







在这篇博客中,我们将全面探讨时间序列分析的基本概念和分类,深入理解平稳性及其检验方法,并介绍自回归模型(AR)、滑动平均模型(MA)、自回归滑动平均模型(ARMA)以及自回归积分滑动平均模型(ARIMA)的定义和应用。此外,我们还将讨论如何选择最优模型,并解释AIC和BIC准则在模型选择中的重要性。这篇博客将为您提供时间序列分析的系统性知识和实用技巧,助您在实际项目中有效地应用这些方法。
一、基本概念
1 定义和分类
时间序列是按时间顺序排列的、随时间变化且相互关联的数据序列。分析时间序列的方法构成数据分析的一个重要领域,即时间序列分析。 时间序列根据所研究的依据不同,可有不同的分类:
- 按所研究的对象的多少分,有一元时间序列和多元时间序列。
- 按时间的连续性可将时间序列分为离散时间序列和连续时间序列两种。
- 按序列的统计特性分,有平稳时间序列和非平稳时间序列。
- 按时间序列的分布规律来分,有高斯型时间序列和非高斯型时间序列。
2 平稳性
以股票为例,每个时间点上的股票价格都应该被视为一个随机变量,简单说就是它服从某个分布,落入(被确定为)某些值的概率是有规律的。既然是随机变量,那这么多天的价格,就是一群随机变量了,那我们如果能求出它们的联合分布,显然它们也不可能是独立的,一个点是一天的价格,k天的价格便是一个线段,这个线段在时间轴上滑动时,对应的价格的联合分布不变,这就是严平稳。
给出的准确定义是:
r t i r_{t_{i}} rti 代表 t i t_{i} ti 时刻下的价格这个随机变量, t \mathrm{t} t 是滑动的距离,F是联合分布概率:
F ( r t 1 , r t 2 , … , r t k ) = F ( r t 1 + t , r t 2 + t , … , r t k + t ) F\left(r_{t_{1}}, r_{t_{2}}, \ldots, r_{t_{k}}\right)=F\left(r_{t_{1}+t}, r_{t_{2}+t}, \ldots, r_{t_{k}+t}\right) F(rt1,rt2,…,rtk)=F(rt1+t,rt2+t,…,rtk+t)
严平稳是很强的条件, 能不能放宽松一点呢, 于是出现了宽平稳, 也叫弱平稳:
定义:
r t r_{t} rt 的均值、 r t r_{t} rt 和 r t − l r_{t-l} rt−l 的协方差不随时间的变化而变化
- 从直观上理解, 我们要求一段段时间价格的分布是不变的, 大部分情况下, 这个严格要求相同的条件, 必然包含了弱平稳所要求的条件, 出于要求的放宽, 我们要求均值要一致, 个个时间点上的差异只和距离有关。
准确的定义是:
(1) E ( r t ) = μ E\left(r_{t}\right)=\mu E(rt)=μ
(2) Cov ( r t , t t − l ) = γ l , l \operatorname{Cov}\left(r_{t}, t_{t-l}\right)=\gamma_{l}, l Cov(rt,tt−l)=γl,l 是间隔距离
- 由 Cov ( r t , t t − l ) = γ l \operatorname{Cov}\left(r_{t}, t_{t-l}\right)=\gamma_{l} Cov(rt,tt−l)=γl ,可以推出一下性质:
- γ 0 = Var ( r t ) \gamma_{0}=\operatorname{Var}\left(r_{t}\right) γ0=Var(rt)
- γ − l = γ l \gamma_{-l}=\gamma_{l} γ−l=γl
- 性质 2是因为 Cov ( r t , r t + l ) = Cov ( r t + l , r t ) \operatorname{Cov}\left(r_{t}, r_{t+l}\right)=\operatorname{Cov}\left(r_{t+l}, r_{t}\right) Cov(rt,rt+l)=Cov(rt+l,rt), 协方差互换位置不变
