







 本文详细介绍了使用R语言进行参数估计的各种方法,包括点估计、正态总体均值和方差的区间估计、单正态总体方差、双正态总体均值差和方差比的区间估计,以及如何确定样本容量。通过实例展示了R语言内置函数和自定义函数的应用,帮助理解统计推断的概念和实践操作。
本文详细介绍了使用R语言进行参数估计的各种方法,包括点估计、正态总体均值和方差的区间估计、单正态总体方差、双正态总体均值差和方差比的区间估计,以及如何确定样本容量。通过实例展示了R语言内置函数和自定义函数的应用,帮助理解统计推断的概念和实践操作。
R语言参数估计
目录
1.R语言点估计
1.1定义
有大多数定律可知,如果总体上X的k阶矩阵存在,则样本的K阶矩阵以概率收敛到总体的K阶矩,样本矩的连续函数收敛到的总体连续矩的连续函数。这就启发我们可以用样本矩阵作为总体矩的估计量,这种用相应的样本矩的估计方法称为矩估计法。
1.2 例题
对某个篮球运动员记录其在某一次比赛中投篮命中与否,观测数据如下。
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 |
| 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 |
编写R语言估计这个篮球运动员投篮的成败比
#1.2例题
X <- c(1,1,0,1,0,0,1,0,1,1,1,0,1,1,0,1,0,0,1,0,1,0,1,0,0,1,1,0,1,1,0,1)
theta <- mean(X)
h <- theta/(1-theta)
h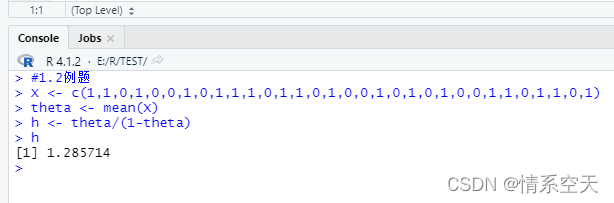
因此得到g(θ)的矩估计值为1.285714
2.R语言正态总体均值区间评估
2.1定义
由于点估计值只是估量值的一个近似值,因而点估计本身既没有反映出这种近似值的精度,既指出用估计值去估计的范围误差有多大,也没有指出这个误差范围有多大的概率包括未知数,这正是区间估计要解决的问题
2.2方差已知时,求置信区间
2.2.1自定义函数
#R语言正态总体均值区间评估(方差已知时,求置信区间)
#x:样本数据 sigma^2:方差 alpha=1-置信度
conf <- function(x,sigma,alpha) {
n <- length(x)
mean <- mean(x)
result <- c(mean-sigma*qnorm(1-alpha/2)/sqrt(n),mean+sigma*qnorm(1-alpha/2)/sqrt(n))
result
}2.2.2例题
某车间生产的滚珠直径X服从正态分别N(μ,0.6)。现在从某日的产品中抽取6个测得直径如下单位(mm)
14.6 15.1 14.9 14.8 15.2 15.1
试求平均直径置信度为95%的置信区间。
#2.2.2例题
x <- c(14.6,15.1,14.9,14.8,15.2,15.1)
sigma <- sqrt(0.6)
conf(x,sigma,0.05)

所以均值的置信区间为[14.3302,15.5698]
2.3方差未知时,求置信区间
2.3.1调用内置函数t.test()
由于在R语言中有求方差未知时均值置信区间的内置函数t.test(),其调用格式如下:
t.test(x,y=null,alternative=c("two.sided","less","greater"),mu=0,paired=FLASE,
var.equal=FLASE,conf.level=0.95,...)alternative用于指定所求置信区间的类型;conf.level=0.95置信度为95%
2.3.2例题
某糖厂自动包装机包装糖,设各包糖重量服从正态分布N(μ,ε²),某日开工后测得9包糖的重量单位(KG)为99.3,98.7,100.5,101.2,98.3,99.7,99.5,102.1,100.5 试求μ的置信度为95%的置信区间。
#2.3.2例题
x <- c(99.3,98.7,100.5,101.2,98.3,99.7,99.5,102.1,100.5)
t.test(x,conf.level = 0.95)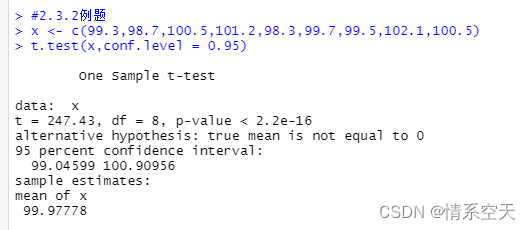
从上述代码中可以看到置信水平为0.95的置信区间为[99.04599,100.90956]
这个结果过于繁琐,由于只需要置信区间的结果,可以优化为:
t.test(x,conf.level = 0.95)$conf.int
3.R语言单正态总体方差区间评估
3.1定义
此时虽然也可以就均值μ是否已知分为两种情况讨论方差的区间估计,但实际中μ已知的情形是极为罕见的,所以只讨论在μ未知的条件下方差ε²的置信区间。
3.2自定义函数
#R语言单正态总体方差区间评估
#n:个数 s2:方差 alpha=1-置信度
chisq <- function(n,s2,alpha){
result <- c((n-1)*s2/qchisq(alpha/2,df = n-1,lower.tail = F),(n-1)*s2/qchisq(1-alpha/2,df=n-1,lower.tail=F))
result
}3.3 例题
从某车间加工的同类零件中抽取16件,测得零件的平均长度为12.8cm,方差为0.0023.假设零件的长度服从正态分布,试求总体方差的置信区间(置信度为95%)
#3.3例题
chisq(16,0.0023,1-0.95)
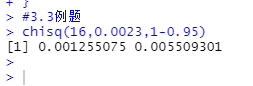
由运行结果可知总体方差的区间估计为[0.001255075 ,0.005509301]
4.R语言双正态总体均值差区间评估
4.1定义
分为两种双正态总体均值差区间评估方法:两方差均已知时和两方差均未知时
4.2两方差均已知时,求置信区间
4.2.1自定义函数
#R语言双正态总体均值差区间评估(两方差均已知时,求置信区间)
#x,y :样本数据 conf.level:置信度 sigma1,sigma2:方差
two.sample.ci <- function(x,y,conf.level,sigma1,sigma2){
options(digits = 4)
m = length(x)
n = length(y)
xbar=mean(x)-mean(y)
alpha=1-conf.level
zstar=qnorm(1-alpha/2)*(sigma1/m+sigma2/n)^(1/2)
xbar+c(-zstar,+zstar)
}4.2.2例题
为比较两种农产品的产量,选择18块条件相似的试验田,采用相同的耕作方法做实验,结果播种甲种的8块试验田的单位面积产量和播种乙品种的10块试验田的单位面积产量分别如下表所示
| 甲品种 | 628 ,583,510,554,612,523,530,615 |
| 乙品种 | 535,433,398,470,567,480,498,560,503,426 |
假定每个品种的单位面积产量均服从正态分布,甲品种产量的方差为2140,乙品种产量的方差为3250,试求这两个品种平均面积产量差的置信区间(置信度95%)
x <- c(628,583,510,554,612,523,530,615)
y <- c(535,433,398,470,567,480,498,560,503,426)
sigma1=2140
sigma2=3250
two.sample.ci(x,y,0.95,sigma1,sigma2)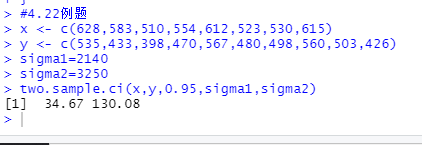
因此两个品种平均面积产量差的置信区间为:[34.67 ,130.08]
4.3两方差均未知时,求置信区间
4.3.1调用内置函数t.test()
如果同求单正态的均值置信区间,在R语言中可以直接利用t.test()求两方差都未知但两均值方差相等的置信区间,并且必须在t.test()中指定选项var.equal=TRUE
4.3.2例题
为比较两种农产品的产量,选择18块条件相似的试验田,采用相同的耕作方法做实验,结果播种甲种的8块试验田的单位面积产量和播种乙品种的10块试验田的单位面积产量分别如下表所示
| 甲品种 | 628 ,583,510,554,612,523,530,615 |
| 乙品种 | 535,433,398,470,567,480,498,560,503,426 |
假定每个品种的单位面积产量均服从正态分布,二者方差相等,试求这两个品种平均面积产量差的置信区间(置信度95%)
#4.3.2例题
x <- c(628,583,510,554,612,523,530,615)
y <- c(535,433,398,470,567,480,498,560,503,426)
t.test(x,y,var.equal = TRUE)
