







系列文章目录
机器学习笔记——梯度下降、反向传播
机器学习笔记——用pytorch实现线性回归
机器学习笔记——pytorch实现逻辑斯蒂回归Logistic regression
机器学习笔记——多层线性(回归)模型 Multilevel (Linear Regression) Model
深度学习笔记——pytorch构造数据集 Dataset and Dataloader
深度学习笔记——pytorch解决多分类问题 Multi-Class Classification
深度学习笔记——pytorch实现卷积神经网络CNN
深度学习笔记——卷积神经网络CNN进阶
深度学习笔记——循环神经网络 RNN
深度学习笔记——pytorch实现GRU
前言
参考视频——B站刘二大人《PyTorch深度学习实践》
一、梯度下降 Gradient-Descent
梯度就是导数,梯度下降法就是一种通过求目标函数的导数来寻找目标函数最小化的方法。
最优化问题在机器学习中有非常重要的地位,很多机器学习算法最后都归结为求解最优化问题。最优化问题是求解函数极值的问题,包括极大值和极小值。在各种最优化算法中,梯度下降法是最简单、最常见的一种,在深度学习的训练中被广为使用。
写了半天发现有个博主把我想写的都写了,而且人家还写得更好(哈哈哈哈),直接贴链接了。
什么是梯度下降
权重更新的公式推导

本文最后一节贴有代码
二、反向传播 Back-propagation
反向传播(BP, back propagation)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。
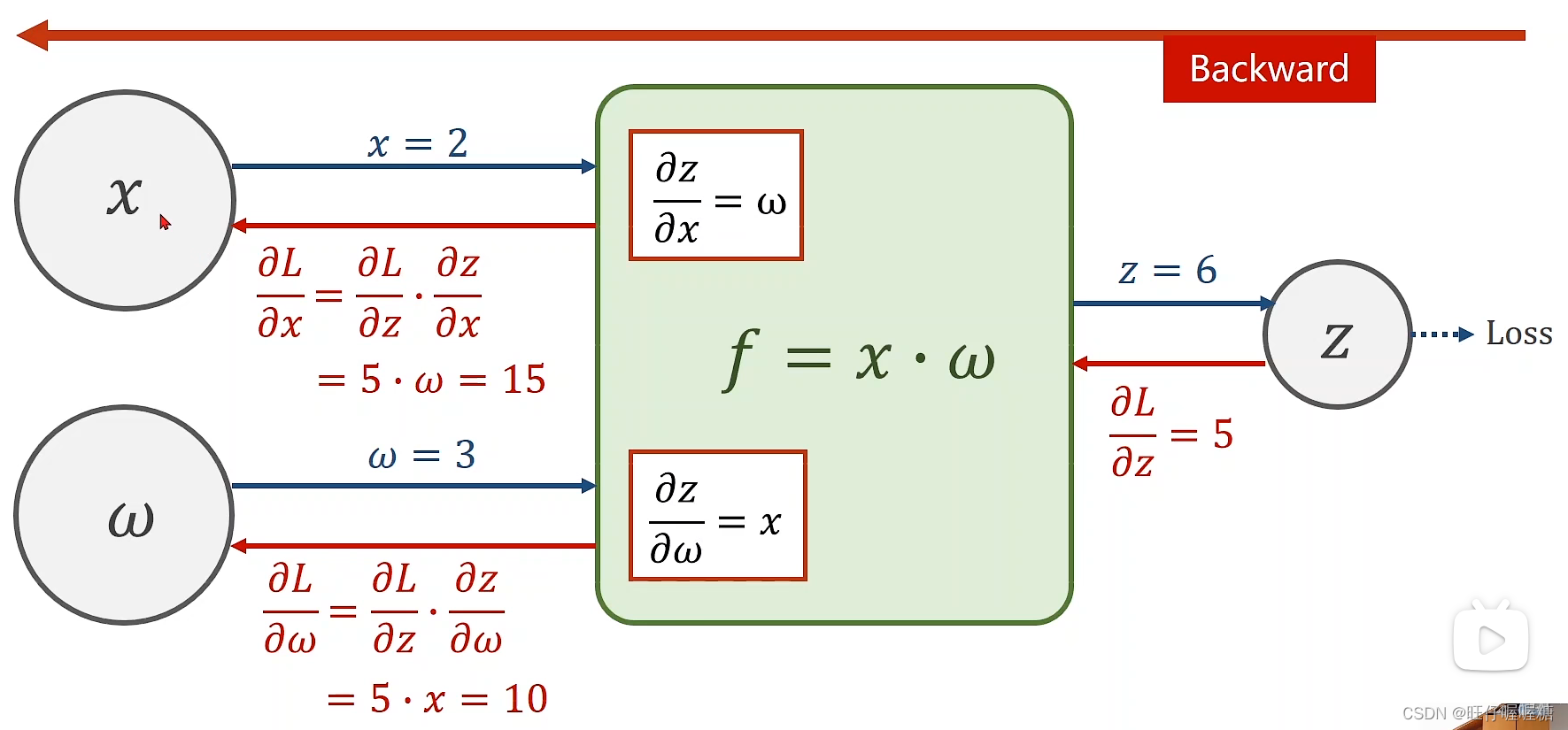
完成前向计算之后,根据链式求导法则,进行后向计算,可以求出梯度值。算出梯度值之后根据完成梯度下降计算。

