AXI_ID_WIDTH-1 : 0] S_AXI_BID | 写响应的ID,示例代码的 Slave 不支持重排序,因此该信号必须赋值为 S_AXI_AWID |
| output wire [1 : 0] S_AXI_BRESP | 写响应,给出写事务的状态,示例代码中该信号恒为 2’b0 |
| output wire [C_S_AXI_BUSER_WIDTH-1 : 0] S_AXI_BUSER | 写响应通道中可选的用户定义的信号 |
| output wire S_AXI_BVALID | 写响应有效 |
| input wire S_AXI_BREADY | 写响应准备 |
读地址通道
| 名称 | 解释 |
|---|---|
| input wire [C_S_AXI_ID_WIDTH-1 : 0] S_AXI_ARID | 读地址ID,示例代码的 Slave 不支持重排序 |
| input wire [C_S_AXI_ADDR_WIDTH-1 : 0] S_AXI_ARADDR | 读地址 |
| input wire [7 : 0] S_AXI_ARLEN | 突发长度,给出了突发中传输的数量 |
| input wire [2 : 0] S_AXI_ARSIZE | 突发大小,给出了突发中每次传输的大小 |
| input wire [1 : 0] S_AXI_ARBURST | 突发类型,ARBURST 和 ARSIZE 决定了此处突发中每次传输的地址是如何计算的 |
| input wire S_AXI_ARLOCK | 锁类型(Lock Type),示例代码没用这个信号,这里不管它的作用 |
| input wire [3 : 0] S_AXI_ARCACHE | 存储类型,示例代码没用这个信号,这里不管它的作用 |
| input wire [2 : 0] S_AXI_ARPROT | 保护类型,示例代码没用这个信号,这里不管它的作用 |
| input wire [3 : 0] S_AXI_ARQOS | 服务质量(Quality of Service),示例代码没用这个信号,这里不管它的作用 |
| input wire [3 : 0] S_AXI_ARREGION | 区域标识符(Region identifier),允许 Slave 的单个物理接口用于多个逻辑接口,示例代码没用这个信号,这里不管它的作用 |
| input wire [C_S_AXI_ARUSER_WIDTH-1 : 0] S_AXI_ARUSER | 读地址通道中可选的用户定义的信号 |
| input wire S_AXI_ARVALID | 读地址有效 |
| output wire S_AXI_ARREADY | 读地址准备 |
S_AXI_ARLEN、S_AXI_ARSIZE 和 S_AXI_ARBURST 的含义参考写地址通道中的解释
读数据通道
| 名称 | 解释 |
|---|---|
| output wire [C_S_AXI_ID_WIDTH-1 : 0] S_AXI_RID | 读ID,示例代码的 Slave 不支持重排序,因此该信号必须赋值为 S_AXI_ARID |
| output wire [C_S_AXI_DATA_WIDTH-1 : 0] S_AXI_RDATA | 读数据 |
| output wire [1 : 0] S_AXI_RRESP | 读响应,示例代码中该信号恒为 2’b0 |
| output wire S_AXI_RLAST | 读最后,表示当前传输是突发中的最后一个传输 |
| output wire [C_S_AXI_RUSER_WIDTH-1 : 0] S_AXI_RUSER | 读地址通道中可选的用户定义的信号 |
| output wire S_AXI_RVALID | 读数据有效 |
| input wire S_AXI_RREADY | 读数据准备 |
在进行最后一次传输的时候,S_AXI_RLAST 信号要拉高
代码阅读
一堆信号声明
下面解释部分信号和参数,没解释的信号先不管,后面碰到了再解释
aw_wrap_en: 在 WRAP 突发中,当下一次传输的地址需要回落到lower address时,该信号会拉高ar_wrap_en: 在 WRAP 突发中,当下一次传输的地址需要回落到lower address时,该信号会拉高aw_wrap_size: 该信号的值等于 SIZE * AWLEN,其中 SIZE 是单次传输的字节数(SIZE 不等于信号 AWSIZE的值),需要注意的是,该信号的值并不等于突发中传输的总字节数,实际传输的总字节数应该为 SIZE * (AWLEN + 1)。该信号的作用是,在 WRAP 突发中,当aw_wrap_en使能的时候,下一次传输的地址就等于当前地址减去aw_wrap_size。ar_wrap_size: 该信号的值等于 SIZE * ARLEN,其中 SIZE 是单次传输的字节数(SIZE 不等于信号 ARSIZE的值),需要注意的是,该信号的值并不等于突发中传输的总字节数,实际传输的总字节数应该为 SIZE * (ARLEN + 1)。该信号的作用是,在 WRAP 突发中,当ar_wrap_en使能的时候,下一次传输的地址就等于当前地址减去ar_wrap_size。ADDR_LSB: 回忆之前说的,在类型为 WRAP 或 INCR 的突发中,起始地址要和 AxSIZE 表示的传输大小对齐,假如说 AxSIZE 的值为 0b010,即传输大小为 4 字节,那么意味着起始地址的 [1:0] 位都为 0,此时 ADDR_LSB 的值即为 2,也就是说,起始地址的 [ADDR_LSB-1:0] 位需要都为0,从而和传输大小保持对齐。又比如说,AxSIZE 的值为 0b011,即传输大小为 8 字节,那么此时 ADDR_LSB 的值应该为 3,即起始地址的 [3-1:0] 位需要都为0。总之需要注意的是,ADDR_LSB 的值是由 AxSIZE 的值决定的。
// AXI4FULL signals
reg [C_S_AXI_ADDR_WIDTH-1 : 0] axi_awaddr;
reg axi_awready;
reg axi_wready;
reg [1 : 0] axi_bresp;
reg [C_S_AXI_BUSER_WIDTH-1 : 0] axi_buser;
reg axi_bvalid;
reg [C_S_AXI_ADDR_WIDTH-1 : 0] axi_araddr;
reg axi_arready;
reg [C_S_AXI_DATA_WIDTH-1 : 0] axi_rdata;
reg [1 : 0] axi_rresp;
reg axi_rlast;
reg [C_S_AXI_RUSER_WIDTH-1 : 0] axi_ruser;
reg axi_rvalid;
// aw_wrap_en determines wrap boundary and enables wrapping
wire aw_wrap_en;
// ar_wrap_en determines wrap boundary and enables wrapping
wire ar_wrap_en;
