







 本文深入探讨了特征值和特征向量的概念,包括它们在矩阵数值计算中的应用,以及如何从几何层面理解它们的含义。文章详细讲解了特征值和特征向量的计算步骤,并通过实例展示了特征值的代数重数与几何重数的区别。
本文深入探讨了特征值和特征向量的概念,包括它们在矩阵数值计算中的应用,以及如何从几何层面理解它们的含义。文章详细讲解了特征值和特征向量的计算步骤,并通过实例展示了特征值的代数重数与几何重数的区别。
原创首发,转载请注明出处(CSDN:古希腊的汉密士),谢谢!
文章目录
一、前言
特征值和特征向量——在矩阵的数值计算中不可或缺的一环,但大多数人仅满足于套用公式 f ( λ ) = ∣ λ E − A ∣ \mathsf{f(\lambda)=\mid \lambda E-A\mid} f(λ)=∣λE−A∣ 止步于粗浅地求出相应的数值和向量。在笔者看来未免太过可惜,没有真正从几何层面体验特征值和特征的向量,自然也就无法领略几何层面的优美。 对于特征值和特征向量,笔者会先从大家熟悉的代数层面切入,然后引出多数人不熟悉的几何层面。但在开始之前,笔者首先对特征值和特征向量进行定义,再引入对于特征值来说两个比较特别的概念:代数重数和几何重数。代数重数和几何重数涉及矩阵的对角化,但对角化一节内容涉及过多非常琐碎,故笔者只取重数一瓢。
二、特征向量与特征值
|概念阐明
定义 设V是数域上的一个线性空间,A是V内的一个线性变换,如果对K内一个数 λ \lambda λ,存在V的一个向量 ξ ≠ 0 \xi \ne 0 ξ=0,使
A ξ = λ ξ , A\xi=\lambda\xi, Aξ=λξ,
则称 λ \lambda λ 为A的一个特征值,而 ξ \xi ξ 称为属于特征值 λ \lambda λ 的特征向量. 如果 λ o \lambda_o λo 是A的一个特征值,定义
V λ o = { α ∈ V ∣ A α = λ o α } , V_{\lambda_o}=\lbrace \alpha\in V|A\alpha=\lambda_o\alpha\rbrace, Vλo={α∈V∣Aα=λoα},
该式由A的对应特征值 λ o \lambda_o λo 的全部特征向量再加上零向量所得的的V的子空间,称为特征值 λ o \lambda_o λo 的特征子空间。
给定数域K上的n阶方阵 A = ( a i j ) , \mathsf{A=(a_{ij})}, A=(aij), 令
f ( λ ) = ∣ λ E − A ∣ = ∣ λ − a 11 − a 12 ⋯ − a 1 n − a 21 λ − a 22 ⋯ − a 2 n ⋮ ⋮ ⋱ ⋮ − a n 1 − a n 2 ⋯ λ − a n n ∣ , \mathsf{f(\lambda)=\mid \lambda E-A\mid=\begin{vmatrix} {\lambda-a_{11}}&{-a_{12}}&{\cdots}&{-a_{1n}}\\ {-a_{21}}&{\lambda-a_{22}}&{\cdots}&{-a_{2n}}\\ {\vdots}&{\vdots}&{\ddots}&{\vdots}\\ {-a_{n1}}&{-a_{n2}}&{\cdots}&{\lambda-a_{nn}}\\ \end{vmatrix}}, f(λ)=∣λE−A∣= λ−a11−a21⋮−an1−a12λ−a22⋮−an2⋯⋯⋱⋯−a1n−a2n⋮λ−ann ,
从行列式的完全展开式可知 f ( λ ) f(\lambda) f(λ) 的多项式,其系数属于数域K, f ( λ ) f(\lambda) f(λ) 称为方阵A的特征多项式, f ( λ ) f(\lambda) f(λ) 属于数域K的根称为方阵A的特征根或特征值.
|数域K上n维线性空间V内线性变换A的特征值和特征向量的计算步骤
- 在V中给定一组基 ϵ 1 , ϵ 2 , ⋯ , ϵ n \mathsf{\epsilon_1,\epsilon_2,\cdots,\epsilon_n} ϵ1,ϵ2,⋯,ϵn ,求线性变换A在这组基下的具体矩阵A;
- 计算特征多项式 f ( λ ) = ∣ λ E − A ∣ f(\lambda)=\mid \lambda E-A\mid f(λ)=∣λE−A∣;
- 求 f ( λ ) = 0 f(\lambda)=0 f(λ)=0 属于数域K的那些根 λ 1 , λ 2 , ⋯ , λ s . \lambda_1,\lambda_2,\cdots,\lambda_s. λ1,λ2,⋯,λs.(这里的 λ \lambda λ 已经是已知数,而非未知数);
- 对每一个 λ i ( i = 1 , 2 , ⋯ , s ) \mathsf{\lambda_i(i=1,2,\cdots,s)} λi(i=1,2,⋯,s) 求齐次方程组 ( λ i E − A ) X = 0 \mathsf{(\lambda_iE-A)X=0} (λiE−A)X=0 的一个基础解系. 具体计算式为
[ λ i − a 11 − a 12 ⋯ − a 1 n − a 21 λ i − a 22 ⋯ − a 2 n ⋮ ⋮ ⋱ ⋮ − a n 1 − a n 2 ⋯ λ i − a n n ] [ x 1 x 2 ⋮ x n ] = 0 \begin{bmatrix}{\lambda_i-a_{11}}&{-a_{12}}&{\cdots}&{-a_{1n}}\\{-a_{21}}&{\lambda_i-a_{22}}&{\cdots}&{-a_{2n}}\\{\vdots}&{\vdots}&{\ddots}&{\vdots}\\{-a_{n1}}&{-a_{n2}}&{\cdots}&{\lambda_i-a_{nn}}\\\end{bmatrix}\begin{bmatrix}x_1\\x_2\\\vdots\\x_n\\\end{bmatrix}=0 λi−a11−a21⋮−an1−a12λi−a22⋮−an2⋯⋯⋱⋯−a1n−a2n⋮λi−ann x1x2⋮xn =0
