






目录
论文:https://arxiv.org/pdf/2309.09818v1
代码:https://github.com/andvg3/Grasp-Anything

一、论文摘要
ChatGPT等基础模型由于其对现实世界领域的普遍表示,在机器人任务中取得了重大进展。在本文中,我们利用基础模型来解决抓取检测,这是机器人技术中具有广泛工业应用的持续挑战。尽管有许多抓取数据集,但与现实世界的数据相比,它们的对象多样性仍然有限。幸运的是,基础模型拥有广泛的现实世界知识库,包括我们在日常生活中遇到的对象。因此,一个有希望的解决方案是利用嵌入在这些基础模型中的通用知识来解决以前的抓取数据集中的有限表示。为了实现这一解决方案,我们提出了一个新的大规模抓取数据集grasp - anything。抓取- anything在多样性和规模方面表现出色,拥有1M个带有文本描述的样本和超过3M个对象,超过了以前的数据集。从经验上看,我们表明grip - anything成功地促进了基于视觉任务和现实世界机器人实验的零抓取检测。
主要贡献:
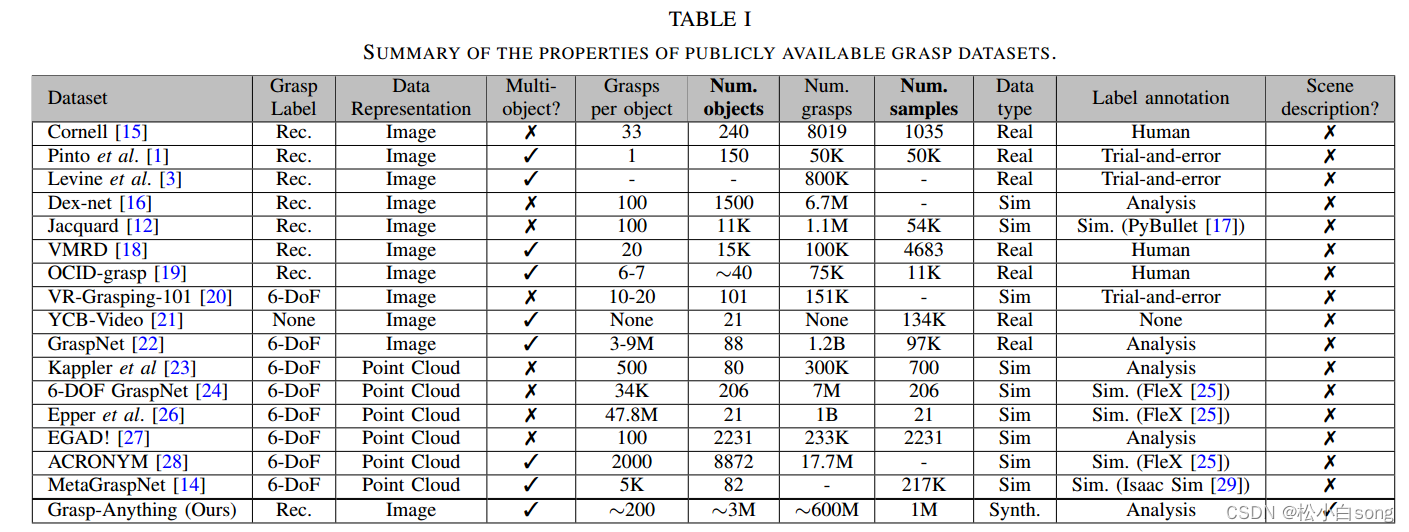
1.我们利用基础模型的知识引入了Grasp-Anything,这是一个新的大规模数据集,具有1M(一百万)个样本和3M个对象,在多样性和规模上大大超过了先前的数据集。
2.我们在各种设置上对零射击抓取检测进行基准测试,包括真实世界的机器人实验。结果表明,鉴于其对真实场景安排的全面表示,grasp - anything有效地支持零射击抓取检测
二、Grasp-Anything数据集
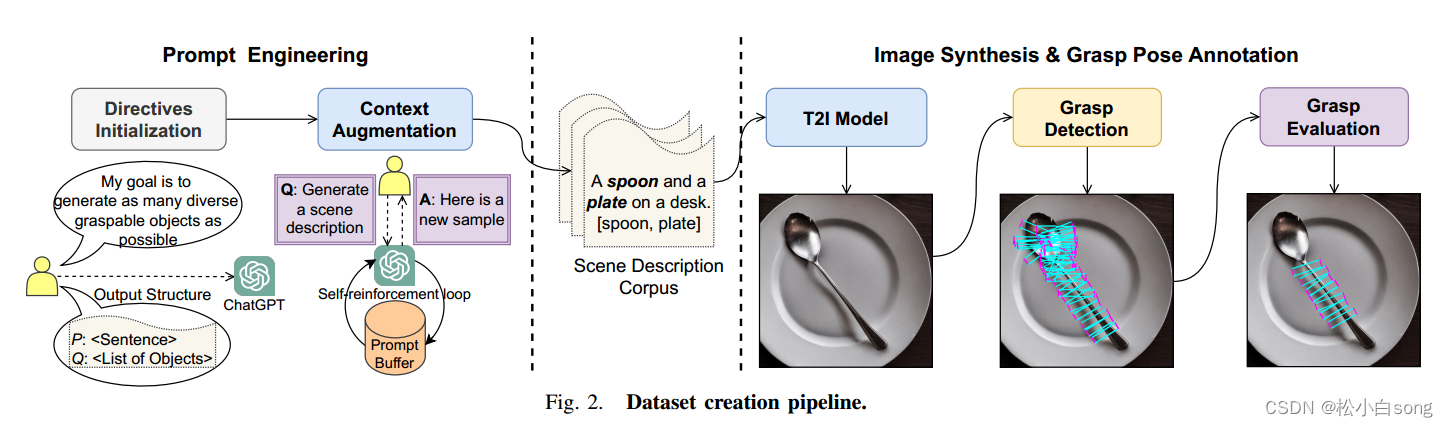
图2显示了生成Grasp-Anything数据集的过程概述。我们首先执行提示工程来生成场景描述,并利用基础模型从这些文本提示生成图像。然后自动生成并评估抓取姿势。
A. 场景生成
-
提示工程:为了生成多样化的对象集合,我们使用ChatGPT并进行提示工程来指导ChatGPT生成多样的场景描述。
- 指令初始化:为ChatGPT配置生成包含多种可抓取对象的场景描述的目标。例如,指令ChatGPT生成包含至少两个对象的场景描述句子。
- 上下文增强:通过创建一个自我增强循环来确保长期的质量一致性。我们初始化一个提示缓冲区,手动分配前50个样本。每次从缓冲区抽取10-15个场景描述并输入给ChatGPT,生成新的场景描述并添加到缓冲区中,直到生成100万个场景描述。
