







最近在学3D方向的语义分析。
师兄推荐了一个哔哩大学的将门创投 | 斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理解中的应用!的宝藏视频,我会多看几遍,并写下每次观看笔记。up主的个人网页:http://stanford.edu/~rqi
下文的截图都源自讲解的PPT,在我的资源:祁芮中台点云讲解.pdf
具体代码实现可参照:PointNet++代码的实现
全篇手码,内容较多会持续更新。
带问号的句子都是乘上引下的重点作用,文章分为三篇,这是第二篇,请耐心食用。

正文继续
第二代网络结构——PointNet++
先理解PointNet的缺陷
左边是3D的CNN,类似于2D,把2D的卷积变成了3D而已。网络有多级的特征学习,有不断地对特征的抽象,同时有平移不变性的特点。
与之相比我们看一下PointNet,刚开始做一个高维映射,再做池化。
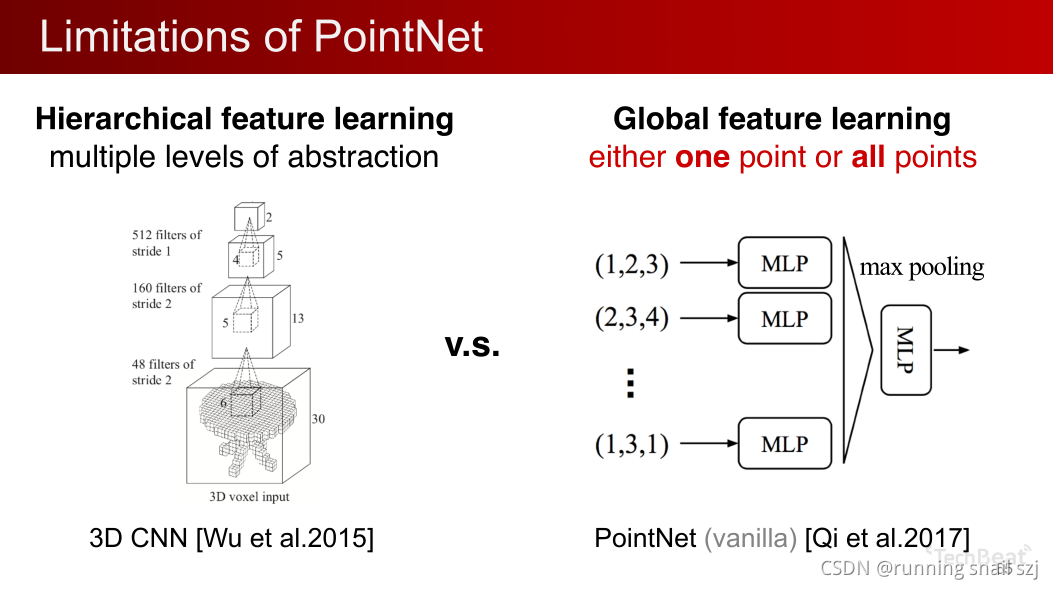
