








Hyper-YOLO:当视觉对象检测遇到超图计算
杨帆,黄江刚,杜少义,IEEE高级会员,应世辉,翁军海,李一鹏,丁国光,吉荣荣,IEEE高级会员,高悦,IEEE高级会员
摘要——我们介绍了一种新的对象检测方法Hyper-YOLO,它将超图计算集成到视觉特征中以捕获复杂的高阶相关性。传统的YOLO模型虽然强大,但在颈部设计上存在限制,无法整合跨层特征和利用高级别特征之间的关系。为了应对这些挑战,我们提出一种基于超图计算的语义收集和散射(HGC-SCS)框架,该框架将视觉特征映射到一个语义空间,并构建了一个用于高阶消息传播的超图。这使得模型能够获取语义和结构信息,超越了传统关注于特征的学习方式。Hyper-YOLO在其主干中引入了混合聚合网络(MANet),增强了特征提取,在其颈部引入了基于超图的跨级和跨位置表示网络(HyperC2Net)。HyperC2Net在五个尺度上运行并摆脱了传统的网格结构,允许在级别和位置之间进行复杂而精细的高阶交互。这种组件协同作用使Hyper-YOLO成为各种规模模型中的前沿架构,如通过在COCO数据集上的出色性能所证明的那样。具体来说,Hyper-YOLO-N显著优于先进的YOLOv8-N和YOLOv9-T,分别提高了12%和9%的APval。源代码可在https://github.com/iMoonLab/Hyper-YOLO访问。
关键词——对象检测、超图、超图神经网络、超图计算
一、引言
YOLO系列 [1]-[11] 在目标检测领域脱颖而出,为这些多样化的应用提供了几个优势。YOLO的架构由两个主要组件组成:主干[7],[12]-[14]和颈部[10],[15],[16]。虽然主干设计用于特征提取并已广泛研究,但颈部负责多尺度融合。
特征,为检测各种大小的对象提供了一个坚实的基础。本文特别强调了颈部的重要性,它在增强模型的跨尺度对象检测能力方面至关重要。
当前的YOLO模型采用了PANet [16]作为其颈部,该方法利用了自上而下和自下而上的路径来促进不同尺度信息的全面融合。然而,PANet的主要能力是融合相邻层之间的特征,并不足以解决跨级特征集成的问题。相比之下,Gold-YOLO [10]等采用的聚集-分发颈设计促进了各层间的信息交换,但仍然无法充分实现特征图内跨位置交互。此外,它并未充分探索特征之间潜在的关系,特别是高阶相关性方面的潜力。高阶相关性是指在不同尺度、位置以及
第 2 页
语义层次,这些对于理解视觉数据的深层上下文和交互至关重要。注意到低级视觉特征及其相关性的协同表示在对象检测任务中起着关键作用。将这些基本特征与高级语义信息相结合是准确识别和定位场景内物体的关键。对低级特征下隐藏的高阶关系进行探索仍然是许多计算机视觉任务中的一个具有挑战性但又至关重要的主题。这种现象,在于挖掘此类高阶关系通常被忽视,可能限制了视觉任务的表现。
在实践中,超图 [17], [18] 通常用于表示复杂的高阶相关性,因为它们比简单图形具有更强的表达能力。而简单图形中的边仅限于连接两个顶点,从而极大地限制了其表达力;而在超图中,超边可以连接两个或多个顶点,因此能够建模更复杂和多向的关系。与简单图形相比,超图可以捕获多个实体之间的更丰富的交互关系,这对于需要理解复杂且多向关系的任务至关重要,在计算机视觉中的对象检测任务中尤为如此,其中特征映射之间跨层、跨位置的相关性是至关重要的。
不同于大多数以前的工作,专注于增强特征提取的主干,我们提出了一种Hypergraph Computation Empowered Semantic Collecting and Scattering (HGC-SCS) 框架。该框架巧妙地将视觉骨干网络提取的特征映射到抽象语义空间中,并通过构建复杂的超图结构来增强这些特征。超图作为高阶消息传播在语义空间中的媒介,使得视觉骨干网络能够同时吸收语义和复杂结构信息,从而克服了传统基于语义特征的学习方法的局限性并超越其传统的性能边界。
基于上述HGC-SCS框架,我们引入了Hyper-YOLO,一种基于超图计算的新型YOLO方法。Hyper-YOLO首次将超图计算集成到视觉目标检测网络的颈部组件中。通过建模从主干提取特征映射中的复杂高阶关联,Hyper-YOLO显著提升了对象检测性能。在骨干架构方面,Hyper-YOLO整合了混合聚合网络(MANet),该网络融合了三个独特的基础结构来丰富信息流并增强特征提取能力,建立在YoloV8提供的基础上。在颈部领域,借助提出的HGC-SCS框架,我们实现了多尺度特征融合颈称为超图基跨层和跨位置表示网络(HyperC2Net)。与传统的颈部设计相比,HyperC2Net同时打破了视觉特征映射网格结构,并且能够实现对不同规模特征的融合,从而促进高级
消息传播的订单在层次和位置上。Hyper-YOLO作为突破性架构,结合了两个位置(主干和颈部)的增强效果。COCO数据集上的实验结果 (图 1) 表明其性能具有显著优势,并证明了该复杂方法的有效性,在目标检测领域取得了进步。我们的贡献可以总结为:
我们提出了一种Hypergraph计算增强的语义收集和散射框架(HGC-SCS),通过高阶信息建模与学习来增强视觉骨干。
2)利用提出的HGC-SCS框架,我们开发了HyperC2Net,一种有助于在整个语义层和位置上进行高阶消息传递的对象检测颈部。与传统的颈部相比,HyperC2Net显著提高了颈部提取高阶特征的能力。
我们提出了一种混合聚合网络 (MANet),它包含三种类型的块,以丰富信息流,并增强主干的特征提取能力。
我们提出Hyper-YOLO,它通过超图计算增强了模型的高阶信息感知能力,并提高了对象检测性能。具体来说,我们的Hyper-YOLO-N在APval上取得了显著改进,在COCO数据集上的提升幅度分别为YOLOv8-N和YOLOv9-T的12% 和9% 。
II. 相关工作
A.YOLO系列对象检测器