接下来介绍相关系数
ρ
\rho
ρ,定义:
ρ
x
,
y
=
Cov
(
X
,
Y
)
Var
(
X
)
Var
(
Y
)
=
E
[
(
X
−
μ
x
)
(
Y
−
μ
y
)
]
E
(
X
−
μ
x
)
2
E
(
Y
−
μ
y
)
2
\rho_{x, y}=\frac{\operatorname{Cov}(X, Y)}{\sqrt{\operatorname{Var}(X) \operatorname{Var}(Y)}}=\frac{E\left[\left(X-\mu_{x}\right)\left(Y-\mu_{y}\right)\right]}{\sqrt{E\left(X-\mu_{x}\right)^{2} E\left(Y-\mu_{y}\right)^{2}}}
ρx,y=Var(X)Var(Y)Cov(X,Y)=E(X−μx)2E(Y−μy)2E[(X−μx)(Y−μy)]
重要性质说两点:
(1)
ρ
∈
[
−
1
,
1
]
\rho \in[-1,1]
ρ∈[−1,1]
(2)
ρ
x
,
y
=
ρ
y
,
x
\rho_{x, y}=\rho_{y, x}
ρx,y=ρy,x
当
ρ
x
,
y
=
0
\rho_{x, y}=0
ρx,y=0, 说明随机变量不相关, 主义不相关和独立还是不一样的, 只有当正态的时候才是等价的。
3 自相关和偏自相关
(1)定义
自相关系数(autocorrelation coefficient,AC)和偏自相关系数(partial autocorrelation coefficient,PAC)是统计学中定义的概念,是用以反映变量之间相关程度的统计指标,只是两者表现的具体变量之间的关系有所不同。
自相关系数:当研究一个变量受另一个变量影响时,若同时考虑其他变量的影响,此时分析变量之间的关系强弱程度称为相关系数。
偏自相关系数:若研究一个变量受另一个变量影响时,其他的影响变量要视作常数,即暂时不考虑其他因素影响,单独考虑这两个变量的关系程度,此时分析变量之间的关系用的是偏相关系数。
(2)ACF
A
C
F
\mathrm{ACF}
ACF, 自相关函数 , 把
r
t
r_{t}
rt 和
r
t
−
l
r_{t-l}
rt−l 的相关系数称为时间间隔为
l
l
l 的自相关系数:
ρ
ℓ
=
Cov
(
r
t
,
r
t
−
ℓ
)
Var
(
r
t
)
Var
(
r
t
−
ℓ
)
=
Cov
(
r
t
,
r
t
−
ℓ
)
Var
(
r
t
)
=
γ
ℓ
γ
0
\rho_{\ell}=\frac{\operatorname{Cov}\left(r_{t}, r_{t-\ell}\right)}{\sqrt{\operatorname{Var}\left(r_{t}\right) \operatorname{Var}\left(r_{t-\ell}\right)}}=\frac{\operatorname{Cov}\left(r_{t}, r_{t-\ell}\right)}{\operatorname{Var}\left(r_{t}\right)}=\frac{\gamma_{\ell}}{\gamma_{0}}
ρℓ=Var(rt)Var(rt−ℓ)Cov(rt,rt−ℓ)=Var(rt)Cov(rt,rt−ℓ)=γ0γℓ
如果这数据是弱平稳的
Var
(
r
t
)
=
Var
(
r
t
−
l
)
\operatorname{Var}\left(r_{t}\right)=\operatorname{Var}\left(r_{t-l}\right)
Var(rt)=Var(rt−l), 因为协方差只和
l
l
l 有关嘛,
l
=
0
l=0
l=0 的时候就是方差。
根据样本数据估计:
ρ
^
