







1.LK光流

2.1 光流:追踪原图像某个点在其他图像中的运动。
(1)按此文的分类,光流法可分为哪几类?
Forward Additive , Forwards Compositional, Inverse Additive , Inverse Compositional
(2)在 compositional 中,为什么有时候需要做原始图像的 wrap?该 wrap 有何物理意义?
略
(3)forward 和 inverse 有何差别?
正向法在第二个图像I2处使用差分法求梯度,逆向法直接在第一个图像I1处的梯度来替代。正向法和逆向法的目标函数不一样。
2.2
(1) 光流法中保留了特征点,值计算关键点,在第一幅图中定义每个关键点的像素为
I
1
(
x
i
,
y
i
)
I_1(x_i, y_i)
I1(xi,yi), 相机通过涌动后,在第二幅图中利用灰度不变假设 找出与第一幅图灰度值相同的对应点
I
2
(
x
i
+
Δ
x
,
y
i
+
Δ
y
)
I_2(x_i + \Delta x, y_i + \Delta y)
I2(xi+Δx,yi+Δy)
e
i
=
min
Δ
x
,
Δ
y
e_i = \min\limits_{\Delta x, \Delta y}
ei=Δx,Δymin
∥
I
1
(
x
i
,
y
i
)
−
I
2
(
x
i
+
Δ
x
,
y
i
+
Δ
y
)
∥
2
2
\lVert I_1(x_i, y_i) - I_2(x_i + \Delta x, y_i + \Delta y)\rVert^2_2
∥I1(xi,yi)−I2(xi+Δx,yi+Δy)∥22
(2)
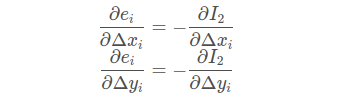
梯度是一个向量,也就是方向导数,图像梯度衡量了图像灰度的变化率,图像就是函数,可以把图像看成是二维的离散函数,图像梯度就是这个二维离散函数求到导,对于数字图像来说就相当与二维离散函数求梯度,使用差分来近似求导。