YOLO系列一直是实时目标检测的基石,从YOLOv1单阶段检测到YOLOv8性能优化模型。每个迭代版本,从YOLOv4结构改进到YOLOv7的E-ELAN主干,都带来了显著的进步。YOLOX引入了无锚点检测,并通过其Gather-and-Distribute机制增强了特征融合。尽管出现了RT-DETR和其他检测器,但YOLO系列仍然盛行,部分原因是其有效使用CSPNet、ELAN和改进的PANet或FPN进行特征集成,以及来自YOLOv3和FCOS的复杂预测头。YOLOv9引入可编程梯度信息和通用高效层聚合网络来最小化深度网络传输中的信息损失。基于这些YOLO方法,本文提出Hyper-YOLO,这是一种先进的方法,利用超图计算增强YOLO框架的复杂相关学习能力。Hyper-YOLO旨在改善层次特征的学习与整合,推动对象检测性能的极限。
B. 超图学习方法
超图 [17], [18] 可以用来捕捉这些复杂的、高阶的关联。超图,由于它们
第 3 页
多节点之间的超边,擅长建模复杂的联系,在社会网络分析 [22][23]、药物靶点相互作用建模 [24][25] 和脑网络分析 [26][27] 等领域应用广泛。超图学习方法作为一种强大的工具,能够捕捉数据中的复杂和高阶相关性,而传统的基于图的方法可能无法充分表示这些关系。如高志伟等人的研究[17]中所讨论的,超边的概念允许多个节点同时交互,从而促进了对这些复杂联系的建模。超图神经网络 (HGNN) 利用这些关系,通过谱方法直接从超图结构进行学习。在此基础上,通用超图神经网络(HGNN+)引入空间方法来实现高阶消息在顶点间的传播,进一步扩展了超图学习的能力。尽管取得了上述进步,但超图学习在计算机视觉任务的应用仍相对未被探索,特别是在模型和学习高阶关联方面。本文将探讨如何利用超图计算来进行对象检测任务,并旨在通过整合由超图建模的细微关系信息来提升分类和定位精度。
III. 超图计算赋能语义收集和分散框架
不同于计算机视觉中的表示学习仅处理视觉特征,这些超图计算方法 [18], [28] 同时处理特征和高阶结构。大多数超图计算方法依赖于固有的超图结构,在大多数计算机视觉场景中无法获得。这里我们介绍计算机视觉中的超图计算的通用范式,包括超图构建和超图卷积。给定神经网络提取出的特征映射X,采用超图构造函数f:X→G来估计语义空间中特征点之间的潜在高阶相关性。然后利用谱或空间超图卷积方法通过超图结构在特征点之间传播高阶消息。生成的高阶特征称为Xhyper。将高阶关系信息整合到Xhyper中,该超图计算策略解决了原始特征映射X中存在的高阶相关性的不足。由此产生的混合特征映射,用作X'表示。这个合成过程最终产生一个语义增强的视觉表示X′,它从语义和高阶结构两个角度提供了更全面的视觉特征表示。
在这里,我们为计算机视觉中的超图计算设计了一个通用框架,称为Hypergraph Computation Empowered Semantic Collecting and Scattering (HGC-SCS) 框架。给定从CNN [29]-[34] 或其他主干提取的特征映射,我们的框架首先收集这些特征并将其融合以构建混合
特征包X在语义空间中混合。第二步,我们估计潜在的高阶相关性以构建语义空间中的超图结构。为了充分利用这些高阶结构信息,一些相关的超图计算方法 [18], [28] 可以被采用。这样,可以生成具有高阶感知特性的特征Xhyper,它结合了高阶结构和语义信息。最后一步,我们将高阶结构信息散射到每个输入特征映射上。HGC-SCS框架可以表示为以下公式:
(XMixed←COLLECTING{X1,X2,···} Xhyper=HyperComputation(XMixed)//HIGH-ORDER LEARNING1,Xn2,···} ←CATTERING{p(Xhyper,X1),0(Xhyper,X2),···} WHERE{X1,X2,···}表示从视觉主干生成的基本特征图。"HyperComputation" 表示第二步,包括超图构建和超图卷积,捕捉语义空间中的潜在高阶结构信息,并产生具有高阶感知的特征Xhyper。在最后一行中,((·))表示特征融合函数。{Xs1,X🟥2,···}表示增强的视觉特征图。接下来我们将介绍我们HGC-SCS框架的一个实例,在目标检测任务中称为HyperC2Net。
IV、方法
在本部分中,我们首先介绍YOLO的符号和Hyper-YOLO提出的框架。接下来,我们将详细介绍我们的Hyper-YOLO所提出的两个核心模块,包括MANet的基本块以及Hy-perC2Net的颈部。最后,我们分析了Hyper-YOLO与其他YOLO方法之间的关系。
A. 前言
YOLO系列方法 [1]-[5], [7], [8], [21], [35]-[39] 通常由两个主要组件组成:主干和颈部。 主干[40][13]负责提取基本视觉特征,而颈部[15][16][19]则有助于多尺度特征的融合以进行最终的目标检测。本文提出针对这两个组件的具体增强策略。为了便于在本论文中描述,我们用{N3, N4, N5}表示颈部三个输出规模,分别对应小、中、大尺度检测。 在主干的特征提取阶段,进一步将其分为五个阶段: {B1, B2, B3, B4, B5} ,代表不同语义级别的特征。数字越大表明该特征是由网络更深层提取出的更高层次语义特征。更多细节请参见A部分。
B. Hyper-YOLO概述
我们的Hyper-YOLO框架保留了典型的YOLO方法的整体架构,包括骨干和颈部,如图S1所示。给定一张图像,Hyper-YOLO的骨干利用提出的MANet作为其核心计算模块,从而增强了
第 4 页
本文提出了一种新颖的Hyper-YOLO架构,该架构借鉴了YOLOv8 [8] 中常规C2f模块的功能辨别能力。与传统的YOLO体系结构不同,Hyper-YOLO采用了一个由五个主要特征集{B1、B2、B3、B4和B5}组成的集合。在一种新的步长中,基于超图计算理论的Hyper-YOLO颈部(HyperC2Net)将这些五重特征集中跨层和跨位置的信息整合在一起,最终生成三个不同尺度上的最终语义特征{N3、N4和N5}。这些层次化的语义特征随后被用于最后的目标检测任务。
C. 混合聚合网络
对于我们的Hyper-YOLO的骨干,为了增强基础网络的特征提取能力,我们设计了混合聚合网络(MANet),如图2所示。该架构协同融合三种典型的卷积变体:用于通道级特征重新校准的1×1旁路卷积、用于高效空间特征处理的深度可分离卷积 (DSConv),以及用于提升特征层次集成的C2f模块。这种汇聚在训练阶段产生更丰富和丰富的梯度流,显著放大了基底中包含的语义深度。