ℓ
=
∑
t
=
ℓ
+
1
T
(
r
t
−
r
ˉ
)
(
r
t
−
ℓ
−
r
ˉ
)
∑
t
=
1
T
(
r
t
−
r
ˉ
)
2
,
0
≤
ℓ
<
T
−
1
\hat{\rho}_{\ell}=\frac{\sum_{t=\ell+1}^{T}\left(r_{t}-\bar{r}\right)\left(r_{t-\ell}-\bar{r}\right)}{\sum_{t=1}^{T}\left(r_{t}-\bar{r}\right)^{2}}, \quad 0 \leq \ell<T-1
ρ^ℓ=∑t=1T(rt−rˉ)2∑t=ℓ+1T(rt−rˉ)(rt−ℓ−rˉ),0≤ℓ<T−1
我们把
ρ
^
1
,
ρ
^
2
,
…
\hat{\rho}_{1}, \hat{\rho}_{2}, \ldots
ρ^1,ρ^2,….称为
r
t
r_{t}
rt 的样本自相关函数 (ACF).
事实上如果ACF的值在两个标准差内, 我们就可以认为在 5 % 5 \% 5% 的水平下它们和 0 没有显著差别,如下图所示,所有间隔 ρ l \rho_l ρl均在阴影部分外,说明95%的置信度数据相关。
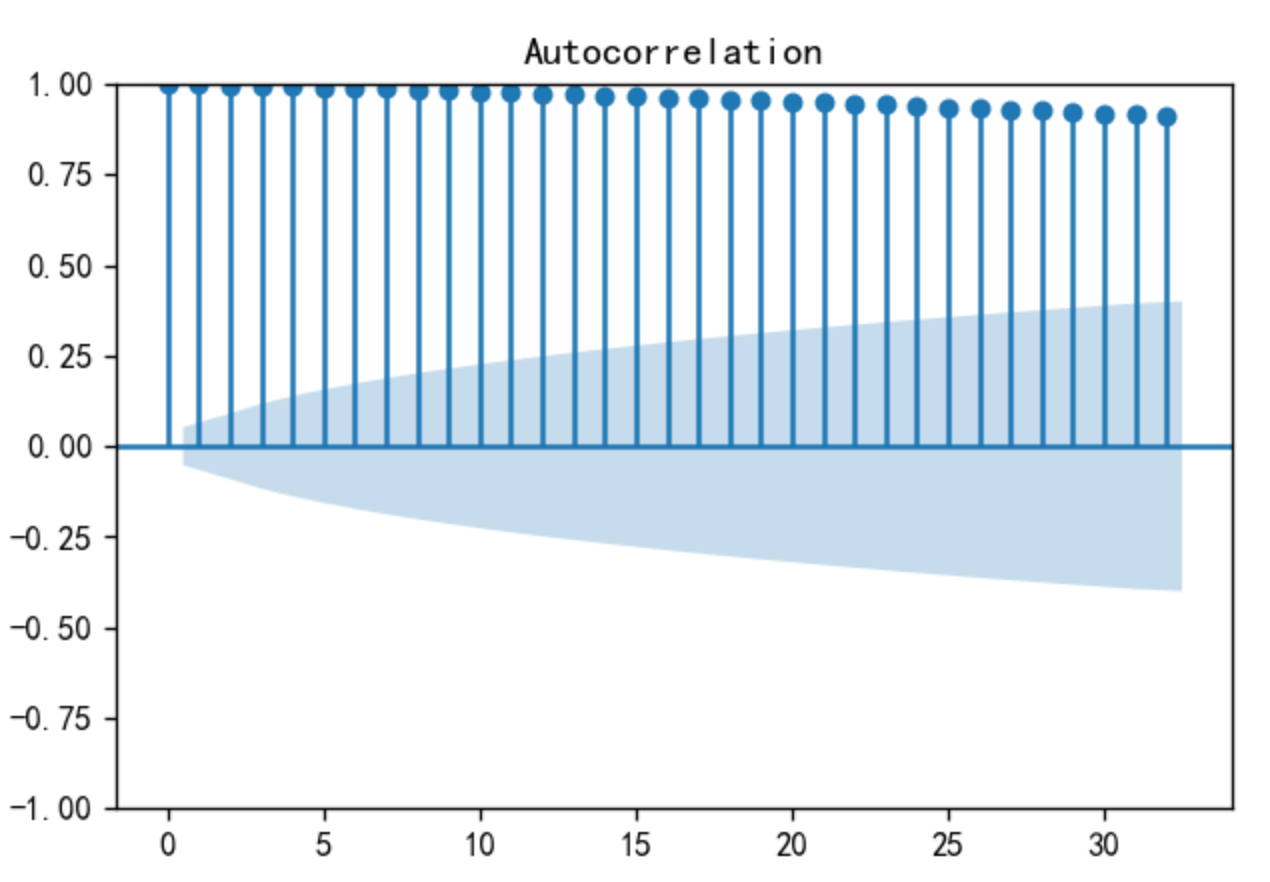
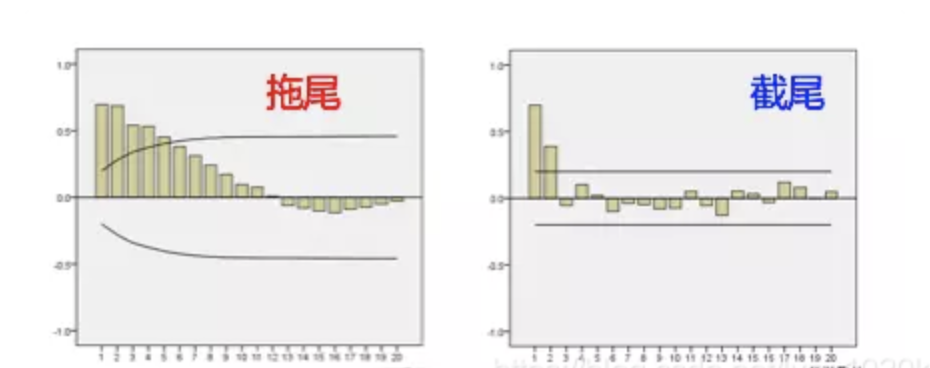
(3)拖尾和截尾
拖尾是指序列以指数率单调递减或震荡衰减,而截尾指序列从某个时间点变得非常小。
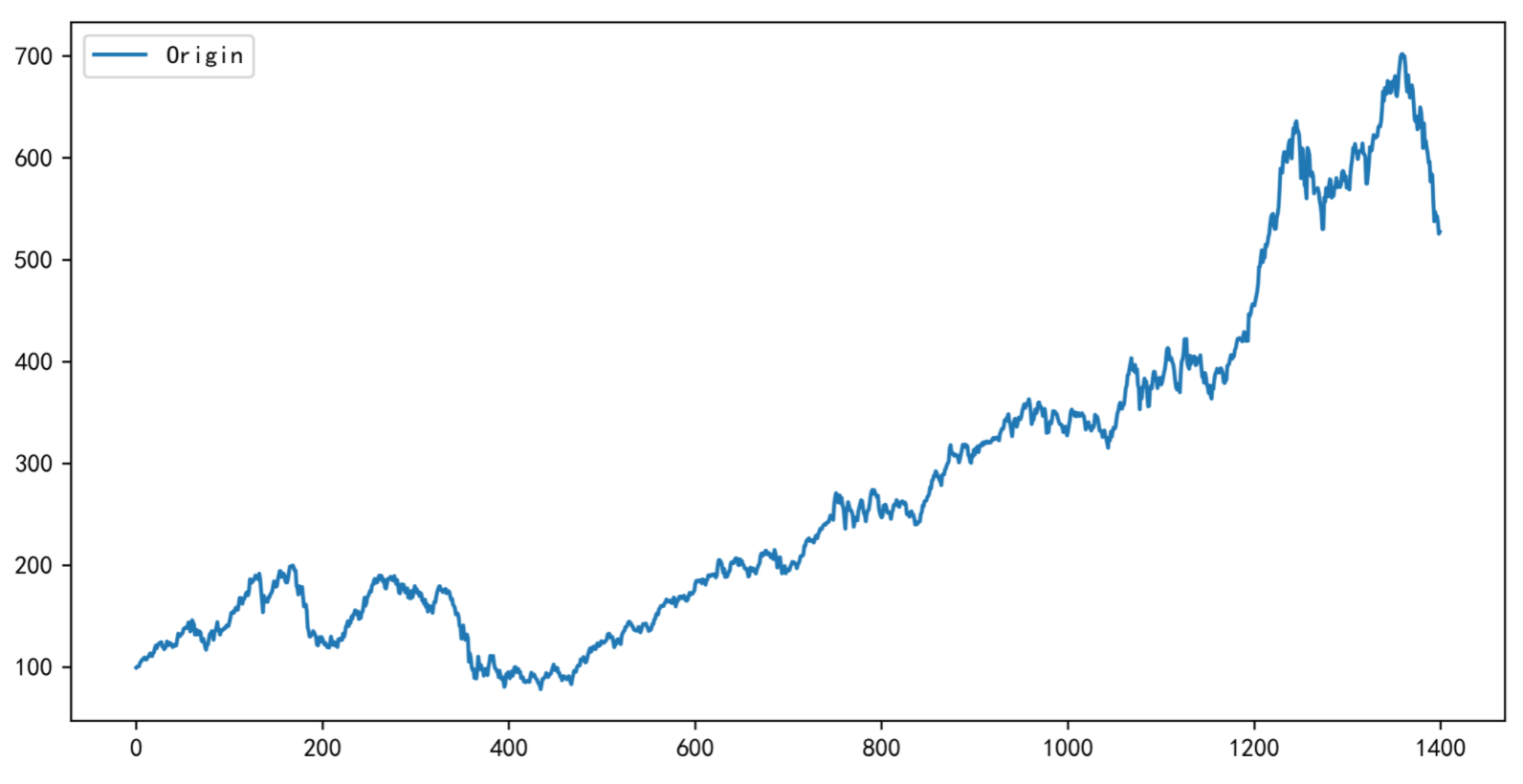
4 平稳性检验
(1)时序图观察
平稳时序定义要求均值、方差为常数,协方差仅仅与时间间隔相关。从定义入手,时序图满足以下任一条件的不是平稳时序:
- 时序存在明显的趋势,即均值不为常数
- 时序存在集群效应,即某段时间的波动幅度较其它时段明显较大或者较小,即方差不为常数
如下时序图具有明显的趋势:
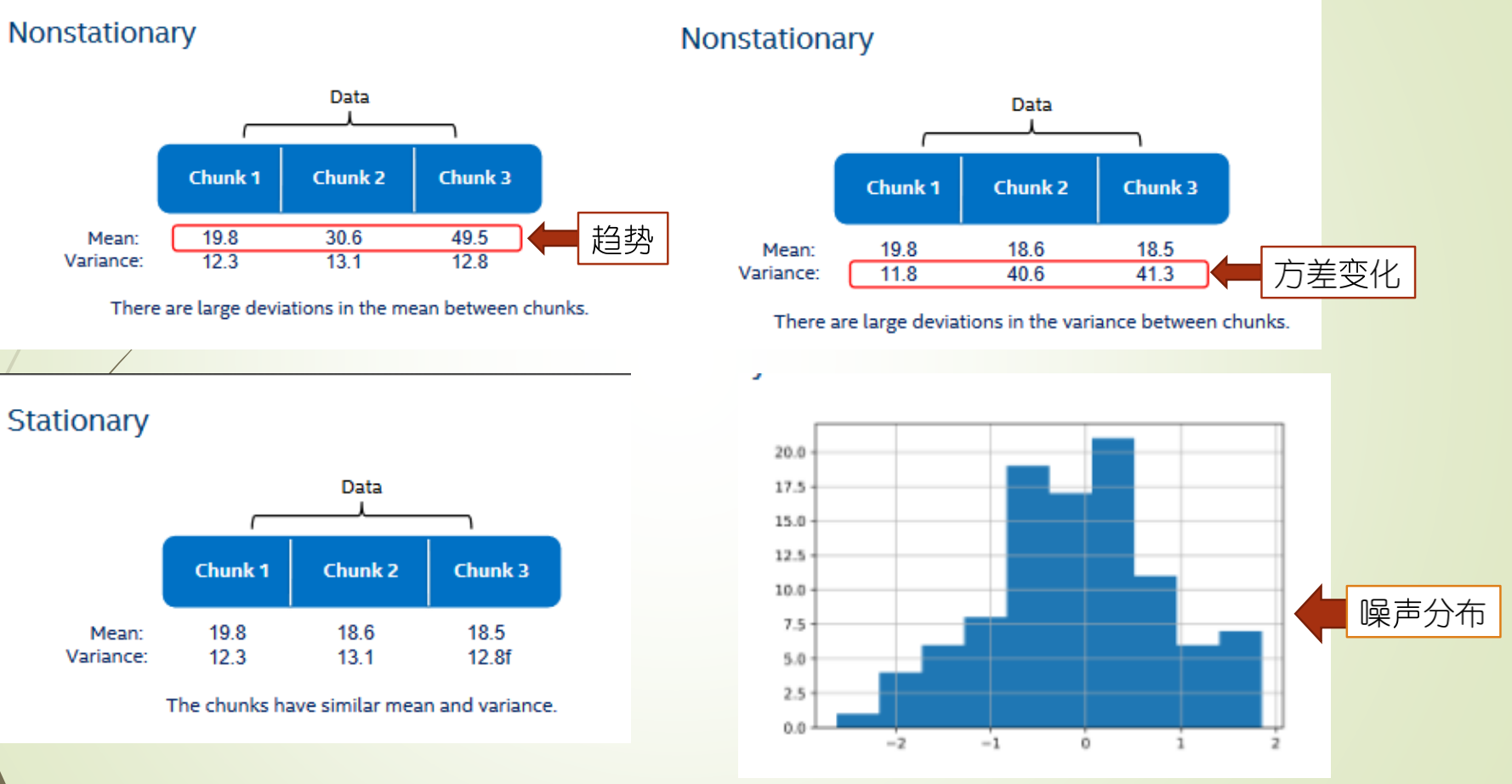
(2)滑窗检验
可以用一个滑窗去验证时间序列是否满足:
- 均值、方差为常数
- 协方差仅仅与时间间隔相关。
(3) ACF图检验
平稳时序往往仅具有短期自相关性,长期的 ACF 会振荡随机趋近于0。因此,当 ACF 图不满足这一条件时,可以认为时序非平稳。如何理解振荡与随机呢?下面给出几个 ACF 图检验的例子:
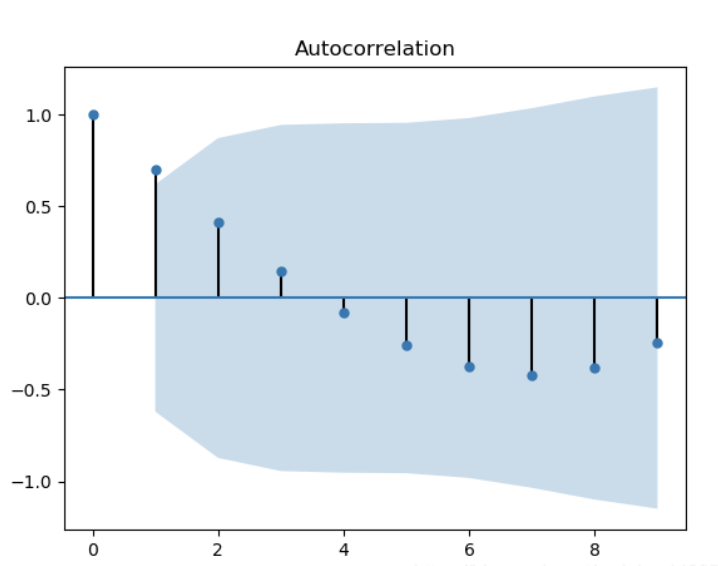
上图在 k >= 2 时就已经趋于非相关的了,但是并没有满足随机趋于 0 的条件,该图中的 ACF(k) 先连续4项正值,然后连续6项负值,整个图形呈现出倒三角的形状,这意味着时序中存在明显的趋势,为非平稳时序。
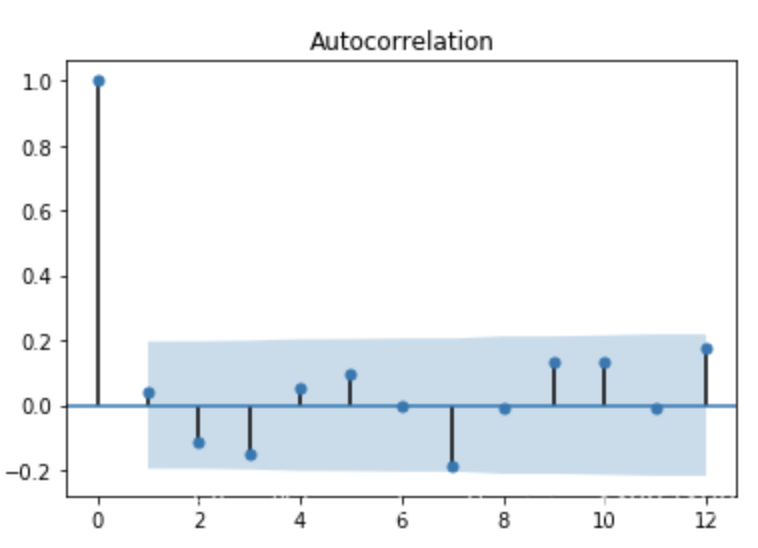
上图是平稳时序的 ACF 图的一个例子,可以看到 ACF(k) 没有出现规律性,振荡随机趋近于0,可以认为时序平稳。
总结来看,当 ACF 图满足下列任一条件时,可以认为时序为非平稳时序:
- ACF 图正项与负项连续交替出现,呈现倒三角形,意味着时序中存在趋势
- ACF 图拖尾,即当 k 很大时仍有 ACF(k) 显著
(4) ADF检验
除了用观察检测的方法,另外比较常用的严格的统计检验方法就是ADF检验,也叫做单位根检验。
ADF检验全称是 Augmented Dickey-Fuller test,顾名思义,ADF是 Dickey-Fuller检验的增广形式。DF检验只能应用于一阶情况,当序列存在高阶的滞后相关时,可以使用ADF检验,所以说ADF是对DF检验的扩展。
单位根(unit root)
在做ADF检验,也就是单位根检验时,需要先明白一个概念,也就是要检验的对象——单位根。
