










TAPIR: Tracking Any Point with per-frame Initialization and temporal Refinement- 通过每帧初始化和时间细化跟踪任意点
文章目录
文章是由谷歌和牛津大学合作进行推出的两阶段点跟踪算法,可以结合双阶段的匹配策略来进行改进
项目官网:https://deepmind-tapir.github.io/
发布在ICCV 2023是点跟踪的一个经典的方法。
摘要概括
该方法提出的是TAP模型,而且采用的是两阶段的跟踪方法。这两个阶段分别为:
-
a matching stage:匹配阶段 -
a refinement stage:细化阶段
- 在匹配阶段:独立地为每隔一帧上的查询点找到合适的候选点匹配。在细化阶段:根据局部相关性更新轨迹和查询特征。生成的模型在 TAP-Vid 基准上显着超越了所有基线方法,
解读:先对第一个阶段的匹配阶段来进行细化的解读
目标:在视频的每隔一帧(例如第 t+1 帧、第 t+2 帧等)中,为每个查询点找到一个最合适的候选点。
独立地" 的含义:在这一阶段,算法不考虑轨迹的连续性(即不考虑目标点在时间维度上的移动规律),而是逐帧独立地寻找与查询点特征最相似的候选点。这种匹配可能基于特征相似性(例如通过特征空间的距离计算),而不依赖历史轨迹信息。缺点是忽略了时间上的相关性(即目标在邻近帧之间通常是连续移动的) 之前的论文也提到过这种局部的搜索策略例如光流只考虑相邻帧就和出现一个问题的。
解读第二个阶段细化阶段:
细化阶段:通过利用时间和空间的局部相关性,提高了匹配结果的精确性,特别是在复杂场景中(如遮挡或快速移动)。这种阶段性的处理方式提高了算法的鲁棒性。
通过分析目标点在邻近帧中的局部一致性(如目标的轨迹平滑性或空间位置的连续性),对初步匹配的结果进行修正。
这样可以修复因为噪声、遮挡或特征相似度不足导致的误匹配问题。
用了两步来解决这一个问题,即为后面提出的合并搜索的思想
- 我们的模型有助于对长且高分辨率的视频序列进行快速推理。 在现代 GPU 上,我们的实现能够比实时更快地跟踪点,并且可以灵活地扩展到更高分辨率的视频。

引言与相关工作
- TAP 面临许多挑战:我们必须稳健地估计遮挡并在点重新出现时恢复(
与光流和运动结构关键点不同)这意味着必须合并搜索。
传统的局部搜索算法(例如光流法)依赖目标点在前后帧之间的小范围移动。如果点被遮挡,局部搜索区域会错过目标点。遮挡后重新出现的点可能出现在较大的搜索范围内,而局部搜索无法覆盖这些点。 RAFT的多尺度的局部搜索就是一个很好的例子。
全局搜索:
- 范围:在整个图像或较大的区域内搜索目标。
- 优势:能够处理目标长时间遮挡后重新出现的情况。
- 缺点:计算复杂度高,可能引入更多噪声。
合并搜索:将局部搜索的高效性与全局搜索的鲁棒性结合起来:
- 在无遮挡时,优先采用局部搜索以保证效率。
- 遮挡发生时,结合外观特征、轨迹信息等,在全局范围内寻找可能的目标点。
- 重新出现后,通过匹配特征信息来关联目标点。
之后的一点是:
- 当点在许多连续帧中保持可见时,整合许多这些帧中的
外观和运动信息非常重要,以便以最佳方式预测位置。
定义 TAPIR 的三个核心设计决策。
- use a coarse-to-fine approach
其中的粗匹配就包括了:在每一帧上单独执行的遮挡鲁棒匹配,其中使用低分辨率特征假设轨道,而不强制执行时间连续性。
解读:该阶段利用了低分辨率的特征表示来假设轨迹。低分辨率特征通常计算效率更高,并且对大范围的运动或目标变化更具鲁棒性。然而,低分辨率特征可能会牺牲细节信息,因此这一阶段的匹配结果是粗略的。
不强制时间连续性:粗匹配阶段不要求目标点在连续帧之间有严格的轨迹约束。这样做的目的是增加灵活性,特别是在目标遮挡、突然运动变化或场景不连续(如视频剪切)的情况下。
在精细化的迭代的部分:使用更高分辨率的局部时空信息,其中神经网络可以权衡运动的平滑度与局部外观线索,以产生最可能的轨迹。
- 第二个设计决策是在时间上完全卷积:我们的神经网络层主要由特征比较、空间卷积和时间卷积组成,从而形成一个有效映射到现代 GPU 和 TPU 硬件的模型。
解读:查找了一些资料去了解了一下什么是时间上完全卷积:时间完全卷积指的是神经网络在时间维度上采用了卷积操作,而不是依赖循环结构(如 RNN、LSTM)或帧间单独处理。 这种设计意味着模型能够一次性处理多个时间步(多个帧)的数据,而不是逐帧处理,使得时间信息可以并行地被处理和编码。
时间卷积操作用于提取帧间的时间特征,空间卷积操作用于提取每一帧内部的空间特征。
- 第三个设计决策是模型应该以自监督的方式估计其位置估计的不确定性。 这确保了可以抑制低置信度预测,从而提高基准分数。
我们发现两个现有的架构已经具备了我们需要的一些部分:TAP-Net 和持久独立粒子(PIPs)参考我之前写的这两篇论文。
这个工作是考虑如何有效的将两者结合起来。
-
TAP-Net 对每一帧独立执行全局搜索,提供对遮挡具有鲁棒性的粗略轨迹。(然而却没有用到视频的连续性)
-
PIPs 给出了一个改进的方法:在进行初始化的情况下,它会搜索本地邻域并随着时间的推移平滑轨迹。
然而,PIP 按块顺序处理视频,并使用最后一个块的输出初始化每个块。从而导致了整个推理速度变慢
-
在TAP-Net中,全局搜索指的是对于每一帧,模型会基于所有已知目标位置的信息,搜索全图中可能的目标位置。这与传统的局部搜索策略不同,局部搜索通常只关注目标周围的局部区域,而全局搜索则利用更广泛的上下文信息,以避免局部信息的丢失或者遮挡引起的跟踪失败。
-
TAP-Net没有显式地使用视频的连续性,可能是因为它采取了一种更加“自包含”的方法。即,每一帧的目标识别和匹配依赖于当前帧内的全局信息,而不是直接依赖前一帧的运动轨迹。