在五个关键阶段的特征。我们的MANet可以表示为:
其中Xmid的通道数为2c,而每个X1、X2,…,X4+n都具有通道数c。最后,我们通过一个连接操作和随后的一个a×1卷积将三种类型的特征的语义信息融合压缩生成Xout,其通道数为
2c,如下:
D. 基于超图的跨层和跨位置表示网络
至于我们Hyper-YOLO的颈部,在这一小节中,为了全面融合跨层和跨位置的信息
第 5 页
从主干中获取信息,我们进一步提出基于超图的跨层和跨位置表示网络(HyperC2Net),如图 4 所示。HyperC2Net 是所提出的 HGC-SCS 框架的一个实现,能够捕获语义空间中的潜在高阶相关性。
1)超图构建:如图S1所示,我们的骨干被分割成五个离散阶段。这些阶段的特征映射表示为{B1、B2、B3、B4和B5}。为了利用超图计算来阐明基础特征之间的复杂高阶关系,我们通过执行基特征五元组的通道级拼接来启动过程,从而合成跨级别视觉特征。通常由其顶点集V和超边集E定义一个常规的超图G={V,E}。在我们的方法中,我们将基于网格的视觉特征分解以构成超图的一个顶点集V。为了建模语义空间内的邻域关系,使用距离阈值从每个特征点构造e球体作为超边,如图3所示。e球体是一个包含所有距中心特征点一定距离阈值的所有特征点的超边。整个超边集合的构建可以定义为E={ball(v,e)|v∈V},其中ball(v,e)={u|||xu−xv||d<e,u∈V}指示指定顶点v的邻居顶点集。||x-y||d是距离函数。在计算中,超图G通常用它的发生矩阵H表示。
2)超图卷积:为了在超图结构上实现高阶消息传递,我们利用了一种典型的空间域超图卷积 [18] ,并增加了额外的残差。
顶点如下:NBNBiiii连接以对顶点特征进行高级学习 特征用于检测
其中,Nv (e) 和Ne (v) 是两个邻域指示函数,在 [18] 中定义:Nv (e) = {v | v∈ e , v∈V } ,Ne (v) ={e | v∈ e , e∈E } 。Θ是一个可训练的参数。为了计算方便,可以将两阶段超图消息传递矩阵表示为:
其中,Dv和De分别表示顶点和超边的对角度量矩阵。
3)HGC-SCS框架的一个实例:通过结合之前定义的超图构建和卷积策略,我们引入了简化版的HGC-SCS框架,称为基于超图的跨层、跨位置表示网络(HyperC2Net),其总体定义如下:
其中,||表示矩阵连接操作。o是图4中所示的融合函数(语义散射模块和自下而上模块)。在我们的HyperC2Net中,Xmixed本质上包含跨层信息,因为它是由多个层次的主干特征融合而成的。此外,通过
第 6 页
将网格特征分解为语义空间中的一个特征点集合,并基于距离构建超边,我们的方法允许在点集内的不同位置之间进行高阶消息传递。这种能力有助于捕获跨位置信息,丰富模型对语义空间的理解。
E. 比较和分析
YOLO系列的改进主要集中在骨干和颈部组件的精简上,特别关注每个迭代版本中作为进化关键要素的骨干。例如,原始的Yolo [1]框架引入了DarkNet骨干,此后经过一系列增强,如在YOLOv7 [7] 中引入的ELAN (Efficient Layer Aggregation Network) 模块以及在YOLOv8 [8] 中推出的C2f(Cross Stage Partial Connections with Feedback)模块。这些创新极大地促进了骨干架构的视觉特征提取能力。
相比之下,我们的Hyper-YOLO模型将创新轴转向了颈部组件的设计。在颈部架构领域,前沿迭代如YOLOv6 [5]、YOLOv7 [7]和YOLOv8 [8]一直整合了PANet(路径聚合网络)结构。同时,Gold-YOLO [10]采用了新颖的聚集-分发颈模式。接下来,我们将比较HyperYOLO的HyperC2Net与这些经典的颈部架构。
尽管PANet架构通过顶部和底部路径融合多尺度特征,但在信息跨相邻层的融合方面仍然受到限制。这种邻域约束的融合模式本质上限制了网络中信息集成的广度。另一方面,HyperC2Net超越了这一局限性,使直接在五重特征级别上进行融合成为可能。这种方法产生了一个更稳健且多样化的信息流,减少了不同深度特征之间的连接差距。值得注意的是,Gold-YOLO引入的聚集-分发颈部机制虽然具有整合多个层次信息的能力,但并不自然地考虑特征映射中的跨位置交互作用。HyperC2Net的独特之处在于其利用超图计算来捕捉特征映射中潜在的高阶关联。语义领域的超图卷积促进了非网格约束的信息流动,实现了跨层级和跨位置的高阶信息传播。该机制打破了传统网格结构的束缚,使得特征表示更加细致入微、综合全面。
HyperC2Net生成的特征表示反映了对原始数据主干提供的语义特征以及潜在高阶结构特征的全面考虑。这种丰富的特征表示对于实现对象检测任务中的优异性能至关重要。HyperC2Net在利用
这些复杂的高阶关系在计算机视觉领域中具有显著的优势,甚至优于传统的颈部架构如PANet和最近的创新颈结构如聚集-分布颈。这强调了高阶特征处理对提升计算机视觉前沿的重要性。
V. 实验
A. 实验设置
1) 数据集:本文采用微软COCO数据集 [41],作为目标检测的基准来评估所提出的Hyper-YOLO模型的有效性。具体来说,使用Train2017子集进行训练,而Val2017子集则用作验证集。对Hyper-YOLO在Val2017子集中进行了性能评价,并详细列于表I中。
2)比较方法:我们选择先进的YOLO系列方法进行对比,包括YOLOv5 [4]、YOLOv6-3.0 [5]、YOLOv7 [7]、YOLOv8 [8]、Gold-YOLO [10] 和 YOLOv9 [21]。在我们的实验中采用其报告的默认参数配置。