实现代码:
#include <opencv2/opencv.hpp>
#include <string>
#include <chrono>
#include <Eigen/Core>
#include <Eigen/Dense>
using namespace std;
using namespace cv;
string file_1 = "../LK1.png";
string file_2 = "../LK2.png";
class OpticalFlowTracker {
public:
OpticalFlowTracker(const Mat &imag1_, const Mat &imag2_, const vector<KeyPoint> &kp1_, vector<KeyPoint> &kp2_, vector<bool> &success_, bool inverse_ = true, bool has_initial_=false):
image1(imag1_), image2(imag2_), kp1(kp1_), kp2(kp2_), success(success_), inverse(inverse_), has_initial(has_initial_) {}
void calculateOpticalFlow(const Range &range);
private:
const Mat &image1;
const Mat &image2;
const vector<KeyPoint> &kp1;
vector<KeyPoint> &kp2;
vector<bool> &success;
bool inverse = false;
bool has_initial = false;
};
//获取图像中某一点的像素值
inline float GetPixelValue(const cv::Mat &image, float x, float y) {
if(x < 0) x=0;
if(y < 0) y = 0;
if(x >= image.cols ) x = image.cols - 1;
if(y >= image.rows) y = image.rows - 1;
uchar *data = &image.data[int(y) * image.step + int(x)];
float xx = x - floor(x);
float yy = y - floor(y);
return float((1 - xx ) * (1 - yy) * data[0] + xx * (1 - yy) * data[1] + (1-xx) * yy * data[image.step] + xx * yy * data[image.step + 1]);
}
void opticalFlowSingleLevel(const Mat &image1,
const Mat &image2,
const vector<KeyPoint> &keypoint1s,
vector<KeyPoint> &keypoint2_single,
vector<bool> &status_single,
bool inverse=false,
bool has_initial=false);
void OpticalFlowMultiLevel(const Mat &image1,
const Mat &image2,
const vector<KeyPoint> &keypoint1s,
vector<KeyPoint> &keypoint2_multi,
vector<bool> &status_multi,
bool inverse=false );
int main(int argc, char** argv)
{
Mat image1 = imread(file_1, 0);
Mat image2 = imread(file_2, 0);
Ptr<GFTTDetector> detector = GFTTDetector::create(500, 0.01, 20); //GoodFeatureToTrackDe
vector<KeyPoint> keypoint1s;
detector->detect(image1, keypoint1s);
vector<KeyPoint> keypoint2s;
chrono::steady_clock::time_point t1 ;
chrono::steady_clock::time_point t2;
// OpenCV实现
vector<Point2f> pt1, pt2;
for(auto &kp: keypoint1s)
pt1.push_back(kp.pt);
vector<uchar> status;
vector<float> error;
t1 = chrono::steady_clock::now();
calcOpticalFlowPyrLK(image1, image2, pt1, pt2, status, error);
t2 = chrono::steady_clock::now();
auto time_used = chrono::duration_cast<chrono::duration<double>>(t2 - t1);
cout << "optical flow by opencv:" << time_used.count() << endl;
// 单层光流
vector<KeyPoint> key2_single;
vector<bool> status_single;
t1 = chrono::steady_clock::now();
opticalFlowSingleLevel(image1, image2, keypoint1s, key2_single, status_single);
opticalFlowSingleLevel(image1, image2, keypoint1s, key2_single, status_single,true);
t2 = chrono::steady_clock::now();
time_used = chrono::duration_cast<chrono::duration<double>>(t2 - t1);
cout << "optical flow by single:" << time_used.count() << endl;
//多层光流
vector<KeyPoint> keypoint2_multi;
vector<bool> status_multi;
t1 = chrono::steady_clock::now();
OpticalFlowMultiLevel(image1, image2, keypoint1s, keypoint2_multi, status_multi);
OpticalFlowMultiLevel(image1, image2, keypoint1s, keypoint2_multi, status_multi, true);
t2 = chrono::steady_clock::now();
time_used = chrono::duration_cast<chrono::duration<double>>(t2 - t1);
cout << "optical flow by multi:" << time_used.count() << endl;
Mat image2_CV;
cvtColor(image2, image2_CV, CV_GRAY2BGR); //将原视图转换为灰度图
for(int i = 0; i < pt2.size(); i++) {
if(status[i]) {
circle(image2_CV, pt2[i], 2, Scalar(0,250, 0), 2);
line(image2_CV, pt1[i], pt2[i], Scalar(0, 250, 0));
}
}
Mat image2_single;
cvtColor(image2, image2_single, CV_GRAY2BGR);
for(int i = 0; i < key2_single.size(); i++) {
if(status_single[i]) {
circle(image2_single, key2_single[i].pt, 2, Scalar(0, 250, 0), 2);
line(image2_single, keypoint1s[i].pt, key2_single[i].pt, Scalar(0, 250, 0));
}
}
Mat image2_multi;
cvtColor(image2, image2_multi, CV_GRAY2BGR);
for(int i = 0; i < keypoint2_multi.size(); i++) {
if(status_multi[i]){
circle(image2_multi, keypoint2_multi[i].pt, 2, Scalar(0, 250, 0), 2);
line(image2_multi, keypoint1s[i].pt, keypoint2_multi[i].pt, Scalar(0, 250, 0));
}
}
imshow("原图", image1);
// imshow("opencv flow", image2_CV);
// imshow("flow single", image2_single);
imshow("flow multilevel" , image2_multi);
waitKey(0);
while(char(waitKey(1)) != 'q') {}
return 0;
}
void opticalFlowSingleLevel(const Mat &image1, const Mat &image2, const vector<KeyPoint> &keypoint1s, vector<KeyPoint> &keypoint2_single, vector<bool> &status_single, bool inverse, bool has_initial)
{
