







使用超图计算的方法来进行高阶特征的交互。
论文链接:https://arxiv.org/pdf/2408.04804v1

摘要
我们介绍了一种新的物体检测方法Hyper-YOLO,该方法集成了超图计算来捕捉视觉特征之间的复杂高阶相关性。传统的YOLO模型虽然强大,但在其颈部设计中存在局限性,这限制了跨层级特征的整合以及高阶特征间相互关系的利用。为了解决这些挑战,我们提出了基于超图计算的语义收集与分散框架(Hypergraph Computation Empowered Semantic Collecting and Scattering, HGCSCS),它将视觉特征图转换到语义空间,并构建一个超图来进行高阶消息传播。这使得模型能够同时获取语义和结构信息,超越了传统以特征为中心的学习方式。Hyper-YOLO在其主干网络中集成了提出的混合聚合网络(MANet)以增强特征提取,并在其颈部引入了基于超图的跨层级和跨位置表示网络(Hypergraph-Based Cross-Level and Cross-Position Representation Network, HyperC2Net)。HyperC2Net在五个尺度上运行,并摆脱了传统的网格结构,允许在层级和位置之间进行复杂的高阶交互作用。这些组件的协同作用使Hyper-YOLO成为各种规模模型中的前沿架构,这一点在COCO数据集上的卓越表现得到了证明。具体来说,Hyper-YOLO-N在APval上显著超过了先进的YOLOv8-N和YOLOv9-T,分别提高了12%和9%的APval。源代码可在以下网址访问:https://github.com/iMoonLab/Hyper-YOLO。
1、介绍
YOLO系列作为物体检测领域的主要流派之一脱颖而出,提供了多种优势以满足不同应用场景的需求。YOLO的架构主要由两个部分组成:主干网络和颈部。主干网络用于特征提取,并已得到广泛研究;而颈部则负责多尺度特征的融合,为不同大小的物体检测提供了坚实的基础。本文特别强调颈部的作用,因为它对于提高模型在不同尺度下检测物体的能力至关重要。
当前的YOLO模型通常采用PANet作为其颈部结构,该结构通过自顶向下和自底向上的路径促进不同尺度信息的全面融合。然而,PANet的能力主要局限于相邻层之间的特征融合,并不足以充分解决跨层级特征的集成问题。相反,以Gold-YOLO为代表的聚集-分散颈部设计促进了层间的信息交换,但仍未能实现特征图内的跨位置交互。此外,它没有彻底探索特征间的关系潜力,特别是那些涉及高阶相关性的关系。高阶相关性指的是不同尺度、位置和语义级别的特征之间存在的复杂且往往是非线性的关系,这对于理解视觉数据中深层次的上下文和交互至关重要。注意到低级视觉特征及其相关性与物体检测任务紧密相关。将这些基本特征与高级语义信息相结合对于准确识别和定位场景中的物体至关重要。探索低级特征背后用于语义分析的高阶相关性仍然是许多计算机视觉任务中一项具有挑战性但又至关重要的课题。这一现象——即挖掘此类高阶关系常常被忽视——可能会限制视觉任务的性能。