文章贡献总结
-
我们提出了一种用于长期点跟踪的新模型,弥合了 TAP-Net 和 PIPS之间的差距。
-
我们证明该模型在具有挑战性的
TAP-Vid基准测试(参考之前写的博客上一篇)中取得了最先进的结果,性能显着提升。 -
影响高性能点的架构决策进行了广泛的分析。
-
我们提供了由 TAPIR 的高质量轨迹支持。
-
对超参数进行调整并且结合了代码的实现方式。
TAPIR架构总结:
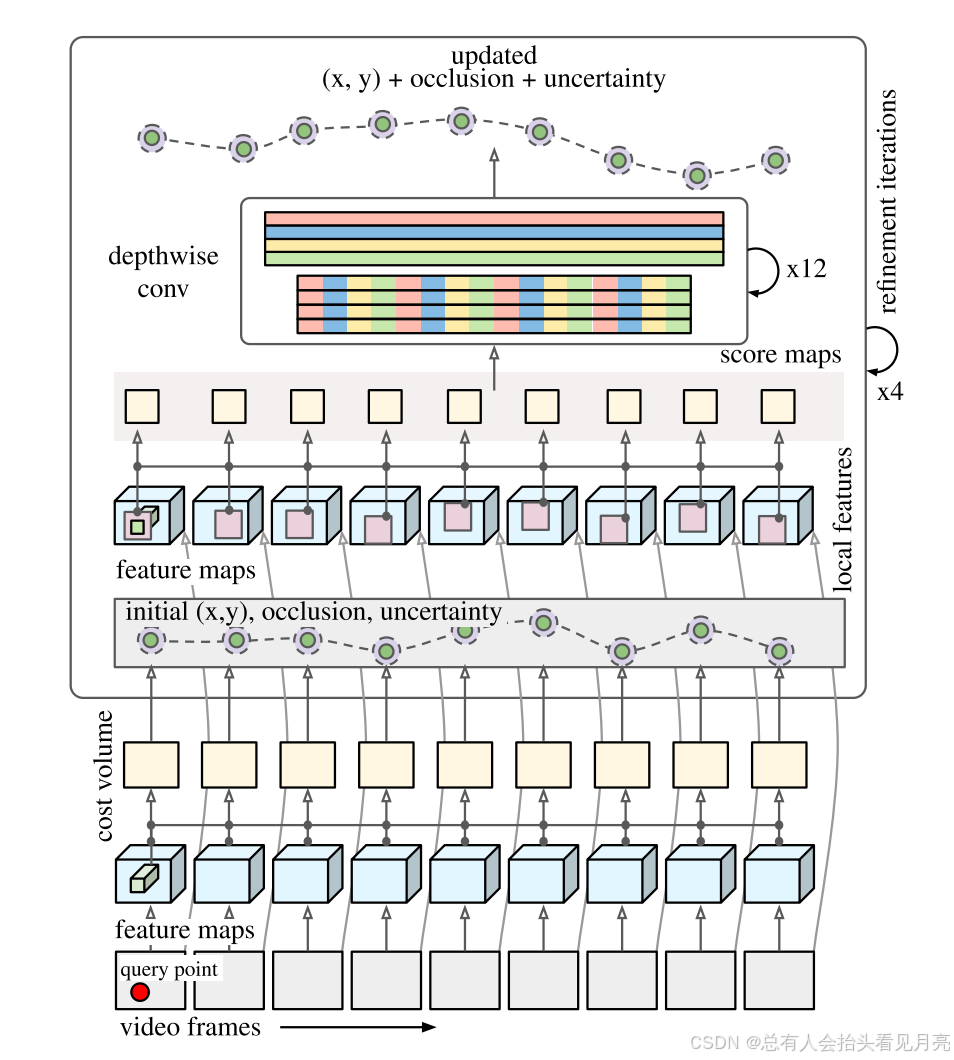
- 我们的模型首先对查询点特征和每个其他帧的特征进行全局比较,以计算初始轨迹估计,包括不确定性估计。
- 然后,我们从初始估计周围的局部邻域(以粉红色显示)中提取特征,并将这些特征与更高分辨率的查询特征进行比较,使用时间深度卷积网络对相似性进行后处理以获得更新的位置估计。
- 这个更新的位置被反馈到下一次细化迭代中,重复固定次数的迭代
TAPIR Model整体流程
模型的任务描述:给定一个视频和一个查询点,我们的目标是估计它在每隔一帧t中对应的2D位置pt,以及该点被遮挡的1D概率和估计位置的不确定性的1D概率ut
-
为了对遮挡具有鲁棒性,我们首先通过将查询特征与所有其他特征进行比较来匹配其他帧中的候选位置,并对相似性进行后处理以获得初始估计。
-
然后,我们细化估计,基于查询点和目标点之间的局部相似性。
请注意,这两个阶段主要取决于查询点特征和其他地方特征之间的相似性(点积)(即不仅仅是特征);这确保了我们不会过度拟合可能只出现在(合成)训练数据中的特定特征。
下面我们先通过注释的图和论文中的相关的描述来总结一下整个模型的整体流程,下面的部分粗略的点轨迹的估计就类似于TAP-NET的实现方式。
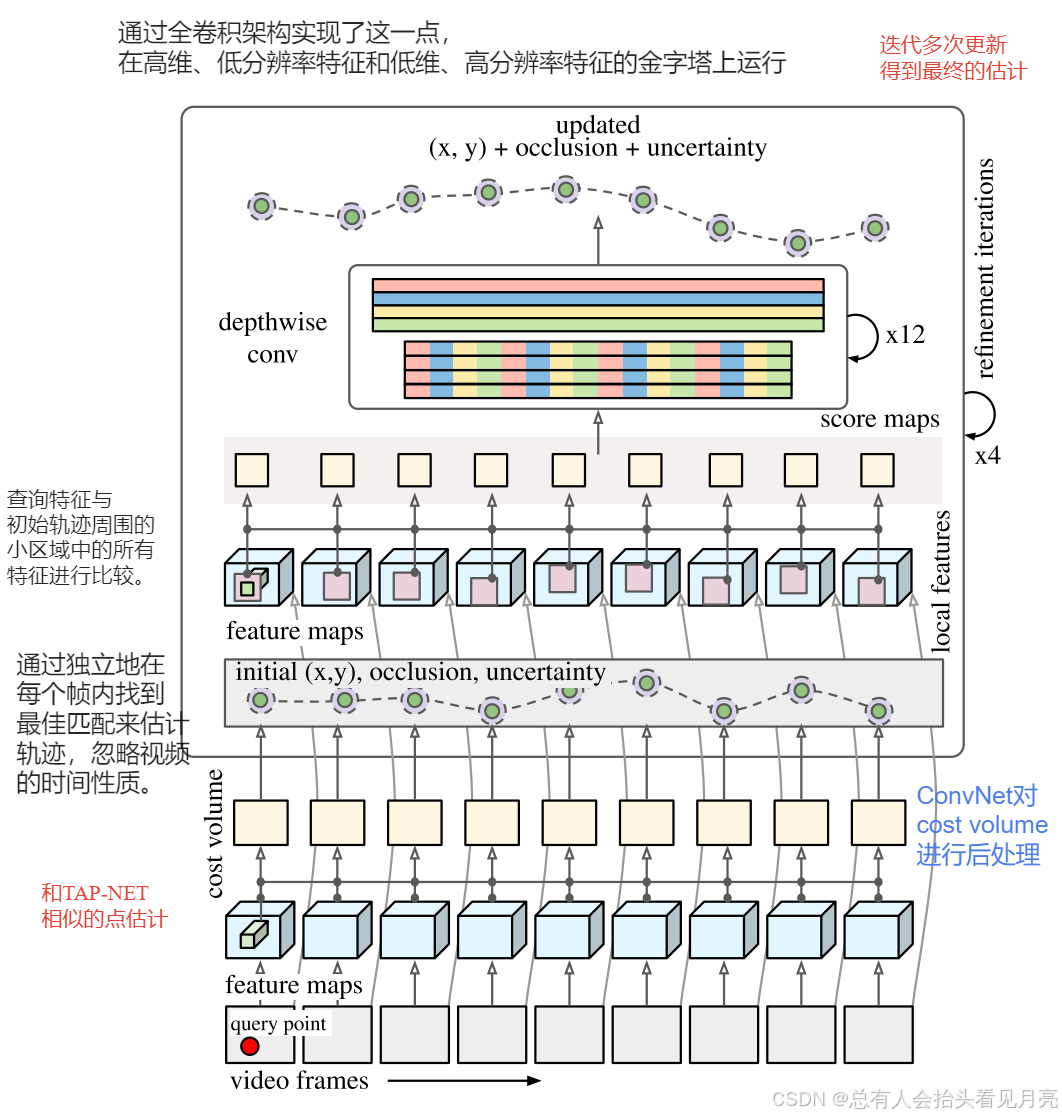
-
先通过独立地在每个帧内找到最佳匹配来估计轨迹,但忽略了视频的时间性质。(TAP-NET的缺点)
-
涉及cost volume:对于每个帧t,我们计算查询特征Fq与第t帧中的所有特征之间的点积。
-
我们使用ConvNet对成本量进行后处理,生成一个空间热图,然后以与TAP-Net大致相似的方式将其汇总为点估计。
上面涉及的类似TAP-NET的粗匹配阶段
-
给定初始化(有了初始化的估计),然后将查询特征与初始轨迹周围的小区域中的所有特征进行比较。
-
我们将比较结果输入到神经网络中,神经网络会更新查询特征和轨迹
-
TAPIR通过全卷积架构实现了这一点,在高维、低分辨率特征和低维、高分辨率特征的金字塔上运行,以最大限度地提高现代硬件的效率。多次迭代获得最后的结果。
们在整个架构中添加了位置不确定性的估计,以抑制低精度预测
核心细节-Track Initialization轨迹初始化