// aw_wrap_size is the size of the write transfer, the
// write address wraps to a lower address if upper address
// limit is reached
wire [31:0] aw_wrap_size ;
// ar_wrap_size is the size of the read transfer, the
// read address wraps to a lower address if upper address
// limit is reached
wire [31:0] ar_wrap_size ;
// The axi_awv_awr_flag flag marks the presence of write address valid
reg axi_awv_awr_flag;
//The axi_arv_arr_flag flag marks the presence of read address valid
reg axi_arv_arr_flag;
// The axi_awlen_cntr internal write address counter to keep track of beats in a burst transaction
reg [7:0] axi_awlen_cntr;
//The axi_arlen_cntr internal read address counter to keep track of beats in a burst transaction
reg [7:0] axi_arlen_cntr;
reg [1:0] axi_arburst;
reg [1:0] axi_awburst;
reg [7:0] axi_arlen;
reg [7:0] axi_awlen;
//local parameter for addressing 32 bit / 64 bit C_S_AXI_DATA_WIDTH
//ADDR_LSB is used for addressing 32/64 bit registers/memories
//ADDR_LSB = 2 for 32 bits (n downto 2)
//ADDR_LSB = 3 for 64 bits (n downto 3)
localparam integer ADDR_LSB = (C_S_AXI_DATA_WIDTH/32)+ 1;
localparam integer OPT_MEM_ADDR_BITS = 7;
localparam integer USER_NUM_MEM = 1;
//----------------------------------------------
//-- Signals for user logic memory space example
//------------------------------------------------
wire [OPT_MEM_ADDR_BITS:0] mem_address;
wire [USER_NUM_MEM-1:0] mem_select;
reg [C_S_AXI_DATA_WIDTH-1:0] mem_data_out[0 : USER_NUM_MEM-1];
genvar i;
genvar j;
genvar mem_byte_index;
一堆 assign 语句
有几个地方需要注意:
aw_wrap_size和ar_wrap_size计算方法,示例代码中 Slave 不支持可变的传输大小,传递给 Slave 的AxSIZE 信号所表示的传输字节数目,恰好等于数据宽度,所以这里每次传输的字节数,就用 C_S_AXI_DATA_WIDTH/8 来表示了- 示例代码中 Slave 不支持重排序,由于 Slave 提供了 ID 接口并且 Master 可能使用不同的 ID,所以这里必须要将 S_AXI_BID 赋值为 S_AXI_AWID,将 S_AXI_RID 赋值为 S_AXI_ARID
- 注意理解
aw_wrap_en和ar_wrap_en的计算方法,当地址等于upper address时,aw_wrap_en和ar_wrap_en会被使能,需要注意的是 ar_wrap_size 不等于传输的总字节数
// I/O Connections assignments
assign S_AXI_AWREADY = axi_awready;
assign S_AXI_WREADY = axi_wready;
assign S_AXI_BRESP = axi_bresp;
assign S_AXI_BUSER = axi_buser;
assign S_AXI_BVALID = axi_bvalid;
assign S_AXI_ARREADY = axi_arready;
assign S_AXI_RDATA = axi_rdata;
assign S_AXI_RRESP = axi_rresp;
assign S_AXI_RLAST = axi_rlast;
assign S_AXI_RUSER = axi_ruser;
assign S_AXI_RVALID = axi_rvalid;
assign S_AXI_BID = S_AXI_AWID;
assign S_AXI_RID = S_AXI_ARID;
assign aw_wrap_size = (C_S_AXI_DATA_WIDTH/8 * (axi_awlen));
assign ar_wrap_size = (C_S_AXI_DATA_WIDTH/8 * (axi_arlen));
assign aw_wrap_en = ((axi_awaddr & aw_wrap_size) == aw_wrap_size)? 1'b1: 1'b0;
assign ar_wrap_en = ((axi_araddr & ar_wrap_size) == ar_wrap_size)? 1'b1: 1'b0;
写地址通道
首先是 axi_awready 和 axi_awv_awr_flag 的生成。
这里需要先解释一下
axi_awv_awr_flag和axi_arv_arr_flag什么时候会被置位和复位:axi_awv_awr_flag/axi_arv_arr_flag会在检测到 Master 即将开启一次写/读事务的时候(即检测到 S_AXI_AxVALID 被置位时)被置位,会在检测到此次突发中最后一次写/读传输完成的时候(即检测到 S_AXI_xLAST && axi_xready)被复位
// Implement axi_awready generation
// 下面这个英文注解写的有问题,axi_awready 不需要等 S_AXI_WVALID 置位
// axi_awready is asserted for one S_AXI_ACLK clock cycle when both
// S_AXI_AWVALID and S_AXI_WVALID are asserted. axi_awready is
// de-asserted when reset is low.
