






文章目录
一、实现过程
1.1 下载数据集
https://github.com/truongnmt/smile-detection
创建一个文件夹存放datasets
1.2 根据猫狗数据集训练的方法来训练笑脸数据集
#coding=gbk
import os
import sys
def rename():
path=input("请输入路径(例如D:\\\\picture):")
name=input("请输入开头名:")
startNumber=input("请输入开始数:")
fileType=input("请输入后缀名(如 .jpg、.txt等等):")
print("正在生成以"+name+startNumber+fileType+"迭代的文件名")
count=0
filelist=os.listdir(path)
for files in filelist:
Olddir=os.path.join(path,files)
if os.path.isdir(Olddir):
continue
Newdir=os.path.join(path,name+str(count+int(startNumber))+fileType)
os.rename(Olddir,Newdir)
count+=1
print("一共修改了"+str(count)+"个文件")
rename()
路径:D:\Face_smile\datasets\train_foder\0
开始数:0

unsmile.改为smile.

1.2 图片分类
import os, shutil #复制文件
# 原始目录所在的路径
# 数据集未压缩
original_dataset_dir1 = 'D:\\Face_smile\\smile\\datasets\\train_folder\\1' ##笑脸
original_dataset_dir0 = 'D:\\Face_smile\\smile\\datasets\\train_folder\\0' ##非笑脸
# 我们将在其中的目录存储较小的数据集
base_dir = 'D:\\Face_smile\\smile1'
os.mkdir(base_dir)
# # 训练、验证、测试数据集的目录
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# 猫训练图片所在目录
train_cats_dir = os.path.join(train_dir, 'smile')
os.mkdir(train_cats_dir)
# 狗训练图片所在目录
train_dogs_dir = os.path.join(train_dir, 'unsmile')
os.mkdir(train_dogs_dir)
# 猫验证图片所在目录
validation_cats_dir = os.path.join(validation_dir, 'smile')
os.mkdir(validation_cats_dir)
# 狗验证数据集所在目录
validation_dogs_dir = os.path.join(validation_dir, 'unsmile')
os.mkdir(validation_dogs_dir)
# 猫测试数据集所在目录
test_cats_dir = os.path.join(test_dir, 'smile')
os.mkdir(test_cats_dir)
# 狗测试数据集所在目录
test_dogs_dir = os.path.join(test_dir, 'unsmile')
os.mkdir(test_dogs_dir)
# 将前1000张笑脸图像复制到train_cats_dir
fnames = ['smile.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir1, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
# 将下500张笑脸图像复制到validation_cats_dir
fnames = ['smile.{}.jpg'.format(i) for i in range(500)]
for fname in fnames:
src = os.path.join(original_dataset_dir1, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
# 将下500张笑脸图像复制到test_cats_dir
fnames = ['smile.{}.jpg'.format(i) for i in range(500)]
for fname in fnames:
src = os.path.join(original_dataset_dir1, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
# 将前1000张非笑脸图像复制到train_dogs_dir
fnames = ['unsmile.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir0, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
# 将下500张非笑脸图像复制到validation_dogs_dir
fnames = ['unsmile.{}.jpg'.format(i) for i in range(500)]
for fname in fnames:
src = os.path.join(original_dataset_dir0, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
# 将下500张非笑脸图像复制到test_dogs_dir
fnames = ['unsmile.{}.jpg'.format(i) for i in range(500)]
for fname in fnames:
src = os.path.join(original_dataset_dir0, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
结果如下:
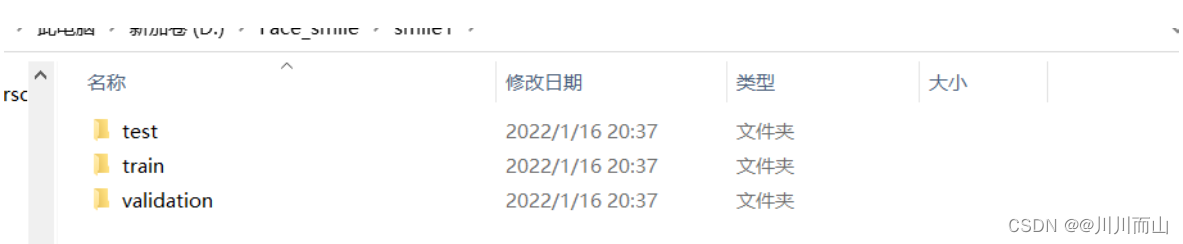
1.3 作为健全性检查,计算一下在每个训练分割中我们有多少图片(训练/验证/测试):
print('total training cat images:', len(os.listdir(train_cats_dir)))
print('total training dog images:', len(os.listdir(train_dogs_dir)))
print('total validation cat images:', len(os.listdir(validation_cats_dir)))
print('total validation dog images:', len(os.listdir(validation_dogs_dir)))
print('total test cat images:', len(os.listdir(test_cats_dir)))
print('total test dog images:', len(os.listdir(test_dogs_dir)))

