






©作者 | iMoon-Lab
单位 | 清华大学
来源 | 新智元
YOLO(You Only Look Once)系列是目标检测领域中的主流方法,以其高效性和实时性而著称。然而,现有的 YOLO 模型在处理跨层特征融合和复杂的高阶特征关系时存在局限,无法充分捕捉跨位置和跨尺度的复杂特征关联。
为了解决这一难点,清华大学提出了 Hyper-YOLO:一种基于超图计算的目标检测方法。Hyper-YOLO 首次将超图计算集成到目标检测网络,对特征图中的复杂高阶关联进行建模,实现了高阶信息的跨层次和跨位置传播。

论文标题:
Hyper-YOLO: When Visual Object Detection Meets Hypergraph Computation
论文地址:
https://arxiv.org/abs/2408.04804
项目地址:
https://github.com/iMoonLab/Hyper-YOLOv1.1
零代码平台:
http://hyperyolo.gaoyue.org:28501/#/predict
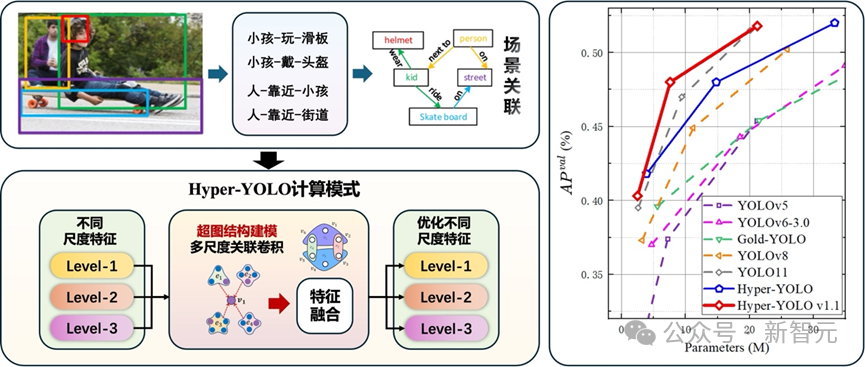

使用超图计算结合 YOLO,性能在各种规模模型中都达到顶尖,在 COCO 数据集上的表现明显优于其他模型,尤其是对中小目标提升更加显著。其中,相比于最新的 YOLOv9-T、YOLO11-S,同规模的 Hyper-YOLO 分别实现了 2% 和 1% 的平均精度提升。

目标检测的困境
近年来,随着深度学习的快速发展,YOLO(You Only Look Once)系列模型凭借其高效的单阶段检测架构,在目标检测领域中脱颖而出。YOLO 模型通过将目标检测简化为回归问题,在保持高精度的同时实现了实时检测能力,受到了广泛关注和应用。
然而,随着应用场景的复杂化,现有的YOLO模型在处理跨层次特征融合和高阶特征关系时暴露出了一定的局限性。
下图展示了几个典型的案例(YOLOv8 为例)。在打网球的场景中,现有模型将网球拍误判为了棒球棒;在冲浪的场景中,现有模型将冲浪板误判为了风筝。这种错误正是由于现有的模型难以捕捉视觉对象之间的复杂关系。
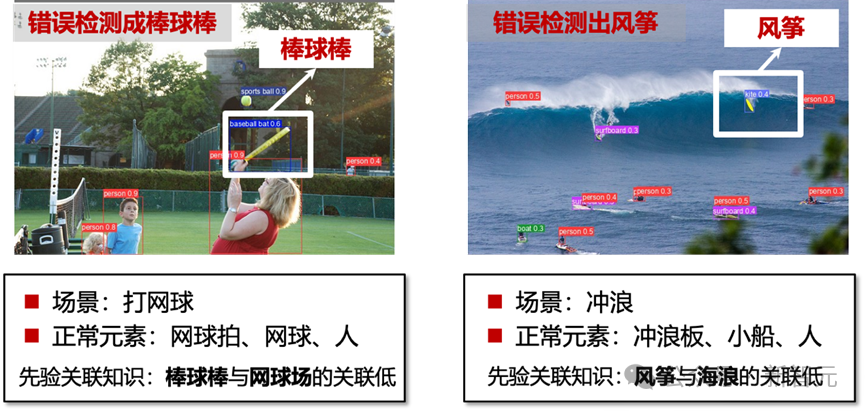
因而,不同目标间的高阶语义关联推理限制了目标检测的性能。