本质上要么对一个点操作,要么对所有点的全局特征操作,这样实际上没有一个局部的概念。No local context,所以比较难对精细的特征进行学习,所以在分割的问题中有一定的局限性。
另外因为没有local context,所以在平移不变性上也有所缺陷。我们知道点云的输入是xyz的坐标,假设对点云做一个平移,那所有的xyz都不一样了,导致所有的特征都不一样了,最后的全局特征也不一样了,分类也会不一样。若单个物体还好办,我们可以把他的平移到坐标系的中心,把他的大小归一化到一个球里边。如果场景中有多个物体就不好办了,因为究竟对哪个物体做归一化呢,所以有平移不变性的缺陷。
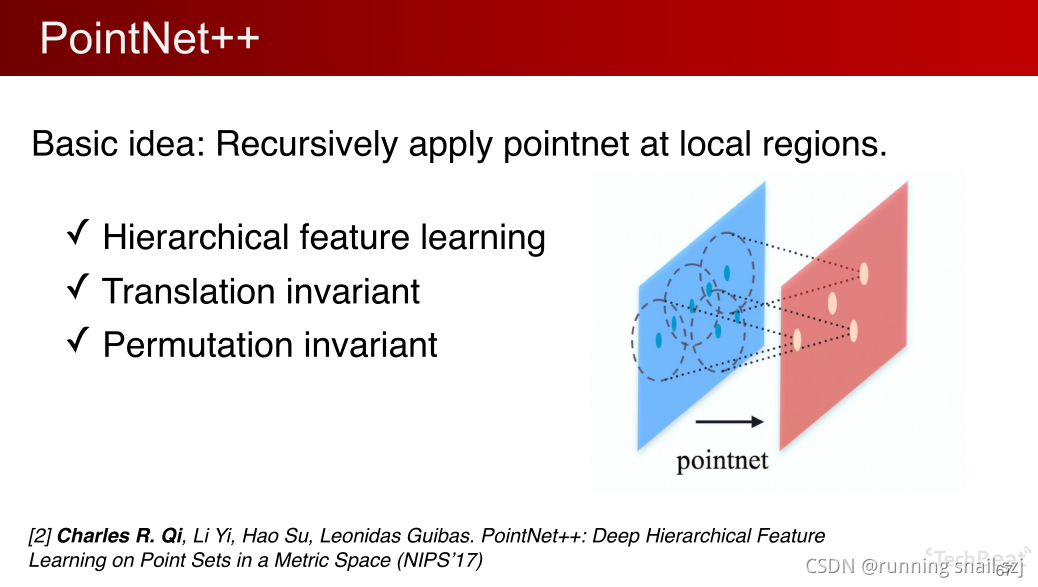
针对上面的问题提出了第二代网络PointNet++,核心的想法是在局部的区域,重复的迭代性的去使用PointNet。