初始cost volume使用相对粗糙的特征图F来进行计算。其中T是帧的数量,H和W是图像的高度和宽度,C是通道的数量,使用标准的TSM-ResNet-18 主干计算。
F ∈ R T × H / 8 × W / 8 × C F \in R^{T \times H / 8 \times W / 8 \times C} F∈RT×H/8×W/8×C
查询点Fq的特征通过查询位置处的双线性插值来提取,并且我们在该查询特征和视频中的所有其他特征之间执行点积操作。
- 我们通过将一个小的ConvNet应用于与帧t对应的成本体积(其形状为H/8×W/8×1/每个查询)来计算位置和遮挡的初始估计值。
p t 0 = ( x t 0 , y t 0 ) 和 O t 0 p_{t}^{0}=\left(x_{t}^{0}, y_{t}^{0}\right) 和 O_{t}^{0} pt0=(xt0,yt0)和Ot0
- 这个ConvNet有两个输出:shape为H/8×W/8×1的热图用于预测位置,单个标量logit用于遮挡估计,通过平均池化然后投影获得。 这里和TAP-net基本上是类似的。
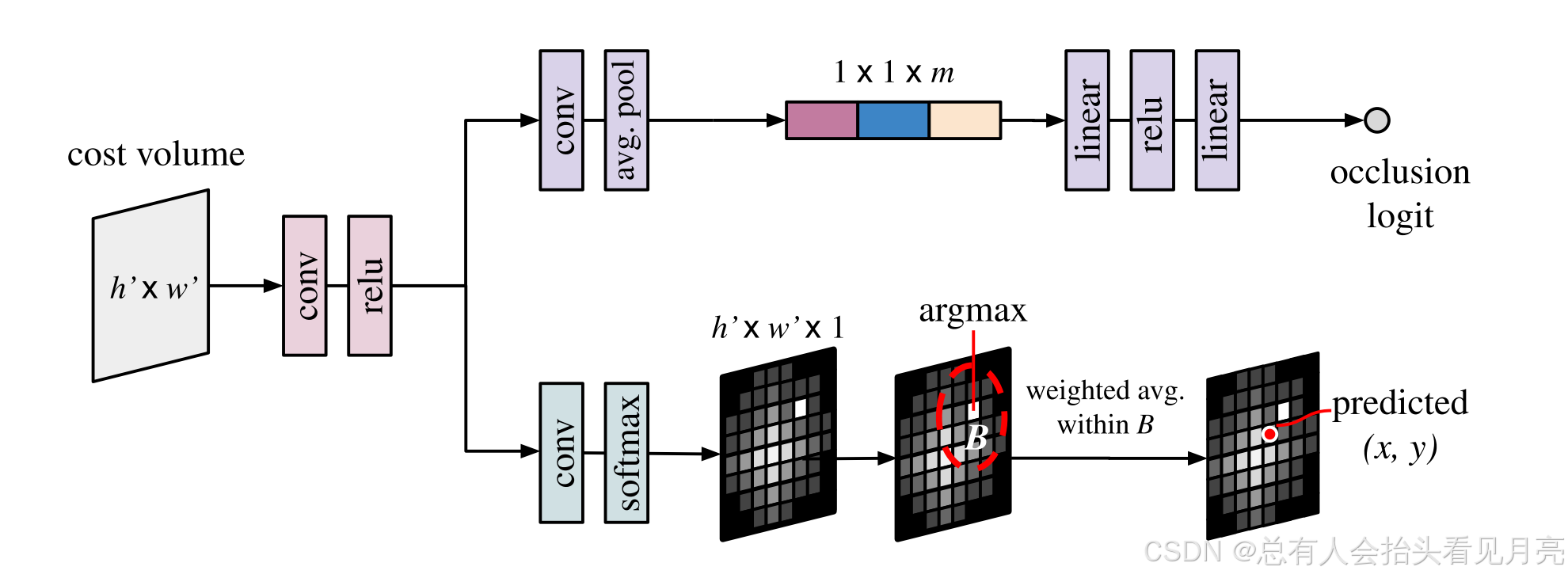
通过“空间软argmax”将热图转换为位置估计,即,一个softmax跨空间(使热图为正并求和为1)之后,将此热图中距离argmax位置太远的所有热图值设置为0
对热图的每个单元的位置进行空间平均,通过阈值化的热图幅度进行加权。
这里实际的计算步骤参考上面的一篇TAP-Net的细节描述和公式的形式
空间软argmax
- softmax处理热图:先对热图进行softmax操作,使得热图的所有值都为正且和为1。
- 位置加权平均:通过对热图位置进行加权平均来估计目标位置,而不是简单地使用硬argmax。
- 抑制远离目标位置的值:通过设置阈值,过滤掉距离argmax位置太远的热图值,减少噪声的影响。
- 空间平均与阈值化加权:通过对热图值进行空间平均,并根据阈值加权,只保留最重要的热图部分,进一步提高定位精度。
Position Uncertainty Estimates-位置估计的不确定性
- 独立于cost volume预测遮挡和位置的缺点(受TAP-Net启发的选择)是如果一个点在GT(
真实数据)中是可见的,那么如果算法预测了一个非常错误的位置,而不是简单地错误地将该点标记为被遮挡,情况会更糟。
解读:在某些模型中,如TAP-Net,遮挡和位置预测是独立进行的。也就是说,模型会分别预测目标的位置和是否被遮挡,而不是同时考虑这两个因素如果模型预测了一个非常错误的位置(例如,预测的位置远离真实位置),这个错误不仅意味着错过了目标的准确定位,还可能对后续任务(例如目标追踪、动作识别等)造成严重影响
如果模型错误地将可见的目标标记为遮挡,虽然这是一个错误的预测,但它相对较轻微。原因是遮挡预测主要影响模型对目标是否可见的认知,而不直接影响目标在空间中的位置。