//
always @( posedge S_AXI_ACLK )
begin
if ( S_AXI_ARESETN == 1'b0 )
begin
axi_awready <= 1'b0;
axi_awv_awr_flag <= 1'b0;
end
else
begin
// 没有读事务的数据正在传输:~axi_arv_arr_flag
// 没有写事务的数据正在传输(但是可能有写响应正在进行):~axi_awv_awr_flag
// Master 想要发起一次写事务:S_AXI_AWVALID
if (~axi_awready && S_AXI_AWVALID && ~axi_awv_awr_flag && ~axi_arv_arr_flag)
begin
// slave is ready to accept an address and
// associated control signals
axi_awready <= 1'b1;
axi_awv_awr_flag <= 1'b1;
// used for generation of bresp() and bvalid
end
// S_AXI_WLAST 表示是突发中的最后一次传输
// axi_wready 表示这次传输已经完成了
else if (S_AXI_WLAST && axi_wready)
// preparing to accept next address after current write burst tx completion
begin
axi_awv_awr_flag <= 1'b0;
end
else
// axi_awready 只会拉高一个周期
begin
axi_awready <= 1'b0;
end
end
end
然后是 axi_awaddr 的生成和其他控制信号的锁存
axi_awaddr表示的是当前传输的地址
// 下面这个英文注解写的有问题,不需要等 S_AXI_WVALID 置位
// Implement axi_awaddr latching
// This process is used to latch the address when both
// S_AXI_AWVALID and S_AXI_WVALID are valid.
always @( posedge S_AXI_ACLK )
begin
if ( S_AXI_ARESETN == 1'b0 )
begin
axi_awaddr <= 0; // 此次突发中,当前传输的地址
axi_awlen_cntr <= 0; // 该信号表示此次突发中,当前是第几个传输,注意是从0开始计数
axi_awburst <= 0; // 突发类型
axi_awlen <= 0; // 实际传输的次数是 axi_awlen + 1
end
else
begin
// 下面这个if的作用是将有关的信号先锁存起来
// 这里的条件比 axi_awready 的生成代码里少了一个,因为无论是否在进行读事务,都不会妨碍先把有关写事务的信息锁存起来,只要没有在进行写事务即可
if (~axi_awready && S_AXI_AWVALID && ~axi_awv_awr_flag)
begin
// address latching
axi_awaddr <= S_AXI_AWADDR[C_S_AXI_ADDR_WIDTH - 1:0];
axi_awburst <= S_AXI_AWBURST;
axi_awlen <= S_AXI_AWLEN;
// start address of transfer
axi_awlen_cntr <= 0;
end
// axi_wready && S_AXI_WVALID:当前传输已经完成
// (axi_awlen_cntr <= axi_awlen):示例代码用这个条件我感觉不是很合适,后面再详细解释
// 需要注意的是,每次传输都需要ready和valid握手
// Master一定是一次传输最多只能占一个周期,不能说一次传输我把Valid拉高多个周期
// 因为Slave每次时钟上升沿都会检查 axi_wready && S_AXI_WVALID,如果条件成立就认为已经完成一次传输了
// 当然相邻传输之间可以等多个周期,但是需要把valid拉低
else if((axi_awlen_cntr <= axi_awlen) && axi_wready && S_AXI_WVALID)
begin
axi_awlen_cntr <= axi_awlen_cntr + 1;
// 根据突发类型,来生成下一次要写入数据的地址
// 由于示例代码的 Slave 不支持可变的传输大小,所以下面的这段代码都默认传输大小为数据宽度
case (axi_awburst)
2'b00: // fixed burst
// The write address for all the beats in the transaction are fixed
begin
axi_awaddr <= axi_awaddr;
//for awsize = 4 bytes (010)
end
2'b01: //incremental burst
// The write address for all the beats in the transaction are increments by awsize
begin
axi_awaddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] <= axi_awaddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] + 1;
//awaddr aligned to 4 byte boundary
axi_awaddr[ADDR_LSB-1:0] <= {ADDR_LSB{1'b0}};
//for awsize = 4 bytes (010)
end
2'b10: //Wrapping burst
// The write address wraps when the address reaches wrap boundary
if (aw_wrap_en)
begin
axi_awaddr <= (axi_awaddr - aw_wrap_size);
end
else
begin