在小区域使用PointNet生成新的点,组成新的点集,又可以定义新的小区域,从而实现多级的特征学习,因为实在区域中我们可以使用局部坐标系,也可以实现平移的不变性。同时因为我们在小区域还是使用的PointNet,对点的顺序无关,整个网络还是保持置换的不变性。
用一个具体的例子来理解,多级的点云特征学习是怎么实现的:
有一个2D的字母A,每一个有坐标xy

先找一个局部的区域,红点周围的小区域,想学这个小区域的特征。因为不想受整体平移的影响,第一步先把这个小区域的点转换到一个局部的坐标系。
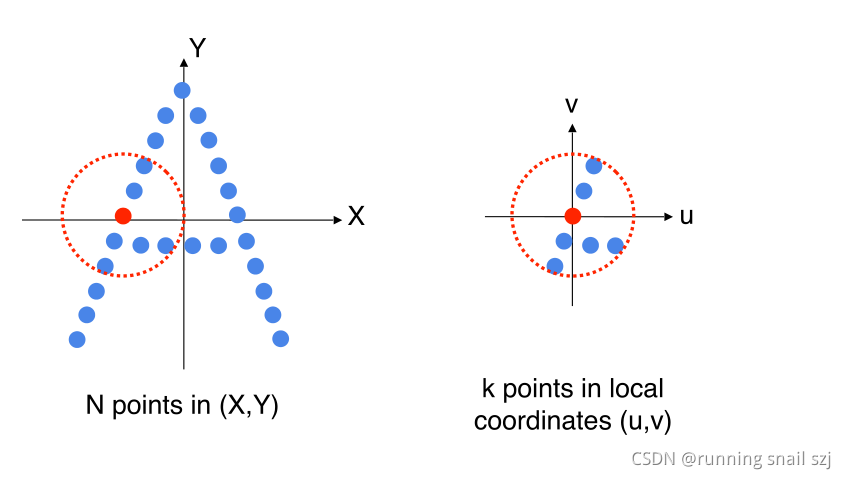
在这个局部坐标系下使用一个pointnet,来提取特征
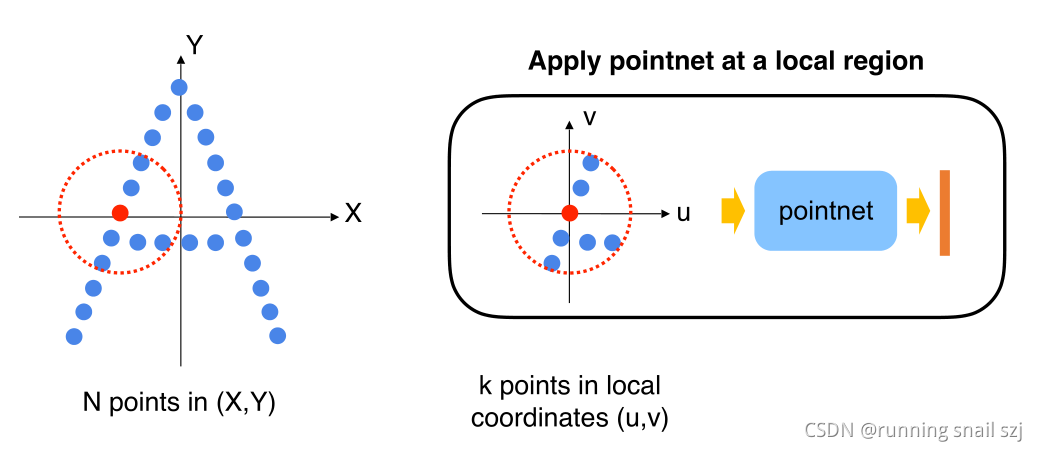
提取完特征会得到一个新的点,这个点不仅有xy代表小区域在整个点云中的位置,还有一个向量特征F代表这个小区域的几何形状。F在高维的特征空间中。
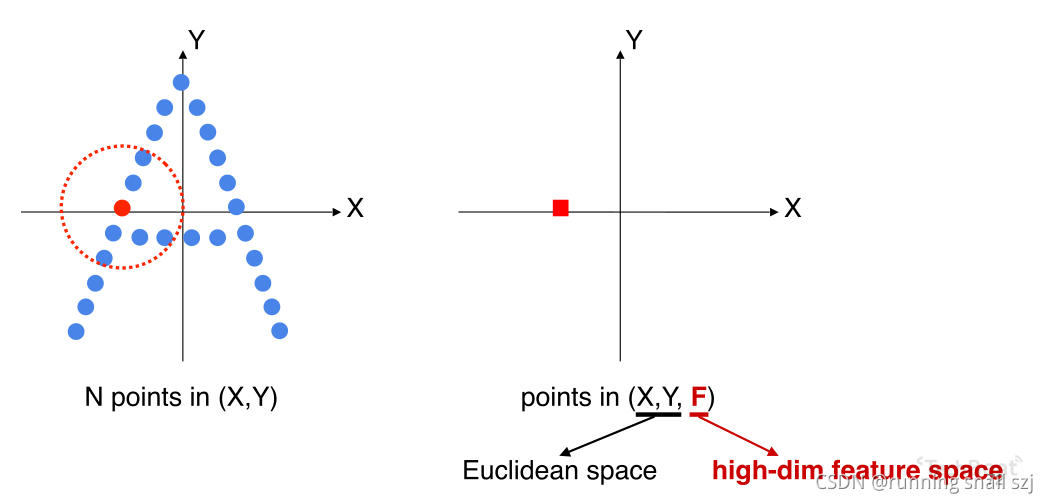
我们重复这个操作,得到另一个区域的代表点
