



 本文是作者手写Transformer代码的笔记。介绍了Transformer整体架构,重点讲解Attention机制,包括其目的、Scaled Dot - product Attention和Multi - head Attention的原理与实现。还涉及前馈层、层归一化、位置嵌入等内容,最后给出了Transformer Encoder和Decoder的代码实现。
本文是作者手写Transformer代码的笔记。介绍了Transformer整体架构,重点讲解Attention机制,包括其目的、Scaled Dot - product Attention和Multi - head Attention的原理与实现。还涉及前馈层、层归一化、位置嵌入等内容,最后给出了Transformer Encoder和Decoder的代码实现。
文章目录
概要
不管是深度学习爱好者还是资深的算法工程师,想必都避免不了对transfomer的研究,本篇作为笔者对transfomer代码手写的笔记,仅作为自己记录,毕竟掉包还是不如自己弄懂了踏实。
阅读本文还是要有基础知识的,最好是看过沐神讲解Transfomer的视频。
整体架构流程
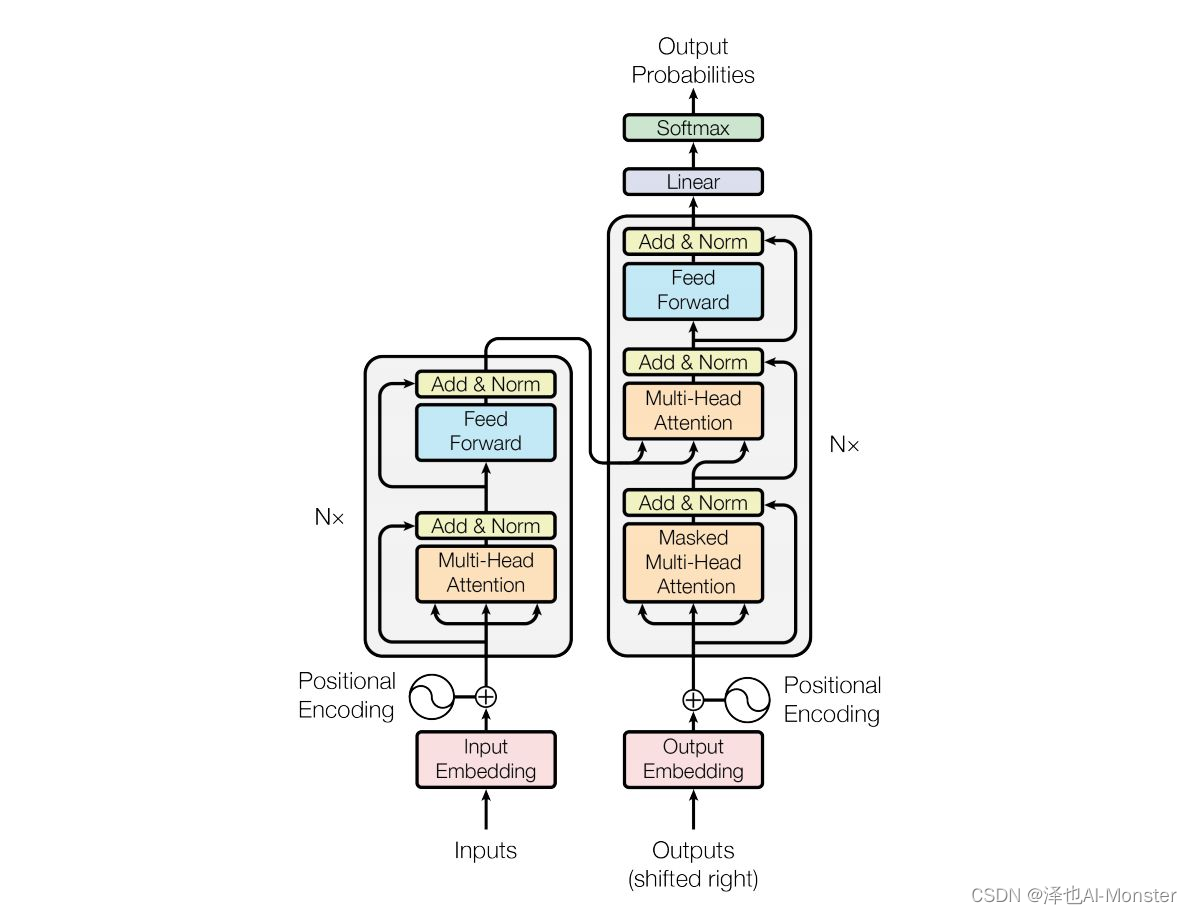
先把Google《Attention is All You Need》论文中的模型结构图拿下来。
先来抽丝剥茧,这个结构图中最重要的是Multi-head Attention,但Multi-head Attention是由Scaled Dot-product Attention改进过来的,想要了解Scaled Dot-product Attention那就要知道Attention的原理。因此下面学Attention部分。
Attention机制
NLP神经网络模型的本质
- 对输入文本进行编码。
- 常规做法是分词,将每个词语转换为词向量,形成词语向量矩阵。
传统编码方式
- 循环网络 (RNNs): 如LSTM,通过递归计算每个词语的编码结果,但速度慢,难以学习全局结构信息。
- 卷积网络 (CNNs): 通过滑动窗口捕获局部信息,速度快,但难以建模长距离语义依赖。
Attention的目的
- Google《Attention is All You Need》提供了第三个方案:直接使用 Attention 机制编码整个文本。
- 直接使用Attention机制编码文本,一步到位获取全局信息。
- 公式表示为:
y
t
=
f
(
x
t
,
A
,
B
)
y_t = f(x_t, A, B)
yt=f(xt,A,B),其中
A和B是词语序列(矩阵)。 - Self-Attention: 当
A = B = X时,即直接比较当前词语与序列中每个词语,计算 y t y_t yt。
知道了为什么要有Attention之后,接下来就来学习常用的 Attention实现方式。
Scaled Dot-product Attention
虽然 Attention 有许多种实现方式,但是最常见的还是 Scaled Dot-product Attention。
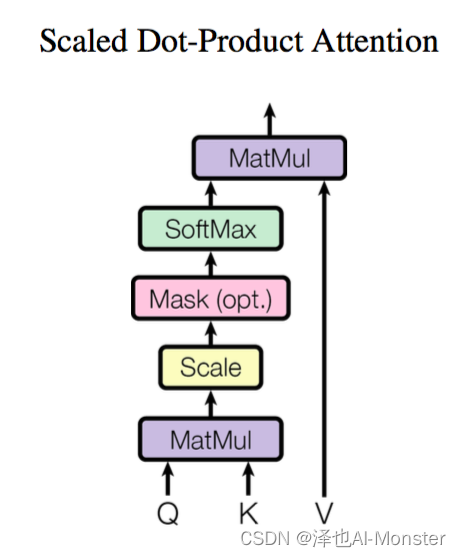
Scaled Dot-product Attention 是 Transformer 模型中使用的一种注意力机制,它的核心步骤如下:
-
输入准备:对于给定的查询(Query)、键(Key)和值(Value)矩阵,这些矩阵通常来源于输入序列的词向量通过不同的线性变换得到。
-
计算注意力权重:计算查询与所有键的点积,得到注意力权重。这个权重分数表示了每个值对于当前查询的重要性。
( Q K T d k ) \left(\frac{QK^T}{\sqrt{d_k}}\right) (dkQKT)
其中, Q Q Q 是查询矩阵, K K K 是键矩阵, d k d_k dk 是键向量的维度,用于缩放点积,防止过大的点积值导致梯度消失问题。
-
