







 本文介绍了如何使用Python的statsmodels库进行ARIMA模型构建,以时间序列数据——太阳黑子数据为例。首先进行了单位根检验和Ljung-Box检验,确定数据的平稳性和无自相关性;接着通过自相关图和偏自相关图确定模型参数,构建ARIMA模型;然后检查模型残差,确保其为白噪声;最后进行预测并评估模型效果,得出模型预测的太阳黑子活动具有较高准确性。
本文介绍了如何使用Python的statsmodels库进行ARIMA模型构建,以时间序列数据——太阳黑子数据为例。首先进行了单位根检验和Ljung-Box检验,确定数据的平稳性和无自相关性;接着通过自相关图和偏自相关图确定模型参数,构建ARIMA模型;然后检查模型残差,确保其为白噪声;最后进行预测并评估模型效果,得出模型预测的太阳黑子活动具有较高准确性。
(最近很多同学找我要统计学这个系列的数据,可以参考:贾俊平统计学,整本书的实验数据都在里面)
时间序列也是传统统计学很重要的一个领域,现代经济类的数据基本都是时间序列数据。时间序列最经典的模型自然是ARIMA模型,全称是自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model)。
原理本文就不过多介绍了,主要是讲述如何使用Python进行ARIMA建模的过程。
自回归主要是单变量模型,也就是一个变量一条数据。多个变量的叫做向量自回归模型(VAR)
为了方便,本次采用statsmodel里面自带的数据集,太阳黑子的数据集,这个数据集是明显带有周期性的。
首先导入包
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
from scipy import stats
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.graphics.api import qqplot
from statsmodels.stats.diagnostic import acorr_ljungbox as lb_test
from statsmodels.tsa.stattools import adfuller查看案例数据
太阳黑子数据