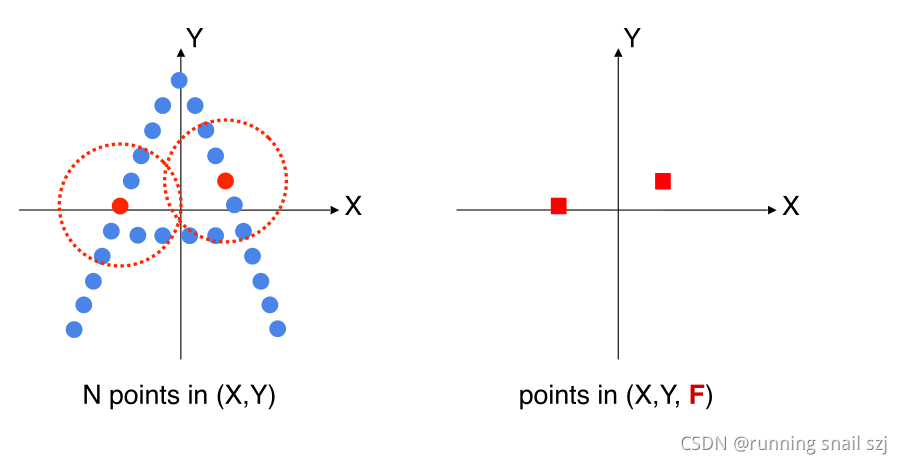
经过一系列操作后就会得到一组新的点,数量上少于原来的点,但每个点代表了周围区域的几何特点,这个操作叫做点集的简化。
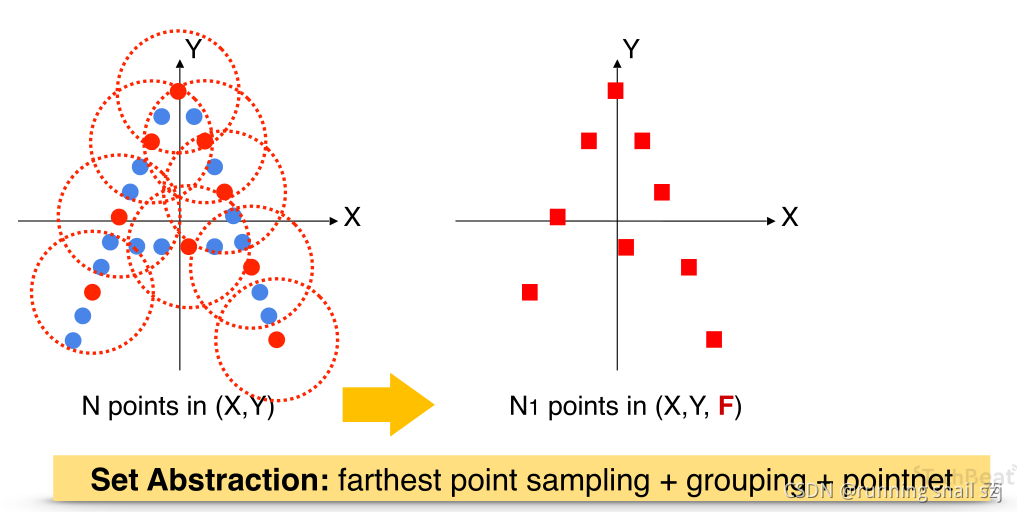
我们可以重复set abstraction点集抽象化的过程,实现一个多级的网络。下图展示了两级,使得点的数量越来越少,代表的特征区域越来越大,和卷积神经网络概念很相似。最后我们对所有的这些得到的点进行point就会得到一个global feature,我们可以用来做整个点的分类。
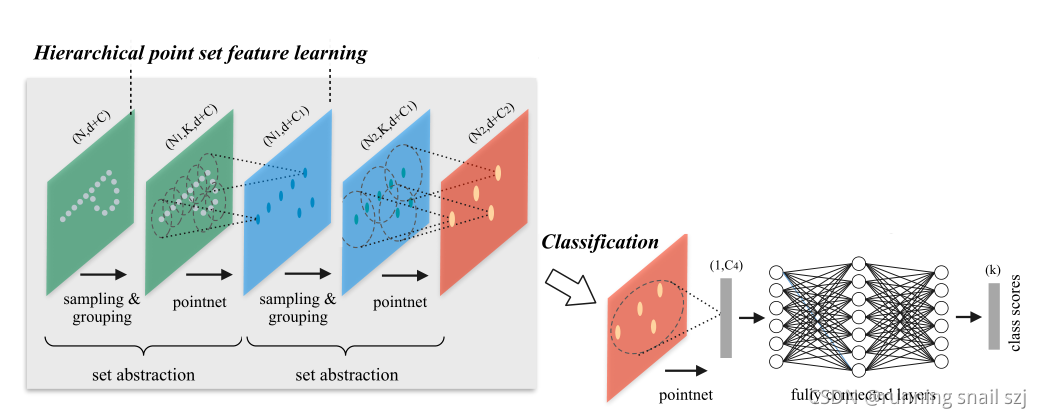
也可以把最后的这个点再重新传回到原来的点上,这个传的方法既可以通过3D点的插值,也可以是通过另一种基于poinetnet的方式。最后实现segmentation
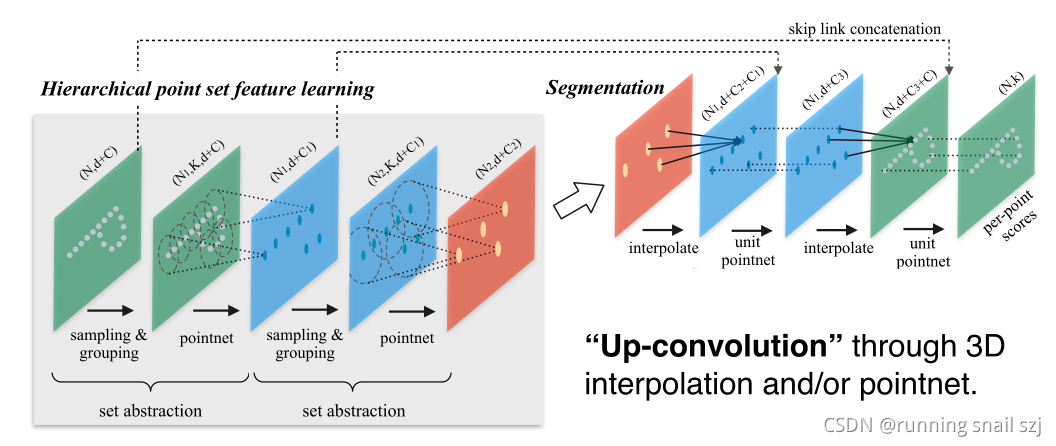
那么问题来了
如何选择小区域的大小?