因此两个品种平均面积产量差的置信区间为[29.47, 135.28]
5.R语言双正态总体方差比区间估计
5.1定义
此时虽然也可以就均值是否已知分两种情况讨论方差的区间估计,但实际中μ已知的情形是极为罕见的,所以只讨论在μ未知的条件下方差ε²的置信区间。
5.2调用内置函数var.test()
var.test(x,y,ratio=1,alternative=c("two.sided","less","greater"),conf.level=0.95,...)5.3 例题
甲、乙两台机床分别加工某种轴承,他们加工的轴承的直径分别服从正态分布N(μ1,ε1²)、N(μ2,ε2²),从各自加工的轴承中分别抽取若干个轴承测其直径,结果如下表所示
总体 样本容量 直径 x(机床甲) 8 20.5,19.8,19.7,20.4,20.1,20.0,19.0,19.9 y(机床乙) 7 20.7,19.8,19.5,20.8,20.4,19.6,20.2
试求两台机床加工的轴承直径的方差比的0.95的置信区间
#5.3例题
x <- c(20.5,19.8,19.7,20.4,20.1,20.0,19.0,19.9)
y <- c(20.7,19.8,19.5,20.8,20.4,19.6,20.2)
var.test(x,y,var.test(x,y,conf.level = 0.95))
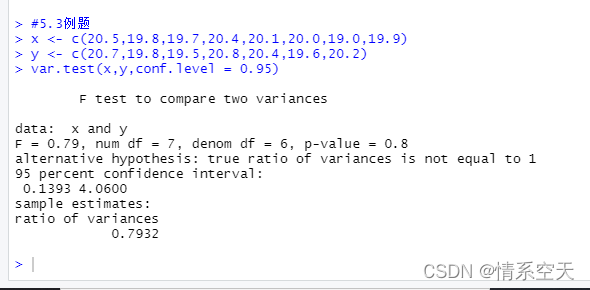
由上面的运行结果可见两台机床加工的轴承直径的方差比的0.95的置信区间为[0.1393,4.0600]方差比为0.7932
6.R语言确定样本容量
6.1定义
确定样本容量n是抽样中的一个重要问题。样本抽取过少了会丢失样本信息,会导致误差大从而不满足要求;若样本抽取太多,虽然各种信息都包含了,误差也降低了,但同时会增加所需的人力、物理、和费用开销。权衡两者,我们要抽取适当数量的样本。
6.2总体方差已知时,求样本容量
6.2.1自定义函数
#R语言确定样本容量(总体方差已知时,求样本容量)
# d:允许误差 var:方差 conf.level:置信度
size.norm1 <- function(d,var,conf.level){
alpha=1-conf.level
((qnorm(1-alpha/2)*var^(1/2))/d)^2
}6.2.2例题
某地区有10000户家庭,拟抽取一个简单的样本,调查一个月的平均开支,要求置信度为95%,允许最大误差为2。根据经验,家庭开支的方差为500,应抽取多少户进行调查?
#6.2.2例题
size.norm1(2,500,conf.level = 0.95)
由上述代码可知应抽取481户。
6.3总体方差未知时,求置信区间
6.3.1自定义函数
#R语言确定样本容量(总体方差未知)
#s:标准差 alpha=1-置信度 d:允许误差
size.norm2 <- function(s,alpha,d){
t1 <- qt(alpha/2,100,lower.tail = FALSE)
n1 <- (t1*s/d)^2
t2 <- qt(alpha/2,n1,lower.tail = FALSE)
n2 <- (t2*s/d)^2
while (abs(n2-n1)>0.5) {
n1 <- (qt(alpha/2,n2,lower.tail = FALSE)*s/d)^2
n2 <- (qt(alpha/2,n1,lower.tail = FALSE)*s/d)^2
}
n2
}6.3.2例题
某公司生产了一批新商品,产品总体服从正态分布,现在要估计这批产品的平均重量,允许最大误差为2,样本标准差为10,试问置信度99%的情况下要取多少样本?
#6.3.2例题
size.norm2(10,0.01,2)
所以应该取样本170个
6.4估计比例/概率(P)时样本容量的确定
6.4.1自定义函数
#R语言确定样本容量(估计比例/概率(P)时样本容量的确定)
#d:误差率 p:估计比例 conf.level:置信度
size.bi <- function(d,p,conf.level){
alpha=1-conf.level
((qnorm(1-alpha/2))/d)^2*p*(1-p)
}6.4.2例题
某市一所大学历届毕业生就业率为90%,试估计应届毕业生就业率,要求估计误差不超过3%,试问在置信度95%下要抽取应届毕业生多少人?
