







👨🎓个人主页:研学社的博客
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录

💥1 概述
1、径向基神经网络
径向基函数网络是由三层构成的前向网络:第一层为输入层,节点个数的能与输入的维数;第二层为隐含层,节点个数视问题的复杂度而定;第三层为输出层,节点个数等于输出数据的维数。由径向基函数的定义可知,函数值仅与自变量的范数有关。
2、多层感知器
多层感知器(MLP,Multilayer Perceptron)是一种前馈人工神经网络模型,其将输入的多个数据集映射到单一的输出的数据集上。
3、两者的异同
对于任意一个多层感知器,都存在一个可以替代它的径向基神经网络,反之,任意一个径向基神经网络,也存在一个多层感知器可以替代它。两者功能相近,但又有明显区别:
径向基神经网络是三层网络(输入层、隐含层、输出层),只有一个隐含层,而多层感知器则可以有多个隐含层。
径向基神经网络的隐含层和输出层完全不同,隐含层采用非线性函数(径向基函数)作为基函数,而输出层采用线性函数,两者作用不同。在多层感知器中,隐含层和输出层没有本质区别,一般都采用非线性函数。由于径向基函数网络输出的是线性加权和,因此学习速度更快。
径向基神经网络的基函数计算的是输入向量与基函数中心之间的欧氏距离(两者取差值,再取欧几里得范数),而多层感知器的隐单元的激励函数则计算输入向量与权值的内积。
多层感知器对非线性映射全局逼近,而径向基函数使用局部指数衰减的非线性函数进行局部逼近,因此,要达到相同的精度,径向基函数需要的参数比多层感知器少得多。
BP网络使用sigmoid函数作为激励函数,有很大的输入可见域。径向基函数网络引入RBF函数,当输入值偏离基函数中心时,输出逐渐减小,并很快趋于零。这一点比多层感知器更符合神经元响应基于感受域这一特点,比BP网络具有更深厚的理论基础。同时由于输入可见区域很小,径向基函数网络需要更多的径向基神经元。
📚2 运行结果
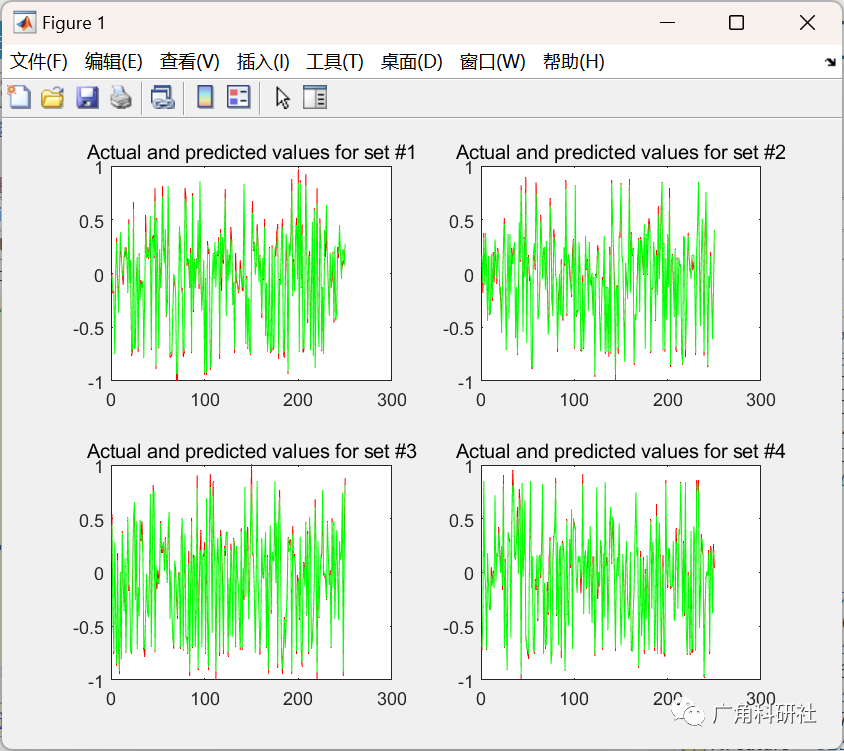
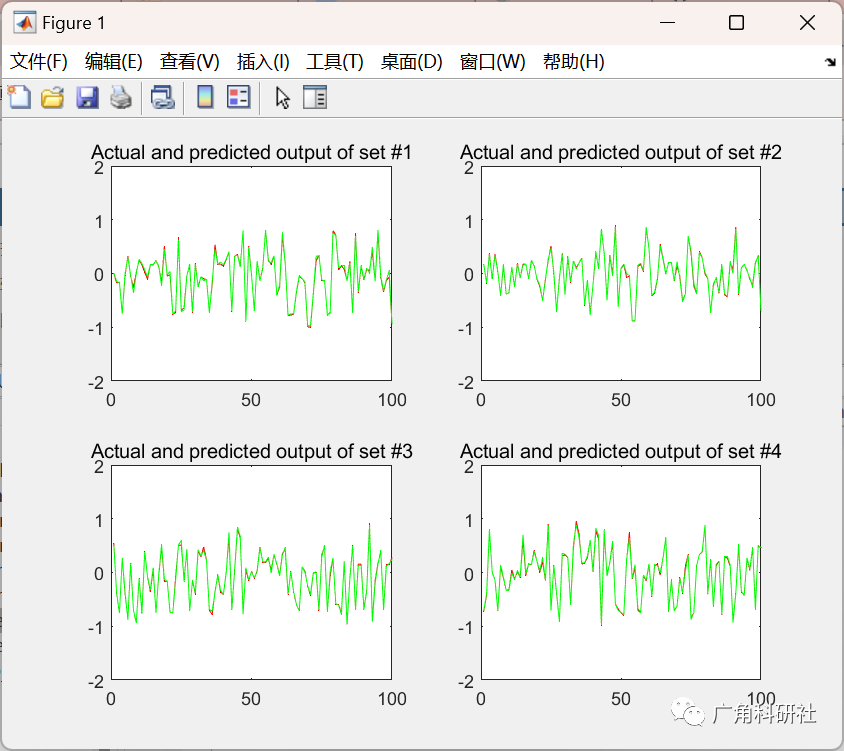
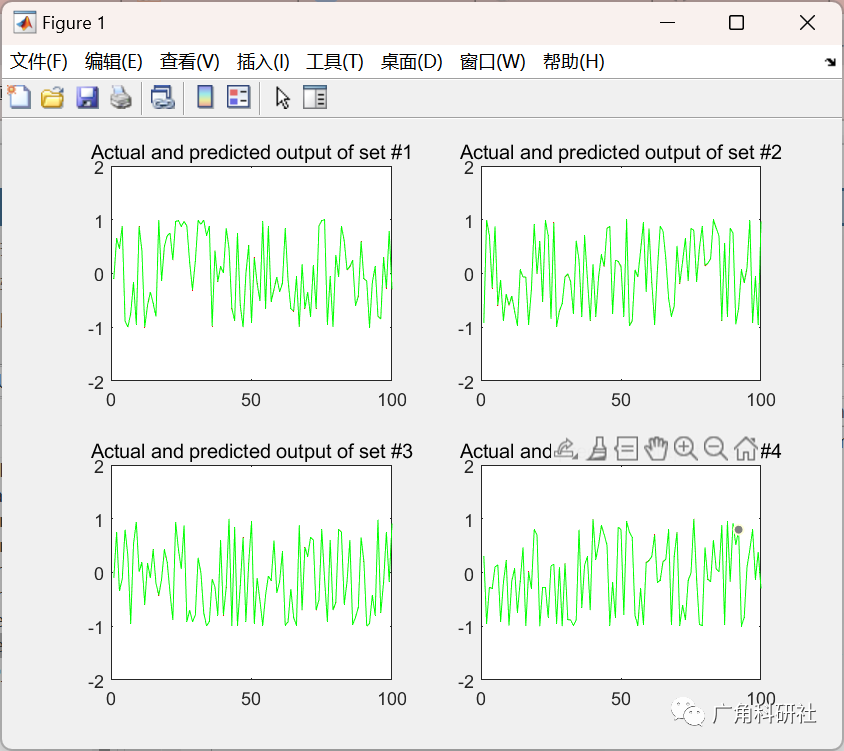
主函数部分代码:
% Program for MLP..........................................
% Update weights for a given epoch
clear all;
close all;
clc;
weights = zeros(1,30,4);
weights_in = zeros(30,10,4);
errors = zeros(4,1);
for set=1:4
switch set
% Set 1
case 1
inp_rows = [251:1000];
out_rows = [1:250];
% Set 2
case 2
inp_rows = [1:250 501:1000];
out_rows = [251:500];
% Set 3
case 3
inp_rows = [1:500 751:1000];
out_rows = [501:750];
% Set 4
case 4
inp_rows = [1:750];
out_rows = [751:1000];
end
% Load the training data..................................................