-
图像合成:根据ChatGPT生成的场景描述,我们使用Stable Diffusion 2.1生成与场景描述相符的图像。然后使用先进的视觉锚定和实例分割模型(如OFA和Segment-Anything)为每个出现在抓取列表中的对象生成实例分割掩码。
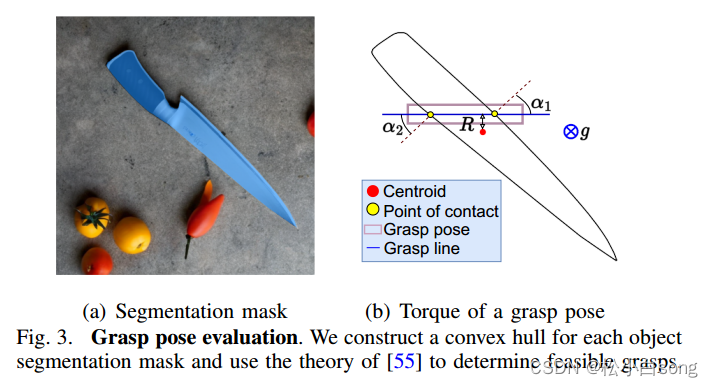
图3. 抓取姿势评估
图3(a):显示了一个对象的分割掩码。掩码用于确定对象的边界和中心点。
- 抓取姿势:表示为2D矩形,如图中的绿色矩形。
- 接触点:抓取线的两个端点,与对象接触的点。
- 凸包:通过对象分割掩码构建的凸包,用于确定可行的抓取姿势。
图3(b):展示了抓取姿势的扭矩评估方法。
- 净扭矩计算:通过公式 𝑇=(𝜏1+𝜏2)−𝑅𝑀𝑔 计算,τ1和τ2表示接触点的抗滑动扭矩,R是抓取线的距离。
- 正抓取和负抓取:根据抓取姿势的扭矩值 𝑇T 来评估抓取质量,正抓取的扭矩值为正,负抓取的扭矩值为负。
B. 抓取姿势标注
- 抓取姿势生成:我们使用预训练的RAGT-3/3模型来标注每个场景描述中的抓取姿势。
- 抓取姿势评估:为确保抓取姿势的准确性,我们采用Kamon等人的传统方法,通过计算每个抓取的净扭矩来评估抓取姿势的质量。根据抗滑动扭矩和施加力的几何特性,计算抓取的扭矩比,从而确定抓取的质量。
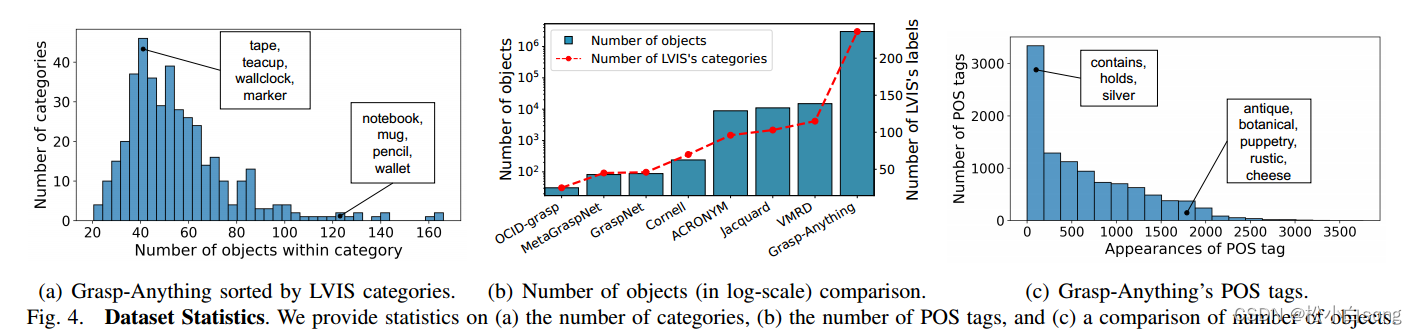
图4. 数据集统计
图4(a):展示了Grasp-Anything数据集中对象类别的分布情况,根据LVIS数据集的类别进行分类和统计。
每个类别的对象数量:通过预训练模型识别每个类别中的候选对象,并过滤出不符合语义的对象。图4(b):比较了不同抓取数据集中对象的数量(以对数尺度表示)。
Grasp-Anything数据集的对象数量明显多于其他数据集。图4(c):展示了Grasp-Anything数据集中词性标签(POS tags)的分布。
统计场景描述语料库中的词汇,显示大约35%是名词,20%是形容词,7%是动词,其余是其他词性标签。

图5. Grasp-Anything样本
展示了多个Grasp-Anything数据集中的样本场景,每个样本显示了最优抓取姿势。
- 样本1:一个绿色玻璃瓶和一个小花瓶放在木架上。
- 样本2:一副太阳镜和一部智能手机放在大理石台面上。