应用 Softmax 函数:由于点积可以产生任意大的数字,这会破坏训练过程的稳定性。因此注意力分数还需要乘以一个缩放因子来标准化它们的方差,然后用一个 softmax 标准化。
形式化表示为:
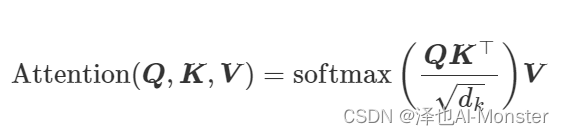
Scaled Dot-product Attention 机制的优势在于它能够捕捉序列中不同部分之间的全局依赖关系,并且计算效率比传统的 RNN 和 CNN 更高。在 Transformer 模型中,这种注意力机制是实现序列到序列映射的关键组件。
代码
通过 Pytorch 来手工实现 Scaled Dot-product Attention:
首先需要将文本分词为词语 (token) 序列,然后将每一个词语转换为对应的词向量 (embedding)。Pytorch 提供了 torch.nn.Embedding 层来完成该操作,即构建一个从 token ID 到 token embedding 的映射表:
# 导入必要的库
from torch import nn # 用于定义神经网络层
from transformers import AutoConfig # 导入自动配置类,用于获取预训练模型的配置
from transformers import AutoTokenizer # 导入自动分词器类,用于文本的分词和编码
# 指定预训练的BERT模型
model_ckpt = "bert-base-uncased"
# 初始化分词器
tokenizer = AutoTokenizer.from_pretrained(model_ckpt) # 从预训练模型加载分词器
# 准备输入文本
text = "time flies like an arrow"
# 使用分词器处理文本,返回特殊的tensor格式
inputs = tokenizer(text, return_tensors="pt", add_special_tokens=False) # 不添加特殊标记
print(inputs.input_ids) # 打印输入的token ids
# 获取模型的配置
config = AutoConfig.from_pretrained(model_ckpt) # 从预训练模型加载配置
# 创建一个嵌入层,用于将token ids转换为词向量
# vocab_size是词汇表的大小,hidden_size是嵌入向量的维度
token_emb = nn.Embedding(config.vocab_size, config.hidden_size)
print(token_emb) # 打印嵌入层
# 将输入的token ids通过嵌入层转换为词向量
inputs_embeds = token_emb(inputs.input_ids) # 调用嵌入层的forward方法
print(inputs_embeds.size()) # 打印词向量的尺寸
tensor([[ 2051, 10029, 2066, 2019, 8612]])
Embedding(30522, 768)
torch.Size([1, 5, 768])
可以看到,BERT-base-uncased 模型对应的词表大小为 30522,每个词语的词向量维度为 768。Embedding 层把输入的词语序列映射到了尺寸为 [batch_size, seq_len, hidden_dim] 的张量。
inputs_embeds.size() 将返回一个元组,其中 1 表示批次大小为1(单个样本),seq_length 表示输入文本中的单词数量(在这个例子中是短语 “time flies like an arrow” 中的单词数),embedding_dim 是BERT模型的隐藏层大小,对于bert-base-uncased模型,这个维度通常是768。
接下来就是创建 query、key、value 向量序列,并且使用点积作为相似度函数来计算注意力分数:
import torch
from math import sqrt # 用于计算平方根
# 假设inputs_embeds是之前步骤中得到的词嵌入向量,这里同时作为查询(Q)、键(K)和值(V)
Q = K = V = inputs_embeds # 这里的Q, K, V是相同的词嵌入向量,但在实际应用中它们可能来自不同的输入
# 获取键(K)的维度大小,即键的嵌入维度
dim_k = K.size(-1) # -1表示最后一个维度,这里是嵌入向量的维度
# 计算注意力分数
'''
为了计算Q和K的点积,我们需要调整K的维度,以便它与Q的维度兼容。原始的K矩阵具有形状(batch_size, sent_len, emb_dim),
为了执行矩阵乘法,我们需要将K的第二个和第三个维度交换,这里我们可以使用转置操作transpose(1, 2)将K的维度变为(batch_size, emb_dim, sent_len)。
现在,Q和K的形状都是(batch_size, sent_len, emb_dim),我们可以执行矩阵乘法。
Q 的形状:(batch_size, sent_len, emb_dim)
K 的转置的形状:(batch_size, emb_dim, sent_len)
注意力分数的形状:(batch_size, sent_len, sent_len)
'''
# 每个分数表示一个查询向量与所有键向量之间的相似度
scores = torch.bmm(Q, K.transpose(1, 2)) / sqrt(dim_k) # 计算得到的分数矩阵并缩放
# 这个矩阵中的每个元素表示一个查询向量与一个键向量之间的相似度分数。
# 打印注意力分数的形状
print(scores.size()) # 应该输出(batch_size, sent_len, sent_len)
# 具体来说,scores 的每个元素 scores[b, i, j] 表示第 b 个批次中第 i 个查询向量与第 j 个键向量之间的相似度分数。
torch.Size([1, 5, 5])
这里 Q,K 的序列长度都为 5,因此生成了一个 5×5的注意力分数矩阵,接下来就是应用 Softmax 标准化注意力权重:
import torch.nn.functional as F # PyTorch的nn.functional模块,包含了许多神经网络操作的函数
# 使用softmax函数对注意力分数进行归一化,得到注意力权重
# softmax函数将查询向量与键向量的相似度分数转换成一个概率分布。
# 这里的dim=-1指定了softmax操作的维度,即沿着最后一个维度(sent_len)进行,这个维度表示的是键向量的索引。
'''
简单讲下,假设
scores = [[[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0],
[7.0, 8.0, 9.0]]]
1.计算每个元素的指数值:
exp_scores = [[[exp(1.0), exp(2.0), exp(3.0)],
[exp(4.0), exp(5.0), exp(6.0)],
[exp(7.0), exp(8.0), exp(9.0)]]]
2.计算每个查询向量的指数值之和:
sum_exp_scores = [[exp(1.0) + exp(2.0) + exp(3.0),
exp(4.0) + exp(5.0) + exp(6.0),
exp(7.0) + exp(8.0) + exp(9.0)]]
3.计算 softmax 值:
softmax_scores = [[[exp(1.0) / sum_exp_scores[0][0], exp(2.0) / sum_exp_scores[0][0], exp(3.0) / sum_exp_scores[0][0]],
[exp(4.0) / sum_exp_scores[0][1], exp(5.0) / sum_exp_scores[0][1], exp(6.0) / sum_exp_scores[0][1]],