axi_awaddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] <= axi_awaddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] + 1;
axi_awaddr[ADDR_LSB-1:0] <= {ADDR_LSB{1'b0}};
end
default: //reserved (incremental burst for example)
begin
axi_awaddr <= axi_awaddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] + 1;
//for awsize = 4 bytes (010)
end
endcase
end
end
end
这里解释一下,为什么我认为示例代码使用 (axi_awlen_cntr <= axi_awlen) 不太合理
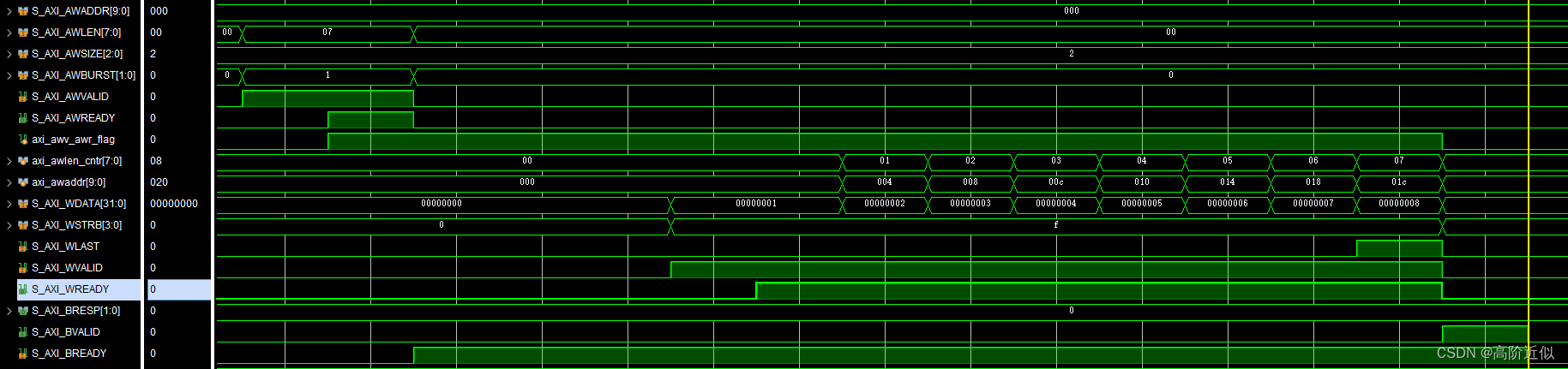
从直觉上来说,只有当还有传输没有完成时,我们才需要更新下一次传输的地址,但是根据示例代码,当最后一次传输已经完成时(即axi_awlen_cntr == axi_awlen && axi_wready && S_AXI_WVALID),此时传输的地址还是会更新,这可以从模拟波形得到验证,下图是模拟的波形,可以看到,最后一次传输的地址是 0x1c,但是实际上传输完成后,axi_awaddr 的值变成了 0x20

当然这个在写地址生成这里问题不大,仅仅只是不符合直觉而已;但是在读地址那块,代码仍然采用了 (axi_awlen_cntr <= axi_awlen) 作为条件,那里会牵涉到另一个问题,后面再解释
写数据通道
这块主要是 axi_wready 的生成,该信号会在传输中一直保持高电平,直至最后一次传输完成,这也是为什么我在上一节的代码注解中说 Master一定是一次传输最多只能占一个周期,不能说一次传输我把Valid拉高多个周期,因为ready信号一直拉高,如果一次传输把Valid拉高多个周期,那么slave会认为已经完成了多次传输
// Implement axi_wready generation
// 下面这个英文注解写的有问题,不需要检测 S_AXI_AWVALID 置位
// axi_wready is asserted for one S_AXI_ACLK clock cycle when both
// S_AXI_AWVALID and S_AXI_WVALID are asserted. axi_wready is
// de-asserted when reset is low.
always @( posedge S_AXI_ACLK )
begin
if ( S_AXI_ARESETN == 1'b0 )
begin
axi_wready <= 1'b0;
end
else
begin
// 对方发送的数据有效:S_AXI_WVALID
// 之前已经完成写地址:axi_awv_awr_flag
if ( ~axi_wready && S_AXI_WVALID && axi_awv_awr_flag)
begin
// slave can accept the write data
axi_wready <= 1'b1;
end
// axi_wready 会一直拉高,直至所有的传输均已完成
// S_AXI_WLAST 表示是突发中的最后一次传输
// axi_wready 表示这次传输已经完成了
//else if (~axi_awv_awr_flag)
else if (S_AXI_WLAST && axi_wready)
begin
axi_wready <= 1'b0;
end
end
end
写响应通道
这块比较简单,不再赘述
// Implement write response logic generation
// The write response and response valid signals are asserted by the slave
// when axi_wready, S_AXI_WVALID, axi_wready and S_AXI_WVALID are asserted.
// This marks the acceptance of address and indicates the status of
// write transaction.
always @( posedge S_AXI_ACLK )
begin
if ( S_AXI_ARESETN == 1'b0 )
begin
axi_bvalid <= 0;
axi_bresp <= 2'b0;
axi_buser <= 0;
end
else
begin
// 最后一次传输已完成: S_AXI_WLAST && S_AXI_WVALID && axi_wready
if (axi_awv_awr_flag && axi_wready && S_AXI_WVALID && ~axi_bvalid && S_AXI_WLAST )
begin
axi_bvalid <= 1'b1;
axi_bresp <= 2'b0;
// 'OKAY' response
end
else
begin
if (S_AXI_BREADY && axi_bvalid)
//check if bready is asserted while bvalid is high)
//(there is a possibility that bready is always asserted high)
begin
axi_bvalid <= 1'b0;
end
end
end
end
我们可以结合仿真波形,来理解写地址、写数据和写响应,下面是有关的波形,读者可以自行结合代码进一步理解
读地址通道
首先是 axi_arready 和 axi_arv_arr_flag 的生成。
这块代码和写地址通道差不多,这里不再赘述
// Implement axi_arready generation
// axi_arready is asserted for one S_AXI_ACLK clock cycle when
// S_AXI_ARVALID is asserted. axi_awready is
// de-asserted when reset (active low) is asserted.
