









上次谈到相关性分析,主要讲了pearson和spearman相关性分析:
 https://blog.csdn.net/weixin_46500027/article/details/124030269?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_46500027/article/details/124030269?spm=1001.2014.3001.5501
下面我们来用上次的数据,绘制一张好看的散点图:
数据格式准备如下,并将数据储存成csv格式:
下面开始绘制散点图:
读取文件:
setwd("D:\\")
dir()
data <- read.csv("PCC(1).csv",header = T,sep = ",")
head(data)
然后建一个线性模型:
model <- lm(data$GeneB~data$GeneA,data = data)
summary(model)
> summary(model)
Call:
lm(formula = data$GeneB ~ data$GeneA, data = data)
Residuals:
Min 1Q Median 3Q Max
-0.042368 -0.010605 -0.004979 0.003309 0.280395
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.023862 0.001442 16.548 < 2e-16 ***
data$GeneA 0.049984 0.006120 8.167 4.06e-15 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.02273 on 405 degrees of freedom
Multiple R-squared: 0.1414, Adjusted R-squared: 0.1393
F-statistic: 66.7 on 1 and 405 DF, p-value: 4.057e-15下面就是画图:
library(ggplot2)
a <- ggplot(data = data,aes(x = data$GeneA,y = data$GeneB))+
geom_point(shape = 19,colour = "dodgerblue3")+
labs(y = "GeneA",x = "GeneB")
a将线性模型传入图中:
b <- a+stat_smooth(method = lm,se = F,colour = "red")
b
g <- b+theme(plot.title = element_text(hjust = 0.5,size = 15),
axis.title.y.left = element_text(size = 13,colour = "black"),