高阶关联的建模方法
为了解决这些问题,学术界一直在探索更加先进的模型设计与优化方法。其中,超图计算作为一种能够捕捉多方关系的数学工具,逐渐被应用于包括社交网络、脑网络等复杂数据结构分析中。

超图覆盖了多种关联,是复杂关联计算的有效方法。在 Hyper-YOLO 中,作者首次将超图计算引入目标检测领域,以实现视觉高阶语义关联的建模与学习。
模型效果
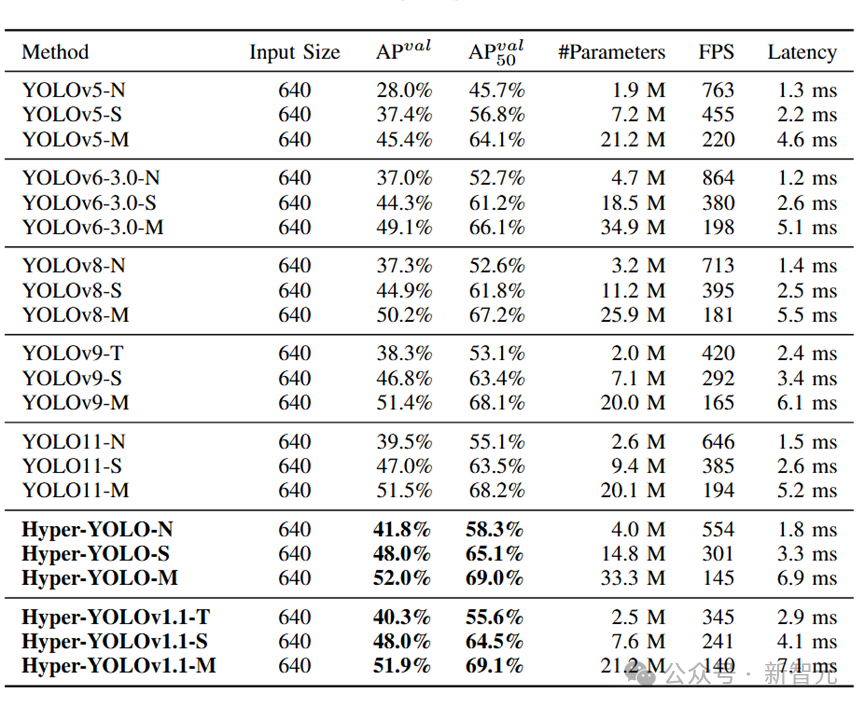
该工作在 COCO 数据集上进行了丰富的实验。Hyper-YOLOv1.1 提供了 3 种规模的版本(Tiny, Small , Medium),在对比实验中,均明显优于最新的 YOLO 模型。
其中,Tiny 版本的平均精度(mAP)指标相比于 YOLOv8、YOLOv9、YOLO11 的同规模版本分别提升 3.0%、2.0%、0.8%;Small 版本的 mAP 指标相比于 YOLOv8、YOLOv9、YOLO11 的同规模版本分别提升 3.1%、1.2%、1.0%。此外,对于骨干网络、Kernel 大小、特征增强策略、超图构建策略的消融实验证明了所提出的方法的先进性。
以下两图为 YOLOv8、Hyper-YOLO 在目标检测和实例分割任务下的可视化结果。


