






前言
self-attention 下
一、Self-attention(下)
Self-attention中的bi的计算其实是同时进行的,将相应的向量,拼成矩阵,通过矩阵计算。
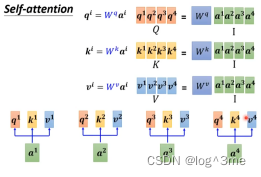
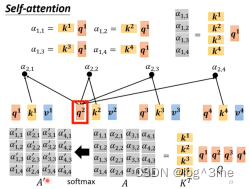
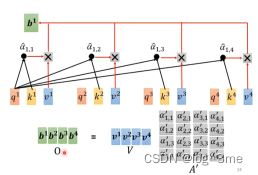
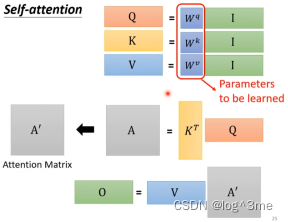
I是输入,是一串向量。输出是O,self-attention里面唯一需要学的参数只有Wq、Wk、Wv。
二、Multi-head self-attention
有的时候,比如翻译、语音辨识等,多head的情况会比较好。而用多少个head是需要调的参数。为什么需要多个head,因为在self-attention里面是用q找相关的k,相关这件事有很多不同的相关,可能需要多个q,不同q负责不同种类的相关。
以两个head为例,qi乘上另外两个矩阵得到qi1和qi2.同理q有两个,那么k也要有两个,v也要有两个。qi1计算相关性的时候,只对ki1和kj1计算不管ki2和kj2,同理v。qi2也只对ki2和kj2、vi2、vj2。
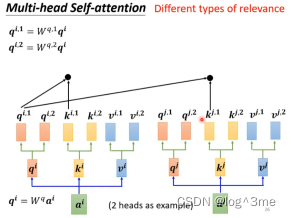
得到bi1和bi2后,在乘上一个矩阵得到bi。传到下一层去。

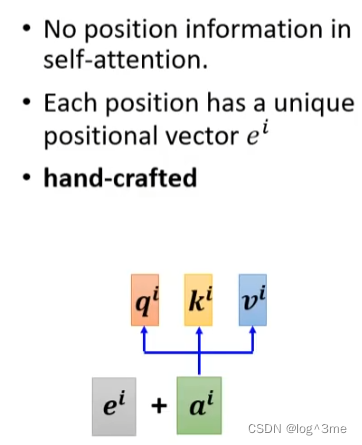
目前还有一个缺陷,就是没有位置信息。对self-attention而言,所有运算都是同时进行的,q1~q4的操作是没有区别的。
如何设置位置信息:设置一个positional vector ei。将ei加到ai上,就知道现在出现的位置在i这个位置。
总结
学习视频地址:https://www.bilibili.com/video/BV13Z4y1P7D7/?p=11&vd_source=3a369b537e1d34ff9ba8f8ab23afedec















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