- 以步骤(4)中求出的基础解系为坐标写出V中的一个向量组,其为 V λ i \mathsf{V_{\lambda_i}} Vλi 的一组基。
例题 1 例题1 例题1 设三维线性空间V内一个线性变换A在基 ϵ 1 , ϵ 2 , ϵ 3 \epsilon_1,\epsilon_2,\epsilon_3 ϵ1,ϵ2,ϵ3 下的矩阵为
A
=
(
1
2
2
2
1
2
2
2
1
)
,
A=\begin{pmatrix}1&2&2\\2&1&2\\2&2&1\\\end{pmatrix},
A=
122212221
,
求A的全部特征值和对应的特征向量。
解:
- 特征多项式和特征值(特征根)
f ( λ ) = ∣ λ E − A ∣ = ∣ λ − 1 − 2 − 2 − 2 λ − 1 − 2 − 2 − 2 λ − 1 ∣ = ( λ − 5 ) ∣ 1 − 2 − 2 1 λ − 1 − 2 1 − 2 λ − 1 ∣ = ( λ − 5 ) ∣ 1 − 2 − 2 0 λ + 1 0 0 0 λ + 1 ∣ = ( λ − 5 ) ( λ + 1 ) 2 , \mathsf{f(\lambda)=\mid \lambda E-A \mid=\begin{vmatrix}{\lambda-1}&{-2}&{-2}\\{-2}&{\lambda-1}&{-2}\\{-2}&{-2}&{\lambda-1}\\\end{vmatrix}=(\lambda-5)\begin{vmatrix}{1}&{-2}&{-2}\\{1}&{\lambda-1}&{-2}\\{1}&{-2}&{\lambda-1}\\\end{vmatrix}=(\lambda-5)\begin{vmatrix}{1}&{-2}&{-2}\\{0}&{\lambda+1}&{0}\\{0}&{0}&{\lambda+1}\\\end{vmatrix}=(\lambda-5)(\lambda+1)^2}, f(λ)=∣λE−A∣= λ−1−2−2−2λ−1−2−2−2λ−1 =(λ−5) 111−2λ−1−2−2−2λ−1 =(λ−5) 100−2λ+10−20λ+1 =(λ−5)(λ+1)2,
即 f ( λ ) \mathsf{f(\lambda)} f(λ) 的根为 λ 1 = 5 , λ 2 = λ 3 = − 1 \mathsf{\lambda_1=5,\lambda_2=\lambda_3=-1} λ1=5,λ2=λ3=−1
-
特征值对应的特征向量
( λ 1 E − A ) X = [ 1 1 − 2 0 1 − 1 0 0 0 ] X = 0 , \mathsf{(\lambda_1E-A)X=\begin{bmatrix}{1}&{1}&{-2}\\{0}&{1}&{-1}\\{0}&{0}&{0}\\\end{bmatrix}X=0}, (λ1E−A)X= 100110−2−10 X=0, 有 { x 1 + x 2 − 2 x 3 = 0 x 2 = x 3 , \mathsf{\begin{cases} x_1+x_2-2x_3=0\\ x_2=x_3\\ \end{cases}}, {x1+x2−2x3=0x2=x3,
令 x 3 = 1 \mathsf{x_3=1} x3=1 解得 { x 1 = 1 x 2 = 1 x 3 = 1 \mathsf{\begin{cases}x_1=1\\x_2=1\\x_3=1\\\end{cases}} ⎩ ⎨ ⎧x1=1x2=1x3=1,则对应特征值 λ 1 \mathsf{\lambda_1} λ1的特征向量 η 1 = ( 1 , 1 , 1 ) , \mathsf{\eta_1=(1,1,1)}, η1=(1,1,1),
对应A的特征子空间 V λ 1 \mathsf{V_{\lambda_1}} Vλ1 的一组基有 V λ 1 = L ( ϵ 1 + ϵ 2 + ϵ 3 ) . \mathsf{V_{\lambda_1}=L(\epsilon_1+\epsilon_2+\epsilon_3)}. Vλ1=L(ϵ1+ϵ2+ϵ3).
同理 ( λ 2 E − A ) X = [ 1 1 1 0 0 0 0 0 0 ] X = 0 , \mathsf{\lambda_2E-A)X=\begin{bmatrix}1&1&1\\0&0&0\\0&0&0\\\end{bmatrix}X=0}, λ2E−A)X= 100100100 X=0, 有 x 1 + x 2 + x 3 = 0 \mathsf{x_1+x_2+x_3=0} x1+x2+x3=0 解得 x 1 = − x 2 − x 3 , \mathsf{x_1=-x_2-x_3}, x1=−x2−x3,
有两组解 ,即
{ x 2 = 1 x 3 = 0 ⟶ η 1 = ( − 1 , 1 , 0 ) ; { x 2 = 0 x 3 = 1 ⟶ η 2 = ( − 1 , 0 , − 1 ) . \mathsf{\begin{cases}x_2=1\\x_3=0\\\end{cases}\longrightarrow \eta_1=(-1,1,0);\begin{cases}x_2=0\\x_3=1\\\end{cases}\longrightarrow\eta_2=(-1,0,-1)}. {x2=1x3=0⟶η1=(−1,1,0);{x2=0x3=1⟶η2=(−1,0,−1).对应A的特征子空间 V λ 2 = L ( − ϵ 1 + ϵ 2 , − ϵ 1 + ϵ 3 ) . \mathsf{V_{\lambda_2}=L(-\epsilon_1+\epsilon_2,-\epsilon_1+\epsilon_3)}. Vλ2=L(−ϵ1+ϵ2,−ϵ1+ϵ3).