-
这种误差往往发生在算法对位置不确定时。 例如,如果有很多潜在的匹配。因此,我们发现算法也可以估计其自身关于位置的确定性。
-
我们通过使遮挡路径输出第二个logit来量化这一点,估计预测可能与GT相距足够远的概率
u0t,即使模型预测它是可见的。
损失函数的初始化
L ( p t , o t , u t ) = Huber ( p ^ t , p t ) ∗ ( 1 − o ^ t ) + BCE ( o ^ t , o t ) + BCE ( u ^ t , u t ) ∗ ( 1 − o ^ t ) where, u ^ t = { 1 if d ( p ^ t , p t ) > δ 0 otherwise \begin{aligned} \mathcal{L}\left(p_{t}, o_{t}, u_{t}\right)= & \operatorname{Huber}\left(\hat{p}_{t}, p_{t}\right) *\left(1-\hat{o}_{t}\right) \\ & +\operatorname{BCE}\left(\hat{o}_{t}, o_{t}\right) \\ & +\operatorname{BCE}\left(\hat{u}_{t}, u_{t}\right) *\left(1-\hat{o}_{t}\right) \\ \text { where, } \quad \hat{u}_{t}= & \left\{\begin{array}{cc} 1 & \text { if } d\left(\hat{p}_{t}, p_{t}\right)>\delta \\ 0 & \text { otherwise } \end{array}\right. \end{aligned} L(pt,ot,ut)= where, u^t=Huber(p^t,pt)∗(1−o^t)+BCE(o^t,ot)+BCE(u^t,ut)∗(1−o^t){10 if d(p^t,pt)>δ otherwise

u ^ t \hat{u}_{t} u^t
是根据GT(真实)位置和网络的预测来计算不确定性估计的目标ut如果模型的位置预测足够接近真实的位置(在阈值δ内),则为0,否则为1
最后我们对这两个概率进行软组合:如果大于0.5则算法输出该点可见
( 1 − u t ) ∗ ( 1 − 0 t ) ≥ 0.5. \left(1-u_{t}\right) *\left(1-0_{t}\right) \geq 0.5 . (1−ut)∗(1−0t)≥0.5.
这里也就是要在点估计的时候对位置的不确定来进行估计。
核心细节 —Iterative Refinement(细化迭代)
给定每个帧的估计位置、遮挡和不确定性,我们的细化过程的每次迭代i的目标是计算更新.