当一个自回归过程中: ,如果滞后项系数b为1,就称为单位根。当单位根存在时,自变量和因变量之间的关系具有欺骗性,因为残差序列的任何误差都不会随着样本量(即时期数)增大而衰减,也就是说模型中的残差的影响是永久的。这种回归又称作伪回归。如果单位根存在,这个过程就是一个随机漫步(random walk)。
ADF检验的原理
ADF检验就是判断序列是否存在单位根:如果序列平稳,就不存在单位根;否则,就会存在单位根。
所以,ADF检验的 H0 假设就是存在单位根,如果得到的显著性检验统计量小于三个置信度(10%,5%,1%),则对应有(90%,95,99%)的把握来拒绝原假设。
ADF检验可以通过python中的 statsmodels 模块中的adfuller函数:
adfuller函数的参数意义分别是:
- x:一维的数据序列。
- maxlag:最大滞后数目。
- regression:回归中的包含项(c:只有常数项,默认;ct:常数项和趋势项;ctt:常数项,线性二次项;nc:没有常数项和趋势项)
- autolag:自动选择滞后数目(AIC:赤池信息准则,默认;BIC:贝叶斯信息准则;t-stat:基于maxlag,从maxlag开始并删除一个滞后直到最后一个滞后长度基于 t-statistic 显著性小于5%为止;None:使用maxlag指定的滞后)
- store:True False,默认。
- regresults:True 完整的回归结果将返回。False,默认。
返回值意义为:
- adf:Test statistic,T检验,假设检验值。
- pvalue:假设检验结果。
- usedlag:使用的滞后阶数。
- nobs:用于ADF回归和计算临界值用到的观测值数目。
- icbest:如果autolag不是None的话,返回最大的信息准则值。
- resstore:将结果合并为一个dummy。
adf,p_value,usedlag,nobs,critical_value,icbest=adfuller(data)
print("ADF:",adf)
print("pvalue:",p_value) #由pvalue知数据不平稳,一般来说p<0.05认为序列平稳
#输出
ADF: -0.10143549087345222
pvalue: 0.9492953652092122
5 白噪声
白噪声序列,是指白噪声过程的样本实称,简称白噪声。白噪声是在较宽的频率范围内,各等带宽的频带所含的噪声能量相等的噪声,是一种功率频谱密度为常数的随机信号或随机过程,也就是说,此信号在各个频段上的功率是一样的。
{ e 0 , e 1 , … , e t , … } \left\{e_{0}, e_{1}, \ldots, e_{t}, \ldots\right\} {e0,e1,…,et,…} 是白噪声的三个条件:
- E ( e t ) = 0 E\left(e_{t}\right)=0 E(et)=0
- Var ( e t ) = σ 2 \operatorname{Var}\left(e_{t}\right)=\sigma^{2} Var(et)=σ2
- 当 k ≠ 0 k \neq 0 k=0 时, Cov ( e t , e t + k ) = 0 \operatorname{Cov}\left(e_{t}, e_{t+k}\right)=0 Cov(et,et+k)=0
按照上述定义, 白噪声是一种特殊的弱平稳过程, 通常时间序列分析到白噪声这一层就没什么好分析的了,因为在时间上,数据没有什么关联性了。
根据白噪声的定义,我们可以根据ACF来检验是否是白噪声
二、时间序列的分析
1 时间序列的成分分解
时间序列包含很多特征中包含诸多成分,基本可以分解为以下三种:
- 趋势:指时间序列在较长一段时间内呈现出来的持续向上或者持续向下的变动;
- 季节性:指时间序列在一年内重复出现的周期性波动,如气候条件、生产条件、节假日等;
- 残差:也称为不规则波动,指除去趋势、季节性、周期性外的随机波动。不规则波动通常总是夹杂在时间序列中,致使时间序列产生一种波浪形或震荡式的变动。只含有随机波动的序列也称为平稳序列。