dta = sm.datasets.sunspots.load_pandas().data
dta.index = pd.Index(sm.tsa.datetools.dates_from_range("1700", "2008"))
dta.index.freq = dta.index.inferred_freq
del dta["YEAR"]
dta.plot(figsize=(10, 4))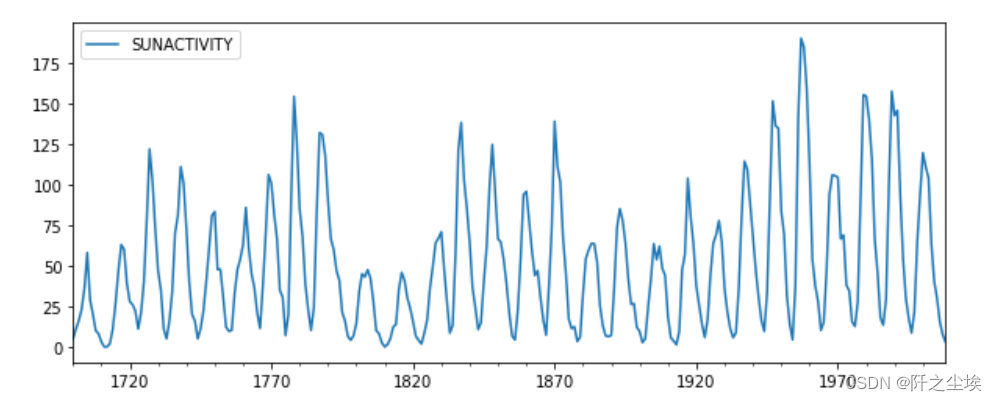
可以看到数据从1700年开始的,一直到2008年,数据口径是年度的,而且数据明显是带有周期性的。
单位根检验
时间序列建模都需要先检验数据的平稳性,最常用的是ADF单位根检验。实现如下
#单位根检验 原假设是存在单位根
adfuller(dta)
单位根检验的原假设是存在单位根,即数据不平稳。如果拒绝原假设就表明数据平稳。
结果分析:
第一个值(-2.83):Test Statistic。表示adf的t统计量的值,要和后面的
{'1%': -3.4523371197407404,
'5%': -2.871222860740741,
'10%': -2.571929211111111}
去对比,绝对值大于他们,就说明在该显著性水平下是显著的。
例如这里2.83大于2.57,但是小于2.87,说明该数据只能在10%的显著性水平下平稳。
第二个值(0.053):就是P值,这里的P为0.053,略微比0.05大量一点,说明在0.05的显著性水平下不显著,只能说明在10%的显著性水平下显著。和第一个值的结论是一致的。
第三个值(8):Lags Used,即表示延迟阶数
第四个值(300):Number of Observations Used,即表示测试的次数。
结论是在10%的显著性水平下该数据是平稳的,可以进行ARIMA模型的构建。
Ljung-Box 检验
LB检验,用来做纯随机性检验的。如果该数据的白噪声数据,即无自相关,没有啥规律,那么这个数据就没啥建模的价值,纯粹是随机游走的。
LB检验的原假设是不相关,即该数据是纯随机的,如果拒绝原假设,说明该数据有一定的规律,可以建模。
lb_test(dta, return_df=True,lags=5)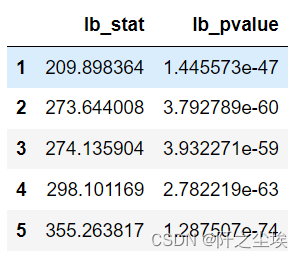