对于特征值和特征向量请务必准确把握其定义.下面笔者从代数的角度出发,以一阶常系数微分方程为代表的例题进行剖析。
|代数的层面——微分方程 d u d t = A u \mathsf{\frac{du}{dt}=Au} dtdu=Au
例题2 求微分方程组 { d u 1 d t = 4 u 1 − 5 u 2 d u 2 d t = 2 u 1 − 3 u 2 \mathsf{\begin{cases}\frac{du_1}{dt}=4u_1-5u_2\\\frac{du_2}{dt}=2u_1-3u_2\\\end{cases}} {dtdu1=4u1−5u2dtdu2=2u1−3u2 的通解 ?
小贴士:这里有一个很突出的地方,那就是说微积分领域的求导和线性代数里的线性变换到底有什么联系?或者说两者表达的含义是不是等价的呢?其实,两者在抽象向量空间层面是等价的.不管是函数(functions)亦或是想来向量(vectors),两者都具有向量特性.这里可以引出一个相当深刻的问题:一个函数的变换是线性的到底意味着什么? 对于向量而言,一个线性变换要满足在数域内保持加法封闭 L ( v ⃗ + w ⃗ ) = L ( v ⃗ ) + L ( w ⃗ ) \mathsf{L(\vec v+\vec w)=L(\vec v)+L(\vec w)} L(v+w)=L(v)+L(w)和数乘封闭 L ( c v ⃗ ) = c L ( v ⃗ ) \mathsf{L(c\vec v)=cL(\vec v)} L(cv)=cL(v) 才是线性变换。同样的,对于求导 d f d x \frac{df}{dx} dxdf、多项式加减也要满足加法和乘法封闭,同样也是线性的.我们必须明白,矩阵是一种线性变换,求导也是一种线性变换,如 d f d x = ( x 3 + x 2 ) ′ = d d x ( x 3 ) + d d x ( x 2 ) ; y = 3 x 2 + 4 x + 7 \frac{df}{dx}=(x^3+x^2)'=\frac{d}{dx}(x^3)+\frac{d}{dx}(x^2);y=3x^2+4x+7 dxdf=(x3+x2)′=dxd(x3)+dxd(x2);y=3x2+4x+7。 因此,对于微分方程的求解我们可以将其转化为矩阵的形式,利用特征值和特征向量求出通解。
解: 将 u ( t ) = e λ t x u(t)=e^{\lambda t}x u(t)=eλtx 代入原微分方程组,有
{ λ e λ t C 1 = 4 λ e λ t C 1 − 5 e λ t C 2 λ e λ t C 2 = 2 λ e λ t C 2 − 3 e λ t C 2 \begin{cases}\lambda e^{\lambda t}C_1=4\lambda e^{\lambda t}C_1-5e^{\lambda t}C_2\\\lambda e^{\lambda t}C_2=2\lambda e^{\lambda t}C_2-3e^{\lambda t}C_2\end{cases} {λeλtC1=4λeλtC1−5eλtC2λeλtC2=2λeλtC2−3eλtC2
约分化简提取出对应放入矩阵形式如下:
(
4
5
2
−
3
)
(
C
1
C
2
)
=
λ
(
C
1
C
2
)
\begin{pmatrix}4&5\\2&-3\\\end{pmatrix}\begin{pmatrix}C_1\\C_2\\\end{pmatrix}=\lambda\begin{pmatrix}C_1\\C_2\\\end{pmatrix}
(425−3)(C1C2)=λ(C1C2)
因
(
A
−
λ
I
)
X
=
0
(A-\lambda I)X=0
(A−λI)X=0 且
X
∈
N
(
A
−
λ
I
)
,
X\in N(A-\lambda I),
X∈N(A−λI), 有
d
e
t
(
A
−
λ
I
)
=
∣
4
−
λ
−
5
2
−
3
−
λ
∣
=
(
λ
+
1
)
(
λ
−
2
)
=
0
,
det(A-\lambda I)=\begin{vmatrix}4-\lambda&-5\\2&-3-\lambda\\\end{vmatrix}=(\lambda +1)(\lambda-2)=0,
det(A−λI)=
4−λ2−5−3−λ
=(λ+1)(λ−2)=0,
解得
λ
1
=
−
1
,
λ
2
=
2.
\lambda_1=-1,\lambda_2=2.