下图为使用高阶关联学习对特征图增强前后的可视化图(通过 HyperC2Net 前后的特征图)。

上述实验结果证明,Hyper-YOLO 具有目前最先进的检测性能,尤其对场景中不同视觉对象的高阶关系具有更准确的理解能力。
Hyper-YOLO零代码平台
智能媒体与认知实验室还推出了一款基于 Hyper-YOLO 的零代码训练平台。在该平台上,无需配置环境、修改配置文件等繁琐操作,既可以一键上传图像利用训练好的 Hyper-YOLO 模型进行推理,也可以上传数据集自定义训练、直观展示训练过程 (推荐使用 PC 端 chrome/Edge 浏览器)。
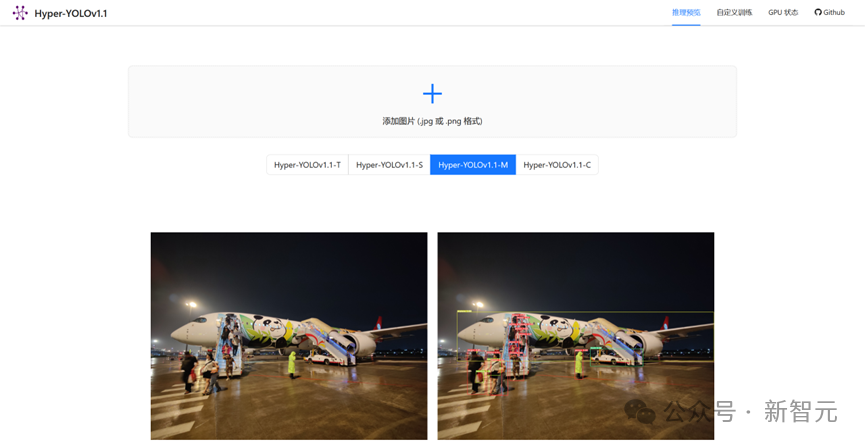
项目支持自定义训练。