实际上,超图常被用来表示复杂的高阶相关性,因为它们比简单图具有更强的表达力。简单图中的边只能连接两个顶点,这极大地限制了其表达能力;而在超图中,超边可以连接两个或更多顶点,从而使模型能够更好地模拟更为复杂的高阶关系。与简单图相比,超图能够捕捉实体间的更丰富的一组交互作用,这对于需要理解复杂和多方关系的任务至关重要,例如在计算机视觉中的物体检测,其中特征图间的跨层级和跨位置相关性是关键。
不同于大多数先前的工作专注于增强特征提取的主干网络,我们提出了基于超图计算的语义收集与分散框架(Hypergraph Computation Empowered Semantic Collecting and Scattering, HGC-SCS)。该框架巧妙构思,旨在通过将视觉主干网络提取的特征图转换到抽象的语义空间,并随后构建复杂的超图结构来增强这些特征图。超图充当了一个媒介,使特征在语义空间内实现高阶消息传播。这种方法赋予了视觉主干网络同时吸收语义信息和复杂结构信息的双重能力,从而克服了传统以语义特征为中心的学习的局限性,并将性能提升至新的高度。
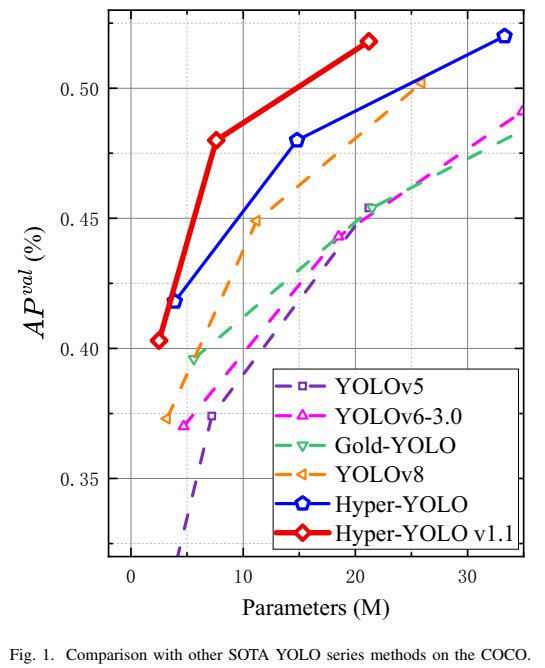
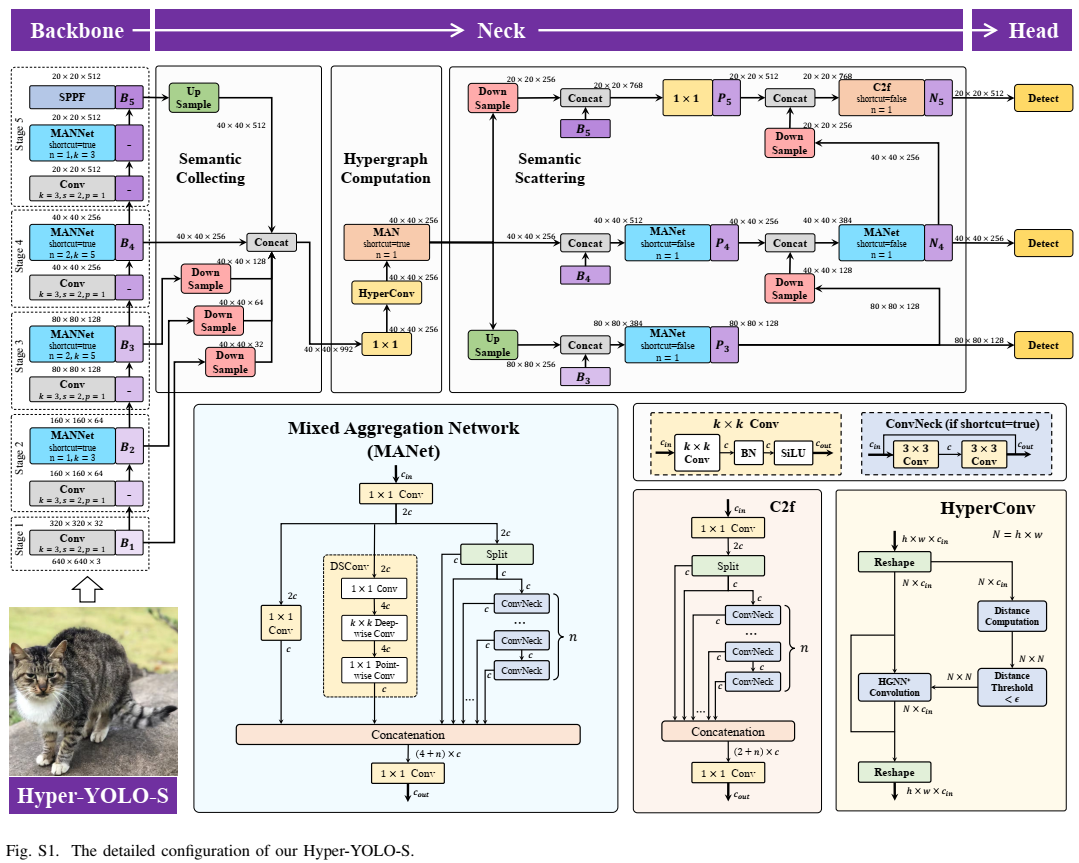
基于上述HGC-SCS框架,我们介绍了Hyper-YOLO,这是一种基于超图计算的新YOLO方法。Hyper-YOLO首次将超图计算集成到视觉目标检测网络的颈部组件中。通过对从主干网络提取的特征图建模其内在的复杂高阶关联性,Hyper-YOLO显著提高了物体检测性能。就主干网络架构而言,Hyper-YOLO集成了混合聚合网络(MANet),该网络融合了三种独特的基础结构以丰富信息流并增强特征提取能力,建立在YOLOv8的基础上。在颈部方面,利用所提出的HGC-SCS框架,我们实现了基于超图的跨层级和跨位置表示网络(Hypergraph-Based Cross-Level and Cross-Position Representation Network, HyperC2Net)。与传统颈部设计不同,HyperC2Net在五个不同的尺度上融合特征,同时摆脱了视觉特征图的网格结构,从而促进了层级和位置之间的高阶消息传播。主干网络和颈部的综合增强使得Hyper-YOLO成为一个开创性的架构。实验结果(图1)表明,在COCO数据集上,它在性能方面表现出显著的优势,证实了这种复杂方法在推进物体检测领域方面的有效性。我们的贡献可以总结如下:
-
我们提出了基于超图计算的语义收集与分散框架(HGC-SCS),增强了视觉主干网络对高阶信息的建模和学习能力。
-
借助提出的HGC-SCS框架,我们开发了HyperC2Net,这是一个物体检测颈部,能够在语义层和位置之间实现高阶消息传递。HyperC2Net显著提高了颈部提炼高阶特征的能力。
-
我们提出了混合聚合网络(MANet),该网络集成了三种类型的块以丰富信息流,从而增强了主干网络的特征提取能力。
-
我们介绍了Hyper-YOLO,该模型通过集成超图计算增强了对高阶信息的感知能力,从而在物体检测方面取得了进步。具体来说,我们的Hyper-YOLO-N在COCO数据集上APval指标上实现了显著提升,与YOLOv8-N相比提高了12%,与YOLOv9-T相比提高了9%。
2、相关工作
A. YOLO系列目
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