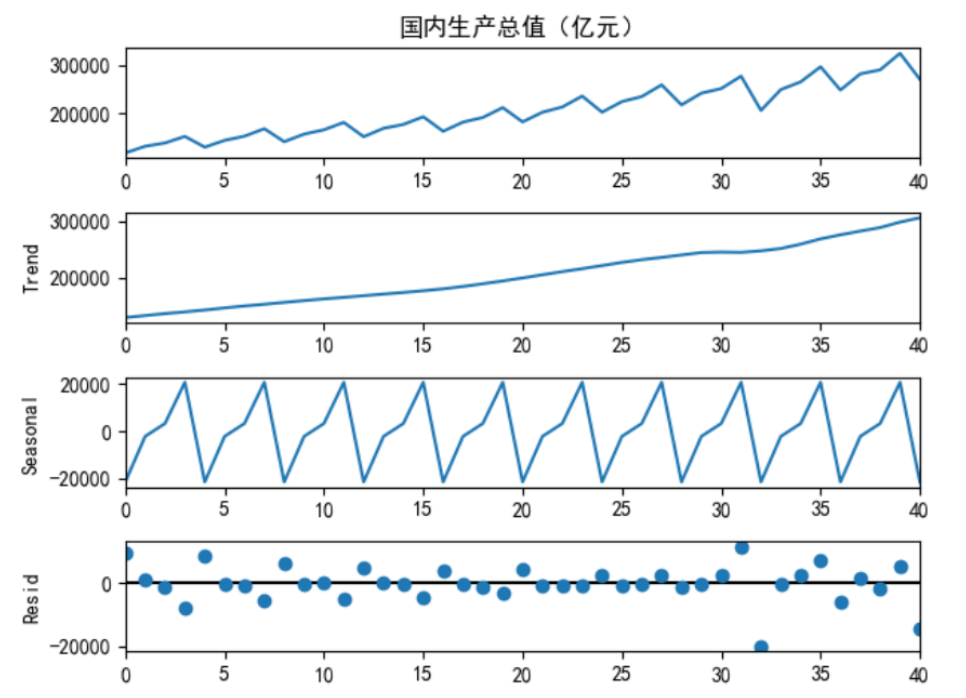
可以有做加分分解和乘法分解:
2 将序列转化为平稳序列
将非平稳时间序列转化为平稳时间序列原因:很多模型回归方案在非平稳信号下是无效的
序列平稳化一般操作流程:
- 趋势消除 Remove trend
- 异方差的消除 Remove heteroscedasticity
- 自相关性消除 Remove autocorrelation with differencing
- 去周期性 Remove seasonality
重复上述步骤,直到平稳,常用方法为:k阶差分。
def toStationary(data,threshold):
p=0
while(True):
data=np.diff(data) #一阶差分
print(len(data))
if p>5:
break
p=p+1
result=adfuller(data)
if result[1]<threshold: #如果p_value小于阈值
break
return data,p_value
data=df["国内生产总值(亿元)"]
sta_data,p_val=toStationary(data,0.05)
print(p_val)
plt.plot(data,label="原始数据")
plt.plot(sta_data,label="平稳后的数据")
plt.legend()
三 时间序列的建模
1 自回归模型(AR)
自回归模型(Autoregressive Model)是用自身做回归变量的过程,即利用前期若干时刻的随机变量的线性组合来描述以后某时刻随机变量的线性回归模型,它是时间序列中的一种常见形式。
1)定义
p阶自回归模型:
X
t
=
c
+
∑
i
=
1
p
φ
i
X
t
−
i
+
ε
t
X_{t}=c+\sum_{i=1}^{p} \varphi_{i} X_{t-i}+\varepsilon_{t}
Xt=c+i=1∑pφiXt−i+εt
- 其中: c 是常数项; ε t \varepsilon_{t} εt 被假设为平均数等于 0 , 标准差等于 σ \sigma σ 的随机误差值; σ \sigma σ 被假设为对于任何的都不变。
- 文字叙述为: X的期望值等于一个或数个落后期的线性组合, 加常数项, 加随机误差。
2)优点与限制
- 自回归方法的优点是所需资料不多, 可用自身变数数列来进行预测。但是这种方法受到一定的限制:
必须具有自相关, 自回归系数 ( φ i ) \left(\varphi_{i}\right) (φi) 是关键。如果自相关系数 ( R ) (R) (R) 小于 0.5 0.5 0.5, 则不宜采用, 否则预测结果极不准确。 - 自回归只能适用于预测与自身前期相关的经济现象, 即受自身历史因素影响较大的经济现象, 如矿的开采量, 各种自然资源 产量等; 对于受社会因素影响较大的经济现象, 不宜采用自回归, 而应改采可纳入其他变数的向量自回归模型。
2 滑动平均模型(MA)
滑动平均模型(Moving Average model),是用白噪声的有限线性组合来描述q步相关的平稳序列。
模型原理:找出过去几期的白噪声影响了当前值,找出过去q期冲击效应对当前值的影响
1)定义
设
{
ε
t
}
\left\{\varepsilon_{t}\right\}
{εt} 是
W
N
(
0
,
σ
2
)
\mathrm{WN}\left(0, \sigma^{2}\right)
WN(0,σ2)(服从均值为0,方差为
σ
2
\sigma^2
σ2的白噪声, 如果实数
b
1
,
b
2
,
⋯
,
b
q
(
b
q
≠
0
)
b_{1}, b_{2}, \cdots, b_{q}\left(b_{q} \neq 0\right)
b1,b2,⋯,bq(bq=0) 使得
