







原文链接:https://arxiv.org/abs/2303.17895
引言
目前的基于图像的BEV感知方法多使用LSS预测像素的深度分布,并根据深度估计将2D特征提升到3D空间。然而,实际场景中区域的深度差异较大(“深度跳变”),会导致不能准确估计边缘的深度。
为提高深度跳变区域深度估计的精度,本文提出边缘感知的深度融合(EADF)模块,为深度网络提供额外的边缘信息,以适应深度的快速变化。
此外,目前的方法不能充分利用来自点云的深度监督,本文提出细粒度深度(FGD)模块,包含上采样分支,用于匹配预测特征图和真实深度图的大小。该模块使深度估计网络更细粒度地感知深度分布,并尽可能多地保留原始深度信息。该模块仅用于训练,不会增加推断时间。
本文的方法称为边缘感知的LSS(EA-LSS),可适用于任何使用LSS的方法。
方法
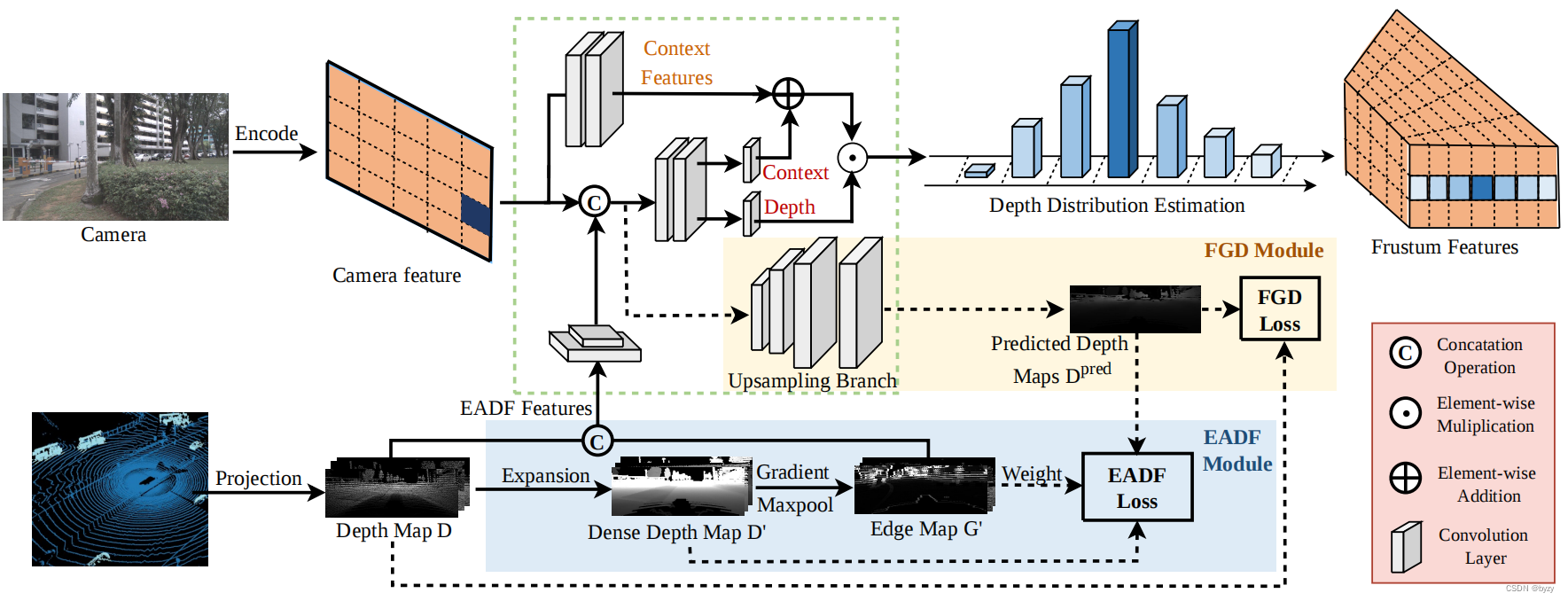
细粒度深度模块
来自点云的深度图及其稀疏,存在大量零值。为保留精确的深度信息,本文提出细粒度深度(FGD)模块,使用上采样分支处理预测深度图,该上采样分支作为额外的深度估计网络用于监督。
该模块使用focal损失作为细粒度深度损失以关注前景物体。来自点云投影的多视图深度图 D ∈ R N v × H × W D\in\mathbb R^{N_v\times H\times W} D∈RNv×H×W作为真值(其中的非零值转化为独热向量),与上采样分支的输出 D p r e d D^{pred} Dpred计算FGD损失:
L F G D = ∑ i = 1 n ∑ c = 1 H D − α c ( 1 − y i , c ) γ log ( y ^ i , c ) L_{FGD}=\sum_{i=1}^n\sum_{c=1}^{H_D}-\alpha_c(1-y_{i,c})^\gamma\log(\hat y_{i,c}) LFGD=i=1∑nc=1∑HD−αc(1−yi,c)γlog(y^
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