这里参数lags=5表示只检验滞后五期。我们可以看到五期的P值全部小于0.05,说明在0.05的显著性水平下,该数据不是纯随机序列。可以进行下一步建模。
自相关图和偏自相关图(ACF、PACF)
上面检验了该数据不是纯随机的,那么该数据的自相关阶数怎么确定,需要画图看,画出该数据的ACF和PACF图,自相关图和偏自相关图:
fig = plt.figure(figsize=(8, 5))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(dta.values.squeeze(), lags=40, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(dta, lags=40, ax=ax2)
plt.tight_layout()
plt.show()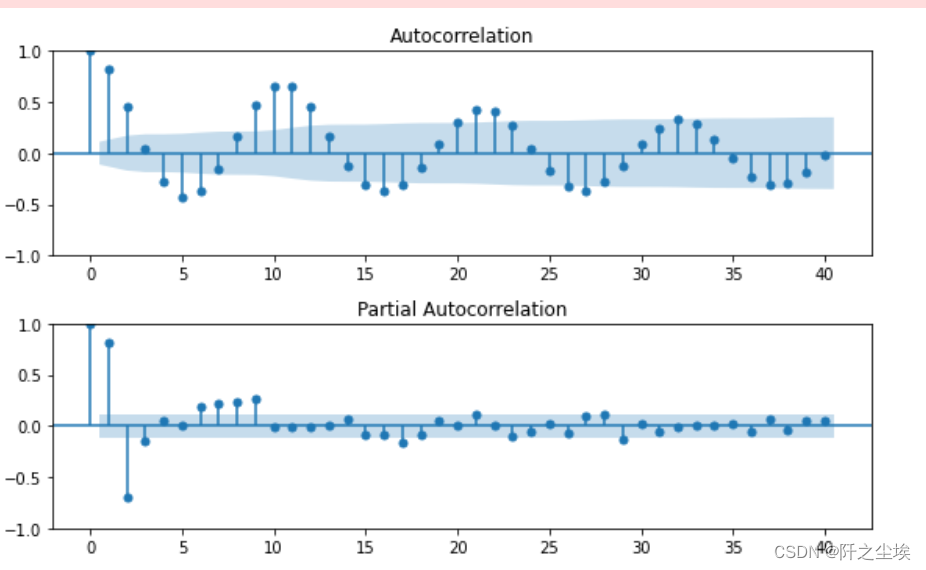
可以从图中看出,acf拖尾,pacf2阶截尾,应该拟合AR(2)模型
拟合模型
arma_mod20 = ARIMA(dta, order=(2, 0, 0)).fit()
print(arma_mod20.params)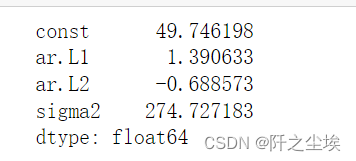 模型的参数
模型的参数
打印模型全部信息,输出和Eviews很像
print(arma_mod20.summary())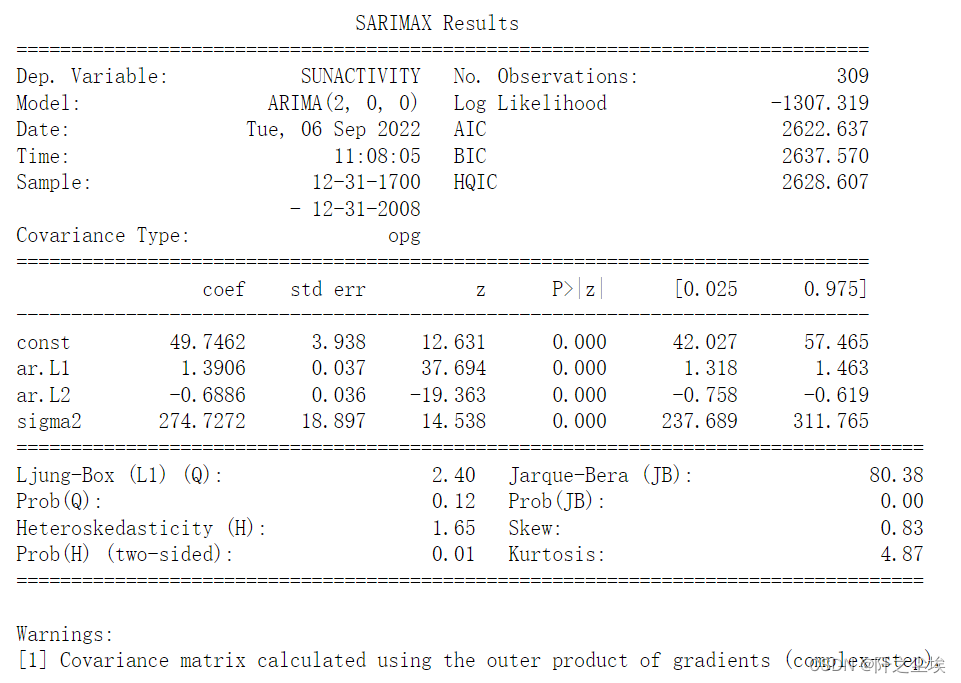
可以看到系数p值都为0,都很显著
计算模型的AIC,BIC,HQIC等等信息准则
print(arma_mod20.aic, arma_mod20.bic, arma_mod20.hqic)![]()
这几个信息准则都是越小越好,可能拟合其他阶数的模型,然后对比这些信息准则,再择优选择。
残差检验
模型拟合完了,还需要检验残差,看残差是否是白噪声,即纯随机序列,如果残差不是白噪声,说明模型提取的规律不够充分,还需再处理。
首先要检验残差是否服从正态分布,画图查看,然后检验
arma_mod20.resid.plot(figsize=(10,3))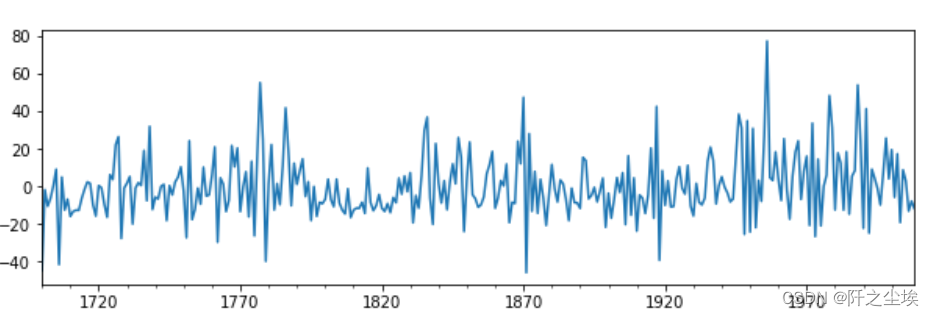