- 样本3:一个木质床头柜上放着一本书、一个时钟和一个花瓶。
- 样本4:一个黑色皮革钱包和一把银色钥匙放在咖啡桌上。
- 样本5:一个白色陶瓷杯子放在靠墙的小桌子上,旁边是一个小植物盆。
- 样本6:一个圆形镜子放在红玫瑰和化妆镜之间,位于白色梳妆台上。
C. Grasp-Anything统计
- 类别数量:使用LVIS数据集的300个类别来评估数据集中对象类别的多样性。结果显示Grasp-Anything覆盖了236个LVIS类别,显著优于其他数据集。
- 对象数量:Grasp-Anything的数据集中包含的对象数量显著多于其他抓取数据集。
- 词性标签数量:我们提取数据集中的词性标签,场景描述语料库使用了广泛的词汇来描述场景安排。
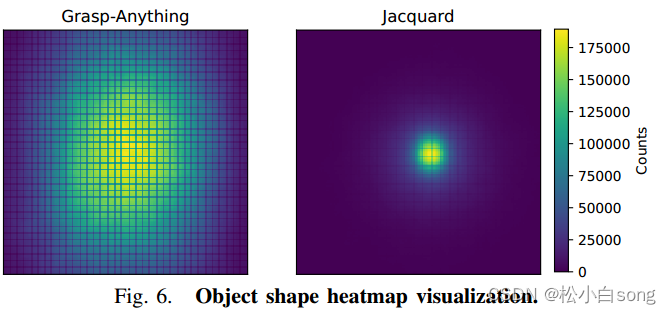
图6. 对象形状分布
比较了Grasp-Anything和Jacquard数据集中对象形状的分布情况。
热图:随机选择5000个对象,提取对象内部的像素坐标(x, y),并将这些坐标聚合生成热图。热图显示对象形状的覆盖范围,Grasp-Anything数据集中的对象形状覆盖范围更广,表明其形状多样性更高。
D. Grasp-Anything对社区的帮助
由于其大规模和多模态(如文本提示、图像和分割掩码)特点,Grasp-Anything可以在以下方面推动未来研究:
- 抓取检测:尽管已有许多抓取数据集,Grasp-Anything能够容纳更广泛的对象和更自然的场景设置,有助于推进零样本抓取检测和领域适应研究。
- 语言驱动的抓取:Grasp-Anything支持多样的场景描述,促进大规模训练以对齐自然语言与抓取检测。
三、实验
A. 零样本抓取检测
-
实验设置:
- 训练了三种深度学习抓取网络:GR-ConvNet、Det-Seg-Refine和GG-CNN。
- 使用五个数据集进行训练:Grasp-Anything、Jacquard、Cornell、VMRD和OCID-grasp。
- 主要指标是成功率,定义为与真实抓取的IoU分数大于0.25且偏移角度小于30°。
- 利用LVIS标签分类,将标签按出现频率分为“基础”类和“新”类,使用调和均值(H)衡量零样本成功率。
-
基础到新类别的泛化:
结果表明,使用Grasp-Anything数据集训练的基线网络在测试中表现略低于其他数据集,因为测试阶段包含更多未见对象,增加了挑战性。 -
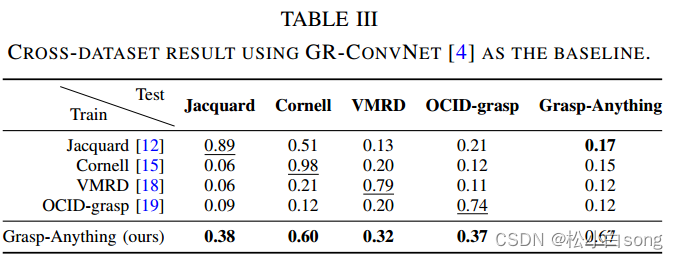