( Δ p t i , Δ o t i , Δ u t i ) \left(\Delta p_{t}^{i}, \Delta o_{t}^{i}, \Delta u_{t}^{i}\right) (Δpti,Δoti,Δuti)
其将估计调整为更接近真实数据,从而跨时间整合信息。
跨时间整合信息的解读:跨时间信息:这里强调了通过时间序列数据(即多帧之间的联系),对目标点的状态进行连续性建模。这种跨时间信息的整合,能够让模型更好地利用运动趋势和帧间关系,提升预测的精度和稳定性。 调整为更接近真实数据:通过不断迭代更新,将当前帧的估计逐步修正为更加贴近真实情况(ground truth)的结果
- 更新基于一组“局部得分图”,其捕获与轨迹邻域中的特征的查询点相似性(即点积)。
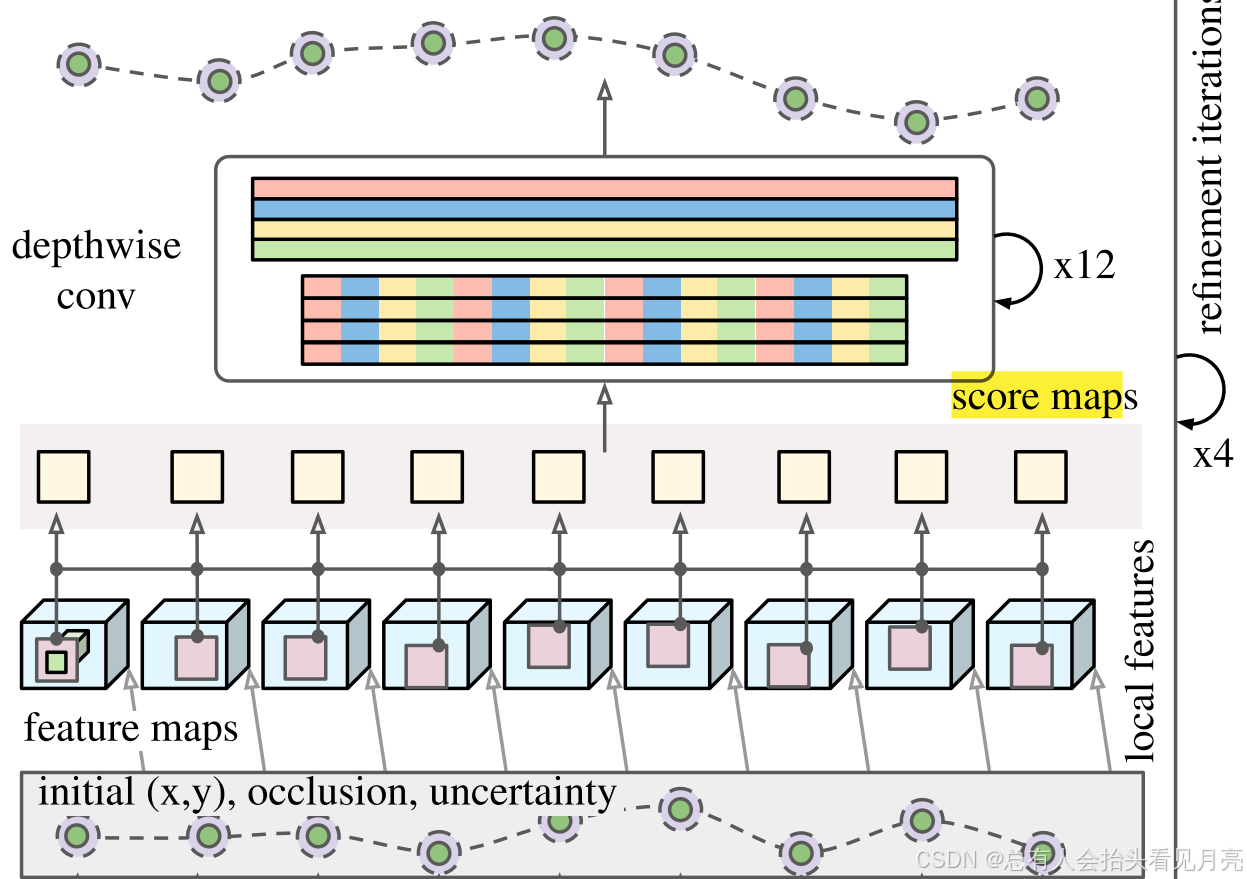
-
这些是在不同分辨率的金字塔上计算的,因此对于给定的轨迹,它们具有形状(H′ ×W′ × L),其中H′ = W′ = 7,局部邻域的大小,L是空间金字塔的层数(通过空间合并特征体积F来计算不同的金字塔级别)
-
与初始化一样,这组相似性用网络进行后处理,以预测精确的位置,遮挡和不确定性估计。然而,与初始化不同的是,我们同时将许多帧的“局部得分图”作为后处理的输入。
解读这里的许多帧就体现了在细化迭代阶段的时候,考虑多帧之间的联系。
- 我们将当前位置估计、原始查询特征和(展平的)局部得分图包含在形状为T ×(C + K + 4)的张量中,其中C是查询特征中的通道数,K = H′ · W′ · L是展平的局部得分图中的值数,以及位置、遮挡和不确定性的4个额外维度。
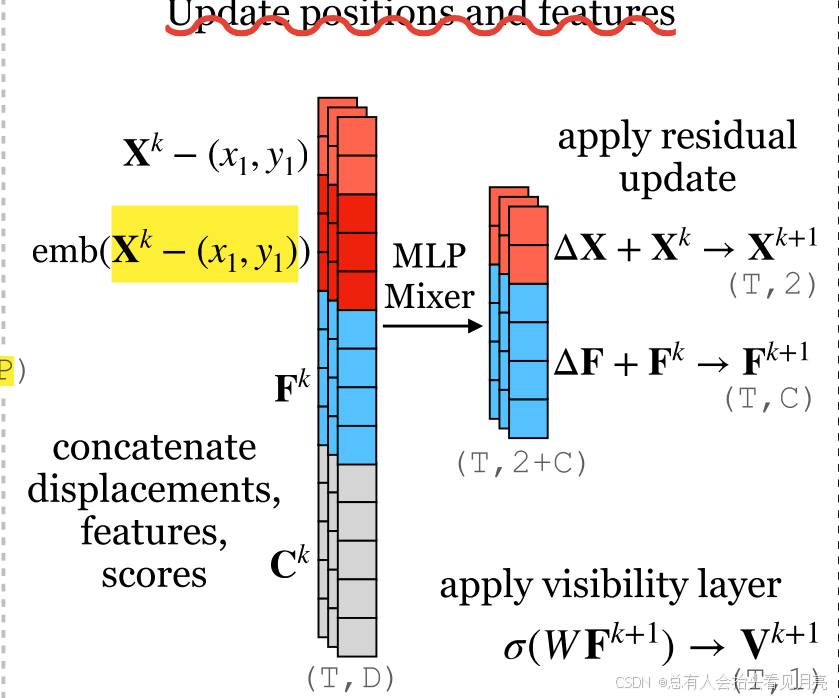
- 这个网络模型最后的输出就为:F代表的是查询特征的信息。
( Δ p t i , Δ o t i , Δ u t i , Δ F q , t , i ) \left(\Delta p_{t}^{i}, \Delta o_{t}^{i}, \Delta u_{t}^{i}, \Delta F_{q, t, i}\right) (Δpti,Δoti,Δuti,ΔFq,t,i)