axis.title.x.bottom = element_text(size = 13,colour = "black"))
g
h <- g+theme(axis.text.x.bottom = element_text(size = 12,colour = "black"))
h
i <- h +theme(axis.text.y.left = element_text(size = 12,colour = "black",
vjust = 0.5,hjust = 0.5,
angle = 90))
i最终得到下面图片:
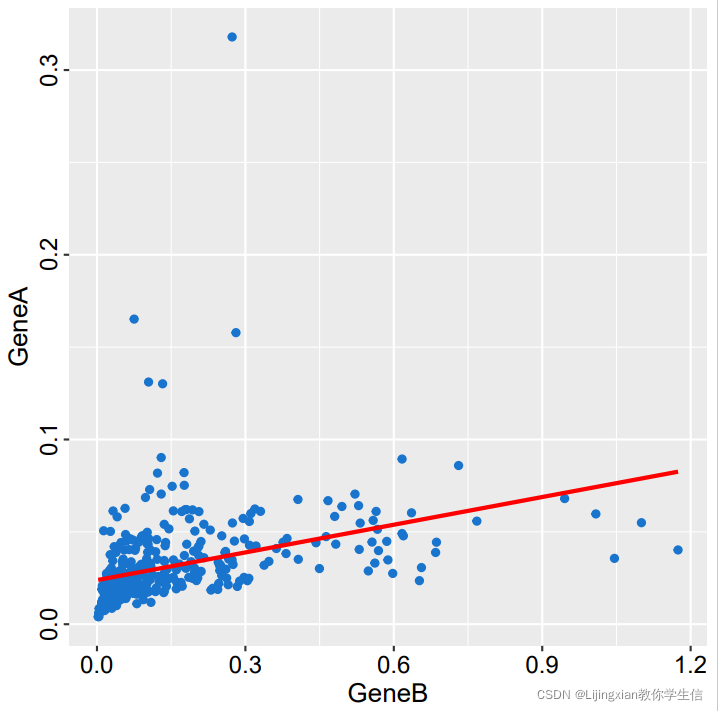
当然也可以去掉网格线和背景:
j <- i+theme_classic()
j 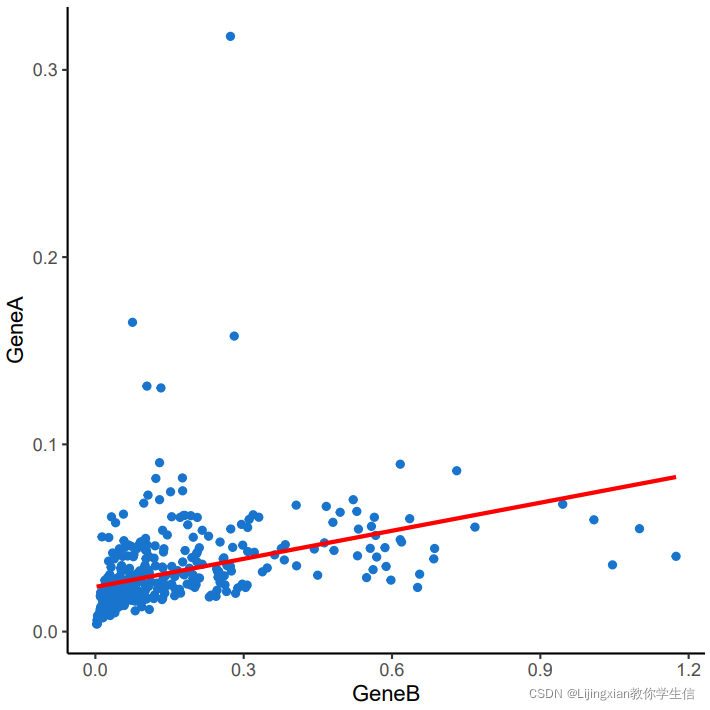
颜色搭配可以参考之前的文章:
那么如何选择pearson和spearman呢?
简单说,服从正态分布的连续性数据用pearson相关系数最恰当,当然也可以用spearman。
但是如果数据不符合正态分布,就用spearman相关系数,不能用pearson相关系数。
两个定序测量数据之间也用spearman相关系数,不能用pearson相关系数。
像我们上次的数据,我们首先来检查一下他们的正态性:
setwd("D:\\")
dir()
data <- read.csv("PCC.csv",header = T,sep = ",")
head(data)
shapiro.test(data$GeneA)
shapiro.test(data$GeneB)
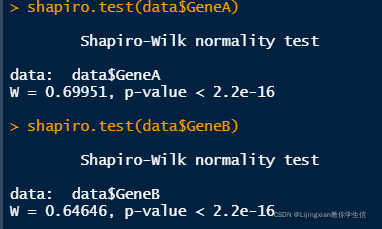
可以看到,这两个数据都不符合正态分布,所以使用pearson相关分析是不太合适的,因此我们用spearman相关分析。
建议:既然spearman相关性分析任何条件下都适用,那么我们主要还是用spearman相关性分析比较好。
我们再看一看这两种方法计算的结果:
a <- cor.test(data$GeneA,data$GeneB,method = "spearman")
a
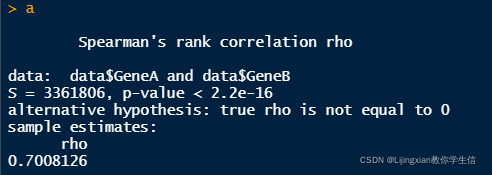
a <- cor.test(data$GeneA,data$GeneB,method = "pearson")
a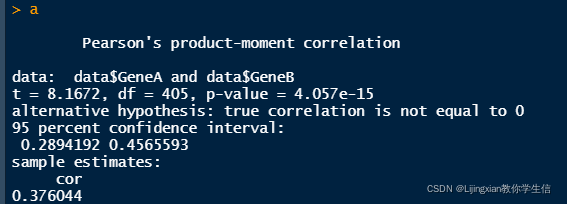
可以看到,相差很大,所以不符合正态分布的还是不要用pearson相关分析。



















 2754
2754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