keypoint2_single.resize(keypoint1s.size());
status_single.resize(keypoint1s.size());
OpticalFlowTracker tracker(image1, image2, keypoint1s,keypoint2_single, status_single, inverse, has_initial);
parallel_for_(Range(0, keypoint1s.size()), std::bind(&OpticalFlowTracker::calculateOpticalFlow, &tracker, placeholders::_1));
}
void OpticalFlowTracker::calculateOpticalFlow(const Range &range)
{
int half_patch_size = 4;
int iterations = 10;
for(size_t i = range.start; i < range.end; i++) {
auto kp = kp1[i];
double dx = 0 , dy = 0;
if(has_initial) {
dx = kp2[i].pt.x - kp.pt.x;
dy = kp2[i].pt.y - kp.pt.y;
}
double cost = 0, lastCost = 0;
bool succ = true;
//高斯牛顿迭代
Eigen::Matrix2d H = Eigen::Matrix2d::Zero();
Eigen::Vector2d b = Eigen::Vector2d::Zero();
Eigen::Vector2d J;
for(int iter = 0; iter < iterations; iter++) {
if(inverse == false) {
H = Eigen::Matrix2d::Zero();
b = Eigen::Vector2d::Zero();
} else {
b = Eigen::Vector2d::Zero();
}
cost = 0;
//计算cost和J
for(int x = -half_patch_size; x < half_patch_size; x++)
for(int y = -half_patch_size; y < half_patch_size; y++) {
double error = GetPixelValue(image1, kp.pt.x + x, kp.pt.y + y) -
GetPixelValue(image2, kp.pt.x + x + dx, kp.pt.y + y + dy);
if (inverse == false) {
J = -1.0 * Eigen::Vector2d(
0.5 * ( GetPixelValue(image2, kp.pt.x + dx + x + 1, kp.pt.y + dy + y) -
GetPixelValue(image2, kp.pt.x + dx + x - 1, kp.pt.y + dy + y)),
0.5 * (GetPixelValue(image2, kp.pt.x + dx + x, kp.pt.y + dy + y + 1)-
GetPixelValue(image2, kp.pt.x + dx + x, kp.pt.y + dy + y -1))
);
} else if(iter == 0 && inverse = true) {
J = -1.0 * Eigen::Vector2d(
0.5 * (GetPixelValue(image1, kp.pt.x + x + 1, kp.pt.y + y) -
GetPixelValue(image1, kp.pt.x + x - 1, kp.pt.y + y)),
0.5 * (GetPixelValue(image1, kp.pt.x + x, kp.pt.y + y + 1) -
GetPixelValue(image1, kp.pt.x + x, kp.pt.y + y - 1))
);
}
b += -error * J;
cost += error * error;
if(inverse == false || iter == 0) {
H += J * J.transpose();
}
}
Eigen::Vector2d update = H.ldlt().solve(b);
if(std::isnan(update[0])) {
cout << "update is nan" << endl;
succ = false;
break;
}
if(iter > 0 && cost > lastCost) {
break;
}
dx += update[0];
dy += update[1];
lastCost = cost;
succ = true;
if(update.norm() < 1e-2) {
break;
}
}
success[i] = succ;
kp2[i].pt = kp.pt + Point2f(dx,dy);
}
}
void OpticalFlowMultiLevel(const Mat &image1, const Mat &image2, const vector<KeyPoint> &keypoint1s, vector<KeyPoint> &keypoint2_multi, vector<bool> &status_multi, bool inverse)
{
int pyramids = 4;
double pyramid_scale = 0.5;
double scales[] = {1.0, 0.5, 0.25, 0.125};
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
vector<Mat> pyr1, pyr2;
for(int i = 0; i<pyramids; i++) {
if(i == 0)
{
pyr1.push_back(image1);
pyr2.push_back(image2);
} else {
Mat img1_pyr, img2_pyr;
cv::resize(pyr1[i-1], img1_pyr, cv::Size(pyr1[i-1].cols * pyramid_scale, pyr1[i-1].rows * pyramid_scale));
cv::resize(pyr2[i-1], img2_pyr, cv::Size(pyr2[i-1].cols * pyramid_scale, pyr2[i-1].rows * pyramid_scale));
pyr1.push_back(img1_pyr);
pyr2.push_back(img2_pyr);
}
}
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
auto time_used = chrono::duration_cast<chrono::duration<double>>(t2 - t1);
cout << "build pyramid time: " << time_used.count() << endl;
//由粗到精在层上追踪
vector<KeyPoint> kp1_pyr, kp2_pyr;
for(auto &kp:keypoint1s) {
auto kp_top = kp;
kp_top.pt *= scales[pyramids - 1];
kp1_pyr.push_back(kp_top);
kp2_pyr.push_back(kp_top);
}
for(int level = pyramids-1; level >= 0; level--)
{
status_multi.clear();
t1 = chrono::steady_clock::now();
opticalFlowSingleLevel(pyr1[level], pyr2[level], kp1_pyr, kp2_pyr, status_multi, inverse, true);
t2 = chrono::steady_clock::now();
auto time_used = chrono::duration_cast<chrono::duration<double>>(t2 - t1);
cout << "track pyr"<< level << "cost time:" << time_used.count() << endl;
if(level > 0){
for(auto &kp: kp1_pyr)
kp.pt /= pyramid_scale;
for(auto &kp: kp2_pyr)
kp.pt /= pyramid_scale;
}
}
for(auto &kp:kp2_pyr)
keypoint2_multi.push_back(kp);
}
CMakeLists.txt:
cmake_minimum_required(VERSION 2.8)
project(LK)
set(CMAKE_BUILD_TYPE "Debug")
add_definitions("-DENABLE_SSE")
set(CMAKE_CXX_FLAGS "-std=c++11 ${SSE_FLAGS} -g -O3 -march=native")
find_package(OpenCV 3 REQUIRED)
find_package(Pangolin REQUIRED)
include_directories(
${OpenCV_INCLUDE_DIRS}
"/usr/include/eigen3/"
${Pangolin_INCLUDE_DIRS}
)
add_executable(optical_flow optical_flow.cpp)
target_link_libraries(optical_flow ${OpenCV_LIBS})
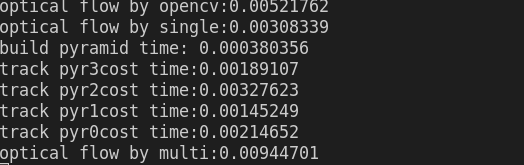
inverse 默认为false时的结果:正向

