






编辑:计算机视觉工坊
0. 这篇文章干了啥?
目标检测是自动驾驶中的一项基础任务,它使车辆能够理解和导航周围环境。传统上,这些任务是在预定义的类别集上进行训练的,这限制了它们全面理解复杂和动态环境的能力。为了克服这一限制,最近的进展引入了3D占用估计,这是一种流行的方法,它使用体素网格来表示场景几何。这种方法允许基于几何的通用目标检测,使自动驾驶车辆能够感知其环境中的任何结构。然而,大多数现有的3D占用估计方法都依赖于昂贵的3D真实标签。这一要求带来了重大挑战,因为为大规模数据集获取准确的3D标签既耗费资源又不切实际。此外,现有的基准测试通常只反映有限的预定义类别集。因此,迫切需要新方法来有效地训练占用模型,而无需依赖3D标签,例如通过自监督学习。虽然已有一些努力来避免使用体素标签,但它们要么仍然需要标记的激光雷达点云,要么涉及复杂的伪真实标签生成技术。此外,尽管这些方法能够捕获任何几何形状,但其语义理解仍然局限于预定义的类别集。这些限制阻碍了自主系统在理解和适应多样化和不断变化的环境方面的适应性和灵活性。
在本文中,我们提出了一种新颖的自监督占用估计方法,该方法将几何估计与开放词汇的自然语言特征对齐,从而允许表示任何语义,因此消除了对2D或3D语义标签的需求。为实现这一目标,我们利用流行的CLIP模型的强大功能,并通过体积渲染将其表示能力提炼到3D空间中。特别是,我们的模型不是预测预定义类别的概率,而是估计每个体素的视觉-语言对齐特征。该模型通过从3D体素空间以可微方式渲染这些特征回到2D图像空间进行训练,其中这些特征由现成的视觉-语言编码器CLIP预先计算得到并作为监督。源代码将很快发布。
下面一起来阅读一下这项工作~
1. 论文信息
标题:LangOcc: Self-Supervised Open Vocabulary Occupancy Estimation via Volume Rendering
作者:Simon Boeder, Fabian Gigengack, Benjamin Risse
机构:Robert Bosch GmbH、University of M¨unster
原文链接:https://arxiv.org/abs/2407.17310
2. 摘要
近年来,基于视觉的自动驾驶领域中,三维占用估计任务已成为一个重要的挑战。然而,大多数现有的基于摄像头的方法依赖于昂贵的三维体素标签或激光雷达扫描进行训练,这限制了它们的实用性和可扩展性。此外,大多数方法仅限于检测一组预定义的类别。在本工作中,我们提出了一种称为LangOcc的新颖的开放词汇占用估计方法,该方法仅通过摄像头图像进行训练,并能够通过视觉-语言对齐来检测任意语义。