file=xlsread('fin_19.xlsx');
for i=1:11
minval = min(file(:,i)) ;
maxval = max(file(:,i));
minmat = ones(size(file,1),1).*minval;
maxmat = ones(size(file,1),1).*maxval;
tp =ones(size(file,1),1);
file(:,i)= ((file(:,i) - minmat) ./ (maxmat -minmat)).* 2 - tp ;
end
Ntrain = file(inp_rows,:);
[NTD,~] = size(Ntrain);
% Initialize the Algorithm Parameters.....................................
inp = 10; % No. of input neurons
hid = 30; % No. of hidden neurons
out = 1; % No. of Output Neurons
lam = 0.0001; % Learning rate
epo = 2000;
% Initialize the weights..................................................
Wi = 0.001*(rand(hid,inp)*2.0-1.0); % Input weights
Wo = 0.001*(rand(out,hid)*2.0-1.0); % Output weights
% Train the network.......................................................
for ep = 1 : epo
sumerr = 0;
DWi = zeros(hid,inp);
DWo = zeros(out,hid);
for sa = 1 : NTD
xx = Ntrain(sa,1:inp)'; % Current Sample
tt = Ntrain(sa,inp+1:end)'; % Current Target
Yh = 1./(1+exp(-Wi*xx)); % Hidden output
Yo = Wo*Yh; % Predicted output
er = tt - Yo; % Error
DWo = DWo + lam * (er * Yh'); % update rule for output weight
DWi = DWi + lam * ((Wo'*er).*Yh.*(1-Yh))*xx'; %update for input weight
sumerr = sumerr + sum(er.^2);
end
Wi = Wi + DWi;
Wo = Wo + DWo;
% disp(sqrt(sumerr/(NTD)))
% save -ascii Wi.dat Wi;
% save -ascii Wo.d at Wo;
end
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]张驰,郭媛,黎明.人工神经网络模型发展及应用综述[J].计算机工程与应用,2021,57(11):57-69.
















 3120
3120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