λ1=−1,λ2=2. 将两个解分别代入
(
A
−
λ
I
)
X
=
0
,
(A-\lambda I)X=0,
(A−λI)X=0, 解得特征向量
η
1
=
(
1
1
)
,
η
2
=
(
5
2
)
\eta_1=\begin{pmatrix}1\\1\\\end{pmatrix},\eta_2=\begin{pmatrix}5\\2\\\end{pmatrix}
η1=(11),η2=(52)
则两个特解形式为
u
1
=
e
λ
1
t
η
1
=
e
−
t
(
1
1
)
,
u
2
=
e
λ
2
t
η
2
=
e
2
t
(
5
2
)
,
u_1=e^{\lambda_1t}\eta_1=e^{-t}\begin{pmatrix}1\\1\\\end{pmatrix},u_2=e^{\lambda_2t}\eta_2=e^{2t}\begin{pmatrix}5\\2\\\end{pmatrix},
u1=eλ1tη1=e−t(11),u2=eλ2tη2=e2t(52),
故通解形式为
U
=
C
1
e
λ
1
t
η
1
+
C
2
e
λ
2
t
η
2
,
C
1
,
C
2
∈
R
U=C_1e^{\lambda_1t}\eta_1+C_2e^{\lambda_2t}\eta_2,C_1,C_2\in R
U=C1eλ1tη1+C2eλ2tη2,C1,C2∈R
下面笔者直接切入几何层面. 温馨提示,请先看完课程「线性代数的本质」中的「特征向量与特征值一节」。
|几何的层面——向量的变换
从几何的层面出发,绝大多数向量在线性变换的过程中基本上离开了其张成(span)的空间,但是某些向量仍然“停留”在原空间内,矩阵(矩阵是线性变换的具象化表现形式)对这些特殊向量仅仅起到了“拉伸”或“压缩”,而其他向量在变换过程中偏离了张成的“直线”,我们称这些“不动”的向量为特征向量,每个特征向量其所属的值称为“特征值”。 特征值的的作用在于衡量特征向量在线性变换中拉伸或者压缩的比例,若特征值出现负数,则说明线性变换使得线性空间出线性翻转,对于行列式值的正负同样适用。
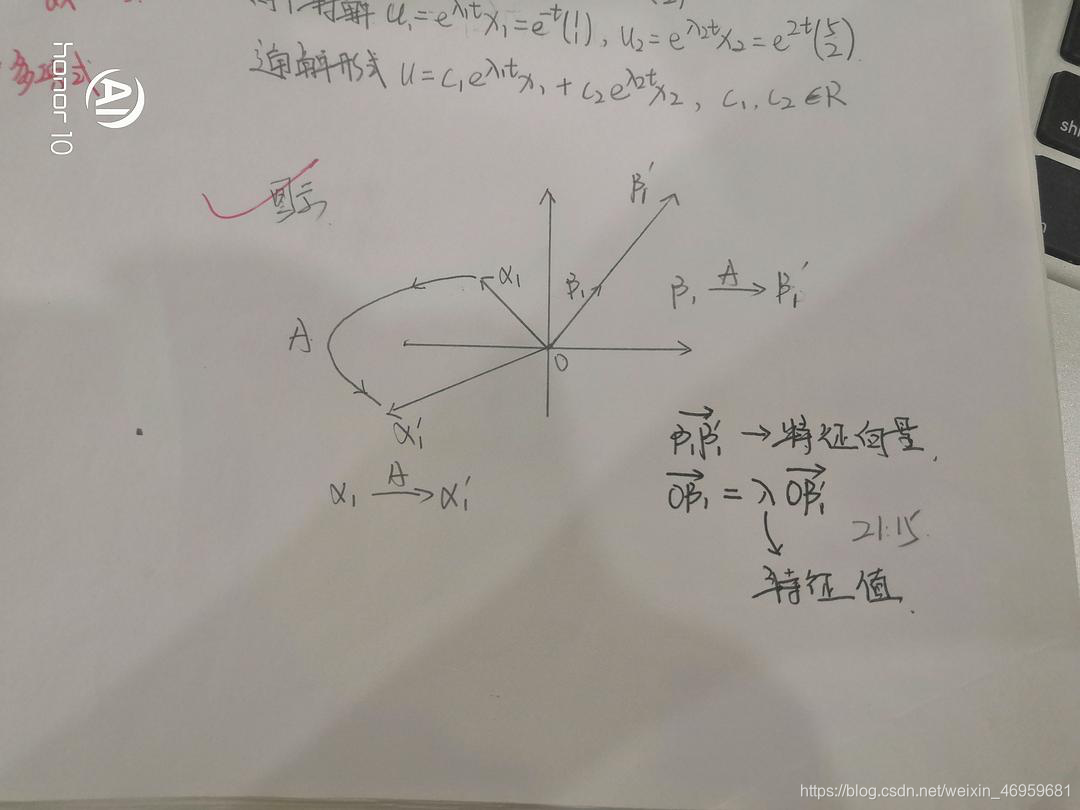
配合笔者的笔记图片再加上前面一段笔者的阐述,可以清晰的看到
α
⃗
1
,
\vec \alpha_1,
α1, 在线性变换A的过程中产生了偏离,故
α
⃗
1
\vec \alpha_1
α1 不是特征向量,而
β
⃗
1
\vec \beta_1
β1 在线性变换A的过程中仍然“停留”在了原空间原位置并且拉伸
λ
\lambda
λ 倍,故
β
⃗
\vec \beta
β 是特征向量。
再来来看两张图片:(截取自课程《线性代数的本质》特征值与特征向量一节)。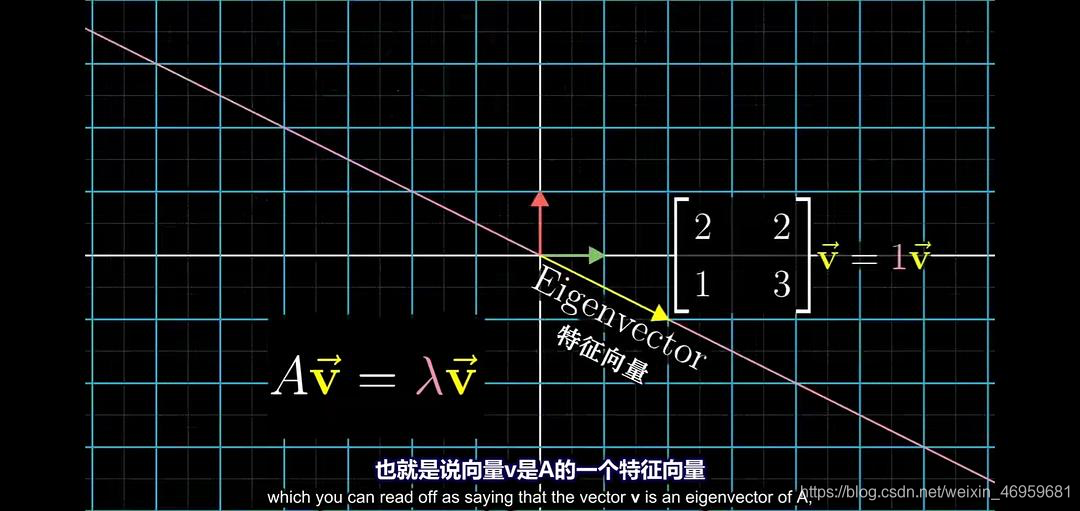
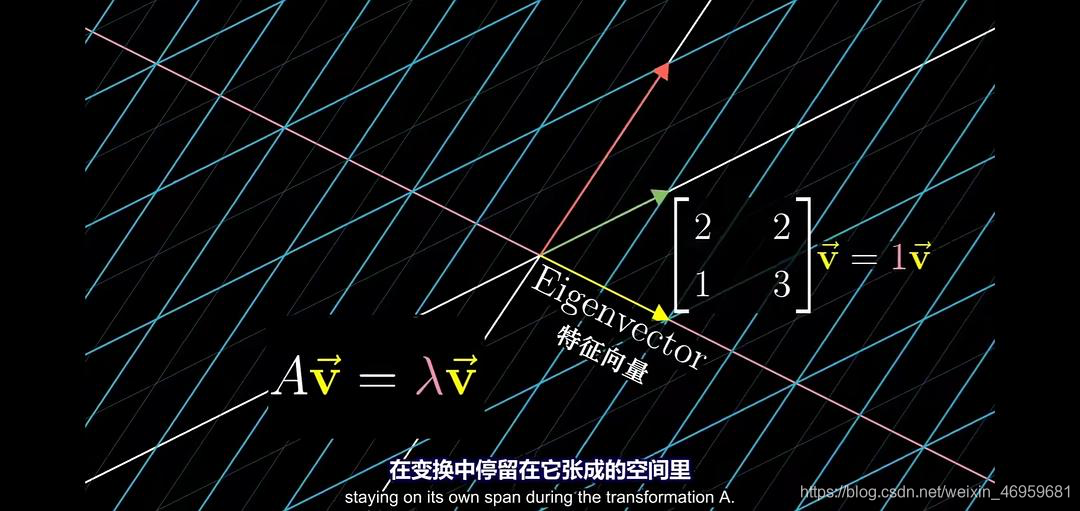
从前后两张图片我们可以清晰的看到整个向量空间经过线性变换A后的变化,若存在特征向量,则可经由
A
v
⃗
=
λ
v
⃗
A\vec v=\lambda\vec v
Av=λv 求出。
对想继续深入了解的朋友来说,上面的分析仅仅是蜻蜓点水. 笔者在这里提出几个容易被大家忽略的问题:
- 特征值必须是数域K内的数;
- 特征向量必须是非零向量,因为零向量对要讨论的问题是没有作用的,但在研究特征子空间 V λ o V_{\lambda_o} Vλo 是有要将其添加进去,子空间必须包含零向量;
- 特征向量与特征值的定义与基是没有关联的,只是在我们进行计算的时候要借用一组基,将线性变换A具体化为某个方阵. 最后归结为特征多项式 f ( λ ) = ∣ λ E − A ∣ f(\lambda)=\begin{vmatrix}\lambda E-A\\\end{vmatrix} f(λ)= λE−A 的根和齐次线性方程组 ( λ i E − A ) X = 0 (\lambda_i E-A)X=0 (λiE−A)X=0 的基础解系的计算;
