







 本文提出了一种基于定向稀疏过滤(DSF)的算法,利用可学习权重的Lehmer平均值处理源不平衡问题,以改进无监督盲源分离(BSS)在多通道语音信号中的表现。实验结果显示,该方法在不同真实声学环境中提高了源信号分离的性能。
本文提出了一种基于定向稀疏过滤(DSF)的算法,利用可学习权重的Lehmer平均值处理源不平衡问题,以改进无监督盲源分离(BSS)在多通道语音信号中的表现。实验结果显示,该方法在不同真实声学环境中提高了源信号分离的性能。
👨🎓个人主页:研学社的博客
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录

💥1 概述
文献来源:

在语音信号的盲源分离中,源频谱中固有的不平衡对依赖单源优势来估计混合矩阵的方法提出了挑战。我们提出了一种基于定向稀疏过滤(DSF)框架的算法,该算法利用具有可学习权重的Lehmer平均值来自适应地解释源不平衡。在多个真实声学环境中的性能评估表明,与基线方法相比,声源分离有所改善。
无监督盲源分离 (BSS) 是从其混合物中提取源信号的过程,几乎没有关于源的先验信息,并且没有使用标记数据的事先训练。在本文中,我们重点讨论了从多通道观察到的混合(特别是语音信号)中估计复值混合矩阵的问题。我们假设每个频率箱的数据都遵循无噪声线性混频模型
原文摘要:
Abstract:
In blind source separation of speech signals, the inherent imbalance in the source spectrum poses a challenge for methods that rely on single-source dominance for the estimation of the mixing matrix. We propose an algorithm based on the directional sparse filtering (DSF) framework that utilizes the Lehmer mean with learnable weights to adaptively account for source imbalance. Performance evaluation in multiple real acoustic environments show improvements in source separation compared to the baseline methods.
📚2 运行结果
部分代码:
% n_src = 4;
n_src = 3;
file_name = ['../audiofiles/dev1_female' int2str(n_src) '_liverec_130ms_1m'];
[data, fs] = audioread([file_name '_mix.wav']);
mixture = data'; % n_chan by n_sample
% Load the source's image at each channel
sources = zeros(n_src, 160000, 2);
for i = 1:n_src
sources(i, :, :) = reshape(audioread([file_name '_sim_' int2str(i) '.wav']), 1, 160000, 2);
end
tic;
[~, n_sampl] = size(mixture);
X = stft(mixture, NFFT, n_overlap, window);
[n_freq, n_frame, n_chan] = size(X);
P = zeros(n_freq, n_frame, n_src);
% for f = 1:n_freq
parfor f = 1:n_freq
x_f = squeeze(X(f, :, :)).'; % x_f: n_chan by n_frame
rng(seed, 'combRecursive'); % For reproducible results
[~, ~, cos2, Jm] = dsf_lite(x_f, n_src, r, o);
P(f, :, :) = calc_softmask(cos2, b_)';
end
[P, ~] = permutation_alignment(P, 10, 1e-3);
P = repmat(P, [1, 1, 1, n_chan]);
Y = permute(repmat(X, [1, 1, 1, n_src]), [1 2 4 3]) .* P;
y_t_anh = istft(Y, n_sampl, NFFT, n_overlap, window);
elapse_time = toc;
[SDR_anh, ISR_anh, SIR_anh, SAR_anh, perm_anh] = bss_eval_images(y_t_anh, sources);
my_result = mean(SDR_anh);
my_result_SIR = mean(SIR_anh);
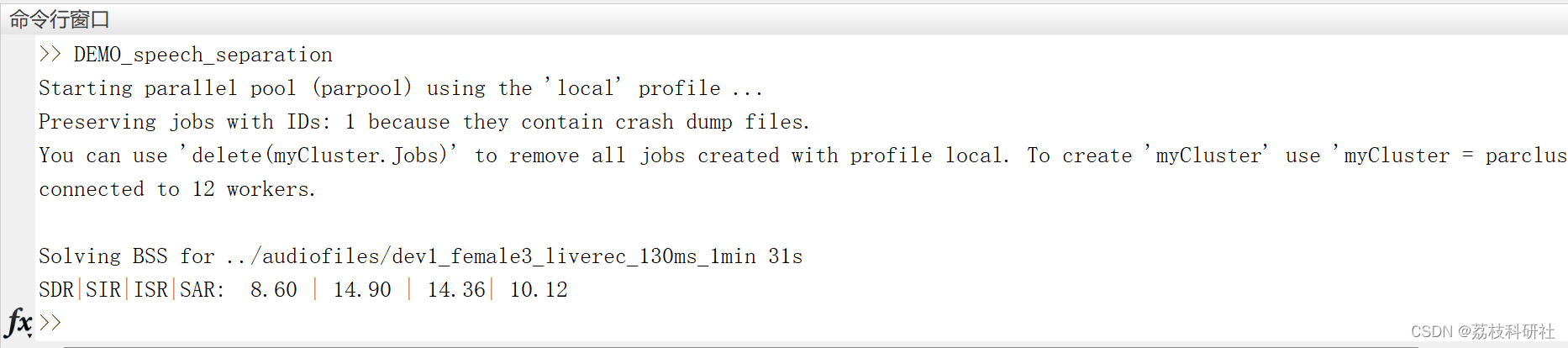
fprintf(['\nSolving BSS for ' file_name 'in ' int2str(elapse_time) 's']);
fprintf('\nSDR|SIR|ISR|SAR: %.2f | %.2f | %.2f| %.2f\n', mean(SDR_anh), mean(SIR_anh), mean(ISR_anh), mean(SAR_anh));
for i = 1:n_src
out = squeeze(y_t_anh(i, :, :));
audiowrite([file_name '_out_' int2str(i) '.wav'], 0.9 * out / max(abs(out(:))), fs);
end
S(1) = load('gong');
sound(S(1).y, S(1).Fs)
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]K. Watcharasupat, A. H. T. Nguyen, C. -H. Ooi and A. W. H. Khong, "Directional Sparse Filtering Using Weighted Lehmer Mean for Blind Separation of Unbalanced Speech Mixtures," ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 4485-4489, doi: 10.1109/ICASSP39728.2021.9414336.
[2]A. H. T. Nguyen, V. G. Reju and A. W. H. Khong, "Directional Sparse Filtering for Blind Estimation of Under-Determined Complex-Valued Mixing Matrices," in IEEE Transactions on Signal Processing, vol. 68, pp. 1990-2003, 2020, doi: 10.1109/TSP.2020.2979550.
[3]A. H. T. Nguyen, V. G. Reju, A. W. H. Khong and I. Y. Soon, "Learning complex-valued latent filters with absolute cosine similarity," 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 2412-2416, doi: 10.1109/ICASSP.2017.7952589.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