B
(
z
)
=
1
+
∑
j
=
1
q
b
j
z
j
≠
0
,
∣
z
∣
<
1
,
(
1
)
X
t
=
ε
t
+
∑
j
=
1
q
b
j
ε
t
−
j
,
t
∈
Z
(
2
)
\begin{gathered} B(z)=1+\sum_{j=1}^{q} b_{j} z^{j} \neq 0, \quad|z|<1,\quad (1) \\ X_{t}=\varepsilon_{t}+\sum_{j=1}^{q} b_{j} \varepsilon_{t-j}, \quad t \in \mathbb{Z}\qquad (2) \end{gathered}
B(z)=1+j=1∑qbjzj=0,∣z∣<1,(1)Xt=εt+j=1∑qbjεt−j,t∈Z(2)就称是
q
q
q 阶滑动平均模型, 简称
MA
(
q
)
\operatorname{MA}(q)
MA(q) 模型。由式(1)决定的平稳序列
{
X
t
}
\left\{X_{t}\right\}
{Xt} 是滑动平均序列, 简称
MA
(
q
)
\operatorname{MA}(q)
MA(q) 序列。如果进一步要求多项式
B
(
z
)
B(z)
B(z) 在单位圆上没有零点, 即
B
(
z
)
≠
0
B(z) \neq 0
B(z)=0 当
∣
z
∣
≤
1
|z| \leq 1
∣z∣≤1, 就称式(1)为可逆的
MA
(
q
)
\operatorname{MA}(q)
MA(q) 模型, 相应的平稳序列是可逆的
MA
(
q
)
\operatorname{MA}(q)
MA(q) 序列.
2)q步相关序列
设零均值平稳序列
{
X
t
}
\left\{X_{t}\right\}
{Xt} 有自协方差函数
{
γ
k
}
\left\{\gamma_{k}\right\}
{γk}, 则
{
X
t
}
\left\{X_{t}\right\}
{Xt} 是
MA
(
q
)
\operatorname{MA}(q)
MA(q) 序列的充分必要条件是
γ
q
≠
0
,
γ
k
=
0
,
∣
k
∣
>
q
\gamma_{q} \neq 0, \quad \gamma_{k}=0, \quad|k|>q
γq=0,γk=0,∣k∣>q
并且称这个序列为q步相关的
3 自回归滑动平均模型(ARMA)
自回归滑动平均模型(英语:Autoregressive moving average model,简称:ARMA模型),是研究时间序列时间序列的重要方法,由自回归模型与滑动平均模型为基础“混合”构成。ARMA(p,q)模型:
X
t
=
ϕ
1
X
t
−
1
+
ϕ
2
X
t
−
2
+
⋯
+
ϕ
p
X
t
−
p
+
ϵ
t
+
θ
1
ϵ
t
−
1
+
θ
2
ϵ
t
−
2
+
⋯
+
θ
q
ϵ
q
,
t
=
0
,
±
1
,
±
2
,
⋯
,
X_{t}=\phi_{1} X_{t-1}+\phi_{2} X_{t-2}+\cdots+\phi_{p} X_{t-p} \quad+\epsilon_{t}+\theta_{1} \epsilon_{t-1}+\theta_{2} \epsilon_{t-2}+\cdots+\theta_{q} \epsilon_{q} \quad, \quad t=0, \pm 1, \pm 2, \cdots \text {, }
Xt=ϕ1Xt−1+ϕ2Xt−2+⋯+ϕpXt−p+ϵt+θ1ϵt−1+θ2ϵt−2+⋯+θqϵq,t=0,±1,±2,⋯,
其中
{
ϵ
t
:
t
=
0
,
±
1
,
±
2
,
⋯
}
\left\{\epsilon_{t}: t=0, \pm 1, \pm 2, \cdots\right\}
{ϵt:t=0,±1,±2,⋯} 为白噪声, 且
Var
(
ϵ
t
)
=
σ
2