3)我们的Hyper-YOLO方法:我们的Hyper-YOLO基于YOLOv8的四个尺度(-N,-S,-M和-L)。因此,我们修改了每个阶段的Hyper-YOLO架构中的超参数(卷积层数量、特征维度),如表S2所示,从而形成了Hyper-YOLO-N,Hyper-YOLO-S,Hyper-YOLO-M和Hyper-YOLO-L。考虑到我们的Hyper-YOLO在颈部引入高阶学习,这增加了参数数量,我们在Hyper-YOLO-N的基础上进一步减少了参数以形成Hyper-YOLO-T。具体来说,在Hyper-YOLO-T的HyperC2Net中,Bottom-Up阶段的最后一层C2f被替换为一个1×1卷积。此外,我们注意到最新的YOLOv9采用了一种新的可编程梯度信息传输,并且在推理过程中修剪路径来减少参数并保持精度。基于YOLOv9,我们开发了Hyper-YOLOv1.1。具体而言,我们将YOLOv9的颈部替换为来自Hyper-YOLO的HyperC2Net,从而使YOLOv9具备高阶学习的能力。
4)其他细节:为了确保公平的比较,我们排除了所有方法中预训练和自蒸馏策略的应用,如在 [5] 和 [10] 中所述。此外,考虑到输入图像大小可能对评估结果的影响,我们在所有实验中标准化输入分辨率至 640×640 像素,这是该领域的常见选择之一。评估基于标准的 COCO 平均精度 (AP) 指标。额外的实现细节可在部分 A 和部分 C 中找到。
B.结果与讨论
COCO Val2017验证集上的对象检测结果
如表1所示,dation set导致四个主要观察结果。
首先,提出的Hyper-YOLO方法在所有四个尺度上都优于其他模型。例如,在APval度量标准下,Hyper-YOLO分别在N、S、M和L尺度上的性能为41.8%、48.0%、52.0%和53.8%。与
第 7 页
比较最先进的YOLO方法。术语“#参数”是指模型中的“参数数量”。在FP16精度下,帧每秒(FPS)和延迟均使用Tesla T4 GPU进行了基准测试,并且所有模型与TensorRT 8.6.1一致。在我们的实际速度评估中,值得注意的是TensorRT并未完全优化距离计算(torch.cdist()),这是构建超图的关键步骤之一。为了保持与其他YOLO变体的公平比较,我们还提供了额外的结果,这些结果仅隔离了对骨干网络架构本身的改进,由符号†表示。
Gold-YOLO,Hyper-YOLO分别提高了2.2、2.6、2.2和2.0。与YOLOv8相比,这些改进分别为4.5、3.1、1.8 和0.9 。与YOLOv9相比,Hyper-YOLO的改进为3.5、1.2、0.6 和0.8 。这些结果验证了Hyper-YOLO方法的有效性。
其次,值得注意的是我们的方法不仅在性能上优于Gold-YOLO,在参数数量上也显著减少。具体来说,N、S、M和L尺度分别减少了28%,31%,19% 和25% 。主要原因是我们的HGC-SCS框架,它进一步引入了与Gold-YOLO的聚集-分布机制相比,在语义空间中进行高阶学习。这使得我们的方法能够更有效地利用由主干提取的各种信息,包括跨层和跨位置的信息,并且使用较少的参数。
第三,考虑到Hyper-YOLO与YOLOv8共享相似的底层架构,我们发现提出的Hyper-YOLO-T在参数数量更少(3.2M→3.1M)的情况下,相比于YOLOv8-N,在AP val上实现了更高的目标检测性能(37.3→38.5)。这表明所提的HyperC2Net可以通过高阶学习实现更好的特征表示学习。
从而提高了检测性能。同样,我们比较了Hyper-YOLOv1.1和YOLOv9,因为两者都使用相同的主干架构,并且唯一的区别是Hyper-YOLOv1.1采用了基于超图的HyperC2Net作为颈部。结果表明我们的Hyper-YOLOv1.1在物体检测任务中表现出了显著的性能改进:Hyper-YOLOv1.1-T优于YOLOv9-T 2.0 APval,而Hyper-YOLOv1.1-S优于YOLOv9-S 1.2 APval。这种在同一规模下采用相同架构进行公平对比验证了所提出的方法的有效性。
最后,我们观察到,在模型规模从L级减小到N级时(即模型大小变小时),Hyper-YOLO带来的改进比YOLOv8更显著 (从0.9增加到4.5)。这是因为较小的模型规模会削弱特征提取能力和从视觉数据中获取有效信息的能力。此时,高阶学习变得必要以捕获语义空间中的特征映射所蕴含的潜在高阶相关性,并丰富最终用于检测头的特征。此外,基于超图在语义空间中的高阶消息传播允许不同位置和级别的直接信息流,从而增强特征提取能力。
第 8 页
有限参数的基网络。
C. 框架的消融研究
在本节和下一节中,考虑到模型的大小,我们选择Hyper-YOLO-S进行骨干网络和颈部的消融研究。
1)在骨干网络的基本块上:我们对所提出的MANet进行消融实验,以验证基本块中混合聚合机制的有效性,如表II所示。为了确保公平的比较,我们将YOLOv8 [8] 中使用的PANet [16]作为颈部使用,这样两种方法之间的唯一区别在于基本块。实验结果清楚地表明,在相同的颈部下,所提出的MANet在所有指标上都优于C2f模块。这种优越性能归因于混合聚合机制,该机制整合了三种经典结构,从而导致信息流更丰富,并且表现出增强的效果。
2)不同阶段的卷积核大小:我们进一步对不同阶段中卷积核大小进行了消融实验,这是确定感受野和网络捕获数据空间层次结构能力的关键因素。在我们的实验中,ki表示MANet在第i个阶段使用的卷积核大小。由于我们的MANet从第二个阶段开始使用混合聚合,我们在实验中的配置为[k2,k3,k4,k5]。实验结果如表III所示。实验结果表明,将卷积核大小从3增加到5确实可以提高模型的准确性。然而,在小规模和中等规模对象检测中,与混合不同大小的卷积核相比,并不一定能提高准确度,而且也会导致参数数量增多。因此,考虑到性能和参数数量之间的平衡,最终选择[3,5,5,3]作为我们MANet中卷积核大小的最佳设置。
D. 颈部消融研究
1)高阶学习与低阶学习在HGC-SCS框架中的对比:HGC-SCS框架的核心在于