// The read address is also latched when S_AXI_ARVALID is
// asserted. axi_araddr is reset to zero on reset assertion.
always @( posedge S_AXI_ACLK )
begin
if ( S_AXI_ARESETN == 1'b0 )
begin
axi_arready <= 1'b0;
axi_arv_arr_flag <= 1'b0;
end
else
begin
if (~axi_arready && S_AXI_ARVALID && ~axi_awv_awr_flag && ~axi_arv_arr_flag)
begin
axi_arready <= 1'b1;
axi_arv_arr_flag <= 1'b1;
end
// 最后一次传输已经完成
else if (axi_rvalid && S_AXI_RREADY && axi_arlen_cntr == axi_arlen)
// preparing to accept next address after current read completion
begin
axi_arv_arr_flag <= 1'b0;
end
else
begin
axi_arready <= 1'b0;
end
end
end
然后是 axi_araddr 的生成和其他控制信号的锁存,这块大体上和写地址那块差不多,除了增加了一个 axi_rlast 信号的生成,这个稍后再描述
// Implement axi_araddr latching
//This process is used to latch the address when both
//S_AXI_ARVALID and S_AXI_RVALID are valid.
always @( posedge S_AXI_ACLK )
begin
if ( S_AXI_ARESETN == 1'b0 )
begin
axi_araddr <= 0;
axi_arlen_cntr <= 0;
axi_arburst <= 0;
axi_arlen <= 0;
axi_rlast <= 1'b0;
axi_ruser <= 0;
end
else
begin
// 没有读事务在进行
if (~axi_arready && S_AXI_ARVALID && ~axi_arv_arr_flag)
begin
// address latching
axi_araddr <= S_AXI_ARADDR[C_S_AXI_ADDR_WIDTH - 1:0];
axi_arburst <= S_AXI_ARBURST;
axi_arlen <= S_AXI_ARLEN;
// start address of transfer
axi_arlen_cntr <= 0;
axi_rlast <= 1'b0;
end
else if((axi_arlen_cntr <= axi_arlen) && axi_rvalid && S_AXI_RREADY)
begin
axi_arlen_cntr <= axi_arlen_cntr + 1;
axi_rlast <= 1'b0;
case (axi_arburst)
2'b00: // fixed burst
// The read address for all the beats in the transaction are fixed
begin
axi_araddr <= axi_araddr;
//for arsize = 4 bytes (010)
end
2'b01: //incremental burst
// The read address for all the beats in the transaction are increments by awsize
begin
axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] <= axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] + 1;
//araddr aligned to 4 byte boundary
axi_araddr[ADDR_LSB-1:0] <= {ADDR_LSB{1'b0}};
//for awsize = 4 bytes (010)
end
2'b10: //Wrapping burst
// The read address wraps when the address reaches wrap boundary
if (ar_wrap_en)
begin
axi_araddr <= (axi_araddr - ar_wrap_size);
end
else
begin
axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] <= axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] + 1;
//araddr aligned to 4 byte boundary
axi_araddr[ADDR_LSB-1:0] <= {ADDR_LSB{1'b0}};
end
default: //reserved (incremental burst for example)
begin
axi_araddr <= axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB]+1;
//for arsize = 4 bytes (010)
end
endcase
end
else if((axi_arlen_cntr == axi_arlen) && ~axi_rlast && axi_arv_arr_flag )
begin
axi_rlast <= 1'b1;
end
else if (S_AXI_RREADY)
begin
axi_rlast <= 1'b0;
end
end
end
这里解释一下,为什么我认为示例代码使用 (axi_arlen_cntr <= axi_arlen) 不太合理,除了上面说的不符合直觉外,还存在一个问题
需要注意的是,axi_rlast 置位的条件是 else if((axi_arlen_cntr == axi_arlen) && ~axi_rlast && axi_arv_arr_flag),而在这之前是地址的更新,这块的条件是 else if((axi_arlen_cntr <= axi_arlen) && axi_rvalid && S_AXI_RREADY) ,这里存在一个问题,当 axi_arlen_cntr 刚增加到 axi_arlen 的时候,此时如果 axi_rvalid 已经是置位的,并且对方也拉高了 S_AXI_RREADY 信号,那么 if 语句会进入到地址更新的代码,而不会进入 axi_rlast 置位的代码,但是此时已经最后一次传输已经完成了,但是 axi_rlast 却没有置位,这是不符合规范的。我描述的这种情况是可能存在的,因为官方的示例中,写事务在进行若干次数据传输的过程中,valid 和 ready 信号就是一直拉高的,这样就是一个周期完成一次传输,如果读事务也是这样一周期完成一次传输,那就会出现我上面说的 axi_rlast 没有置位的情况。
所幸的是,官方示例在读事务中并不是一周期完成一次传输,这在后面 valid 信号的生成代码可以看出来,每次valid置位后,都会复位一个周期,这样就不会出现我上面这个问题:当 axi_arlen_cntr 刚增加到 axi_arlen 的时候,由于此时valid刚复位,所以下一个时钟上升沿 else if((axi_arlen_cntr <= axi_arlen) && axi_rvalid && S_AXI_RREADY) 会为 False,而 else if((axi_arlen_cntr == axi_arlen) && ~axi_rlast && axi_arv_arr_flag) 会为 True,从而成功进入到 axi_rlast 置位的代码。
如果后续要将 slave 优化为读事务中一周期完成一次传输,一旦没有注意到 (axi_arlen_cntr <= axi_arlen) 这个问题,就会出现上面说的 axi_rlast 没有置位的情况。因此我认为,应该使用 (axi_arlen_cntr < axi_arlen) 作为判断条件才更为合理。
读数据通道
在一次突发中,每完成一次传输后,axi_rvalid 都会复位一个周期,具体见下面代码
// Implement axi_rvalid generation
// axi_rvalid is asserted for one S_AXI_ACLK clock cycle when both
// S_AXI_ARVALID and axi_arready are asserted. The slave registers
// data are available on the axi_rdata bus at this instance. The
// assertion of axi_rvalid marks the validity of read data on the
// bus and axi_rresp indicates the status of read transaction.axi_rvalid
// is deasserted on reset (active low). axi_rresp and axi_rdata are
// cleared to zero on reset (active low).