两层的神经网络结构

然而发现,在多层的这种线性结构中,最终都可以简化为一层,做多少层都没有意义。

所以需要在此结构中加入一个非线性函数(如sigmod函数)
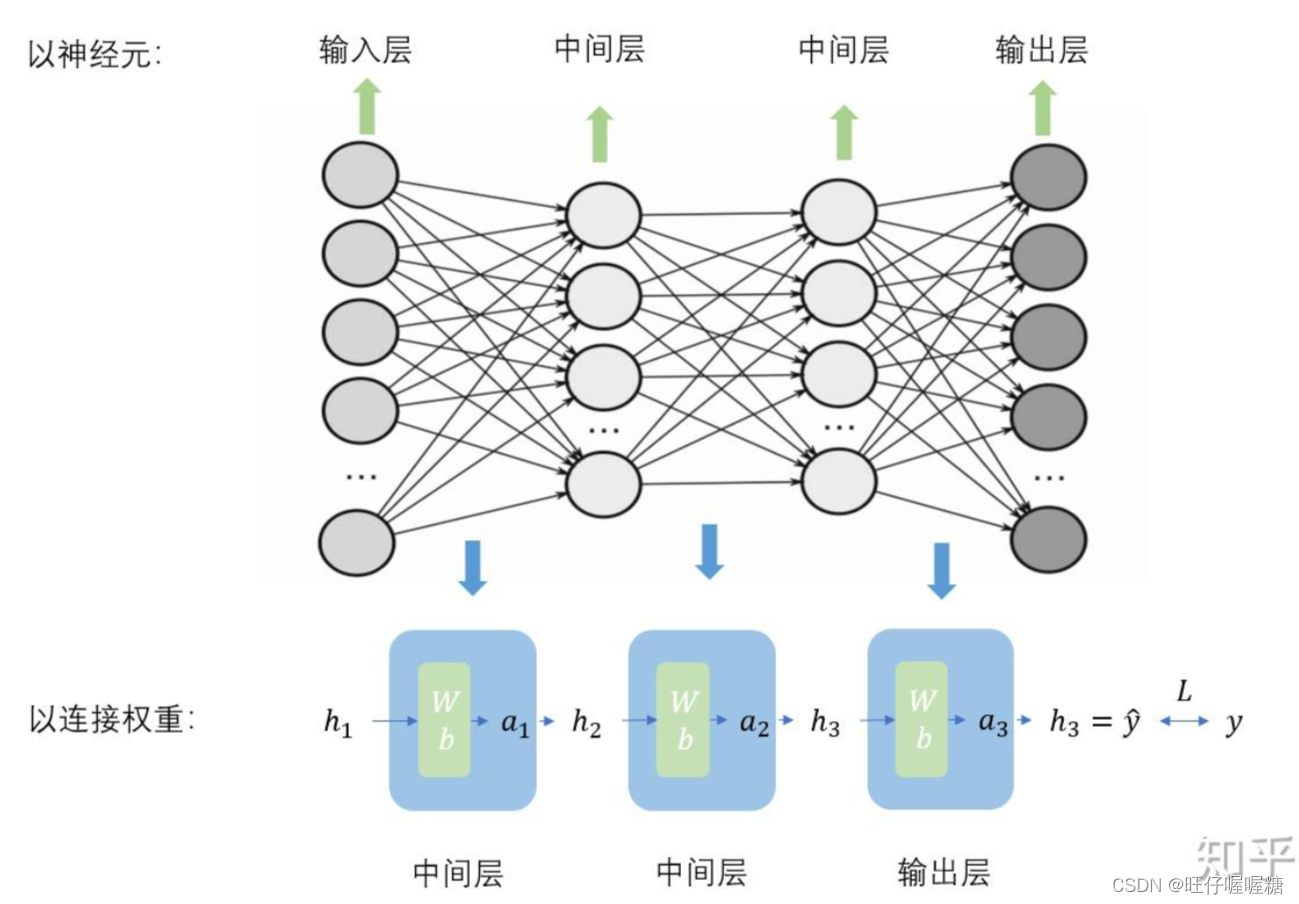
通过这种方式可以构建起一个多层的神经网络。
三、Tensor简介
Tensor,中文叫做张量。在深度学习里,Tensor实际上就是一个多维数组(multidimensional array)。在概念上与numpy中的ndarrays是一样的,很多用法类似于numpy中的ndarrays。使用Tensor的目的是能够创造更高维度的矩阵、向量。Tensor可以在gpu或其他专用硬件上运行来加速计算。
在pytorch中tensor可以用来构建计算图,计算梯度。