[exp(7.0) / sum_exp_scores[0][2], exp(8.0) / sum_exp_scores[0][2], exp(9.0) / sum_exp_scores[0][2]]]]
至于为什么不能在查询向量上面做,主要是因为查询向量和键向量的作用不同。查询向量(Q)用于表示我们想要获取信息的请求,而键向量(K)用于表示与查询向量进行比较的键。
'''
weights = F.softmax(scores, dim=-1)
# 打印权重的和,dim=-1表示沿着最后一个维度(即每个词的权重和)进行求和
# 由于softmax函数的输出是概率分布,每个维度的和应该接近1(如果不是1,可能是由于浮点数精度问题)
print(weights.sum(dim=-1)) # 打印每个查询词的权重和,理论上应该接近1
tensor([[1., 1., 1., 1., 1.]], grad_fn=<SumBackward1>)
最后将注意力权重与 value 序列相乘:
attn_outputs = torch.bmm(weights, V)
print(attn_outputs.shape)
torch.Size([1, 5, 768])
至此就实现了一个简化版的 Scaled Dot-product Attention。可以将上面这些操作封装为函数以方便后续调用:
import torch
import torch.nn.functional as F # 导入PyTorch的nn.functional模块,包含了许多神经网络操作的函数
from math import sqrt # 导入math库中的sqrt函数,用于计算平方根
# 定义Scaled Dot-product Attention函数
def scaled_dot_product_attention(query, key, value, query_mask=None, key_mask=None, mask=None):
# 获取查询(query)的最后一个维度大小,即键(key)的维度
dim_k = query.size(-1)
# 计算查询和键的点积,并缩放,得到未归一化的注意力分数
scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(dim_k)
# 如果提供了查询掩码(query_mask)和键掩码(key_mask),则计算掩码矩阵
if query_mask is not None and key_mask is not None:
mask = torch.bmm(query_mask.unsqueeze(-1), key_mask.unsqueeze(1))
else:
# 如果没有提供掩码,则使用之前传入的掩码(如果有的话)
mask = mask
# 如果存在掩码,则将分数矩阵中与掩码对应位置为0的分数替换为负无穷
# 这样在应用softmax时,这些位置的权重会接近于0
if mask is not None:
scores = scores.masked_fill(mask == 0, -float("inf"))
# 使用softmax函数对分数进行归一化,得到注意力权重
weights = F.softmax(scores, dim=-1)
# 计算加权后的输出,即将注意力权重与值(value)相乘
# 这里的输出是经过注意力加权后的值向量,用于下游任务
return torch.bmm(weights, value)
上面的做法会带来一个问题:当 Q 和 K 序列相同时,注意力机制会为上下文中的相同单词分配非常大的分数(点积为 1),而在实践中,相关词往往比相同词更重要。例如对于上面的例子,只有关注“time”和“arrow”才能够确认“flies”的含义。
因此,多头注意力 (Multi-head Attention) 出现了!