always @( posedge S_AXI_ACLK )
begin
if ( S_AXI_ARESETN == 1'b0 )
begin
axi_rvalid <= 0;
axi_rresp <= 0;
end
else
begin
if (axi_arv_arr_flag && ~axi_rvalid)
begin
axi_rvalid <= 1'b1;
axi_rresp <= 2'b0;
// 'OKAY' response
end
else if (axi_rvalid && S_AXI_RREADY)
begin
axi_rvalid <= 1'b0;
end
end
end
可以结合仿真波形,进一步理解读地址和读数据

存储器的生成和访问
在官方的 Slave 的示例中,可以生成 USER_NUM_MEM 个存储器,这里 USER_NUM_MEM 的值默认为 1。
需要说明的是,有些信号官方示例给出了,但是却不用,下面只是我自己的理解,可能有误,欢迎指正
首先是 mem_select 和 mem_address 的生成
generate
if (USER_NUM_MEM >= 1)
begin
assign mem_select = 1;
assign mem_address = (axi_arv_arr_flag? axi_araddr[ADDR_LSB+OPT_MEM_ADDR_BITS:ADDR_LSB]:(axi_awv_awr_flag? axi_awaddr[ADDR_LSB+OPT_MEM_ADDR_BITS:ADDR_LSB]:0));
end
endgenerate
mem_select 一共有 USER_NUM_MEM 个比特位,置位就表示对应的存储器被选择用来完成读/写事务,这个信号官方示例就是简单的置1,但是实际使用肯定不是这样,这里我提出自己的两种解释,我更倾向于第一种解释
- 该信号需要根据 AxREGION 来生成,不同的 AxREGION 的值对应不同的存储器
- 该信号需要根据 AxADDR 来生成,不同的地址范围对应不同的存储器
需要注意的是, mem_address 一共是 OPT_MEM_ADDR_BITS+1 个比特位,因此 Master 给出的地址,只有低OPT_MEM_ADDR_BITS+1+ADDR_LSB位是真正对 Slave 有用的
然后是 USER_NUM_MEM 个存储器的生成
// implement Block RAM(s)
generate
// 这个循环是生成 USER_NUM_MEM 个存储器
for(i=0; i<= USER_NUM_MEM-1; i=i+1)
begin:BRAM_GEN
wire mem_rden;
wire mem_wren;
assign mem_wren = axi_wready && S_AXI_WVALID ;
assign mem_rden = axi_arv_arr_flag ; //& ~axi_rvalid
// 这个循环是生成单个存储器
for(mem_byte_index=0; mem_byte_index<= (C_S_AXI_DATA_WIDTH/8-1); mem_byte_index=mem_byte_index+1)
begin:BYTE_BRAM_GEN
wire [8-1:0] data_in ;
wire [8-1:0] data_out;
// 这里用255这个数字不太好,这个值等于 2^(OPT_MEM_ADDR_BITS+1) - 1 更好
reg [8-1:0] byte_ram [0 : 255];
integer j;
//assigning 8 bit data
assign data_in = S_AXI_WDATA[(mem_byte_index*8+7) -: 8];
assign data_out = byte_ram[mem_address];
always @( posedge S_AXI_ACLK )
begin
if (mem_wren && S_AXI_WSTRB[mem_byte_index])
begin
byte_ram[mem_address] <= data_in;
end
end
always @( posedge S_AXI_ACLK )
begin
if (mem_rden)
begin
// 这里使用了 :- 这个操作符
// [end_idx -: width] 等效于 [end_idx : end_idx - width + 1]
// [(mem_byte_index*8+7) : (mem_byte_index*8+7)-8+1]
// 这里的8给出的是宽度
mem_data_out[i][(mem_byte_index*8+7) -: 8] <= data_out;
end
end
end
end
endgenerate
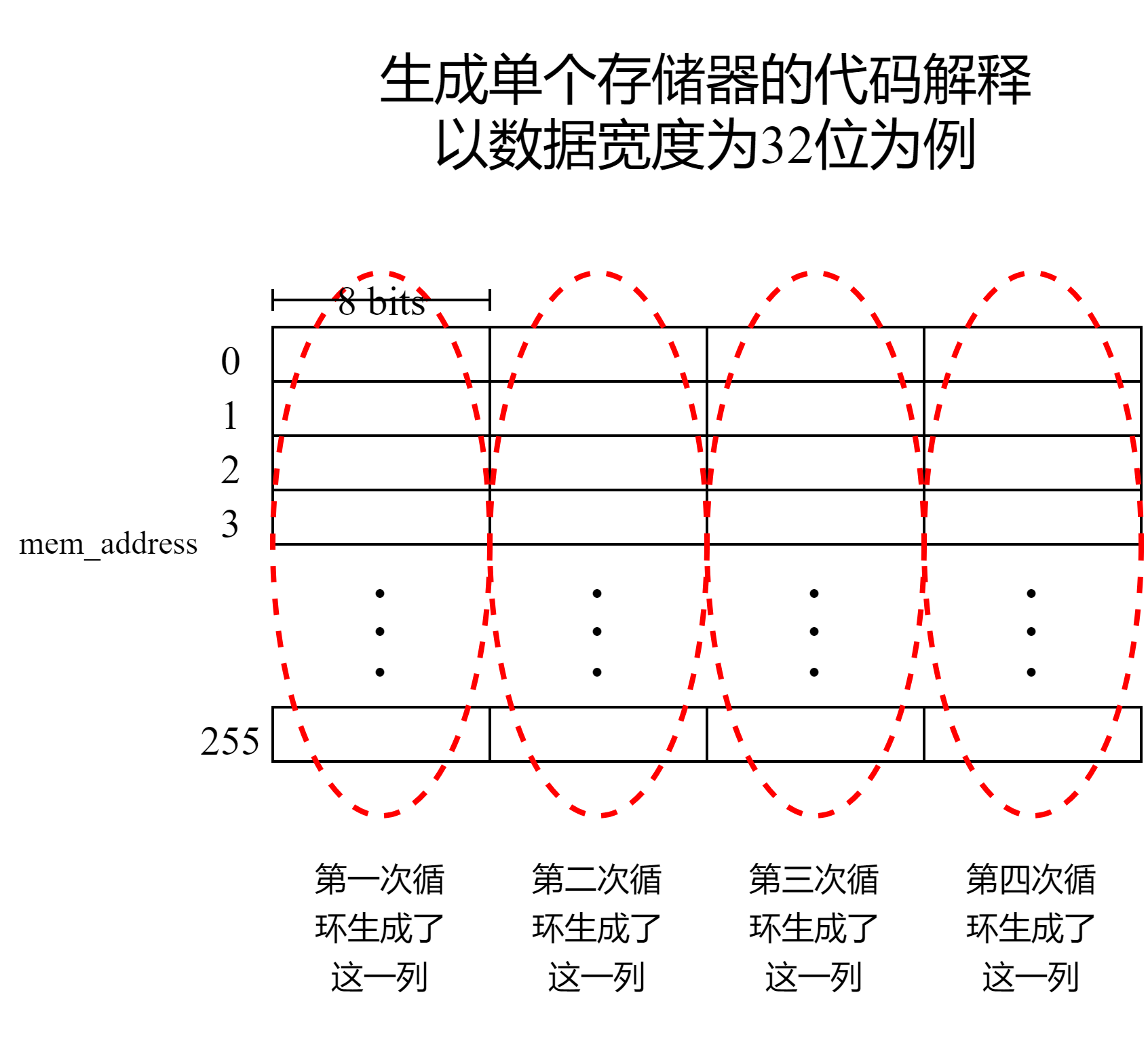
上面生成单个存储器的循环可以用下图解释,需要注意的是,Slave 默认传输的大小等于数据宽度
最后是生成 axi_rdata
//Output register or memory read data
always @( mem_data_out, axi_rvalid)
begin
if (axi_rvalid)
begin
// Read address mux
axi_rdata <= mem_data_out[0];
end
else
begin
axi_rdata <= 32'h00000000;
end
end
值得一提的是,上面代码生成的电路是一个组合逻辑电路,通过查看RTL分析得到的网表结构可以知道,该代码的实现使用了一个LUT2,如下图所示