tensor包含data和grad,用来保存权重和梯度(损失值对权重的导数)。data和grad的数据类型也是tensor。
tensor和tensor进行计算时,会构建计算图。tensor和非tensor类型数据进行乘除运算时,会将该数据转为tensor类型后进行计算。
pytorch完成后向计算后,保存梯度,自动释放计算图。
四、示例
1.梯度下降
代码实现:
#!/user/bin/env python3
# -*- coding: utf-8 -*-
"""
梯度下降法
求y=2x
"""
import matplotlib.pyplot as plt
# 数据集
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0 # 系数初始值
learn_val = 0.01 # 学习率
epoch_list = []
cost_list = []
# 前向函数
def forward(x):
return x * w
# 损失函数
def cost(xs, ys):
cost_val = 0 # 损失值
for x, y in zip(xs, ys):
y_pred = forward(x)
cost_val += (y_pred - y) ** 2
return cost_val / len(xs) # 返回损失的平均值
# 梯度函数
def gradient(xs, ys):
grad_val = 0 # 梯度值
for x, y in zip(xs, ys):
grad_val += 2 * x * (x * w - y)
return grad_val / len(xs) # 返回梯度的平均值
print('predict(before training):', 4, forward(4))
# 开始训练
for epoch in range(100): # 进行一百轮训练
cost_value = cost(x_data, y_data) # 计算损失值
grad_value = gradient(x_data, y_data) # 计算梯度
w -= learn_val * grad_value
epoch_list.append(epoch)
cost_list.append(cost_value)
print('epoch:', epoch, 'cost:', cost_value, 'grad:', grad_value, 'w=', w)
print('predict:', 4, forward(4))
# 绘图
plt.plot(epoch_list, cost_list)
plt.xlabel('epoch')
plt.ylabel('cost')
plt.show()
结果:


2.反向传播

以y=2x为例
实现代码:
#!/user/bin/env python3
# -*- coding: utf-8 -*-
"""
反向传播
线性模型 y=2x 作为例子
"""
import torch
# 数据集
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# 系数初始值
w = torch.Tensor([1.0])
# 需要计算梯度
w.requires_grad = True
# 模型
# 前馈计算
def forward(x):
return x * w # w是一个Tensor Tensor在做乘法运算时,会将x自动类型转换为Tensor,做Tensor与Tensor之间的数乘
# 损失函数 loss的本质是构建一个计算图
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
print('predict(before training):', 4, forward(4))
for epoch in range(100): # 进行一百轮的训练
for x, y in zip(x_data, y_data):
loss_val = loss(x, y) # 前馈计算 构建计算图 loss_val也是一个Tensor
loss_val.backward() # 反馈计算 torch会将梯度存在w里面,之后释放计算图
print('x:', x, 'y=', y, 'grad=', w.grad.item())
w.data -= 0.01 * w.grad.data # 更新系数
w.grad.data.zero_() # 下一轮计算前,将梯度清零
print('progress:', epoch, 'loss_value=', loss_val.item())
print('predict(after training):', 4, forward(4))
结果:
前两轮:
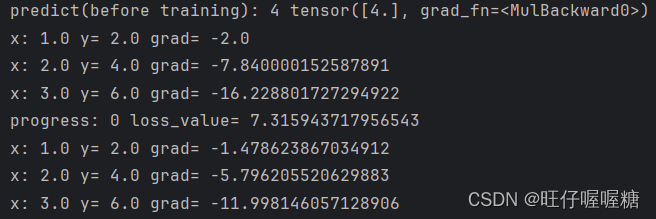
最后两轮:

课后习题

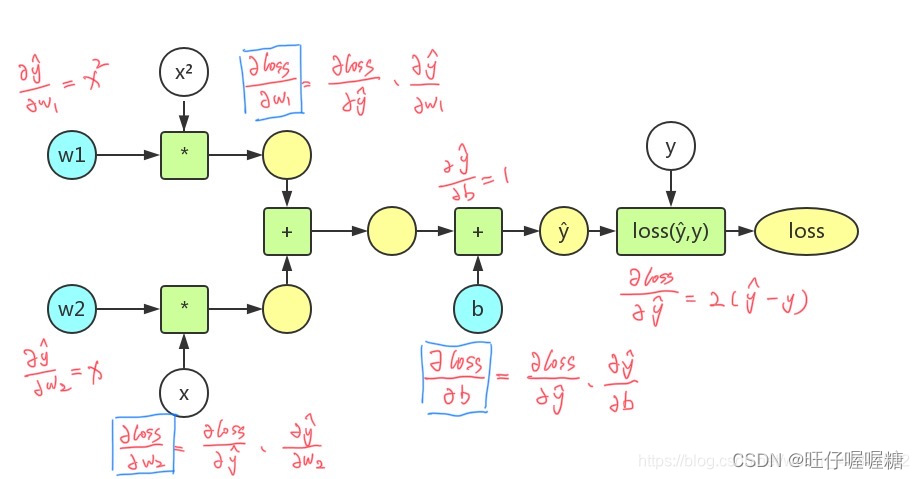
#!/user/bin/env python3
# -*- coding: utf-8 -*-
"""
反向传播
y=w1*x^2+w2*x+b
w1=2 w2=3 b=5
"""
import torch
import matplotlib.pyplot as plt
# 数据集
x_data = [1.0, 2.0, 3.0]
y_data = [10.0, 19.0, 32.0]
# 初始化
# 创建tensor
w1 = torch.Tensor([1.0])
w2 = torch.Tensor([1.0])
b = torch.Tensor([0.0])
# 设置需要计算梯度
w1.requires_grad = True
w2.requires_grad = True
b.requires_grad = True
# 设置学习率
rate = 0.02
# 绘图需要的数据
epoch_list = []
loss_list = []
# 模型
# 前向计算
def forward(x):
return w1 * x * x + w2 * x + b
# 损失函数
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
print('predict(before training):', 4, forward(4))
for epoch in range(100): # 进行一百轮的训练
for x, y in zip(x_data, y_data):
loss_val = loss(x, y) # 前向计算
loss_val.backward() # 后向计算
# 更新权重
w1.data -= rate * w1.grad.data
w2.data -= rate * w2.grad.data
b.data -= rate * b.grad.data
print('x:', x, 'y:', y, 'w1 grad:', w1.grad.item(), 'w2 grad:', w2.grad.item(), 'b grad:', b.grad.item())
# 梯度清零
w1.grad.data.zero_()
w2.grad.data.zero_()
b.grad.data.zero_()
# 绘图数据
epoch_list.append(epoch)
loss_list.append(loss_val.item())
print('progress:', epoch, 'loss_value:', loss_val.item())
print('predict(after training):', 4, forward(4))
# 绘图
plt.plot(epoch_list, loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
结果:

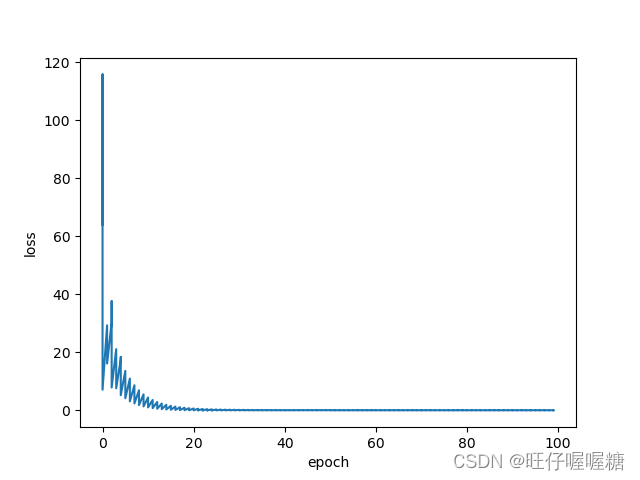















 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