Multi-head Attention
Multi-head Attention 首先通过线性映射将 Q,K,V 序列映射到特征空间,每一组线性投影后的向量表示称为一个头 (head),然后在每组映射后的序列上再应用 Scaled Dot-product Attention:

每个注意力头负责关注某一方面的语义相似性,多个头就可以让模型同时关注多个方面。
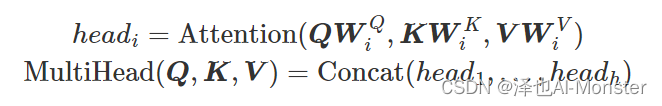
所谓的“多头” (Multi-head),其实就是多做几次 Scaled Dot-product Attention,然后把结果拼接。
下面我们首先实现一个注意力头:
from torch import nn
# 定义AttentionHead类,继承自nn.Module
class AttentionHead(nn.Module):
# 初始化函数
def __init__(self, embed_dim, head_dim):
super().__init__() # 调用基类的初始化方法
# 定义线性层,用于将输入的词嵌入向量转换为查询(q)、键(k)和值(v)向量
# embed_dim是输入嵌入的维度,head_dim是每个头输出的维度
self.q = nn.Linear(embed_dim, head_dim)
self.k = nn.Linear(embed_dim, head_dim)
self.v = nn.Linear(embed_dim, head_dim)
# 前向传播函数
def forward(self, query, key, value, query_mask=None, key_mask=None, mask=None):
# 调用scaled_dot_product_attention函数,传入通过线性层转换后的查询、键和值
# 同时传入可选的掩码参数
attn_outputs = scaled_dot_product_attention(
self.q(query), # 经过查询线性层转换的query
self.k(key), # 经过键线性层转换的key
self.v(value), # 经过值线性层转换的value
query_mask, # 查询掩码
key_mask, # 键掩码
mask # 已有的掩码(如果有的话)
)
# 返回注意力机制的输出
return attn_outputs
每个头都会初始化三个独立的线性层,负责将 Q,K,V序列映射到尺寸为 [batch_size, seq_len, head_dim] 的张量,其中 head_dim 是映射到的向量维度。
实践中一般将 head_dim 设置为 embed_dim 的因数,这样 token 嵌入式表示的维度就可以保持不变,例如 BERT 有 12 个注意力头,因此每个头的维度被设置为768/12=64。
最后只需要拼接多个注意力头的输出就可以构建出 Multi-head Attention 层了(这里在拼接后还通过一个线性变换来生成最终的输出张量):
from torch import nn
# 定义MultiHeadAttention类,继承自nn.Module
class MultiHeadAttention(nn.Module):
# 初始化函数
def __init__(self, config):
super().__init__() # 调用基类的初始化方法
# 从配置中获取嵌入维度和注意力头的数量
embed_dim = config.hidden_size
num_heads = config.num_attention_heads
# 计算每个头的维度大小
head_dim = embed_dim // num_heads
# 创建一个包含多个AttentionHead模块的列表
# 每个头都使用相同的嵌入维度和头维度
self.heads = nn.ModuleList(
[AttentionHead(embed_dim, head_dim) for _ in range(num_heads)]
)
# 定义输出线性层,用于将多头注意力的输出合并
self.output_linear = nn.Linear(embed_dim, embed_dim)
# 前向传播函数
def forward(self, query, key, value, query_mask=None, key_mask=None, mask=None):
# 并行通过每个注意力头处理输入
# 使用torch.cat将所有头的输出在最后一个维度上拼接起来
x = torch.cat([
h(query, key, value, query_mask, key_mask, mask) for h in self.heads
], dim=-1)
# 通过输出线性层处理拼接后的输出
x = self.output_linear(x)
# 返回最终的输出
return x
这里使用 BERT-base-uncased 模型的参数初始化 Multi-head Attention 层,并且将之前构建的输入送入模型以验证是否工作正常:
from transformers import AutoConfig
from transformers import AutoTokenizer
model_ckpt = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
text = "time flies like an arrow"
inputs = tokenizer(text, return_tensors="pt", add_special_tokens=False)
config = AutoConfig.from_pretrained(model_ckpt)
token_emb = nn.Embedding(config.vocab_size, config.hidden_size)
inputs_embeds = token_emb(inputs.input_ids)
multihead_attn = MultiHeadAttention(config)
query = key = value = inputs_embeds
attn_output = multihead_attn(query, key, value)
print(attn_output.size()) #torch.Size([1, 5, 768])
The Feed-Forward Layer