#6.4.2例题
size.bi(0.03,0.9,0.95)
所以在满足要求置信度在95%的时候应抽取应届毕业生385人才能让误差小于3%
练习题:
1.
高三1、2班的期末数学成绩服从正态分布,分别从1、2班中各抽取12名学生的成绩,如下表所示。假设1班数学成绩的方差是181,2班数学出成绩的方差是214.5
| 班级 | 样本量 | 成绩/分 |
|---|---|---|
| 1 | 12 | 64,63,91,70,92,98,96,83,89,84,61,74 |
| 2 | 12 | 87,61,47,89,73,71,86,86,95,91,62,76 |
试比较1、2班的成绩的95%的置信区间,成绩方差比的99%置信区间
#x:样本数据 sigma^2:方差 alpha=1-置信度
conf <- function(x,sigma,alpha) {
n <- length(x)
mean <- mean(x)
result <- c(mean-sigma*qnorm(1-alpha/2)/sqrt(n),mean+sigma*qnorm(1-alpha/2)/sqrt(n))
result
}
#一班样本数据
x <- c(64,63,91,70,92,98,96,83,89,84,61,74)
#二班样本数据
y <- c(87,61,47,89,73,71,86,86,95,91,62,76)
#一班成绩置信度95%的置信区间
conf(x,sqrt(181),1-0.95)
#二班成绩置信度95%的置信区间
conf(y,sqrt(214.5),1-0.95)
#R语言双正态总体方差比区间估计
#x,y:样本数据 conf.level:置信度
var.test(x,y,conf.level = 0.99)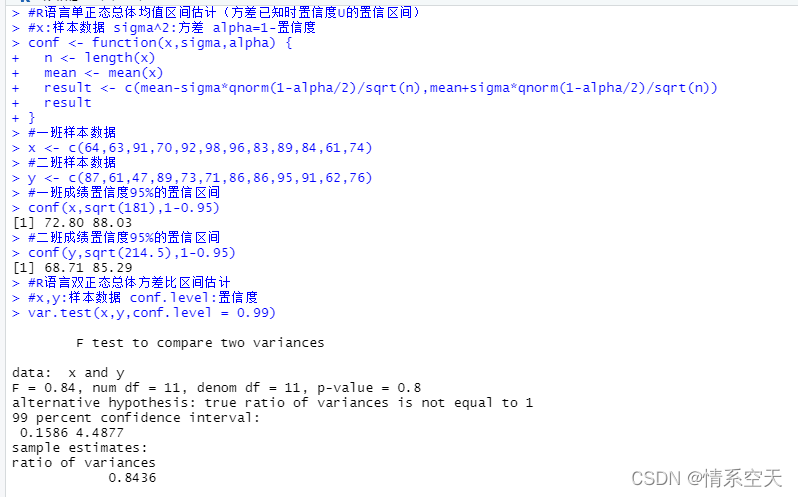
所以1班成绩的95%置信区间为[72.80470,88.02863]
所以2班成绩的95%置信区间为[68.7135 ,85.2865]
所以成绩方差比的99%置信区间为[0.15858,4.487718]
所以成绩方差比为0.8436088
2.
某研究中心,受托为一大型公司进行客户消费能力调研,需要估计出潜在客户对公司产品的平均消费支出意愿,允许误差为200元,标准差为300元,在90%的置信区间里,该研究机构应该抽取多少个客户?如果置信区间提高到95%、99%时,客户调研数量将发生什么变化?
#s:标准差 alpha=1-置信度 d:允许误差
size.norm2 <- function(s,alpha,d){
t1 <- qt(alpha/2,100,lower.tail = FALSE)
n1 <- (t1*s/d)^2
t2 <- qt(alpha/2,n1,lower.tail = FALSE)
n2 <- (t2*s/d)^2
while (abs(n2-n1)>0.5) {
n1 <- (qt(alpha/2,n2,lower.tail = FALSE)*s/d)^2
n2 <- (qt(alpha/2,n1,lower.tail = FALSE)*s/d)^2
}
n2
}
#允许误差200,标准差300,90%的置信区间里
size.norm2(300,0.1,200)
#允许误差200,标准差300,95%的置信区间里
size.norm2(300,0.05,200)
#允许误差200,标准差300,99%的置信区间里
size.norm2(300,0.01,200)
所以90%的置信区间里应该调查8人
所以95%的置信区间里应该调查11人
所以99%的置信区间里应该调查19人


















 200
200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