特别是,我们通过可微体积渲染,将强大的视觉-语言对齐编码器CLIP的知识提炼到三维占用模型中。我们的模型仅使用图像在三维体素网格中估计视觉-语言对齐的特征。它通过将我们的估计重新渲染回二维空间来进行自监督训练,其中可以计算真实特征。这种训练机制自动监督场景几何,从而提供了一种直接且强大的训练方法,而无需任何明确的几何监督。LangOcc在开放词汇占用估计方面大大优于基于激光雷达监督的竞争对手,且仅依赖于基于视觉的训练。此外,尽管不受特定类别集的限制,我们在Occ3D-nuScenes数据集上的自监督语义占用估计方面也取得了最先进的结果,从而证明了我们提出的视觉-语言训练的有效性。
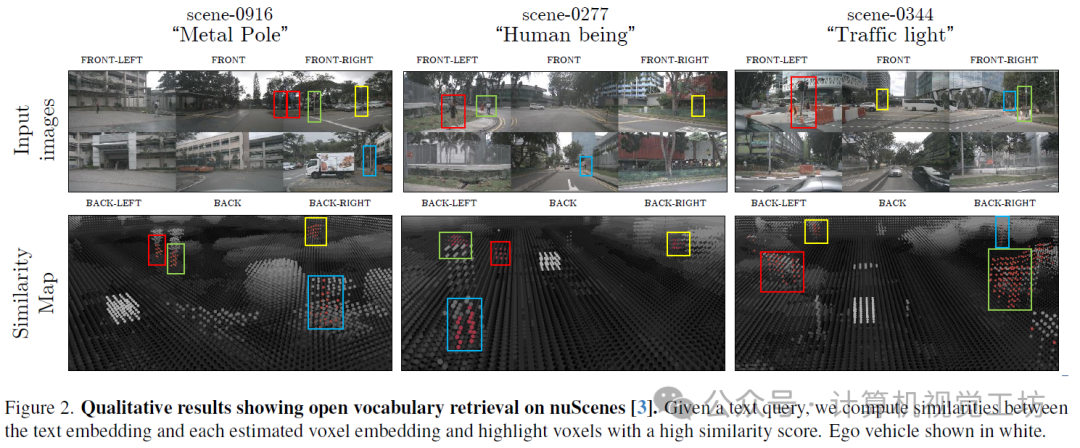
3. 效果展示
4. 主要贡献
总之,我们的贡献包括:
• 开放词汇占用估计:一种新颖的仅视觉架构,通过将语义特征空间与自然语言对齐来建模任意几何形状和语义,从而将占用表示与预定义的语义类别定义解耦。
• 自监督学习:受NeRF启发,LangOcc联合训练语言特征和3D场景几何,并消除了对3D真实标签的需求。因此,所提出的方法仅通过图像即可进行训练。我们的模型能够以零样本方式泛化估计几何和语义,无需像NeRF方法那样进行逐场景优化。
• 特征子空间学习:此外,我们还引入了一种专门的降维策略,以提高在存在一组特定任务类别时的分割性能。
• 最先进的性能:LangOcc在开放词汇占用估计方面大幅优于竞争对手,并在自监督语义占用估计方面取得了最先进的结果。
5. 基本原理是啥?
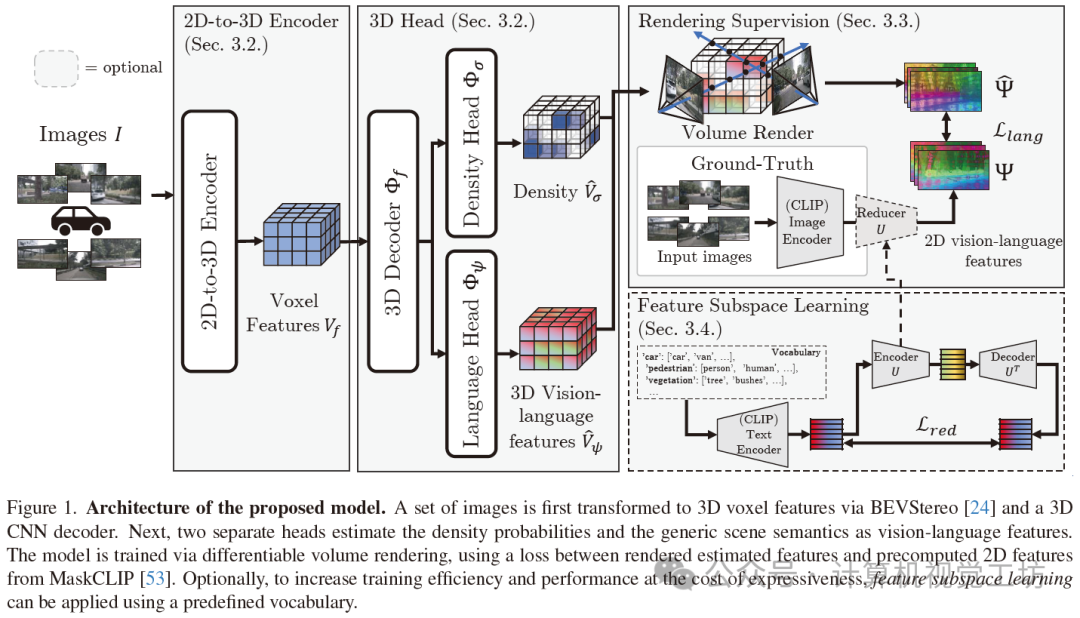
所提模型的大致框架如图1所示。首先,类似于之前的工作,使用突出的二维到三维转换网络BEVStereo将输入图像I转换为三维体素特征Vf。但请注意,也可以使用其他任何二维到三维编码器。之后,这些体素特征被用于通过三维卷积神经网络(CNN)解码器和两个独立的多层感知机(MLP)头部来预测密度Vσ和语言对齐特征Vψ。整个模型通过体积渲染监督进行训练,即将估计的三维特征渲染回二维图像空间,并将其与预计算的视觉-语言特征进行比较。此外,介绍了一种可选方法,通过在给定词汇表上预训练降维编码器来提高检测性能和训练效率。
6. 实验结果
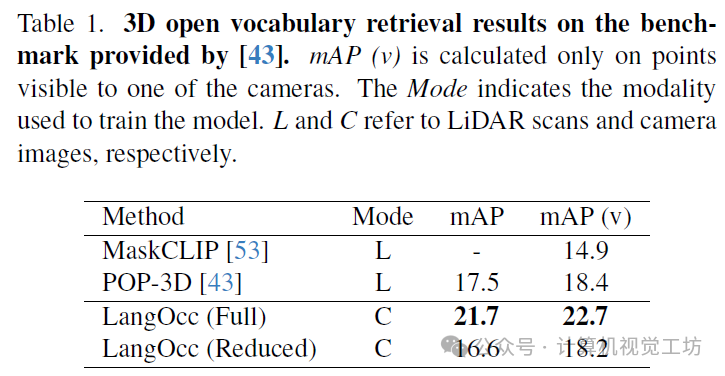