Transformer Encoder/Decoder 中的前馈子层实际上就是两层全连接神经网络,它单独地处理序列中的每一个词向量,也被称为 position-wise feed-forward layer。常见做法是让第一层的维度是词向量大小的 4 倍,然后以 GELU 作为激活函数。
下面实现一个简单的 Feed-Forward Layer:
from torch import nn
# 定义FeedForward类,继承自nn.Module
class FeedForward(nn.Module):
# 初始化函数
def __init__(self, config):
super().__init__() # 调用基类的初始化方法
# 定义第一个线性层,将输入的隐藏状态映射到中间维度
self.linear_1 = nn.Linear(config.hidden_size, config.intermediate_size)
# 定义第二个线性层,将中间维度的表示映射回原始的隐藏状态维度
self.linear_2 = nn.Linear(config.intermediate_size, config.hidden_size)
# 定义GELU激活函数
self.gelu = nn.GELU()
# 定义Dropout层,用于防止过拟合
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# 前向传播函数
def forward(self, x):
# 应用第一个线性层
x = self.linear_1(x)
# 应用GELU激活函数
x = self.gelu(x)
# 应用第二个线性层
x = self.linear_2(x)
# 应用Dropout
x = self.dropout(x)
# 返回最终的输出
return x
将前面注意力层的输出送入到该层中以测试是否符合我们的预期:
feed_forward = FeedForward(config)
ff_outputs = feed_forward(attn_output)
print(ff_outputs.size()) #torch.Size([1, 5, 768])
至此创建完整 Transformer Encoder 的所有要素都已齐备,只需要再加上 Skip Connections 和 Layer Normalization 就大功告成了。
Layer Normalization
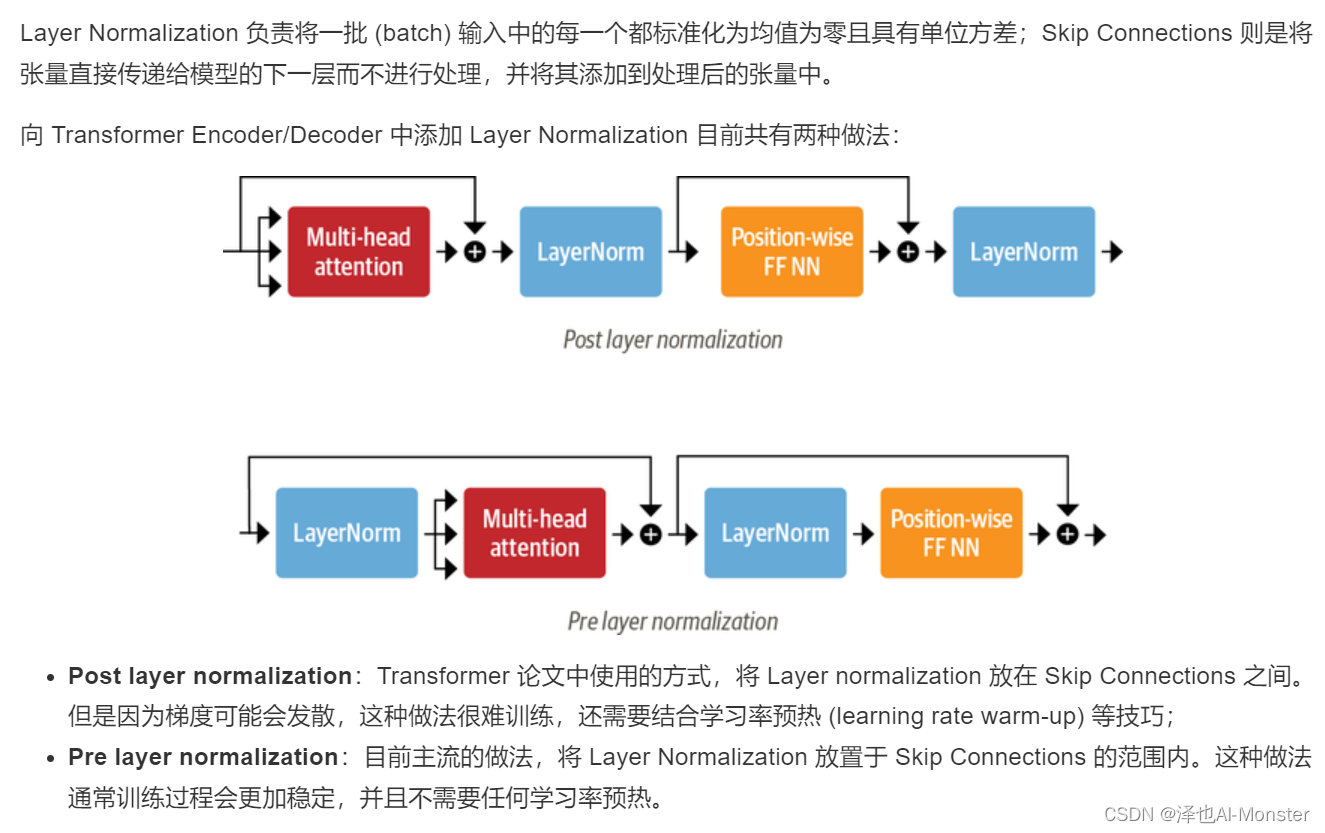
采用第二种方式来构建 Transformer Encoder 层:
from torch import nn
# 定义TransformerEncoderLayer类,继承自nn.Module
class TransformerEncoderLayer(nn.Module):
# 初始化函数
def __init__(self, config):
super().__init__() # 调用基类的初始化方法
# 定义第一个层归一化,用于注意力机制之前
self.layer_norm_1 = nn.LayerNorm(config.hidden_size)
# 定义第二个层归一化,用于前馈网络之前
self.layer_norm_2 = nn.LayerNorm(config.hidden_size)
# 定义多头注意力机制
self.attention = MultiHeadAttention(config)
# 定义前馈神经网络
self.feed_forward = FeedForward(config)
# 前向传播函数
def forward(self, x, mask=None):
# 应用第一个层归一化
hidden_state = self.layer_norm_1(x)
# 应用注意力机制,并将结果与输入进行残差连接
# 注意力机制的输出将与输入x相加,得到更新后的x
x = x + self.attention(hidden_state, hidden_state, hidden_state, mask=mask)
# 应用第二个层归一化
# 注意这里的self.layer_norm_2(x)实际上是对更新后的x进行归一化
hidden_state = self.layer_norm_2(x)
# 应用前馈网络,并将结果与更新后的x进行残差连接
x = x + self.feed_forward(hidden_state)
# 返回最终的输出x
return x
同样地,这里将之前构建的输入送入到该层中进行测试:
encoder_layer = TransformerEncoderLayer(config)
print(inputs_embeds.shape)
print(encoder_layer(inputs_embeds).size())
#torch.Size([1, 5, 768])
#torch.Size([1, 5, 768])
Positional Embeddings
前面讲过,由于注意力机制无法捕获词语之间的位置信息,因此 Transformer 模型还使用 Positional Embeddings 添加了词语的位置信息。
Positional Embeddings 基于一个简单但有效的想法:使用与位置相关的值模式来增强词向量。
如果预训练数据集足够大,那么最简单的方法就是让模型自动学习位置嵌入。下面本章就以这种方式创建一个自定义的 Embeddings 模块,它同时将词语和位置映射到嵌入式表示,最终的输出是两个表示之和:
from torch import nn, LongTensor, arange
# 定义Embeddings类,继承自nn.Module
class Embeddings(nn.Module):
# 初始化函数
def __init__(self, config):
super().__init__() # 调用基类的初始化方法
# 定义词嵌入层,将词ID映射到词向量
self.token_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
# 定义位置嵌入层,为序列中的每个位置生成一个唯一的位置向量
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
# 定义层归一化,用于稳定训练过程
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=1e-12)
# 定义Dropout层,用于防止过拟合
self.dropout = nn.Dropout(config.hidden_dropout_prob) # 初始化dropout层
# 前向传播函数
def forward(self, input_ids):