- 特征向量可以有无限多个,但特征值也许只有一个数值.比如将整个线性空间扩大K倍,则全体向量都为特征向量,而特征值仅为K。
对于根基不扎实的朋友即便日常练习中做了大量的题目将整个计算计算流程烂熟于心,但对于其中的一条或两条要点依然无所知。学习解题的套路确实很重要,但若是流于表面仅仅满足于计算,那更深层次的美妙大概率就难以领会了。
三、特征值的代数重数与几何重数
|代数重数与几何重数的定义
定义 设A是数域K上的n级矩阵, λ i \lambda_i λi 是A的某个特征值. 设 d e t ( A − λ I ) = ( λ 1 − λ ) n 1 ⋯ ( λ k − λ ) n k , det(A-\lambda I)=(\lambda_1-\lambda)^{n_1}\cdots(\lambda_k-\lambda)^{n_k}, det(A−λI)=(λ1−λ)n1⋯(λk−λ)nk, 其中 λ i ≠ λ ( i ≠ j ) , \lambda_i\neq \lambda(i\neq j), λi=λ(i=j), 称 n i n_i ni 为特征值 λ i \lambda_i λi 的代数重数,记作 A M ( λ i ) = n i ; AM(\lambda_i)=n_i; AM(λi)=ni; 称 d i m N ( A − λ i I ) dimN(A-\lambda_i I) dimN(A−λiI) 为特征值 λ i \lambda_i λi 的几何重数,记作 G M ( λ i ) = d i m ( A − λ i I ) GM(\lambda_i)=dim(A-\lambda_i I) GM(λi)=dim(A−λiI)。
- 几何直观上, λ i \lambda_i λi对应的特征子空间的维数为 λ i \lambda_i λi的几何重数(geometric multiplicity);
- 代数的抽象层面上, λ i \lambda_i λi对应放入特征多项式的根的重数为 λ i \lambda_i λi的代数重数(algebraic multiplicity)。
∗ \ast ∗注:该定义是笔者阅读了邱维声先生的书本讲义和清华线性代数公开课视频讲义结合而成,定义的力道算的上是入木三分了。
例题 3 例题3 例题3 矩阵 A = ( 0 1 0 0 ) A=\begin{pmatrix}0&1\\0&0\\\end{pmatrix} A=(0010) 的特征值为 λ 1 = λ 2 = 0 , \lambda_1=\lambda_2=0, λ1=λ2=0, 故 G M = 1 < 2 = A M GM=1 \lt 2=AM GM=1<2=AM
e . g e.g e.g I = ( 1 0 0 1 ) I=\begin{pmatrix}1&0\\0&1\\\end{pmatrix} I=(1001) 的特征值 λ 1 = λ 2 = 1 , \lambda_1=\lambda_2=1, λ1=λ2=1, 故 G M = A M = 2 GM=AM=2 GM=AM=2
e . g e.g e.g A = ( 6 − 1 1 4 ) A=\begin{pmatrix}6&-1\\1&4\\\end{pmatrix} A=(61−14) 的特征值 λ 1 = λ 2 , \lambda_1=\lambda_2, λ1=λ2, 故 G M = 1 < 2 = A M GM=1\lt 2=AM GM=1<2=AM
从以上三个例题可以推出以下命题:数域K上的n级矩阵的一个特征值 λ i , \lambda_i, λi, 其对应几何重数不大于对应的代数重数.