LUT的介绍可以参考我之前的一篇博客 FPGA原理介绍 (CLB, LUT, 进位链, 存储元素, RAM)
修改后用于自己的项目
在修改官方示例从而用于自己的应用中时,一定要弄清楚 Master 和 Slave 各自支持什么功能,比如说 Master 可能会改变 AxSIZE 的值,但是 Slave 又不支持,那这时候就需要进行修改了,要么把 Master 改为 AxSIZE 的值不变,要么把 Slave 改为支持可变的 AxSIZE。
官方示例的 Slave 恰好可以满足我自己项目中 Master 的需求,因此我并不需要对 Slave 代码进行大规模修改。下面是对 Slave 官方示例的修改和优化。
首先代码中两个地方直接使用了数值,而不是使用参数,这里我将其修改为参数
// 第一处:存储器 byte_ram 的大小使用数值 255 来表示,这里将其用参数 OPT_MEM_ADDR_BITS 表示
for(mem_byte_index=0; mem_byte_index<= (C_S_AXI_DATA_WIDTH/8-1); mem_byte_index=mem_byte_index+1)
begin:BYTE_BRAM_GEN
wire [8-1:0] data_in ;
wire [8-1:0] data_out;
// reg [8-1:0] byte_ram [0 : 255];
reg [8-1:0] byte_ram [0 : 2**(OPT_MEM_ADDR_BITS+1)-1];
integer j;
// 第二处:直接使用 axi_rdata <= 32'h00000000,实际上 axi_rdata 的宽度也可能为 64,应该用 C_S_AXI_ADDR_WIDTH 来表示
always @( mem_data_out, axi_rvalid)
begin
if (axi_rvalid)
begin
// Read address mux
axi_rdata <= mem_data_out[0];
end
else
begin
// axi_rdata <= 32'h00000000;
axi_rdata <= {C_S_AXI_ADDR_WIDTH{1'b0}};
end
end
我的需求是测试项目中各模块的延迟,Slave 只要有返回值即可,但我并不关心 Slave 返回的值,因此我这里将读出的数据恒赋为 1
always @( posedge S_AXI_ACLK )
begin
if (mem_rden)
begin
// mem_data_out[i][(mem_byte_index*8+7) -: 8] <= data_out;
mem_data_out[i][(mem_byte_index*8+7) -: 8] <= 8'b01;
end
end
接下来是优化读事务,官方的 Slave 示例在一次突发中,每次数据传输至少需要 2 个周期,这里将其优化为至少需要 1 个周期,首先我将代码进行了如下的修改(需要注意的是下面的修改是错误的,这里仅仅是将我遇到的问题记录下来)
// 将
// else if((axi_arlen_cntr <= axi_arlen) && axi_rvalid && S_AXI_RREADY)
// 改为
else if((axi_arlen_cntr < axi_arlen) && axi_rvalid && S_AXI_RREADY)
// 将
//else if (axi_rvalid && S_AXI_RREADY)
// begin
// axi_rvalid <= 1'b0;
// end
// 改为
else if (axi_rvalid && S_AXI_RREADY && axi_rlast)
begin
axi_rvalid <= 1'b0;
end
修改后进行仿真出现了问题,起初我以为是项目本身有问题,在查看了很久的波形图和项目代码后,我最终发现问题还是在我修改的 Slave 代码上。按照我上面的修改方式,axi_rlast 的拉高会延迟一个周期,从而使得一次突发中传输的次数比预期的要多 1 次。
在我没有进行上面的修改时,即每次数据传输至少需要 2 个周期,此时的仿真是正确的,但是修改后就出现了问题,起初我以为是由于项目的 Master 不支持一周期一次传输,这导致我 debug 的方向不对,最终饶了一圈,结果发现是 Slave 修改错了
这里给我的一个提示就是,首先要对自己修改的代码要十分谨慎,要先确保没有修改错,其次就是可以进行修改前后一些核心信号的波形图的对比,这样可以更加快速的锁定问题所在
最终正确的修改方式如下
// 将
// else if((axi_arlen_cntr <= axi_arlen) && axi_rvalid && S_AXI_RREADY)
// begin
// axi_arlen_cntr <= axi_arlen_cntr + 1;
// axi_rlast <= 1'b0;
// case (axi_arburst)
// 2'b00: // fixed burst
// // The read address for all the beats in the transaction are fixed
// begin
// axi_araddr <= axi_araddr;
// //for arsize = 4 bytes (010)
// end
// 2'b01: //incremental burst
// // The read address for all the beats in the transaction are increments by awsize
// begin
// axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] <= axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] + 1;
// //araddr aligned to 4 byte boundary
// axi_araddr[ADDR_LSB-1:0] <= {ADDR_LSB{1'b0}};
// //for awsize = 4 bytes (010)
// end
// 2'b10: //Wrapping burst
// // The read address wraps when the address reaches wrap boundary
// if (ar_wrap_en)
// begin
// axi_araddr <= (axi_araddr - ar_wrap_size);
// end
// else
// begin
// axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] <= axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] + 1;
// //araddr aligned to 4 byte boundary
// axi_araddr[ADDR_LSB-1:0] <= {ADDR_LSB{1'b0}};
// end
// default: //reserved (incremental burst for example)
// begin
// axi_araddr <= axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB]+1;
// //for arsize = 4 bytes (010)
// end
// endcase
// end
// else if((axi_arlen_cntr == axi_arlen) && ~axi_rlast && axi_arv_arr_flag )
// begin
// axi_rlast <= 1'b1;
// end
// 修改为
else if((axi_arlen_cntr < axi_arlen) && axi_rvalid && S_AXI_RREADY)
begin
if (axi_arlen_cntr == axi_arlen - 1)
begin
axi_rlast <= 1'b1;
end
else
begin
axi_rlast <= 1'b0;
end
axi_arlen_cntr <= axi_arlen_cntr + 1;
case (axi_arburst)
2'b00: // fixed burst
// The read address for all the beats in the transaction are fixed
begin
axi_araddr <= axi_araddr;
//for arsize = 4 bytes (010)
end
2'b01: //incremental burst
// The read address for all the beats in the transaction are increments by awsize
begin
axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] <= axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] + 1;
//araddr aligned to 4 byte boundary
axi_araddr[ADDR_LSB-1:0] <= {ADDR_LSB{1'b0}};
//for awsize = 4 bytes (010)
end
2'b10: //Wrapping burst
// The read address wraps when the address reaches wrap boundary
if (ar_wrap_en)
begin
axi_araddr <= (axi_araddr - ar_wrap_size);
end
else
begin
axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] <= axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB] + 1;
//araddr aligned to 4 byte boundary
axi_araddr[ADDR_LSB-1:0] <= {ADDR_LSB{1'b0}};
end
default: //reserved (incremental burst for example)
begin
axi_araddr <= axi_araddr[C_S_AXI_ADDR_WIDTH - 1:ADDR_LSB]+1;
//for arsize = 4 bytes (010)
end
endcase
end
// 将
//else if (axi_rvalid && S_AXI_RREADY)
// begin
// axi_rvalid <= 1'b0;
// end
// 改为
else if (axi_rvalid && S_AXI_RREADY && axi_rlast)
begin
axi_rvalid <= 1'b0;
end

















 7527
7527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