# 根据输入序列的长度创建位置ID
seq_length = input_ids.size(1) # 获取序列长度
position_ids = torch.arange(seq_length, dtype=torch.long).unsqueeze(0) # 创建位置ID序列
# 创建词嵌入和位置嵌入
token_embeddings = self.token_embeddings(input_ids) # 通过词嵌入层获取词嵌入
position_embeddings = self.position_embeddings(position_ids) # 通过位置嵌入层获取位置嵌入
# 将词嵌入和位置嵌入相加,得到最终的嵌入表示
embeddings = token_embeddings + position_embeddings
# 应用层归一化
embeddings = self.layer_norm(embeddings)
# 应用Dropout
embeddings = self.dropout(embeddings)
# 返回最终的嵌入表示
return embeddings
# 创建Embeddings层的实例,并使用config配置
embedding_layer = Embeddings(config)
# 使用embedding_layer处理输入的词ID,并打印输出的大小
# 这里假设inputs.input_ids是之前通过tokenizer得到的词ID序列
print(embedding_layer(inputs.input_ids).size()) #torch.Size([1, 5, 768])
Transformer Encoder:
接下来我们将上面的函数封装一下:
from torch import nn
# 定义TransformerEncoder类,继承自nn.Module
class TransformerEncoder(nn.Module):
# 初始化函数
def __init__(self, config):
super().__init__() # 调用基类的初始化方法
# 创建嵌入层实例,用于将输入的词ID转换为嵌入向量
self.embeddings = Embeddings(config)
# 创建一个包含多个Transformer编码器层的列表
# num_hidden_layers表示编码器中隐藏层的数量
self.layers = nn.ModuleList([TransformerEncoderLayer(config) for _ in range(config.num_hidden_layers)])
# 前向传播函数
def forward(self, x, mask=None):
# 首先通过嵌入层处理输入x
x = self.embeddings(x)
# 然后依次通过每个编码器层
for layer in self.layers:
# 将当前层的输出作为下一层的输入,并传递掩码(如果有的话)
x = layer(x, mask=mask)
# 返回最终的编码器输出
return x
同样地,我们对该层进行简单的测试:
encoder = TransformerEncoder(config)
print(encoder(inputs.input_ids).size()) #torch.Size([1, 5, 768])
完整代码
import torch
from torch import nn
import torch.nn.functional as F
from math import sqrt
class AttentionHead(nn.Module):
def __init__(self, embed_dim, head_dim):
super().__init__()
self.q = nn.Linear(embed_dim, head_dim)
self.k = nn.Linear(embed_dim, head_dim)
self.v = nn.Linear(embed_dim, head_dim)
def forward(self, query, key, value, mask=None):
query, key, value = self.q(query), self.k(key), self.v(value)
scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(query.size(-1))
if mask is not None:
scores = scores.masked_fill(mask == 0, -float("inf"))
weights = F.softmax(scores, dim=-1)
return torch.bmm(weights, value)
class MultiHeadAttention(nn.Module):
def __init__(self, config):
super().__init__()
embed_dim = config.hidden_size
num_heads = config.num_attention_heads
head_dim = embed_dim // num_heads
self.heads = nn.ModuleList(
[AttentionHead(embed_dim, head_dim) for _ in range(num_heads)]
)
self.output_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, query, key, value, mask=None, query_mask=None, key_mask=None):
if query_mask is not None and key_mask is not None:
mask = torch.bmm(query_mask.unsqueeze(-1), key_mask.unsqueeze(1))
x = torch.cat([h(query, key, value, mask) for h in self.heads], dim=-1)
x = self.output_linear(x)
return x
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.linear_1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.linear_2 = nn.Linear(config.intermediate_size, config.hidden_size)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, x):