允许特征点集之间进行高阶信息传播的语义空间超图计算。我们通过简化超图以实现低阶学习,如表IV所示。在这种情况下,该图由连接中心节点与其e球内的邻居组成。所使用的图卷积操作是经典的:Aˆ=D-1/2vAD-1/2v+I,其中Dv为图邻接矩阵A的对角度量矩阵。此外,我们还包括一个完全不考虑相关性的配置:“None”。实验结果,如表IV所示,表明高阶学习在性能上优于其他两种方法。理论上,低阶学习可以被视为高阶学习的一个子集,但缺乏复杂关联建模的能力。另一方面,高阶学习具有更强的关联建模能力,这对应着更高的性能上限。因此,它倾向于更容易地获得更好的性能。
2)在语义收集阶段:HGC-SCS框架的第一阶段是语义收集,它确定了输入到超图计算的语义空间的信息总量。我们对这一阶段进行了消融研究,如表V所示,在三种不同的配置下选择三个、四个或五个特征映射级别作为输入。实验结果表明,更多的特征映射可以带来更丰富的语义空间信息。这种增强的信息丰富性使超图能够充分利用其建模复杂相关性的能力。因此,具有五种特征映射的输入配置表现最佳。这个结果表明,当整合更多级别的特征映射时,模型可以从输入数据中获得更全面的表示形式中受益。更多地包括特征映射可能引入视觉输入中的更广泛的意义和细节范围,从而允许超图建立更高阶的连接,反映对场景的理解更加完整。因此,包含五个特征映射的配置更适合最大化基于超图的复杂相关性建模潜力。
第 9 页
3)在超图计算阶段的超图构建:进一步进行消融实验,以评估用于构建超图的距离阈值的效果,并显示在表VI中。与未引入超图计算的配置“None”相比,引入超图计算导致整体性能显著提高。还观察到,在阈值从7到9范围内,目标检测网络的表现相对稳定,仅存在轻微变化。然而,当阈值为6和10时,出现了性能下降。这种下降可以归因于连接节点的数量直接影响语义空间中的特征平滑度。较高的阈值可能导致更紧密相连的超图,其中节点更有可能共享信息,从而可能造成过度平滑化。相反,较低的阈值可能会导致不完全利用高阶关系的稀疏超图。因此,我们的Hyper-YOLO使用距离阈值8来构建超图。精确值将根据经验结果确定,平衡丰富连接的超图需求以及过度平滑或过少连接的风险。
E. 更多消融研究
在本小节中,我们对Hyper-YOLO的四个不同模型规模进行了全面的消融研究,以评估主干和颈部增强的影响。详细结果如表VII所示。YOLOv8的基本性能位于表的顶部。中间部分介绍了仅包含主干增强的我们的HyperYOLO 模型。底部是完全增强的HyperYOLO模型,它们受益于主干和颈部增强。根据表VII中的实验结果,我们有三个观察:
首先,无论是单独还是组合的增强措施都显著提高了N、S和M模型的表现,并验证了我们提出的修改的有效性。其次,每个增强措施的影响似乎与规模相关。从N到S、M和L模型,由于主干改进带来的增量性能收益逐渐减少,分别为2.6、1.5、0.8 和最后为0.1 。相反,颈部增强在这些尺度上始终贡献更显著的改善,分别获得1.9、1.6、1.0 和0.8 的收益。
这表明,尽管在小模型中,扩展的接收域和宽度缩放对主干的好处更为明显,但高级HyperC2Net颈部通过丰富语义内容并提高整体对象检测性能提供了更均匀的增强。第三,在关注小型物体检测(AP)时,具有主干和颈部增强的HyperYOLO-L模型实现了显著增加1.6,而仅主干增强导致了0.6改进。这强调了超图建模,特别是颈部增强中的潜力,可以捕获这些复杂场景中小型物体之间的关系,并显着改善检测。
F. 更多实例分割任务的评估
我们扩展了Hyper-YOLO在COCO数据集上的实例分割任务,通过采用一致的网络修改方法:用分割头替换检测头来确保与前代YOLOv8进行直接比较。实验结果如表VIII所示。
实证结果清楚地表明,Hyper-YOLO取得了显著的性能提升。对于APbox而言,Hyper-YOLO在N、S、M和L变体上分别显示出令人印象深刻的增长为4.7 AP、3.3 AP、2.2 AP 和1.4 AP;同样,在APmask方面,Hyper-YOLO也表现出明显的改进,分别为N、S、M和L变体上的增长为3.3 AP、2.3 AP、1.3 AP和0.7 AP。这些结果强调了集成到Hyper-YOLO中的进步的有效性。
G. 对象检测中的高阶学习可视化
在我们的论文中,我们提供了一个数学理由来解释基于超图的颈部如何超越传统颈部设计的局限性。这些传统的颈部设计通常依赖于网格状邻域结构进行特征映射中的消息传播。这种设计使高级高阶消息在整个语义空间内跨特征进行传播成为可能。为了进一步证明我们基于超图的颈部的有效性,我们在修订后的手稿中包括了可视化结果,如图5所示。这些可视化比较了应用HyperConv层前后特征映射的结果。从这些图像可以看出,在保持对各种场景中前景对象的关注的同时,背景(例如天空和地面)的注意力得到了一致的减少。这表明通过超图计算,HyperConv有助于颈部更好地识别图像中的相似物体,从而支持检测头做出更一致的决策。
六、结论
在本文中,我们介绍了Hyper-YOLO,这是一种突破性的对象检测模型,它将超图计算与YOLO架构集成在一起,以利用视觉数据中的高阶相关性潜力。通过解决
第 10 页
实例分割任务的实验结果。
传统YOLO模型的固有局限性,特别是颈部设计无法有效整合不同层次特征并利用高阶关系的能力,我们显著提高了物体检测的SOTA。我们的贡献为未来基于HGC-CSC框架的研究和开发对象检测架构奠定了新的基准,并为进一步探索视觉架构中超图计算的集成铺平了道路。
[1] J. Redmon,S. Divvala,R. Girshick 和A. Farhadi,“你只需要看一次:统一的实时对象检测”,在IEEE计算机视觉和模式识别大会上的论文,2016年,第779-788页。
[2] J. Redmon 和 A. Farhadi,“YOLOv3:一个增量改进”,ArXiv预印本,ArXiv:1804.02767,2018。
[3] A. Bochkovskiy,C.-Y. Wang和H.-Y. M. Liao,“YOLOv4:对象检测的最优速度和准确性”,ArXiv,卷。abs / 2004.10934,2020年。
[4] G. Jocher,“Ultralytics YOLOv5”,2020。在线。可用:https://github.com/ultralytics/yolov5