怎么选择feature的宽度?如何选择poinetnet作用球的半径?
在CNN中现在流行选择非常小的kernel,VGG中大量应用3×3的kernel(内核)。但在poinet cloud中不一定,因为poinet cloud中常见的现象是采样率的不均匀。比如说有一个densite camera采到的图像,近的点很密远的点稀疏,密的地方没关系,稀疏的地方有问题,极端的情况只有一个点,特征不好提取。

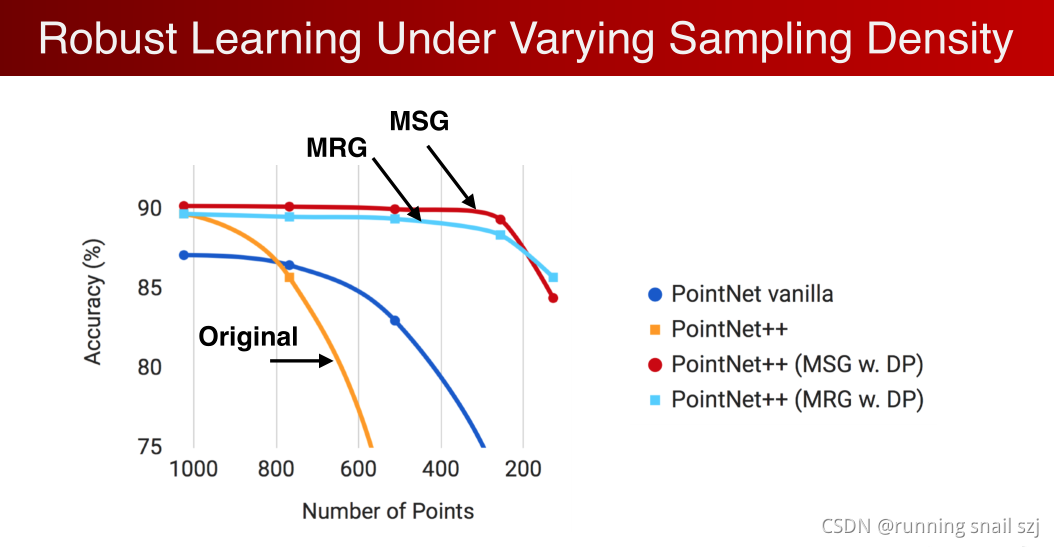
我们用一个量化的实验,从1024个点逐步减少点的数量密度,不均匀减少。
PointNet ++在开始时,功能强大得到更高的分类精确度,但是小区域作用,使其在密度下降后受到较大的影响。
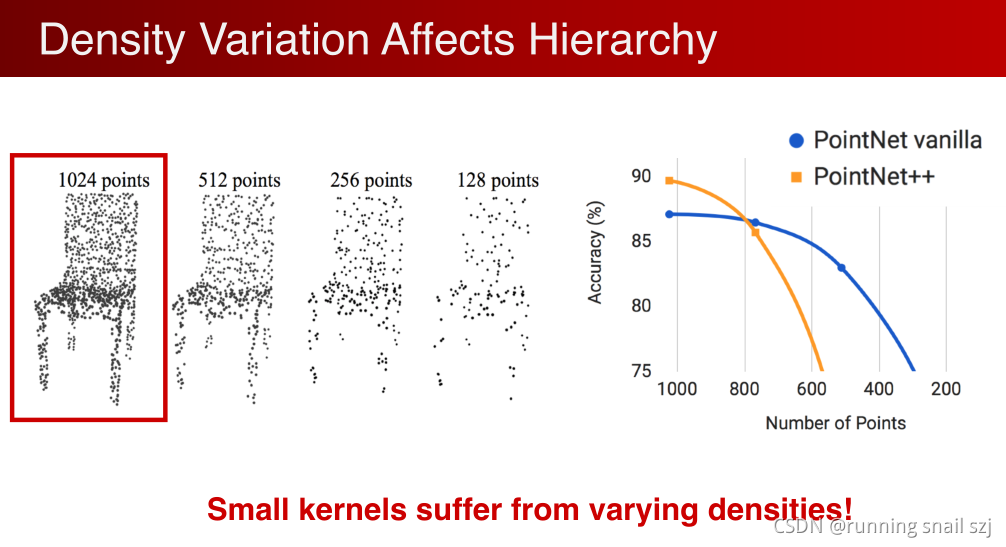
由上面得出kernel(内核)太小的话会因为采样率的不均匀而受影响。
