






重点
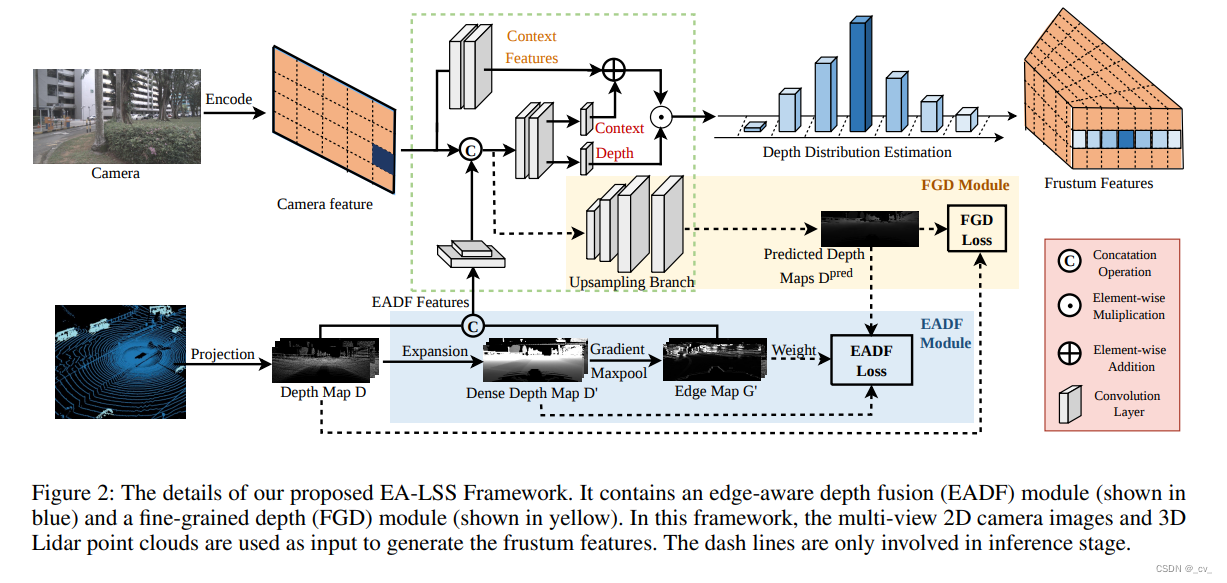
这篇文章最主要就是提出来两个模块,如上图所示,一个是FGD Module(Fine-grained Depth Module),另一个是EADF Module(Edge-aware Depth Fusion Module)
Fine-grained Depth Module
这个模块简单来说就是解决来自点云的投影深度图和预测深度图之间,由于两者稀疏程度不同,投影过来的真值更稀疏,导致算Loss的时候会有很多零值造成的影响这个问题,具体怎么解决看代码,就是这样一个东西。
Edge-aware Depth Fusion Module
第二个模块有趣一些,但也不是什么很精妙的设计吧。

如上图所示,我们从点云投影到图像上的深度图是非常稀疏的,大概只有5%左右的有效点,这个图叫D,然后做了一个什么事情呢?
把稀疏的深度图按k*k的block进行切分,然后用每个block中的最大值来进行形态学上的膨胀操作进行填充就会得到D’。然后在x轴和y轴方向求梯度,或者说求差值,得到G‘,在用最大池化归一化缩放到0-1之间。
F 【EADF】 = [D : G′].这个模块的输出就是D和G’拼到一块,就这样。

- 比较有趣的是,他还讲了一下自己怎么把深度的监督加到原本的lss上。
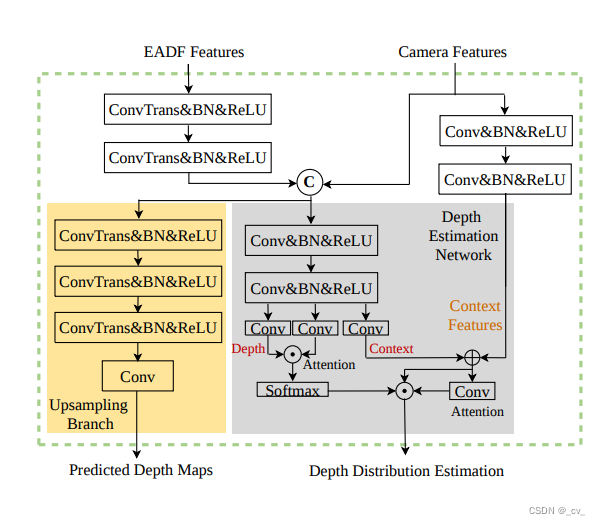
- 如图所示,他出了一个Predicted Depth Maps预测分支,用来监督深度,右边那部分是对lss有修改的,加了一些注意力来强化特征。论文里面是这么说的,为了充分利用深度信息,EADF模块F的输出特征被馈送到卷积层中,以提取其几何特征。并且将几何特征与图像特征融合作为深度网络的输入。此外,我们认为在融合几何信息后,图像的一些语义信息可能会丢失。因此,使用具有跳过连接的两个卷积层来帮助网络恢复丢失的语义信息。
- 我说的比较有趣的是这句”此外,我们认为在融合几何信息后,图像的一些语义信息可能会丢失“,原文”Besides, we believe that some semantic information of the image might be lost after fusing the geometric information. Hence two convolutional layers with a skip connection are used to help the network to restore the lost semantic information.“
文章就是这样,然后呢因为lss是个插件,可以和现有的很多算法相结合,于是就结合了一下此前的sota,bevfusion,然后得到一个新的sota就是这样。不管怎么说,结果是好的,至于工业界和学术界怎么看就不知道了。
















 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