[5] 李超,李丽,耿玉,江海,程明,张斌,柯泽凯,徐鑫和楚晓春,“YOLOv6 v3.0:全面重新加载”,ArXiv,卷。abs / 2301.05586,2023年在线。可用性:https://api.semanticscholar.org/CorpusID:255825915
[6] 李超,李亮,江浩,翁凯,耿永刚,李丽,柯泽,李强,程敏,聂伟等,“YOLOv6:面向工业应用的一体化目标检测框架”,ArXiv预印本ArXiv:2209.02976,2022。
[7] Wang CY,Bochkovskiy A,Liao HYM,“YOLOv7:可训练的免费品集合为实时对象检测器带来了新的最先进的性能”,在IEEE/CVF计算机视觉与模式识别大会论文集上发表,2023年,第7464-7475页。
[8] G. Jocher,A. Chaurasia和J. Qiu,“Ultralytics YOLOv8”,2023。在线。可用:https://github.com/ultralytics/ultralytics
[9] Z. Ge,S. Liu,F. Wang,Z. Li和J. Sun,“YOLOX:超越yolo系列的2021年”,ArXiv,卷。abs / 2107.08430,2021。(在线)。可用性: https :// api.semanticscholar.org/CorpusID:236088010
[10] 王晨,何文,聂亚楠,郭俊杰,刘超,王玉和韩凯,“金-YOLO:通过聚集并分发机制的高效对象检测器”,第 37 届神经信息处理系统大会,2023。
[11] Xu S, Wang X, Lv W, Chang Q, Cui C, Deng K, Wang G, Dang Q, Wei S, Du Y 和 Lai B,“PP-YOLOE:一种改进的YOLO”,ArXiv,卷。abs / 2203.16250,2022。(在线)。可用性: https :// api.semanticscholar.org/CorpusID:247793126
[12] M. Tan 和 Q. Le,“EfficientNet:重新思考卷积神经网络的模型缩放”,在国际机器学习会议上。PMLR,2019年,第6105-6114页。
[13] Ding X., Zhang X., Ma N., Han J., Ding G. and Sun J., "Repvgg:使VGG风格的卷积网络再次伟大”,IEEE/CVF计算机视觉与模式识别大会,2021年,第13页733-13页742。
[14] 王春燕,廖海英和叶一辉,“通过梯度路径分析设计网络设计策略”,ArXiv预印本:arXiv:2211.04800,2022。
[15] T-Y. Lin,P. Dolla´r,R. Girshick,K. He,B. Hariharan 和S. Belongie,“特征金字塔网络用于对象检测”,在IEEE计算机视觉和模式识别大会的会议记录中,2017年,第2117-2125页。
第 11 页
[16] Liu Sheng, Qi Liang, Qin Hong, Shi Jian and Jia Junjie, "Path Aggregation Network for Instance Segmentation," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8759-8768.
[17] 高亚,张志刚,林海,赵晓东,杜胜和周成, “超图学习:方法与实践”,《模式分析与机器智能》杂志第44卷第5期,页码为2548-2566,2020年。
[18] 高亚,冯毅,纪思和纪瑞,“HGNN+:通用超图神经网络”,IEEE模式分析与机器智能杂志,卷号45,第3181-3199页,2023年。
[19] C.吕,张伟,黄海,周玉,王宇,刘亚男,张硕和陈凯,“RTMDet:设计实时对象检测器的实验研究”,2022。
[20] Tian Z, Shen C, Chen H, et al,“ FCOS: 全卷积单阶段目标检测”, 第二届国际计算机视觉会议论文集(IEEE/CVF), 2019年,第9627-9636页。
[21] C-Yang Wang,I-Hao Yeh和H-Yuan M.Liao,“Yolov9:使用可编程梯度信息学习您想要学习的内容”,arXiv预印本arXiv:2402.13616,2024。
[22] J.-G. Young,G. Petri和T.P.Peixoto,“从网络数据中重建超图”,通讯物理学,卷。 4,第1期,页。 135,2021年。
[23] 杨大,曲波,杨杰和库德雷·马鲁克斯,“lbsn2vec ++:基于位置的社会网络的异构超图嵌入”,《IEEE知识与数据工程杂志》,第34卷,第4期,页1843 - 1855,2020。
[24] Jin Shu, Hong Yan, Zeng Lei, Jiang Yong, Lin Ying, Wei Liang, Yu Zhengyu, Zeng Xiaochun, and Liu Xiang, "General Hypergraph Learning Algorithm for Drug Multi-Task Predictions in Micro-to-Macro Biomedical Networks," PLOS Computational Biology,Vol. 19, No. 11, pp. e1011597, 2023。
[25] R. Vin˜as,C.K.Joshi,D.Georgiev,P.Lin,B.Dumitrascu,E.R.Gamazon和P.Lio`,“多组织基因表达预测的超图分解”,自然机器智能,卷。5,第7期,页码:739-753,2023年。
[26] 小李,王杰,卡萨尼普·哈桑,张毅,白玉,史蒂芬·约翰,威尔逊·托马斯,卡尔霍恩·维克多和王一平,“基于多重超图学习的fMRI数据中的脑功能连接分析”,《IEEE医学成像杂志》,第39卷,第5期,页1746-1758,2019。
[27] C. Zu,Y. Gao,B. Munsell,M. Kim,Z. Peng,Y. Zhu,W. Gao,D. Zhang,D. Shen和G. Wu,“通过学习超图识别高阶脑连接组生物标志物”,在MICCAI 2016。Springer出版社,2016年,第1页至第9页。