\operatorname{Var}\left(\epsilon_{t}\right)=\sigma^{2}
Var(ϵt)=σ2 。
4 ARIMA
ARIMA (AutoRegressive Integrated Moving Average) 模型是一类广泛用于时间序列分析和预测的统计模型。它通过结合自回归 (AR) 和移动平均 (MA) 模型,并对时间序列进行差分处理,来捕捉数据的趋势和季节性变化。ARIMA 模型通常表示为 ARIMA(p, d, q),其中:
- p 是自回归部分的阶数 (number of lag observations included in the model)。
- d 是差分次数 (number of times the raw observations are differenced)。
- q 是移动平均部分的阶数 (size of the moving average window)。
下面详细介绍 ARIMA 模型拟合数据的过程:
4.1 数据预处理
在开始拟合 ARIMA 模型之前,首先需要对数据进行预处理,这通常包括以下几个步骤:
- 检查和处理缺失值:如果数据中存在缺失值,需要进行填补或删除。
- 检测和处理异常值:异常值可能会影响模型的拟合效果,需要进行检测并处理。
- 数据平稳性检测:ARIMA 模型要求数据是平稳的,即均值和方差恒定不变。可以通过绘制时间序列图、计算自相关函数 (ACF) 和偏自相关函数 (PACF)、以及进行单位根检验 (如 ADF 检验) 来检测数据的平稳性。如果数据不平稳,则需要进行差分处理。
4.2 差分处理
差分处理的目的是将非平稳时间序列转换为平稳时间序列。差分操作是通过减去前一个时间点的值来消除趋势和季节性。对于 ARIMA(p, d, q) 模型中的 d 次差分处理,具体操作如下:
- 一阶差分:$ y_t’ = y_t - y_{t-1} $
- 二阶差分:$ y_t’’ = y_t’ - y_{t-1}’ = (y_t - y_{t-1}) - (y_{t-1} - y_{t-2}) $
继续进行 d 次差分,直到时间序列平稳为止。
4.3 模型识别与选择
在数据平稳之后,需要确定模型的参数 p 和 q。通常通过以下步骤进行:
- 自相关函数 (ACF) 和偏自相关函数 (PACF) 图:绘制 ACF 和 PACF 图,观察其截尾和拖尾特性,初步确定 p 和 q 的值。
- 信息准则:使用 AIC (Akaike 信息准则) 或 BIC (贝叶斯信息准则) 等信息准则,选择最优的 p 和 q 组合。
4.4 模型估计
确定了 ARIMA 模型的参数 p、d、q 之后,使用最大似然估计 (MLE) 或最小二乘法 (LS) 对模型参数进行估计。
4.5 模型诊断
对拟合的 ARIMA 模型进行诊断,检查模型的残差是否满足白噪声特性。主要步骤包括:
- 残差图:绘制残差图,检查残差的随机性。
- ACF 和 PACF 图:绘制残差的 ACF 和 PACF 图,检查是否存在显著自相关。
4.6 模型预测
在模型通过诊断之后,可以使用 ARIMA 模型对未来的时间点进行预测。预测结果通常包括点预测和区间预测。
5 ARIMA 示例
下面是一个使用 Python 语言拟合 ARIMA 模型的简单示例:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.stattools import adfuller
# 生成示例数据
np.random.seed(0)
data = np.cumsum(np.random.randn(100)) + 50
df = pd.DataFrame(data, columns=['Value'])
# 绘制时间序列图
df.plot()
plt.title('Time Series Data')
plt.show()
# 检测平稳性
result = adfuller(df['Value'])