针对这个问题,设计一个新型的网络结构,来智能去学习如何综合不同区域大小的特征来得到一个鲁棒的学习层。背后的原理是,我们希望在密集的地方相信这个特征,在稀疏的地方不信这个特征去看一个更大的区域。
下图简单的方法是(a)通过一个multi-scale的结构,把不同半径区域的特征联合在一起(2D的例子),我们训练过程对随机的输入的dropout,迫使我们的网络学习如何去应对这些损失的数据,如何结合不同尺度上结合数据的性能特征。另一个例子是(b),不是在同一级中综合不同尺度信号,而是在不同网络集中去综合,可以节省计算,因为下级的特征是计算好的,只需要把他池化拿来用就可以。(a)中需要对不同尺度分别计算。(这里b说没时间细讲,我也没听懂)
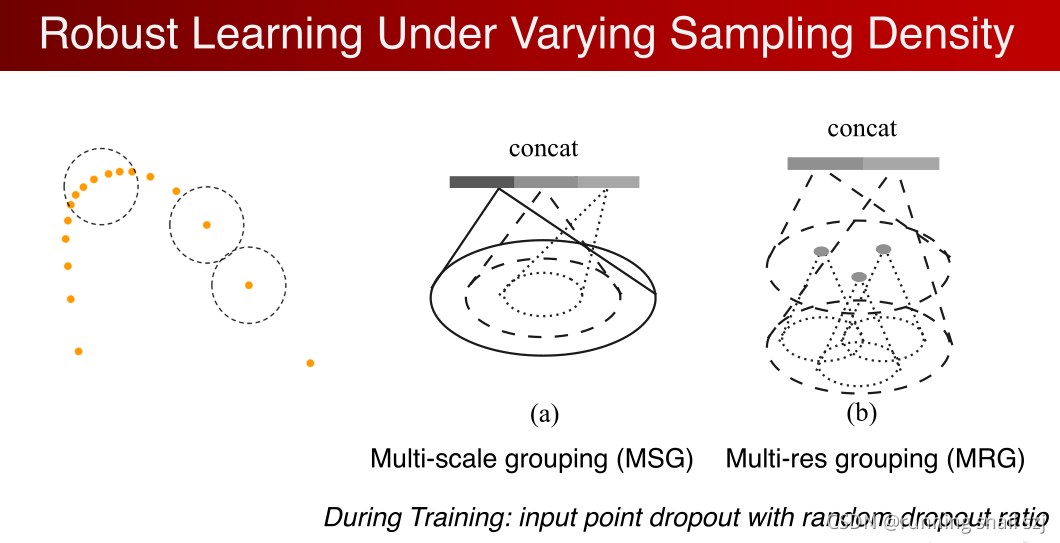
下图展示了采用了上图结构的网络和原来的 PointNet++比对数据的丢失变得更加鲁棒,丢失70%的点对分类无影响。
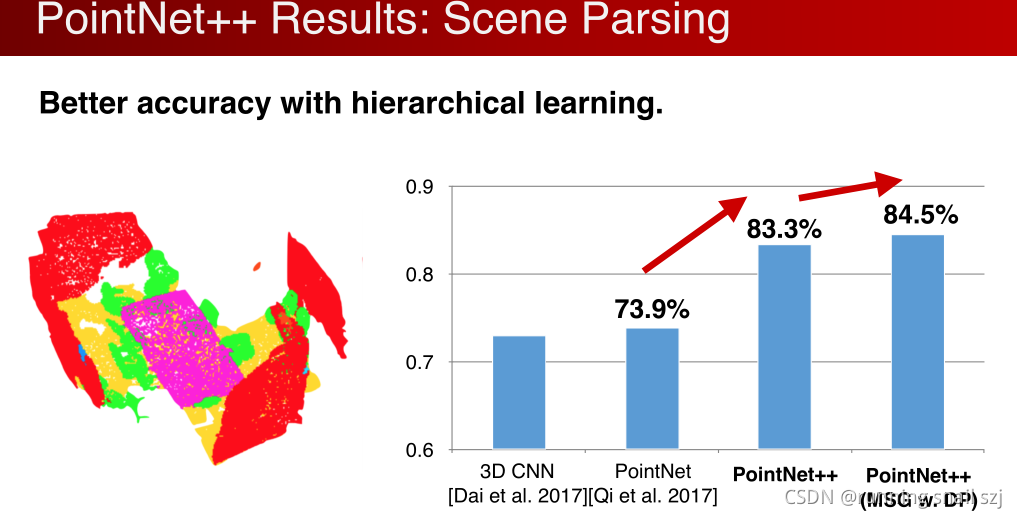
同时这个网络在场景分割上做一个评估。