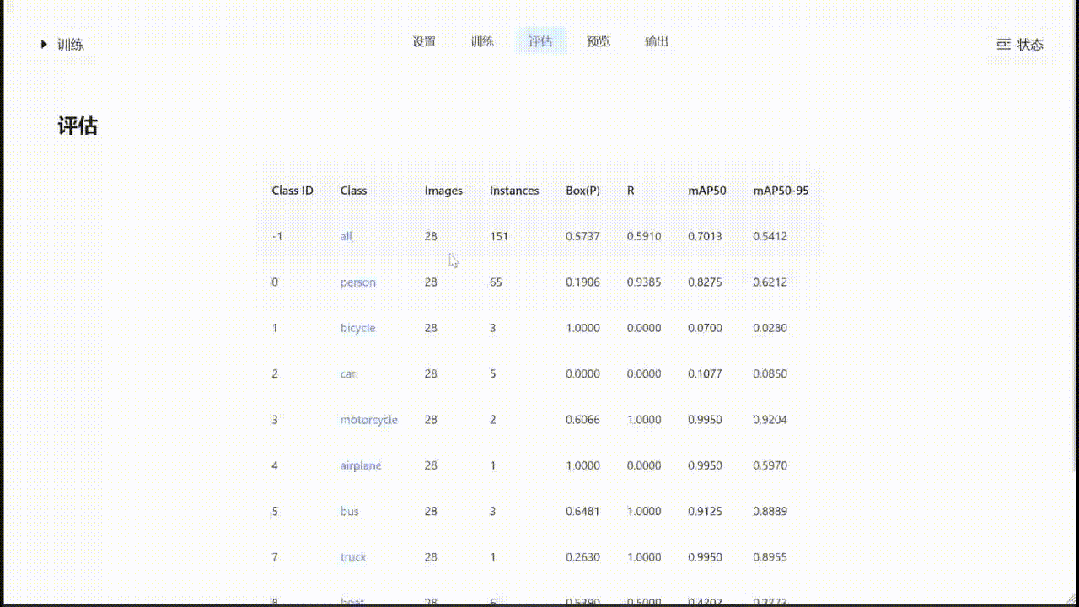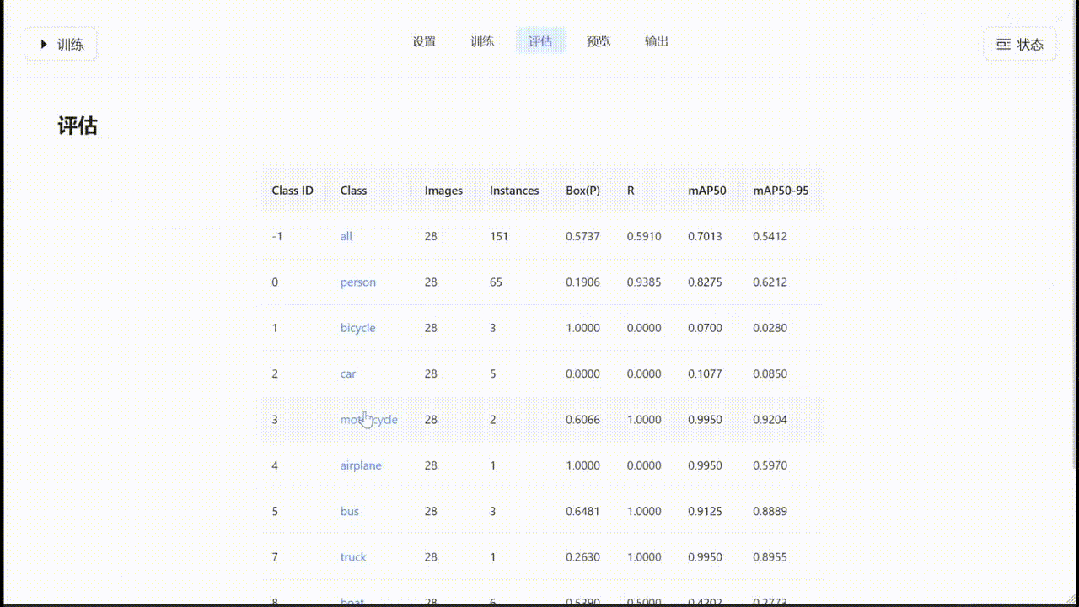