print('ADF Statistic:', result[0])
print('p-value:', result[1])
# 差分处理
df['Value_diff'] = df['Value'].diff().dropna()
# 绘制差分后的时间序列图
df['Value_diff'].plot()
plt.title('Differenced Time Series Data')
plt.show()
# 绘制 ACF 和 PACF 图
plot_acf(df['Value_diff'].dropna())
plot_pacf(df['Value_diff'].dropna())
plt.show()
# 拟合 ARIMA 模型
model = ARIMA(df['Value'], order=(1, 1, 1))
model_fit = model.fit()
# 模型诊断
print(model_fit.summary())
# 预测
forecast = model_fit.forecast(steps=10)
print('Forecast:', forecast)
# 绘制预测结果
plt.plot(df['Value'], label='Actual')
plt.plot(np.arange(100, 110), forecast, label='Forecast')
plt.title('ARIMA Forecast')
plt.legend()
plt.show()
以上代码演示了如何使用 Python 进行 ARIMA 模型的拟合、诊断和预测。通过对时间序列数据进行差分处理、模型识别与选择、参数估计、模型诊断和预测,可以有效地捕捉数据的趋势和季节性变化,并进行未来时间点的预测。
四 最优模型的选择
选择最优模型的指导思想是从两个方面去考察:
- 一个是似然函数最大化
- 另一个是模型中的未知参数个数最小化。
似然函数值越大说明模型拟合的效果越好,但是我们不能单纯地以拟合精度来衡量模型的优劣,这样回导致模型中未知参数越来越多,模型变得越来越复杂,会造成过拟合。所以一个好的模型应该是拟合精度和未知参数个数的综合最优化配置。
1 AIC准则
AIC准则是由日本统计学家Akaike与1973年提出的,全称是最小化信息量准则(Akaike Information Criterion)。它是拟合精度和参数个数的加权函数:
A
I
C
=
2
⋅
n
−
2
ln
(
L
)
AIC=2\cdot n-2\ln(L)
AIC=2⋅n−2ln(L)
2 BIC 准则
AIC为模型选择提供了有效的规则,但也有不足之处。当样本容量很大时,在AIC准则中拟合误差提供的信息就要受到样本容量的放大,而参数个数的惩罚因子却和样本容量没关系(一直是2),因此当样本容量很大时,使用AIC准则选择的模型不收敛与真实模型,它通常比真实模型所含的未知参数个数要多。
BIC(Bayesian InformationCriterion)贝叶斯信息准则是Schwartz在1978年根据Bayes理论提出的判别准则,称为SBC准则(也称BIC),弥补了AIC的不足。
BIC的定义为:
B
I
C
=
k
ln
(
n
)
−
2
ln
(
L
)
B I C=k \ln (n)-2 \ln (L)
BIC=kln(n)−2ln(L)
其中,
k
k
k 为模型参数个数,
n
n
n 为样本数量,
L
L
L 为似然函数。
k
ln
(
n
)
k \ln (n)
kln(n) 惩罚项在维数过大且训练样本数据相对较少的情况下,可以有效避 免出现维度灾难现象。
五、参考资料
- 何书元. 应用时间序列分析[M]. 北京: 北京大学出版社, 2003. ISBN 7-301-06347-4/O·0569.















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