跨数据集迁移学习:
结果表明,当GR-ConvNet在Grasp-Anything数据集上训练后,在其他数据集上的表现显著提高,尤其是在Jacquard数据集上的表现是其他数据集的四倍。 -
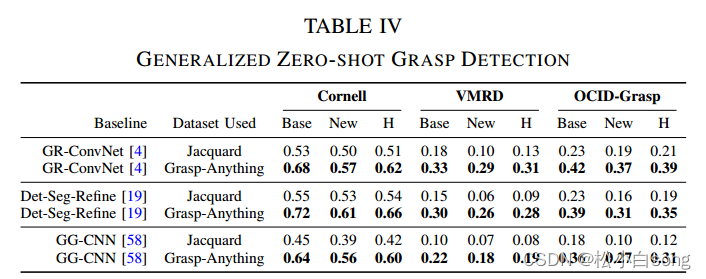
广义零样本学习:
将Grasp-Anything与表现较好的Jacquard数据集进行比较,测试结果显示Grasp-Anything显著提高了所有基线网络的性能。

B. 机器人评估
-
实验设置:
- 使用KUKA机器人进行评估,采用GR-ConvNet作为抓取检测网络。
- 使用RealSense相机获取的深度图像将抓取检测结果转换为6DOF抓取姿势,并通过轨迹规划器执行抓取。
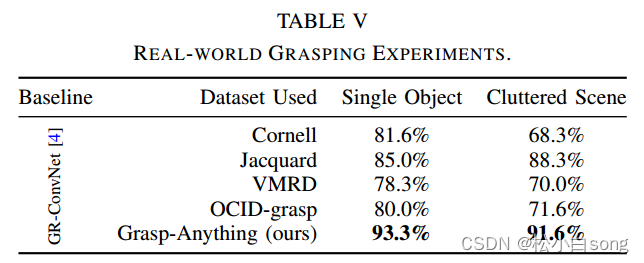
- 评估在单个对象和杂乱场景中进行,每个场景实验60次,网络权重分别来自Grasp-Anything、OCID-grasp、VMRD和Jacquard数据集。
-
结果:
实验表明,使用Grasp-Anything数据集训练的GR-ConvNet在单个对象和杂乱场景中的抓取成功率最高,分别为93.3%和91.6%。
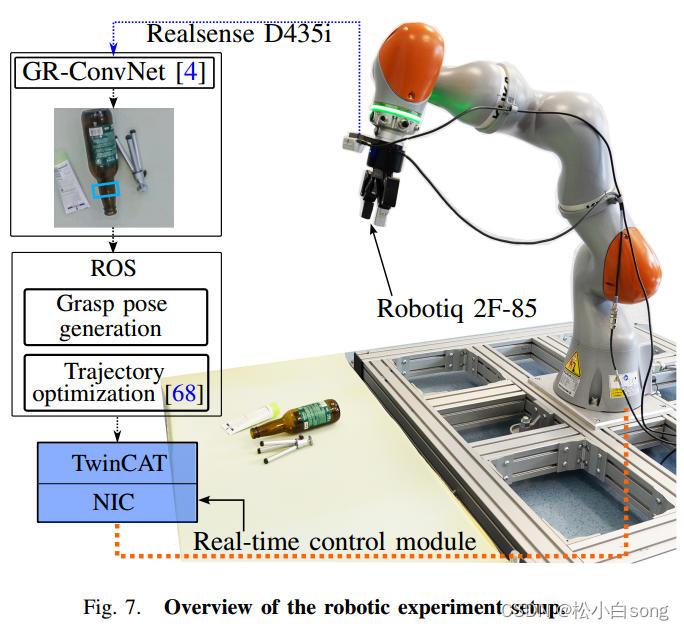
图7展示了用于评估抓取检测的机器人实验设置,包括以下几个组件:
- Realsense D435i:一款深度相机,用于捕捉3D图像和深度信息,帮助识别对象的形状和位置。
- Robotiq 2F-85:一款两指机械手,负责执行抓取任务。
- 实时控制模块:通过ROS(机器人操作系统)实现抓取姿势和轨迹优化的实时控制。
- GR-ConvNet:用于抓取检测的神经网络,将检测到的抓取结果转换为6DOF(六自由度)抓取姿势。
- 轨迹优化:通过深度图像和路径规划算法(如NIC和TwinCAT)计算出最佳的抓取路径和动作。
C. 野外抓取检测
- 结果可视化:
- 在实际办公场景中,使用不同数据集训练的GR-ConvNet进行抓取检测,结果表明,Grasp-Anything提高了抓取检测的质量。
- 展示了使用Grasp-Anything训练的GR-ConvNet在互联网上随机图像上的抓取检测示例,抓取姿势的质量和数量均良好。

图8. 定性结果
图8展示了在实际办公场景中,使用不同数据集训练的GR-ConvNet进行抓取检测的定性结果:
- 输入图像:一个日常办公场景的图像,包含多个需要检测和抓取的对象。
- Grasp-Anything:使用Grasp-Anything数据集训练的GR-ConvNet检测到的抓取姿势,结果显示出较高的抓取质量。
- Jacquard:使用Jacquard数据集训练的GR-ConvNet检测结果,相比之下,抓取质量稍差。
- Cornell、VMRD和OCID-grasp:分别使用Cornell、VMRD和OCID-grasp数据集训练的GR-ConvNet检测结果,抓取质量依次降低。

图9. 野外抓取检测
图9展示了使用Grasp-Anything数据集训练的GR-ConvNet在随机互联网图像和其他数据集图像上的抓取检测示例:
- 上排:从其他数据集中随机选择的图像,包括NBMOD、YCB-Video和GraspNet的数据集。检测结果显示,预训练的GR-ConvNet在这些图像上的抓取姿势质量较高。
- 下排:随机从互联网上获取的图像,展示了GR-ConvNet在不同场景和对象上的抓取检测能力,抓取姿势质量和数量均表现良好。
D. 讨论
-
零样本实验:
- 结果表明,Grasp-Anything可以作为抓取检测的挑战性数据集,因为在测试中,使用该数据集训练的网络准确率较低。
- 跨数据集实验显示,使用Grasp-Anything进行训练可显著提高在其他数据集上的表现。
- 机器人实验表明,使用合成数据集Grasp-Anything训练的模型在实际机器人抓取任务中表现优于其他数据集。
-
改进方向:
- 数据集创建耗时且依赖于商业ChatGPT API,但未来研究可以重用提供的资源(图像、提示等)。
- 目前数据集缺乏3D点云数据,这是由于文本到点云或图像到点云的基础模型尚未取得理想结果。
- 数据集包含的文本提示可以促进语言驱动的抓取和人机交互等研究方向。
四、总结
我们提出了grip - anything,一个新的大规模语言驱动数据集,用于机器人抓取检测。我们的分析表明,“任意抓取”包含了许多对象和自然场景安排。用真实机器人在不同网络和数据集上的实验表明,我们的抓取-任何数据集比相关数据集有明显的改进。通过结合自然场景描述,我们希望我们的数据集可以作为语言驱动抓取检测的基础数据集。

















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