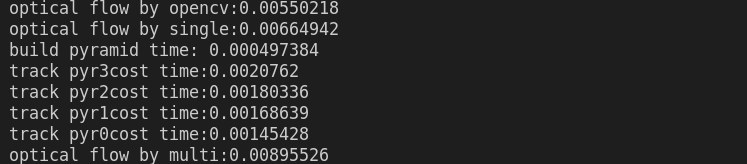


inverse = true的结果:反向

2.4 (1)所谓 coarse-to-fine 是指怎样的过程?
我们把光流写成优化问题,就必须假设优化的初始值靠近最优值,才能在一定程度上保障算法的收敛。如果相机运动过快,两张图像差异明显,那么单层图像光流容易达到一个局部极小值。这种情况需要引入金字塔来改善,金字塔是指对同一个图像进行缩放,得到不同分辨率下的图像,以原始图像作为金字塔的底层,每往上一层,就对下层图像进行一定倍率的缩放,得到一个金字塔,然后,在计算光流时,先从顶层的图像开始算,然后把上一层的追踪结果,作为下一层光流的初始值。由于上层相对粗糙,这就是所谓的由粗到精的过程。
(2)光流法中的金字塔用途和特征点法中的金字塔有何差别?
光流中的由粗到精是为了解决当原始图像的像素运动较大时,很容易由于图像非凸性导致优化困在极小值中。通过金字塔,在顶层的图像看来,像素运动由于图像的缩放而运动了几个像素(小运动), 这时优化的结果明显好于直接在原始图上的优化。
特征点法的金字塔是为了解决特征点的尺度不变性,由于提取的FAST角点固定取半径为3的圆,存在尺度问题:远处看像是角点的地方,接近后可能就不是角点了。针对尺度问题构建了金字塔,在金字塔的每一层上检测角点来实现。
2.5 光流法的多线程并行化
头文件加入 #include #include
在单层光流的特征点前面添加 如下代码:
vector<int> indexes;
for(int i = 0; i < kp1.size(); ++i)
indexes.push_back(i);
std::mutex m;
std::lock_guard<std::mutex> guard(m);
for_each(executable::par_unseq, indexes.begin(), indexes.end(), [&](auto &i){单层光流代码});
2.6 (1)我们优化两个图像块的灰度之差真的合理吗?哪些时候不够合理?你有解决办法吗?
灰度不变假设是一个很强的假设,实际中可能不成立,事实上,由于物体的材质不同,像素会出现高光和阴影部分,有时会自动调整曝光参数,使得图像整体变亮或变暗。这时灰度不变假设是不成立的,因此光流的结果不一定可靠。
(2)图像块大小是否有明显差异?取 16x16 和 8x8 的图像块会让结果发生变化吗?
8x8的结果:

16x16的结果:

在反向光流的作用下 ,取8x8 和16x16的图像块时,多层光流的效果差不多,单从光流有明显差异。
8x8的结果:

16x16的结果:

在正向光流的作用下 ,取8x8 和16x16的图像块时,16x16的图像块中单层和多层光流的效果都要好与8x8的。
总结:在正向光流中,增大图像块可以使得光流的追踪效果更好,在反向光流中增大图像块,单层多层光流的追踪效果差不多。
(3)金字塔层数对结果有怎样的影响?缩放倍率呢?
在正向光流中,8x8图像块中:通过减少或增加层数,光流追踪效果都会变差,4层效果最好。(使用滑动条更方便)
两层:

四层:

八层:

在正向光流,选8x8的图像块中,缩放一半达到做好的效果,
缩小别率为1/2时:

缩小倍率为0.25时:

缩放别率为0.75时:

2,直接法



3.1 单层直接法
(1)该问题中的误差项是什么?
在光流法中,我们是只计算了关键点(角点), 不计算描述子,使用了光流法跟踪特征点的运动。光流法其实实现的是特征点的描述子和匹配的过程,但光流法本身的计算时间要小与描述子与匹配的时间,相机的估计仍然需要使用对极几何,PnP,ICP算法,而直接法我们不需要点与点的对应关系,通过最小化光度误差来计算对应关系和相机位姿,直接根据像素的亮度信息估计相机的运动,可以完全不用计算关键点和描述子,只要场景中存在明暗变化即可。
思路:根据当前相机的位姿值寻找p2的位置,若相机位姿不够好,p2的外观和p1会有差别,为了减少这个差别,我们需要优化相机的位姿,来寻找与p1更相似的p2,使用的是P的两个像素的亮度误差,即光度误差,仍使用了灰度不变假设(一个空间点在各个视角下的成像的灰度是不变的),直接法优化的变量是相机的位姿T,不是光流优化的是各个特征点的运动。
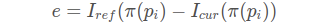
(2)误差相对于自变量的雅可比维度是多少?如何求解?
1x6的向量
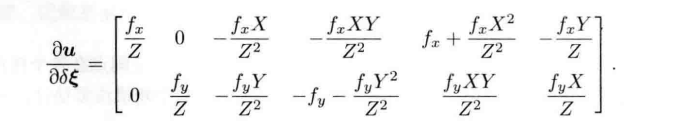

(3)窗口可以取多大?是否可以取单个点?
窗口的范围选取跟窗口内像素的运动有关系,如果窗口内的运动方向不一致造成光度误差不再下降反增的状态,所以特征点运动的朝向快达到一致的时候,说明是窗口选取的最大值。
可以取单个点,和它相似的点太多,精确性肯定会下降。
单层直接法追踪00005.png的结果:

3.2 多层直接法
追踪000001.png的结果:

追踪000005.png的结果:

000001.png追踪后的结果:
000005.png追踪后的结果:

3.3并行化
单层直接法的特征点for()循环处并行化
vector<int> indexes;
for(int i = 0; i < kp1.size(); ++i)
indexes.push_back(i);
std::mutex m;
std::lock_guard<std::mutex> guard(m);
for_each(executable::par_unseq, indexes.begin(), indexes.end(), [&](auto &i){单层直接代码});
3.4 (1)直接法是否可以类似光流,提出 inverse, compositional 的概念?它们有意义吗?
可以提出inverse和compositional的概念,但是没有意义。直接法是两张图整体的光度误差,而不是估计图像中像素的运动。
(2)请思考上面算法哪些地方可以缓存或加速?
循环处理每个特征点的时候,可应并行化处理进行加速。选择合适的窗口大小和金字塔层数,倍率都可以加速算法的效率;
(3)在上述过程中,我们实际假设了哪两个 patch 不变?
灰度不变,同一个窗口内的像素点的深度不变;
(4)请总结直接法相对于特征点法的异同与优缺点。
特征点法在计算关键点和描述子,匹配上耗时,匹配完成后,相机的位姿态估计需要通过对极几何或PnP,ICP来实现,不能直接估计。特征点不是对任意像素点都能进行匹配的,需要选取角点(有明显亮度变化的点), 由于只能选角点,所以只能构建稀疏的地图,特征点和直接法的点对的匹配方式不同,特征点使用描述子距离表明两个特征点的相似程度,而直接法根据光度误差来进行匹配。
直接法的优缺点:
优点:
- 可以省去计算描述子,特征点的时间;
- 只要有像素梯度即可,不需要特征点。直接法对随即的选点都能正常工作。
- 可以构建半稠密乃至稠密的地图,这是特征点法做不到的。
缺点:
- 非凸性:直接法完全依赖梯度搜索,降低目标函数来计算相机位姿,目标函数中需要取像素点的灰度值,而图像是强烈非凸的函数,这使得优化算法很容易陷入到极小,只有运动很小时直接法才能成功。针对这个问题,金字塔的引入一定程度上可以减小非凸性的影响。
- 单个像素没有区分度:和它相似的太多,我们要么通过计算图像快(窗口),要么计算复杂度的相关性来确定对应的点对。每个像素对相机的改变不一致,只能少数服从多数,以数量代替质量。所以,直接法在选点较少时的表现下降明显,建议500个点以上。
- 灰度值不变是很强的假设:如果相机是自动曝光的,当它调整曝光参数时,会使得图像整体变量或变暗。光照变化时也会是这样。特征点对光照具有一定的容忍性,而直接法由于计算灰度间的差异,整体灰度变化会影响灰度不变假设,使算法失败。针对这一点,使用的直接法同时会估计相机的曝光度。














 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