我们将我们的结果与作者在提供的基准测试集上与POP-3D进行了比较。POP-3D的模型基于TPVFormer,并将语义头替换为与我们的模型类似的视觉-语言头。作者使用nuScenes中可用的LiDAR扫描来训练他们的模型,既用于学习几何形状,也用于特征蒸馏。他们还提供了直接使用MaskCLIP作为基线的结果,方法是将LiDAR扫描投影到MaskCLIP特征图上。该比较的结果如表1所示。
从表中可以看出,尽管我们仅使用基于视觉的监督,但我们的方法在两个基线上均表现出色。与POP-3D的17.5和18.4相比,我们分别在所有点和仅可见点上实现了21.7和22.7的mAP分数,而且我们并未使用LiDAR数据。这些结果清楚地证明了在将视觉-语言特征提炼到3D空间中时,渲染监督的有效性。
我们认为这种性能提升主要归功于时间渲染方法,它使我们的模型能够从多个重叠视角中学习,从而增强对几何形状和视觉-语言的理解。正如预期的那样,使用所提出的特征子空间学习方法会降低LangOcc的开放词汇性能,因为我们针对特定类别的集合定义了一个较低维度的空间,这降低了对于不属于该集合的开放词汇查询的检测性能。然而,如后续所示,精简版在语义占用估计任务上反而提高了性能。
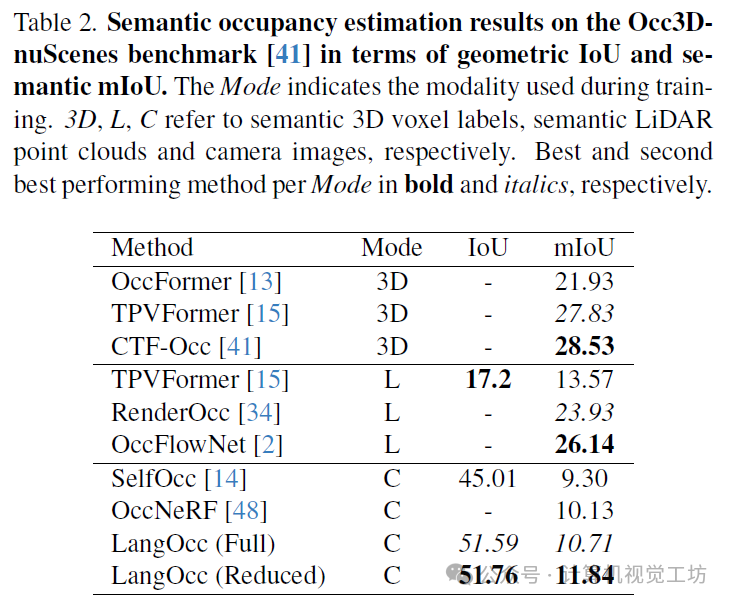
我们在Occ3D-nuScenes数据集上将我们的方法与其他近期方法进行了评估,并在表2中展示了结果。仅使用视觉训练(C),我们提出的方法在几何交并比(IoU)和语义平均交并比(mIoU)上都超越了自监督竞争对手SelfOcc和OccNeRF。LangOcc的几何交并比得分至少为51.59,这表明我们的模型能够在没有任何光度损失或显式深度监督的情况下很好地估计场景几何。SelfOcc和OccNeRF都显式地监督了几何形状,例如通过多视图立体损失和RGB渲染。显然,通过视觉-语言特征的体积渲染学习到的密度提供了足够的信号,甚至比使用光度损失来学习几何形状更为合适。我们假设这可能是由于CLIP嵌入的高表示能力以及我们的模型被迫在许多重叠视图中学习一致的3D特征。因此,与通常非常模糊的光度损失相比,该模型获得了更好的几何监督。我们进一步比较了RGB和特征蒸馏损失对几何的影响。此外,SelfOcc和OccNeRF都使用特定类别的分割网络来估计体素标签,而LangOcc在理论上可以使用相同的模型检测任何类别(在完全变化中)。尽管我们的模型是在没有任何显式类别定义的情况下进行训练的,但我们在语义平均交并比方面也优于这两个竞争对手,这突出了估计特征的强大功能。通过为给定任务指定词汇并使用提出的降维方法,我们可以将语义平均交并比得分从10.71提高到11.84。
7. 总结 & 未来工作
