







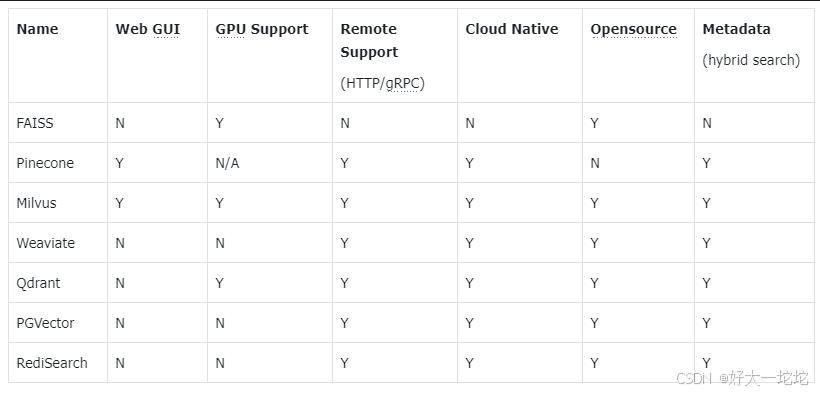
- FAISS: Meta 开源的向量检索引擎 https://github.com/facebookresearch/faiss
- Pinecone: 商用向量数据库,只有云服务 https://www.pinecone.io/
- Milvus: 开源向量数据库,同时有云服务 https://milvus.io/
- Weaviate: 开源向量数据库,同时有云服务 https://weaviate.io/
- Qdrant: 开源向量数据库,同时有云服务 https://qdrant.tech/
- PGVector: Postgres 的开源向量检索引擎 https://github.com/pgvector/pgvector
- RediSearch: Redis 的开源向量检索引擎 https://github.com/RediSearch/RediSearch
- ElasticSearch 也支持向量检索 https://www.elastic.co/enterprise-search/vector-search
粗体推荐使用,性能较好

















 1602
1602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