x = self.linear_1(x)
x = self.gelu(x)
x = self.linear_2(x)
x = self.dropout(x)
return x
class TransformerEncoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.layer_norm_1 = nn.LayerNorm(config.hidden_size)
self.layer_norm_2 = nn.LayerNorm(config.hidden_size)
self.attention = MultiHeadAttention(config)
self.feed_forward = FeedForward(config)
def forward(self, x, mask=None):
# Apply layer normalization and then copy input into query, key, value
hidden_state = self.layer_norm_1(x)
# Apply attention with a skip connection
x = x + self.attention(hidden_state, hidden_state, hidden_state, mask=mask)
# Apply feed-forward layer with a skip connection
x = x + self.feed_forward(self.layer_norm_2(x))
return x
class Embeddings(nn.Module):
def __init__(self, config):
super().__init__()
self.token_embeddings = nn.Embedding(config.vocab_size,
config.hidden_size)
self.position_embeddings = nn.Embedding(config.max_position_embeddings,
config.hidden_size)
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=1e-12)
self.dropout = nn.Dropout()
def forward(self, input_ids):
# Create position IDs for input sequence
seq_length = input_ids.size(1)
position_ids = torch.arange(seq_length, dtype=torch.long).unsqueeze(0)
# Create token and position embeddings
token_embeddings = self.token_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
# Combine token and position embeddings
embeddings = token_embeddings + position_embeddings
embeddings = self.layer_norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
class TransformerEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.embeddings = Embeddings(config)
self.layers = nn.ModuleList(
[TransformerEncoderLayer(config) for _ in range(config.num_hidden_layers)]
)
def forward(self, x, mask=None):
x = self.embeddings(x)
for layer in self.layers:
x = layer(x, mask)
return x
if __name__ == '__main__':
from transformers import AutoConfig
from transformers import AutoTokenizer
model_ckpt = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
config = AutoConfig.from_pretrained(model_ckpt)
text = "time flies like an arrow"
inputs = tokenizer(text, return_tensors="pt", add_special_tokens=False)
encoder = TransformerEncoder(config)
print(encoder(inputs.input_ids).size())
Transformer Decoder
Transformer Decoder 与 Encoder 最大的不同在于 Decoder 有两个注意力子层,如下图所示:

与 Encoder 中的 Mask 不同,Decoder 的 Mask 是一个下三角矩阵:
这里使用 PyTorch 自带的 tril() 函数来创建下三角矩阵,然后同样地,通过 Tensor.masked_fill() 将所有零替换为负无穷大来防止注意力头看到未来的词语而造成信息泄露:
seq_len = inputs.input_ids.size(-1)
mask = torch.tril(torch.ones(seq_len, seq_len)).unsqueeze(0)
scores.masked_fill(mask == 0, -float("inf"))
参考
[1] 《Attention is All You Need》浅读(简介+代码)
[2] 《Natural Language Processing with Transformers》
[3] 《Transformer 第三章:注意力机制》


















 2320
2320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