Δ F q , t , i is of shape T × C ; \Delta F_{q, t, i} \text { is of shape } T \times C \text {; } ΔFq,t,i is of shape T×C;
- 这些位置和得分图被送入12块卷积网络以计算更新其中每个块由1×1卷积块和去卷积块组成。这种架构的灵感来自于PIPs中用于细化的MLP混合器:
( Δ p t i , Δ o t i , Δ u t i , Δ F q , t , i ) \left(\Delta p_{t}^{i}, \Delta o_{t}^{i}, \Delta u_{t}^{i}, \Delta F_{q, t, i}\right) (Δpti,Δoti,Δuti,ΔFq,t,i)
我们直接将Mixer的跨通道层转换为具有相同通道数量的1 x 1卷积,并且通道内操作变成类似的通道内深度卷积与PIP不同,PIP在运行MLP混合器之前将序列分解为8帧块,这种卷积架构可以在任何长度的序列上运行
Mixer架构:是一种用于处理序列数据的架构,典型的例子是MLP-Mixer(多层感知机混合器)。它的核心是通过两种操作分别处理通道间和通道内的信息.
- 跨通道操作:对序列的不同通道(例如多维特征)之间的信息进行融合,通常通过全连接层(MLP)完成。
- 通道内操作:对序列中单个通道内的数据进行独立处理,通常也是通过MLP实现。
将MLP-Mixer中的跨通道和通道内操作分别替换为1x1卷积和深度卷积,从而利用卷积的高效性和灵活性。 与PIP的主要区别在于,这种改进后的卷积架构可以直接在任意长度的序列上运行,而无需像PIP那样将序列分解为固定长度的块,因而更灵活且能捕获更多的全局信息。
- 用于计算“得分图”的特征图对于实现高精度是重要的。
通过以8 · 2l-1的步幅对原始TSM-ResNet特征F进行空间平均池化来计算金字塔的层级从L = 1至L-1然后计算查询特征Fq和金字塔特征之间的所有点积。
对于第t帧,我们提取一个7 × 7的点积块以Pt为中心。