[28] 风杨,游浩,张志刚,纪瑞和高玉,“超图神经网络”,第33届AAAI人工智能大会论文集,2019。
[29] K. He,X. Zhang,S. Ren和J. Sun,“图像识别的深度残差学习”,IEEE计算机视觉与模式识别会议论文集,2016年,第770-778页。
[30]——,“深残差网络中的身份映射”,计算机视觉-ECCV 2016:第十四届欧洲会议,阿姆斯特丹,荷兰,2016年10月11日至14日,论文集,第四部分。Springer,2016,pp. 630-645。
[31] 黄国强,刘志远,马腾和魏宁博,“密集连接卷积网络”,IEEE计算机视觉与模式识别会议论文集,2017年,第4700页至4708页。
[32] Liu Z, Mao H, Wu CY, Feichtenhofer C, Darrell T 和 Xie S,“一个为 2020 年代设计的卷积神经网络”,IEEE/CVF计算机视觉与模式识别大会论文集,2022年,第11976-11986页。
[33] C. Szegedy,V. Vanhoucke,S. Ioffe,J. Shlens和Z. Wojna,“重新思考计算机视觉的Inception架构”,在IEEE计算机视觉与模式识别大会论文集上发表,2016年,第2818-2826页。
[34] Xie,S., Girshick,R., Dolla´r,P., Tu,Z. 和 He,K.“ 深度神经网络的聚合残差变换”,IEEE 计算机视觉和模式识别会议论文集,2017 年,第 1492-1500 页。
[35] 郑宇,袁晓,吴睿,王杰,侯庆和程敏敏,“YOLO-MS:重新思考实时目标检测的多尺度表示学习”,ArXiv预印本ArXiv:2308.05480,2023。
[36] 徐鑫,江宇,陈伟,黄亚,张玉和孙旭,“DAMO-YOLO:实时目标检测设计报告”,ArXiv预印本ArXiv:2211.15444,2022。
[37] Wang CY,Bochkovskiy A,Liao HYM,“Scaled-YOLOv4:缩放跨阶段部分网络”,IEEE/CVF计算机视觉与模式识别大会论文集,2021年,第13029-13038页。
[38] J. Redmon 和 A. Farhadi,“YOLO9000:更好、更快、更强”,在IEEE计算机视觉与模式识别大会论文集,2017年,第7263-7271页。
[39] 黄磊,李文,沈亮,傅海,肖晓和肖硕,“YOLOCS:基于密集通道压缩的特征空间固化的对象检测”,ArXiv预印本ArXiv:2305.04170,2023。
[40] 李宇,黄正伟,李尚,白玉和朴建,“实时对象检测的能耗和GPU计算高效骨干网络”,IEEE/CVF计算机视觉与模式识别会议论文集工作坊,2019年,第0-0页。
[41]林泰宇,马毅,贝尔邦吉,哈斯,佩罗纳,拉曼安,多尔和C.L.齐特尼克,“微软coco:在上下文中常见的对象”,欧洲计算机视觉会议。Springer国际出版公司,2014年,第740-755页。
[42] T.N.Kipf和M.Welling,“基于图卷积网络的半监督分类”,国际学习表示会议,2017。
[43] 风杨,季思,刘一硕,杜帅,戴启和高玉,“基于超图的多模态表示用于开放集三维对象检索”,IEEE模式分析与机器智能杂志,2023。
冯一帆于2018年获得西安电子科技大学计算机科学与技术学士学位,2021年获得厦门大学硕士学位。目前在清华大学软件学院攻读博士学位。他的研究兴趣包括超图神经网络、机器学习和模式识别。
黄江刚于2022年从中国西安交通大学获得软件工程学士学位。目前,他正在攻读该校的硕士学位。他的研究兴趣包括对象检测、软件工程和人工智能。
杜少义于2002年获得西安交通大学计算数学和计算机科学双学士学位,2005年获应用数学硕士学位,并在2009年获得模式识别与智能系统博士学位。他目前是西安交通大学教授。他的研究兴趣包括计算机视觉、机器学习和模式识别等。
第 12 页
应世辉(M'11)于2001年和2008年分别在西安交通大学获得机械工程学士学位和应用数学博士学位。目前,他担任上海大学科学学院数学系教授。他的研究兴趣包括机器智能与医学图像分析的几何理论及方法。
永俊海于1996年和2001年分别在清华大学计算机科学与技术系获得学士学位和博士学位。他在2000年曾担任香港科技大学计算机科学系的访问学者,从2000年至2002年他曾在肯塔基大学计算机科学系任博士后研究员。目前他是清华大学软件学院教授。他的主要研究兴趣包括计算机辅助设计和计算机图形学。他曾获得许多奖项,如国家杰出青年基金等。
博士学位论文奖,国家杰出青年科学基金
青年学者,ACM SIGGRAPH欧洲图形学的最佳论文奖
计算机动画研讨会,杰出服务奖作为
Elsevier出版的《计算机与图形学》杂志副主编,
几项国家优秀教材奖。
李一鹏于2003年、2005年和2011年分别获得哈尔滨工业大学电子工程学士学位,硕士学位以及清华大学电子工程博士学位。目前在清华大学自动化系任助理研究员。他的研究兴趣包括基于无人机视觉的自主导航,自然环境三维重建,复杂系统理论及互联网应用分析等。
丁广贵,清华大学软件学院杰出研究员、博士生导师、副院长;国家信息科学与技术研究院副理事长。研究方向主要为视觉感知理论和方法、高效检索理论及方法、边缘计算和受限场景下的视觉任务神经网络压缩、视觉计算系统及其平台等。
发展。他获得国家杰出青年科学基金资助。
纪荣荣,厦门大学信息科学与技术学院教授、智能多媒体技术实验室主任。主要从事多媒体信号处理、计算机视觉和模式识别等领域的创新性研究工作,在国际期刊及会议上发表论文百余篇。担任《神经计算》、《信号处理》、《多媒体系统》等国际杂志的副主编或客座编辑。
高岳,清华大学软件学院副教授。1987年毕业于哈尔滨工业大学获学士学位;1990和2003年分别在清华大学获得硕士及博士学位。
第 13 页
A. 实施细节HYPER-YOLO