命题看起来很直观,但是对应的数学证明非常硬核.下面笔者给出两种证明方式,初级入门者可以适当略过.
|命题的证明升华到定理
-
证明方法一:
设属于A的特征值 λ i \lambda_i λi 对应放入特征子空间 w 1 w_1 w1 的维数为r. 在 w 1 w_1 w1 中取一个基 ( α 1 , α 2 , ⋯ , α r ) (\alpha_1,\alpha_2,\cdots,\alpha_r) (α1,α2,⋯,αr) 将其扩充为 K n K^n Kn 上的一个基 ( α 1 , α 2 , ⋯ , α r , β 1 , ⋯ , β n − r ) . (\alpha_1,\alpha_2,\cdots,\alpha_r,\beta_1,\cdots,\beta_{n-r}). (α1,α2,⋯,αr,β1,⋯,βn−r).
令 P = ( α 1 , α 2 , ⋯ , α r , β 1 , ⋯ , β n − r ) , P=(\alpha_1,\alpha_2,\cdots,\alpha_r,\beta_1,\cdots,\beta_{n-r}), P=(α1,α2,⋯,αr,β1,⋯,βn−r), 故P是K上的n级可逆矩阵,并且有
P − 1 A P = P − 1 ( A α 1 ⋮ A α r A β 1 ⋮ A β n − r ) T = ( λ 1 P − 1 α 1 ⋮ λ 1 P − 1 α r P − 1 A β 1 ⋮ P − 1 A β n − r ) T P^{-1}AP=P^{-1}\begin{pmatrix}A\alpha_1\\\vdots\\A\alpha_r\\A\beta_1\\\vdots\\A\beta_{n-r}\\\end{pmatrix}^T=\begin{pmatrix}\lambda_{1}P^{-1}\alpha_1\\\vdots\\\lambda_1P^{-1}\alpha_r\\P^{-1}A\beta_1\\\vdots\\P^{-1}A\beta_{n-r}\\\end{pmatrix}^{T} P−1AP=P−1 Aα1⋮AαrAβ1⋮Aβn−r T= λ1P−1α1⋮λ1P−1αrP−1Aβ1⋮P−1Aβn−r T
由于
I
=
P
−
1
P
=
(
P
−
1
α
1
⋮
P
−
1
α
r
P
−
1
β
1
⋮
P
−
1
β
n
−
r
)
T
,
I=P^{-1}P=\begin{pmatrix}P^{-1}\alpha_1\\\vdots\\P^{-1}\alpha_r\\P^{-1}\beta_1\\\vdots\\P^{-1}\beta_{n-r}\\\end{pmatrix}^T,
I=P−1P=
P−1α1⋮P−1αrP−1β1⋮P−1βn−r
T,
因此
ϵ
1
=
P
−
1
α
1
,
ϵ
2
=
P
−
1
α
2
,
⋯
,
ϵ
r
=
P
−
1
α
r
,
\epsilon_1=P^{-1}\alpha_1,\epsilon_2=P^{-1}\alpha_2,\cdots,\epsilon_r=P^{-1}\alpha_r,
ϵ1=P−1α1,ϵ2=P−1α2,⋯,ϵr=P−1αr,
从而
P
−
1
A
P
=
(
λ
1
ϵ
1
⋮
λ
1
ϵ
r
P
−
1
A
β
1
⋮
P
−
1
A
β
n
−
r
)
T
=
(
λ
1
I
r
B
0
C
)
.
P^{-1}AP=\begin{pmatrix}\lambda_1\epsilon_1\\\vdots\\\lambda_1\epsilon_r\\P^{-1}A\beta_1\\\vdots\\P^{-1}A\beta_{n-r}\\\end{pmatrix}^T=\begin{pmatrix}\lambda_1 I_r&B\\0&C\\\end{pmatrix}.
P−1AP=
λ1ϵ1⋮λ1ϵrP−1Aβ1⋮P−1Aβn−r
T=(λ1Ir0BC).「注意:
B
B
B是
r
×
(
n
−
r
)
r\times (n-r)
r×(n−r)矩阵」
由于相似的矩阵具有相似的特征多项式,因此
∣
λ
I
−
A
∣
=
∣
λ
I
r
−
λ
1
I
r
−
B
0
λ
I
n
−
r
−
C
∣
=
∣
λ
I
r
−
λ
1
I
r
∣
∣
λ
I
n
−
r
−
C
∣
=
(
λ
−
λ
1
)
r
∣
λ
I
n
−
r
−
C
∣
,
\mid \lambda I-A\mid=\begin{vmatrix}\lambda I_r-\lambda_1I_r&-B\\0&\lambda I_{n-r}-C\\\end{vmatrix}=\mid \lambda I_r-\lambda_1I_r \mid \mid\lambda I_{n-r}-C\mid=(\lambda-\lambda_1)^r\mid\lambda I_{n-r}-C\mid,
∣λI−A∣=
λIr−λ1Ir0−BλIn−r−C
=∣λIr−λ1Ir∣∣λIn−r−C∣=(λ−λ1)r∣λIn−r−C∣,
从而
λ
1
\lambda_1
λ1 的代数重数大于或等于r,即
λ
1
\lambda_1
λ1 的代数重数大于或等于
λ
1
\lambda_1
λ1 的几何重数.