在本文中,我们提出了一种新颖的模型,该模型能够实现通用的开放词汇场景表示和一种仅需要图像作为输入的自监督训练机制。通过使用可微分的体积渲染,我们将视觉-语言编码器CLIP的丰富知识提炼到3D占用估计模型中,并同时学习估计场景几何,而无需任何显式的几何监督。这允许生成完全独立于特定类别定义的通用3D场景表示。我们的模型以零样本方式学习表示场景,无需像先前工作那样的每场景优化。它在不使用任何激光雷达数据的情况下,显著优于之前的开放词汇占用估计尝试。此外,我们在Occ3D-nuScenes数据集上设立了仅视觉的语义占用估计的最新性能标准,并通过提出的特征子空间学习方法进一步提高了分割性能。我们得出结论,通过将强大的二维视觉编码器的知识提炼到三维占用估计模型中,可以实现比光度方法更强的占用估计。未来一个很有前景的方向是引入更通用的特征表示,如DINO(已被证明能够编码比CLIP更好的几何特征)。此外,我们的工作仍然缺乏处理动态对象的机制,这导致在时间渲染过程中监督信号不一致。在未来的工作中,对场景动态的显式建模可能有助于消除时间上不一致的信号,甚至有助于为下游规划器估计场景流。为了比较未来的开放词汇方法,一个更大且更多样化的基准数据集将是非常有益的。最后,基于我们模型的出色表现,我们需要对开放词汇占用估计进行更多研究,以进一步探索其在各种任务(如自动驾驶)中的适用性和潜在的性能提升,这些任务对开放词汇占用估计有着高度需求。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
计算机视觉工坊交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
最前沿:具身智能、Mamba、NLP、CV、ASR、生成对抗大模型、强化学习大模型、对话大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、BEV感知、Occupancy、目标跟踪、端到端自动驾驶等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

▲长按扫码添加助理
3D视觉学习知识星球
3D视觉从入门到精通知识星球、国内成立最早、6000+成员交流学习。包括:星球视频课程近20门(价值超6000)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

▲长按扫码加入星球
3D视觉课程官网:www.3dcver.com
3D视觉模组选型:www.3dcver.com
















 1213
1213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









