






该论文是在Cross View Transformer的基础上引入LUT(位置查找表)而改进的,主要是现在轻量级显卡上部署的bev试图转换并进行检测达到实时分割结果。
论文地址:https://arxiv.org/pdf/2206.04584.pdf
一、摘要:
从环视摄像头中学习鸟瞰(BEV)表示对于自动驾驶来说非常重要。在这项工作中,我们提出了一种几何引导的核T转换器(GKT),一种新的2D-to-BEV表示学习机制。GKT利用几何先验引导变压器聚焦于判别区域,展开核特征生成BEV表示。为了快速推断,我们进一步引入了查找表(LUT)索引方法,以摆脱相机在运行时的校准参数。GKT可以在3090 GPU上以72.3 FPS运行,在2080ti GPU上以45.6 FPS运行,并且对摄像机偏差和预定义的BEV高度具有鲁棒性。
二、背景:
将传统环视图转化至BEV视角下并非单纯的视角变换,而是特征的变换,只要保留关键特征,因此只要将特征映射至BEV下即可。以往的转换方式有两种:1、基于内参外参的转换,缺点是容易偏离且复杂耗时;2、基于深度学习端到端,但是解释性差,效率不匹配解释。因此如果将这两种方法结合起来,就可以有一个高的效率和一个好的解释性。
本文提出了一种几何引导的核Transformer(GKT),这是一种新的2D到BEV表示学习机制。GKT利用几何先验来引导Transformer聚焦于局部区域,并展开内核特征以生成BEV表示。为了快速推断,进一步引入了查找表(LUT)索引方法,以在运行时消除相机的校准参数。
二、以往论文方法:

第一种是几何转换,主要基于内参外参,来确定二维位置与BEV网格之间的对应关系(一对一或一对多)。利用对应关系,将二维特征投影到三维空间,形成BEV表示。笔者认为这是一切的基础,属于理论保证。第二种方式便是端到端,考虑了图像与BEV之间的完全相关性,多视图图像特征被平化,每个BEV网格与所有图像像素交互。在2D-to-BEV投影中,全局变换不依赖于几何先验。因此,它对相机偏差不敏感。二者均有优缺点。
三、论文方法:
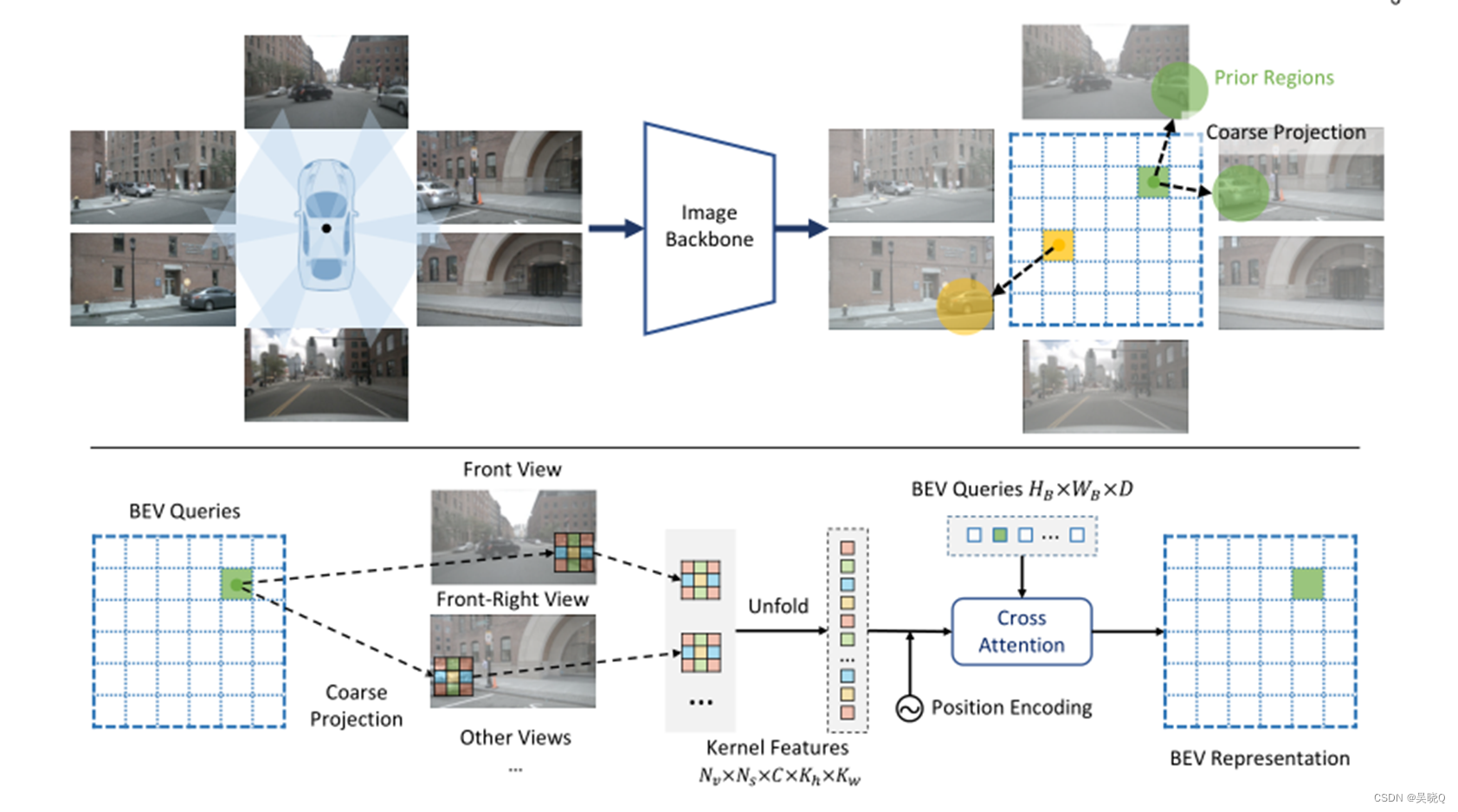
论文的整体结构如上,主要创新点是在原论文的基础上加入和映射查询表(look up table)以及加强了相机偏差鲁棒性。下面重点介绍这两个创新点。
四、创新点:
4.1 映射查询表
引入BEV-to-2D LUT(look up table)索引以加快GKT。每个BEV网格的内核区域是固定的,可以离线预计算。在运行前,我们构建了一个LUT(查找表),它缓存了BEV查询索引和图像像素索引之间的对应关系。在运行时,我们从LUT中获得每个BEV查询的对应像素索引,并通过索引有效地获取内核特征。通过LUT索引,GKT摆脱了对相机参数的高精度计算

4.2 相机偏差鲁棒性
对于正在运行的自动驾驶系统,外部环境是复杂的。摄像机将很容易偏离其校准位置。为了增强模型的鲁棒性,本文模拟了真实场景中摄像机的偏差。具体来说,本文将偏差分解为旋转偏差Rdevi和平移偏差Tdevi,并将随噪声添加到所有x、y、z维度。所有的偏差均为高斯噪声。取整函数也可以保证--定的抗噪能力。

4.3 Position Embeeding

4.4 Cross Attention

五、代码实现
见前面的发文http://t.csdn.cn/5igqf















 1473
1473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