笔者出于博客的美观考虑将原来所有似基横向的写法全部改为行向量转置的类型,其原型类似于(1,2,3,4,5)
- 证明方法二:(在证明之前先引入两个引理)
引理一:相似矩具有相同的特征多项式
引理二:任意复方阵相似于一个上三角,且其对角元为矩阵的特征值.
关于引理二的证明如下:
当
n
=
1
n=1
n=1 时定理成立.
假设对
n
−
1
n-1
n−1 阶复矩阵结论成立. 对任意n阶复方阵A设有特征值
λ
1
\lambda_1
λ1 及相应的特征向量
x
1
≠
0
x_1\neq 0
x1=0 将其扩充为
C
n
C^n
Cn 的一组基
(
x
1
,
x
2
,
⋯
,
x
n
)
,
(x_1,x_2,\cdots,x_n),
(x1,x2,⋯,xn), 有
A
(
x
1
,
⋯
,
x
n
)
=
(
x
1
,
⋯
,
x
n
)
(
λ
1
∗
0
A
1
)
A(x_1,\cdots,x_n)=(x_1,\cdots,x_n)\begin{pmatrix}{\lambda_1}&{*}\\{0}&{A_1}\\\end{pmatrix}
A(x1,⋯,xn)=(x1,⋯,xn)(λ10∗A1) 记
P
1
=
(
x
1
,
⋯
,
x
n
)
,
P_1=(x_1,\cdots,x_n),
P1=(x1,⋯,xn), 则有
P
−
1
A
P
=
(
λ
1
∗
0
A
1
)
P^{-1}AP=\begin{pmatrix}{\lambda_1}&{*}\\{0}&{A_1}\\\end{pmatrix}
P−1AP=(λ10∗A1) 对n-1阶复方阵
A
1
,
A_1,
A1,由归纳假设可得,存在可逆矩阵Q使得
Q
−
1
A
Q
=
T
1
Q^{-1}AQ=T_1
Q−1AQ=T1为上三角矩阵.
令
P
2
=
(
1
Q
)
,
P
=
P
1
P
2
P_2=\begin{pmatrix}1& \\ &Q\end{pmatrix},P=P_1P_2
P2=(1Q),P=P1P2 可推出
P
−
1
A
P
=
P
2
−
1
P
1
−
1
A
P
1
P
2
=
P
2
−
1
(
λ
1
∗
0
A
1
)
P
2
=
(
λ
1
∗
0
T
1
)
=
T
P^{-1}AP=P_2^{-1}P_1^{-1}AP_1P_2=P_2^{-1}\begin{pmatrix}\lambda_1&*\\0&A_1\\\end{pmatrix}P_2=\begin{pmatrix}\lambda_1&*\\0&T_1\end{pmatrix}=T
P−1AP=P2−1P1−1AP1P2=P2−1(λ10∗A1)P2=(λ10∗T1)=T
「注意:T为上三角矩阵」
由引理可知
d
e
t
(
A
−
λ
I
)
=
d
e
t
(
T
−
λ
I
)
=
(
t
11
−
λ
)
⋯
(
t
n
n
−
λ
)
det(A-\lambda I)=det(T-\lambda I)=(t_{11}-\lambda)\cdots(t_{nn}-\lambda)
det(A−λI)=det(T−λI)=(t11−λ)⋯(tnn−λ)
上三角矩阵T的对角元
t
11
,
⋯
,
t
n
n
t_{11},\cdots,t_{nn}
t11,⋯,tnn 为A的特征值.
命题:
G
M
(
λ
)
≤
A
M
(
λ
)
GM(\lambda)\le AM(\lambda)
GM(λ)≤AM(λ)
证明:A相似于T,则特征值相同,且对任意特征值
λ
i
\lambda_i
λi,有
G
M
A
(
λ
i
)
=
G
M
T
(
λ
i
)
=
d
i
m
N
(
T
−
λ
i
I
)
=
d
i
m
N
(
A
−
λ
i
I
)
GM_A(\lambda_i)=GM_T(\lambda_i)=dimN(T-\lambda_i I)=dimN(A-\lambda_i I)
GMA(λi)=GMT(λi)=dimN(T−λiI)=dimN(A−λiI)
设A是上三角矩阵,即
A
=
(
a
11
⋯
∗
⋱
∗
a
n
n
)
A=\begin{pmatrix}a_{11}&\cdots&*\\ &\ddots&*\\ & &a_{nn}\\\end{pmatrix}
A=
a11⋯⋱∗∗ann
于是
r
(
A
−
λ
i
I
)
≥
n
−
A
M
(
λ
i
)
r(A-\lambda_i I)\ge n-AM(\lambda_i)
r(A−λiI)≥n−AM(λi)
故
G
M
(
λ
i
)
=
n
−
r
(
A
−
λ
i
I
)
≤
A
M
(
λ
i
)
GM(\lambda_i)=n-r(A-\lambda_i I)\le AM(\lambda_i)
GM(λi)=n−r(A−λiI)≤AM(λi)
命题经由证明升华成了定理,即:
复方阵A可对角化
⟷
\longleftrightarrow
⟷ 对任意特征值
λ
i
\lambda_i
λi 有
G
M
(
λ
i
)
=
A
M
(
λ
i
)
,
∑
i
=
1
k
A
M
(
λ
i
)
=
n
.
GM(\lambda_i)=AM(\lambda_i),\displaystyle\sum_{i=1}^{k}AM(\lambda_i)=n.