stats.normaltest(arma_mod20.resid)
画 QQ图看正态性
qqplot(arma_mod20.resid, line="q", fit=True) 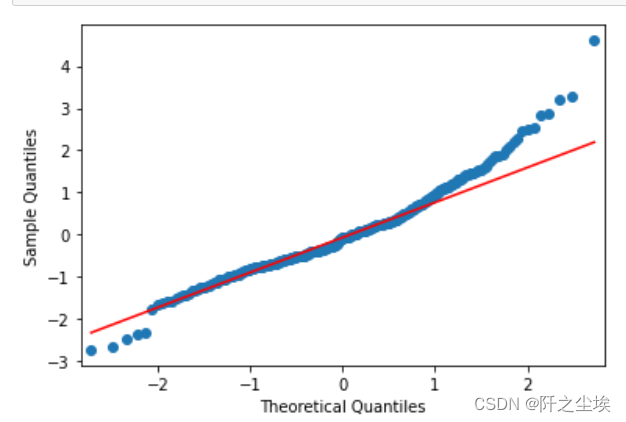
emmm,好像不太正态,但是残差均匀分布在0轴上下,应该也不存在异方差等问题。
DW检验
sm.stats.durbin_watson(arma_mod20.resid.values)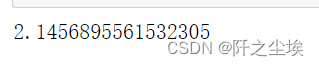
DW 越接近于0,正自相关性越强。
DW 越接近2,判断无自相关性把握越大。这里DW=2.14,说明差不多一个无自相关了。
进一步做LB检验
LB检验
lb= lb_test(arma_mod20.resid, return_df=True,lags=5)
print(lb)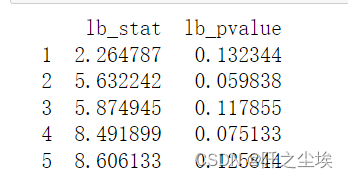
还是检验五期,可以看到在0.05的显著性水平下,五期都是接受原假设,说明残差是纯随机序列,模型已经充分提取了数据里面的规律。拟合良好。
最后再看看残差的自相关和偏自相关的图
ACF/PACF
fig = plt.figure(figsize=(8, 5))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(arma_mod20.resid.values.squeeze(), lags=40, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(arma_mod20.resid, lags=40, ax=ax2)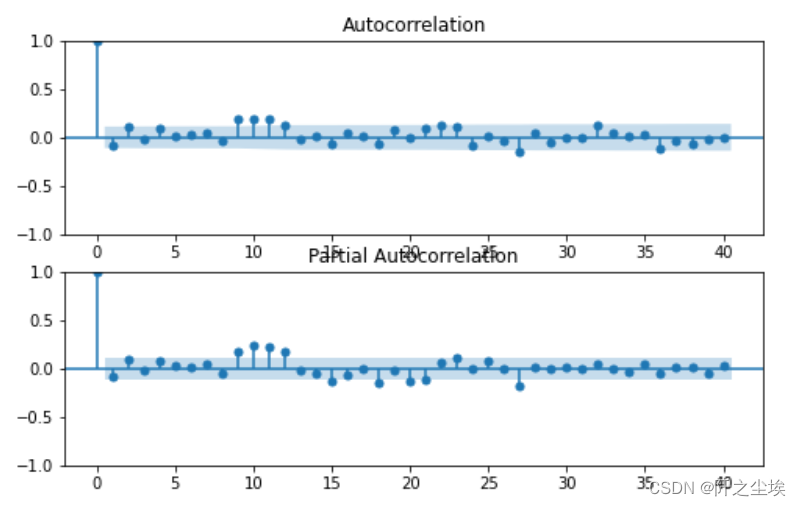
可以看到ACF和PACF都是截尾,和上面结论一致,残差里面不存在信息了。
模型预测
时间序列建模的最大作用就是预测,预测这个数据后面的发展。
原始数据是从1700年到2008年的,这里我们预测从1700年到2022年,多预测14年,然后画在一张图上对比。
predict_sunspots = arma_mod20.predict("1700", "2022", )#dynamic=True)