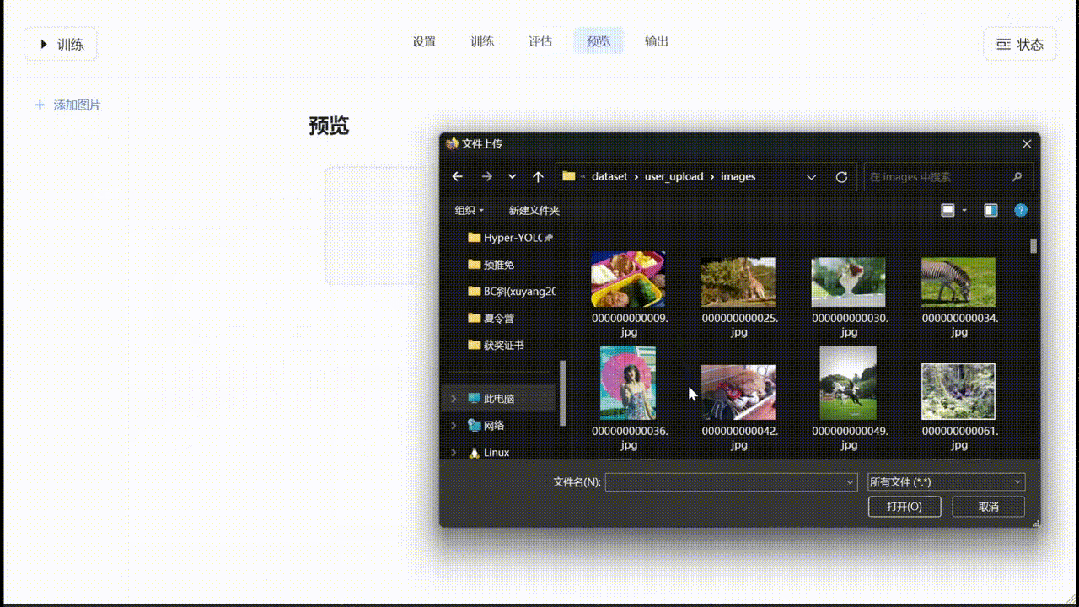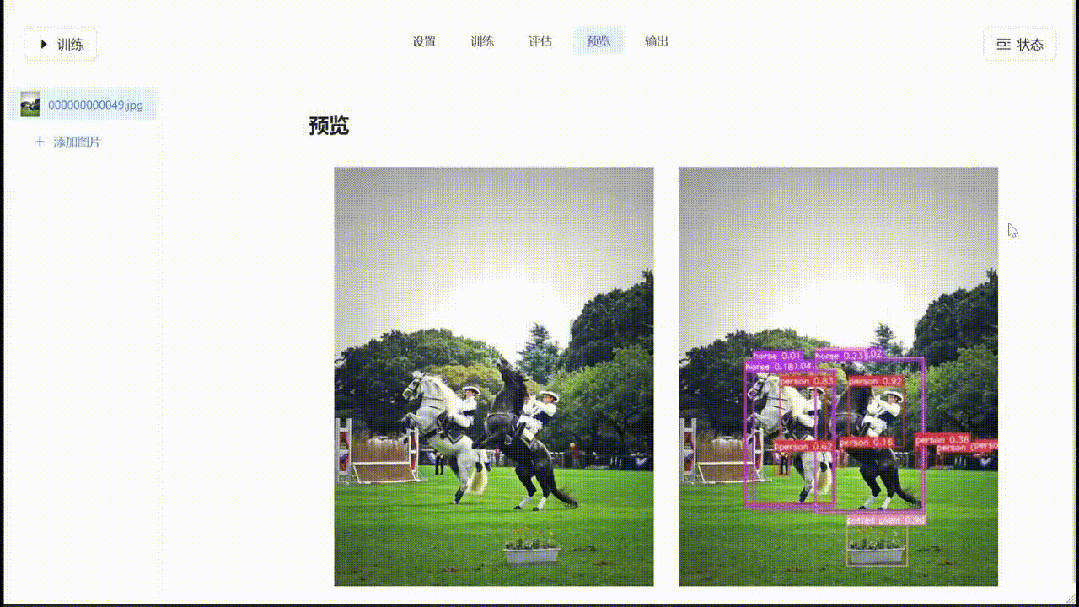
在训练完成后,可以对验证数据进行推理和评估,并可视化检测结果:

方法概述
超图计算
超图是图的推广形式,是一种高效的特征表示学习方法。在超图中,一条超边可以连接多个顶点,从而表示对象之间的高阶关联。超图神经网络作为超图计算的核心方法,通常包含以下几个步骤:
1. 从原始数据构建超边
2. 从顶点到超边的消息聚合(超边卷积)
3. 从超边到顶点的消息分发(节点卷积)
超图神经网络由于其灵活性和丰富的表达能力,广泛应用于社交网络分析、生物信息学、推荐系统等领域,能够更有效地建模和分析复杂的多层次数据关联。
Hyper-YOLO整体架构
Hyper-YOLO 继承了典型的 YOLO 架构,骨干网络通过引入混合聚合网络(MANet)来增强特征提取能力,从五个特征层中获取信息。
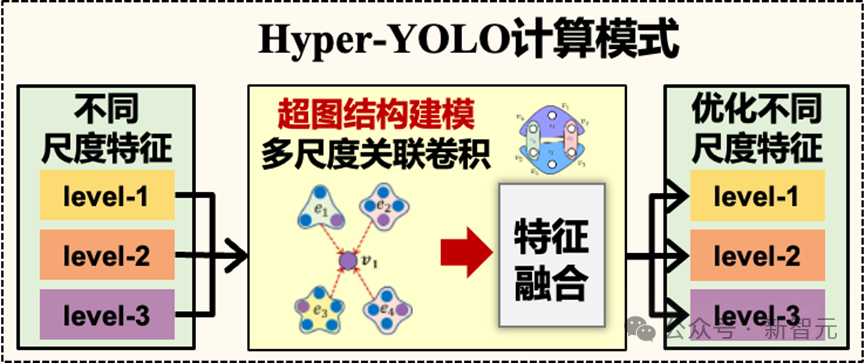
颈部网络(Neck)采用基于超图的跨层次和跨位置表示网络(HyperC2Net),通过超图计算集成多尺度特征,实现高阶信息的跨层次和跨位置传播,从而生成适用于目标检测的语义特征,显著提升模型的检测性能。
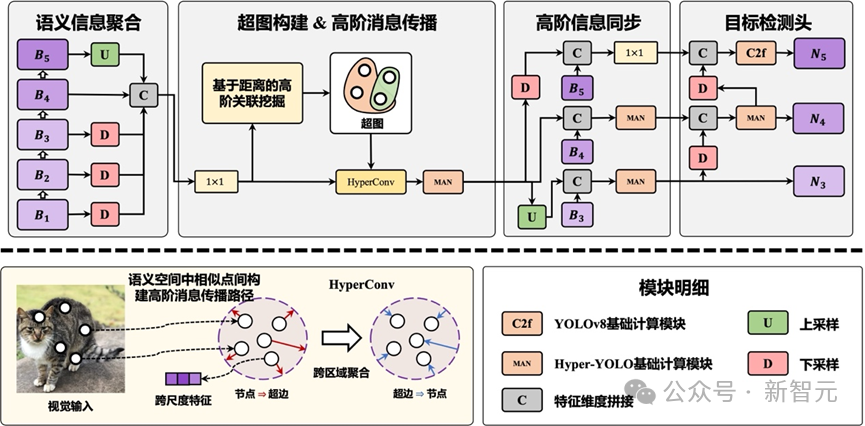
基于超图的跨层次和跨位置表示网络
在传统 YOLO 模型中,颈部为连接骨干网络和预测头之间的部分,通常采用类似 PANet 的结构,承担多尺度特征提取与融合的功能。虽然这类结构能够进行一定的多尺度特征融合,但直接的信息交互局限在相邻层之间。
而基于超图的跨层次跨位置表示网络(Hypergraph-Based Cross-Level and Cross-Position Representation Network, HyperC2Net)则突破了这一瓶颈,主要过程如下:
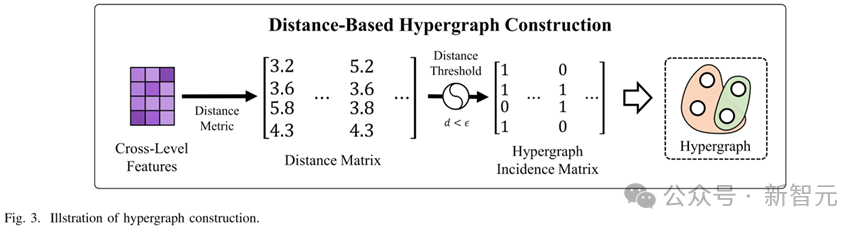
1. 超图构建:HyperC2Net 将来自不同层次的特征图进行拼接,形成跨层次的视觉特征集合。然后通过计算特征点之间的距离,构建一个超图,其中每个超边连接多个顶点,代表多个特征点之间的高阶关系。超图能够表达跨层次和跨位置的复杂关系,而非简单的相邻层信息融合。
2. 超图卷积:在构建超图后,HyperC2Net 利用超图卷积在特征图上进行消息传播。通过这种方式,不同位置和层次的特征点可以相互传递信息,建模特征点之间的高阶关联,增强了模型对于复杂场景中目标的识别能力。特别是在跨位置特征交互方面,相比于传统的卷积操作,超图卷积能够捕捉到更广泛和复杂的特征关联。

总结
Hyper-YOLO 通过引入超图计算方法,突破了传统 YOLO 模型在多尺度特征融合上的局限。超图的高阶关联建模能力使得 HyperC2Net 能够在跨层次和跨位置的信息传播中表现出色,不仅在特征点之间实现高效的信息聚合和分发,还通过跨层次的消息传递显著提升了目标检测性能,尤其在处理复杂场景和多目标检测任务中表现优异。

参考文献
[1] Feng Y, Huang J, Du S, et al. Hyper-YOLO: When visual object detection meets hypergraph computation[J]. arXiv preprint arXiv:2408.04804, 2024.
[2] Feng Y, You H, Zhang Z, et al. Hypergraph neural networks[C]//Proceedings of the AAAI conference on artificial intelligence. 2019, 33(01): 3558-3565.
[3] Gao Y, Feng Y, Ji S, et al. HGNN+: General hypergraph neural networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(3): 3181-3199.
推荐阅读
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!


















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