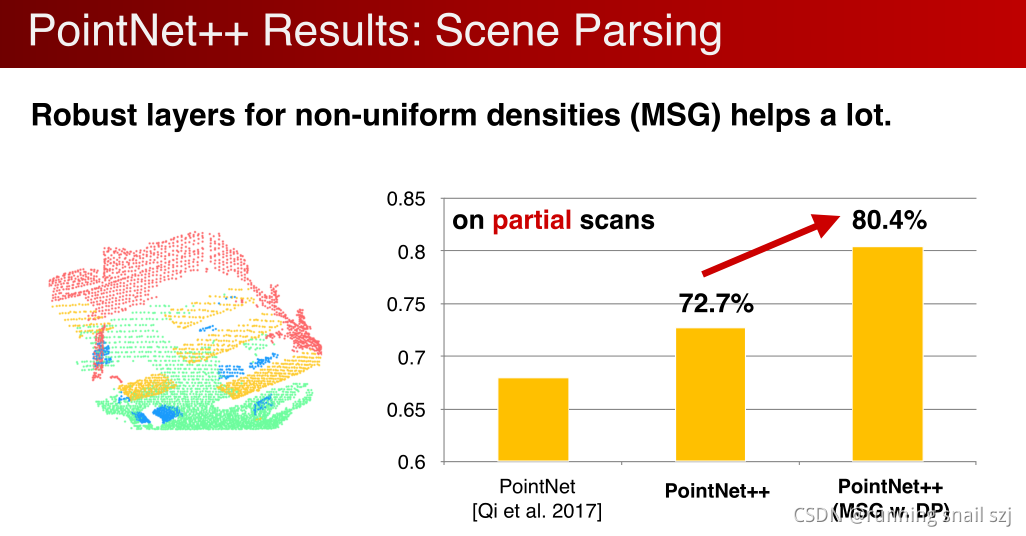
单角度拍摄的局部点云分割,上上上图MSG起作用了。
另一个PointNet++的性能是,他不局限于在2D3D的euclidean space
,他可以在任意的空间。下图是一个对可变形物体分割的数据集,想要对马和猫进行分类,虽然a和b的外形相似,但不同类,a和c虽然外形不相似但属于同一类。我们依靠的不是xyz这种外形上的表达,而是希望在物体表面有一种基于内在特征的学习。

以上充分验证了PointNet++的灵活性。
链接:
点云上的深度学习及其在三维场景理解中的应用————PointNet(一)
点云上的深度学习及其在三维场景理解中的应用————3D Scene Understanding with PointNet and PointNet++(三)














 1084
1084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