print(predict_sunspots)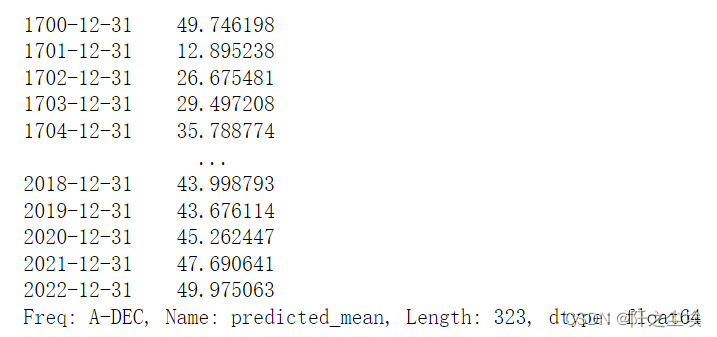
画图
plt.figure(figsize=(10,4))
plt.plot(dta.index,dta.SUNACTIVITY,label='actual')
plt.plot(predict_sunspots.index,predict_sunspots,label='predict')
plt.legend(['actual','predict'])
plt.xlabel('time(year)')
plt.ylabel('SUNACTIVITY')
plt.show()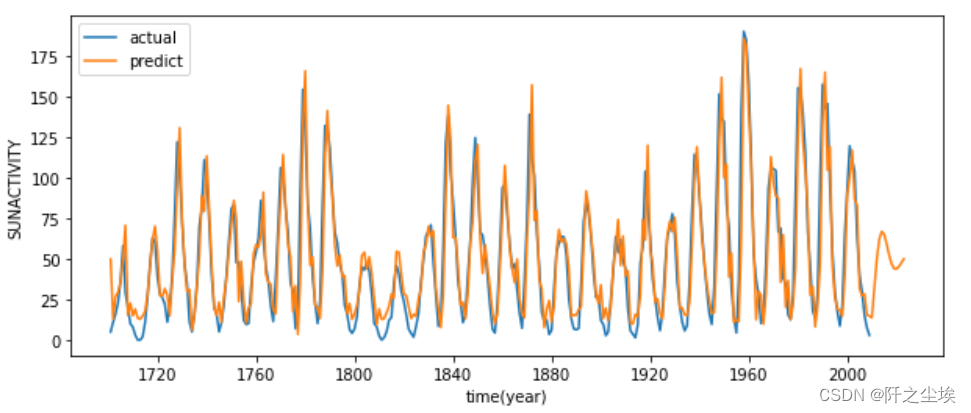
蓝色是真实原始值,黄色是预测值,可以看到效果还是不错的。
最后面最后一小截没有蓝色线,只有黄色的线,因为2009-2022没有真实值,只有黄色预测的值,
模型评价
数值型的回归问题的评价指标很多,这里采用mae和rmse进行评价。
from sklearn.metrics import mean_absolute_error,mean_squared_error
def evaluation(y_test, y_predict):
mae = mean_absolute_error(y_test, y_predict)
mse = mean_squared_error(y_test, y_predict)
rmse = np.sqrt(mean_squared_error(y_test, y_predict))
#mape=(abs(y_predict -y_test)/ y_test).mean()
return mae, rmse, #mapeevaluation(dta.to_numpy(), predict_sunspots[:len(dta)].to_numpy())![]()
mae和rmse的值都比较小,模型效果不错。


















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