在本部分中,我们详细介绍了所提出模型的实现:Hyper-YOLO-N、Hyper-YOLO-S、Hyper-YOLO-M和Hyper-YOLO-L。这些模型基于PyTorch 1开发。与YOLOv8 [8]建立的配置一致,我们的模型共享类似架构和损失函数,但值得注意的是,它们都包含MANet 和HyperC2Net。一个高效的解耦头已被集成用于精确的目标检测。图S1显示了Hyper-YOLO-S的具体配置。
A. 主干
HyperYOLO的骨干,如表S1所示,已从其前身更新,并用MANet模块取代了C2f模块,保持与YOLOv8 [8] 相同的层数结构为[3, 6, 6, 3]。每个阶段的通道数保持与YOLOv8相同,唯一的改变是模块交换。
MANet使用深度可分离卷积,其中通道数增加,在输入为2c时输出变为4c(等效于cout)。
此外,对于四个阶段的超参数k和n分别设置为[3, 5, 5, 3] 和 [3, 6, 6, 6] ×深度。在不同模型尺度上,深度倍数是不同的,分别为Hyper-YOLO-N、Hyper-YOLO-S、Hyper-YOLO-M和Hyper-YOLO-L的1/3、1/3、2/3和1。这意味着每个模型阶段的实际计数为[n = 3, 6, 6, 6] 。
第 14 页
表S2
乘以相应的深度因子。这些规格确保每个HyperYOLO模型的尺度都配备了针对其大小和复杂性进行精细调整的主干,从而实现多尺度特征提取的高效。
B. 颈部
与YOLOv8的颈部设计相比,Hyper-YOLO模型引入了基于超图的跨层和跨位置表示网络(HyperC2Net)作为其颈部组件,如图4所示。这种创新结构是所提出的HGC-SCS框架的具体体现,专门用于封装语义空间中存在的潜在高阶相关性。
HyperC2Net旨在全面融合来自骨干网的跨级别和跨位置信息。通过利用超图架构,它有效地捕捉了不同层和位置之间特征点之间复杂的相互依赖关系。这使得模型能够构建更复杂和丰富的输入数据表示,这对于识别和描述正在处理的图像中的细微差别特别有用。在hyper-yolo模型尺度变化的背景下,颈部在保持高阶相关表示的一致性方面起着至关重要的作用。由于特征点的空间分布在像hyper-yolo-N和hyper-yolo-L这样的模型之间可以显著不同,后者通常具有更分散的分布,hyperC2Net通过为每个模型比例采用不同的距离阈值来相应地调整其方法,如表S2中所述。确保网络捕获适当水平的高阶相关性,而不会屈服于过度平滑。HyperC2Net能够根据模型规模和特征点分布动态调整其阈值,这是其复杂设计的证明。它在上下文理解的深度和保持特征空间的清晰度和粒度的需要之间取得了很好的平衡,因此,增强了模型在复杂多变的视觉环境中检测和分类物体的整体性能。
附录B
结果可视化
在本节中,我们进一步提供了Hyper-YOLO在两个任务上的可视化:对象检测和实例分割,分别如图S2和图S3所示。
A. 对象检测
图S2中描述的结果表明,我们的超YOLO模型表现出卓越的物体识别能力,如图 (b) 和图 (c) 所示。此外,由于在其架构中使用了基于超图的颈部,Hyper-yolo具有一定程度的类推理能力。这在图 (a) 中表现得最为明显,其中超约洛能够高度自信地推断,如果检测到一只鸟,其他两个实体也是鸟。此外,如图 (e) 所示,人类使用飞盘与狗玩耍是很常见的。即使只有一只手套在图像中可见,我们的超约洛仍然能够将其识别为人类的一部分。
B. 实例分割
图S3的结果表明,与YOLOv8相比,Hyper-YOLO在分类和边界划定方面都取得了显著的改进。尽管图(a)中的真实标注并不完全准确,但我们的Hyper-YOLO仍然能够提供精确的边界分割。图(c)、(d)和(e)描绘了更复杂的场景,然而我们的Hyper-YOLO继续提供了准确的实例分割结果,确保没有遗漏任何一个饼干。
附录C:超YOLO的培训细节
Hyper-YOLO的训练协议经过精心设计,以确保在不同实验中的一致性和稳健性。每个GPU被分配一个统一的批处理大小为20,以保持一致的计算环境,并利用总共8个NVIDIA GeForce RTX 4090 GPU。为了评估学习效果和泛化能力,所有
第 15 页
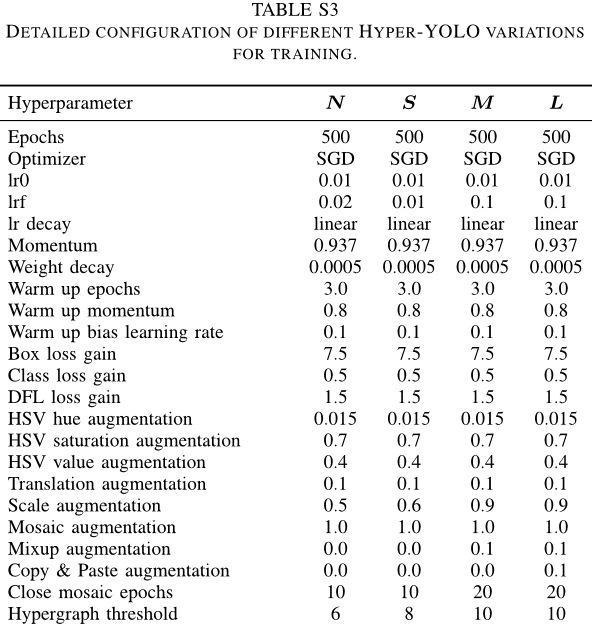
Hyper-YOLO的变体,包括-N、-S、-M和-L,从头开始训练。这些模型进行了500个周期的训练,而无需依赖于像ImageNet这样的大型数据集进行预训练,从而避免了潜在的偏差。对每个模型规模的训练超参数进行了微调以适应特定需求。表S3总结了每个模型规模的关键超参数。
这些核心参数,如初始学习率和权重衰减,在所有尺度上统一设置,以标准化学习过程。然而,超图阈值根据模型规模和批次大小而变化。此阈值配置为每GPU 20的批大小,这意味着如果批大小发生变化,则需要相应地调整阈值。通常,单个GPU上较大的批处理大小需要较低的阈值,而较大的模型规模则与较高的阈值相关。
大多数超参数在不同的模型尺度上保持一致; 尽管如此,诸如学习速率、尺度增强、混合增强、复制和粘贴增强等参数,并为每个模型比例定制超图阈值。数据增强超参数根据YOLOv5的配置进行设置,并对hyper-yolo进行了某些修改。例如,N和S模型采用了较低水平的数据增强,并对N模型的最终学习率进行了具体调整 (lrf = 0.02) 以及S模型的比例增强 (比例 = 0.6)。
另一方面,M和L模型分别利用了中等程度和高水平的数据增强,两个尺度的近似马赛克周期(20)设置相同。
需要强调的是,超图阈值是在每个GPU的批处理大小为20的前提下设置的。批量大小的改变应伴随着阈值的相应调整,遵循较大的单GPU批量大小应导致较小的相对阈值的趋势。同样,更大的模型比例需要更高的阈值。大多数超参数在不同的模型尺度上是一致的,除了一些像lrf、尺度增强、混合增强、复制和粘贴增强以及超图阈值,这些是根据模型的特定比例量身定制的。数据增强参数主要基于YOLOv5设置,其中一些值是不同的,以适应hyper-yolo模型的不同需求。


















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