GM(λi)=AM(λi),i=1∑kAM(λi)=n.
若
∀
i
,
G
M
(
λ
i
)
=
A
M
(
λ
i
)
,
\forall i,GM(\lambda_i)=AM(\lambda_i),
∀i,GM(λi)=AM(λi), 则
G
M
(
λ
1
)
+
G
M
(
λ
2
)
+
⋯
+
G
M
(
λ
k
)
=
n
,
GM(\lambda_1)+GM(\lambda_2)+\cdots+GM(\lambda_k)=n,
GM(λ1)+GM(λ2)+⋯+GM(λk)=n, 故A有n个线性无关的特征向量.
例题 4 例题4 例题4 矩阵 A = ( 0 0 0 − 2 5 − 2 − 2 4 − 1 ) A=\begin{pmatrix}0&0&0\\{-2}&{5}&{-2}\\{-2}&{4}&{-1}\\\end{pmatrix} A= 0−2−20540−2−1 是否可对角化?若可,请求出特征向量矩阵S使得 S − 1 A S S^{-1}AS S−1AS 为对角阵。
解: d e t ( A − λ I ) = − ( λ − 1 ) 2 ( λ − 3 ) = 0 det(A-\lambda I)=-(\lambda-1)^2(\lambda-3)=0 det(A−λI)=−(λ−1)2(λ−3)=0 解得 λ 1 = λ 2 = 1 , λ 3 = 3 \lambda_1=\lambda_2=1,\lambda_3=3 λ1=λ2=1,λ3=3
A
−
λ
1
I
=
(
0
0
0
−
2
4
−
2
−
2
4
−
2
)
→
d
i
m
N
(
A
−
λ
1
I
)
=
2
A-\lambda_1 I=\begin{pmatrix}{0}&{0}&{0}\\{-2}&{4}&{-2}\\{-2}&{4}&{-2}\\\end{pmatrix}\rightarrow dimN(A-\lambda_1 I)=2
A−λ1I=
0−2−20440−2−2
→dimN(A−λ1I)=2
于是
A
M
(
λ
1
)
=
2
=
G
M
(
λ
1
)
,
AM(\lambda_1)=2=GM(\lambda_1),
AM(λ1)=2=GM(λ1), 同理
G
M
(
λ
3
)
=
A
M
(
λ
3
)
=
1
,
GM(\lambda_3)=AM(\lambda_3)=1,
GM(λ3)=AM(λ3)=1, 由以上结论得矩阵A可对角化。
对于
λ
1
=
λ
2
=
1
,
\lambda_1=\lambda_2=1,
λ1=λ2=1, 有
A
−
I
=
(
0
0
0
−
2
4
−
2
−
2
4
−
2
)
→
(
1
−
2
1
0
0
0
0
0
0
)
A-I=\begin{pmatrix}0&0&0\\-2&4&-2\\-2&4&-2\\\end{pmatrix}\rightarrow\begin{pmatrix}1&-2&1\\0&0&0\\0&0&0\\\end{pmatrix}
A−I=
0−2−20440−2−2
→
100−200100
(
A
−
I
)
X
=
0
(A-I)X=0
(A−I)X=0 的基础解系为
x
1
=
(
2
1
0
)
,
x
2
=
(
−
1
0
1
)
x_1=\begin{pmatrix}2\\1\\0\\\end{pmatrix},x_2=\begin{pmatrix}-1\\0\\1\\\end{pmatrix}
x1=
210
,x2=
−101
对于
λ
3
=
3
,
\lambda_3=3,
λ3=3, 有
A
−
3
I
=
(
−
2
−
0
0
−
2
2
−
2
−
2
−
4
−
4
)
→
(
1
0
0
0
1
−
1
0
0
0
)
A-3I=\begin{pmatrix}-2&-0&0\\-2&2&-2\\-2&-4&-4\\\end{pmatrix} \rightarrow \begin{pmatrix}1&0&0\\0&1&-1\\0&0&0\\\end{pmatrix}
A−3I=
−2−2−2−02−40−2−4
→
1000100−10
(
A
−
3
I
)
X
=
0
(A-3I)X=0
(A−3I)X=0 的基础解系为
x
3
=
(
0
1
1
)
x_3=\begin{pmatrix}0\\1\\1\\\end{pmatrix}
x3=
011
故
S
=
(
x
1
,
x
2
,
x
3
)
=
(
2
−
1
0
1
0
1
0
1
1
)
S=(x_1,x_2,x_3)=\begin{pmatrix}2&-1&0\\1&0&1\\0&1&1\\\end{pmatrix}
S=(x1,x2,x3)=
210−101011
且
S
−
1
A
S
=
(
1
1
3
)
S^{-1}AS=\begin{pmatrix}1& & \\ &1& \\ & &3\\\end{pmatrix}
S−1AS=
113
四、参考资料
- 笔者清华大学线性代数公开课笔记
- 笔者线性代数的本质笔记
- 高等代数学习指导书上册 丘维声著
- 高等代数学习指导 蓝以中著
五、文章更新记录
- 文章就部分内容进行了调整。 「2020.12.26 11:22」
- 部分内容做出修改。 「2021.4.2 9:00」
- 修改了部分内容,对文章的内容等级做出调整。「2022.6.14 14:09」
- 修改标题。「2022.6.14 14:09」
- 公开阅读权限。「2023.2.17 16:18」
P.S.1 该篇文章内容较偏数学理论化,如特征值和特征向量的定义,代数重数与几何重数的定义以及对应命题的证明. 对于初步入门的读者重心可放在文章前半节,而后半节关于代数重数和几何重数的内容可略过. 文章耕耘不易,有得请点赞,谢谢🙏.

















 6636
6636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