- 我们可以根据需要多次重复细化步骤,重复使用相同的网络参数。在每次迭代中,我们在输出上使用相同的损失L,每次迭代的权重与初始化相同。
对于这一部分的细节后面还是要在结合代码来进行阅读学习来进一步的进行理解。
三种模型的讨论
下图描述了TAPIR与其他架构之间的关系。
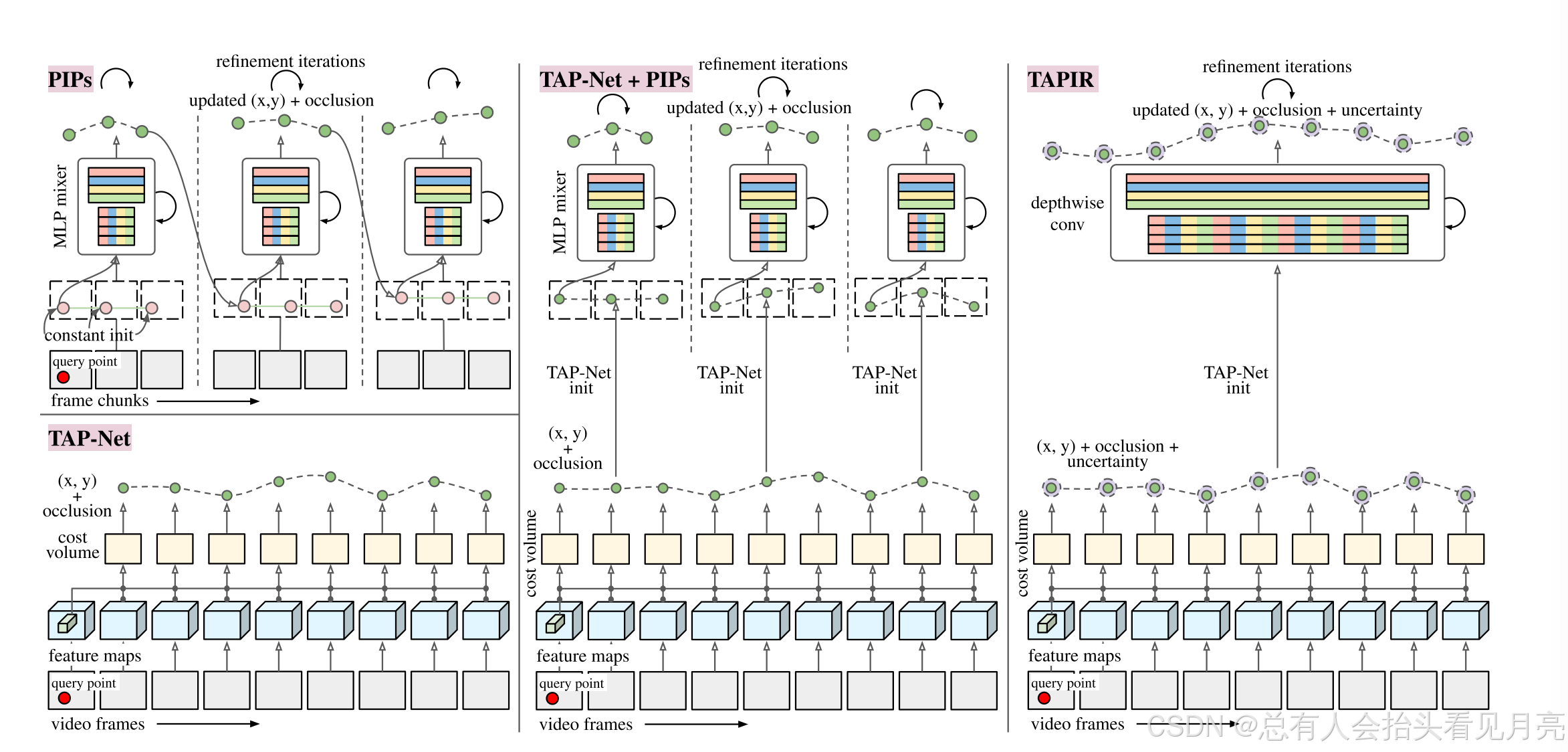
左:初始TAP-Net和PIP模型:TAP-Net对每帧进行独立估计,而PIP将视频分解为固定大小的块并顺序处理块。中间:这两种架构的“简单组合”,其中TAP-Net用于初始化PIP风格的分块迭代。右:我们的模型TAPIR,它删除了组块并增加了不确定性估计。请注意,为简单起见,未示出多尺度金字塔。
整合这两个模型并进行改进的主要的贡献可以描述如下所示。
-
首先,我们利用TAP-Net和PIP之间的互补性
-
其次,我们从PIP中删除了“链接”,用TAP-Net的初始化替换了初始化。我们通过对输入序列进行“分块”,直接应用PIP的MLP混合器架构。请注意,我们采用TAP-Net的特征网络进行初始化和细化。
-
最后,我们调整TAP-Net主干以提取多尺度和高分辨率金字塔(遵循PIP的stride-4测试时架构,但匹配TAP-Net的端到端训练)。
-
TAPIR的其他贡献如下:首先,我们用一种新的深度卷积架构完全取代了PIP的MLP混合器(必须应用于固定长度的序列),该架构具有类似数量的参数,但适用于任何长度的序列。
-
其次,我们引入了不确定性估计,这是计算在每一级的层次结构。这些都是“自我监督”的,因为目标取决于模型自己的输出。
Implementation Details代码补充

对于大多数实验,我们使用L = 5来匹配PIP,但在实践中我们发现L > 3影响很小(参见附录B.3)。因此,为了节省计算,我们的公共模型使用L = 3。更多详情请参见附录C.1。



















 2945
2945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











