







 本文介绍了如何编写大数据类型的论文模型,涵盖了神经网络模型、特征重要性排序(如XGBoost和随机森林)、特征序列选择(前向选择SFS)、集成学习(如AdaBoost、GBDT、LightGBM和CatBoost)以及模型融合(Stacking法)。通过这些方法,可以优化模型性能,降低特征冗余,提升预测准确性。
本文介绍了如何编写大数据类型的论文模型,涵盖了神经网络模型、特征重要性排序(如XGBoost和随机森林)、特征序列选择(前向选择SFS)、集成学习(如AdaBoost、GBDT、LightGBM和CatBoost)以及模型融合(Stacking法)。通过这些方法,可以优化模型性能,降低特征冗余,提升预测准确性。
文章目录
声明(先看)
以下的这些模型,是我从部分优秀论文中整理提取出来,并不是把所有的模型都列出来。很多人都不会写论文,因此大家参考一下别人怎么写的相关模型。
我不确保下面的模型查重,如果你想要直接复制到论文中,请注意查重,适当修改文字描述,模型就是这么写(主要针对大数据类型题目,这也是大多数人最喜欢的题目),更多模型可以自行从优秀论文中寻找
神经网络模型
神经网络模型的思想来源于模仿人类大脑思考的方式。神经元是神经系统最基本的结构和功能单位,人类大脑在思考时,神经元会接受外部的刺激,当传入的冲动使神经元的电位超过阈值时,神经元就会从抑制转向兴奋,并将信号向下一个神经元传导。神经网络的思想是通过构造人造神经元的方式模拟这一过程。
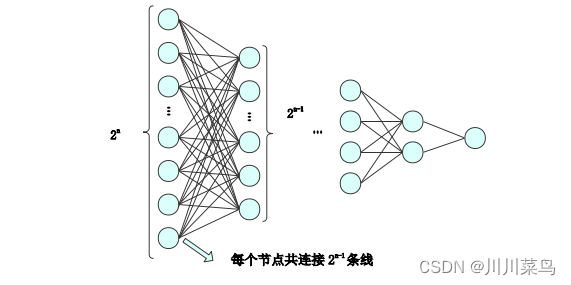
实际应用中,常常采用多层神经网络,在多层神经网络模型中,输入层和输出层间可以有多层隐藏层,层与层之间互相连接,信号通过线性变换和激活函数的复杂映射,不断地进行传递。Keras 是一个高层神经网络库。Keras 序列模型可以很容易地拟合回归数据并预测测试数据,Keras 分为两种类型的模型,顺序模型(Sequential)和泛型模型(Model),预测则在用顺序模型。Sequential 通过多个网络层的线性堆叠达到回归目的,具有极好的实用效果。其原理如下图:

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 606
606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