1.4 卷积网络模型搭建
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
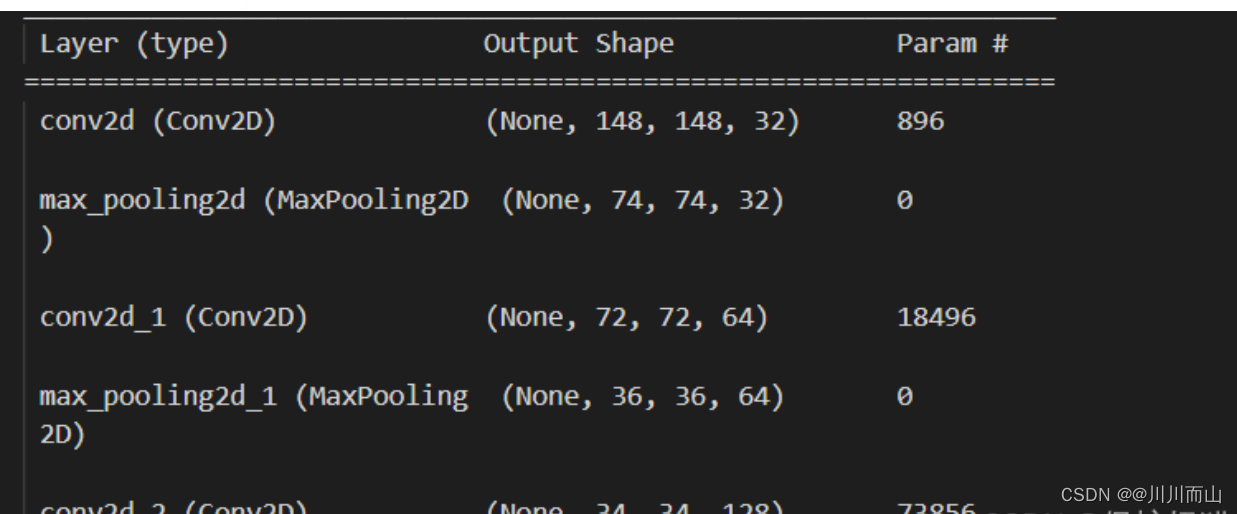
1.5 图像生成器读取文件中数据,进行数据预处理
from tensorflow import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
from keras.preprocessing.image import ImageDataGenerator
# 所有图像将按1/255重新缩放
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 这是目标目录
train_dir,
# 所有图像将调整为150x150
target_size=(150, 150),
batch_size=20,
# 因为我们使用二元交叉熵损失,我们需要二元标签
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')

1.6 开始训练
时间漫长,慢慢等待
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
1.7 保存训练模型
model.save('D:\\Face_smile\\smile1\\smiles_and_unsmiles_small_1.h5')
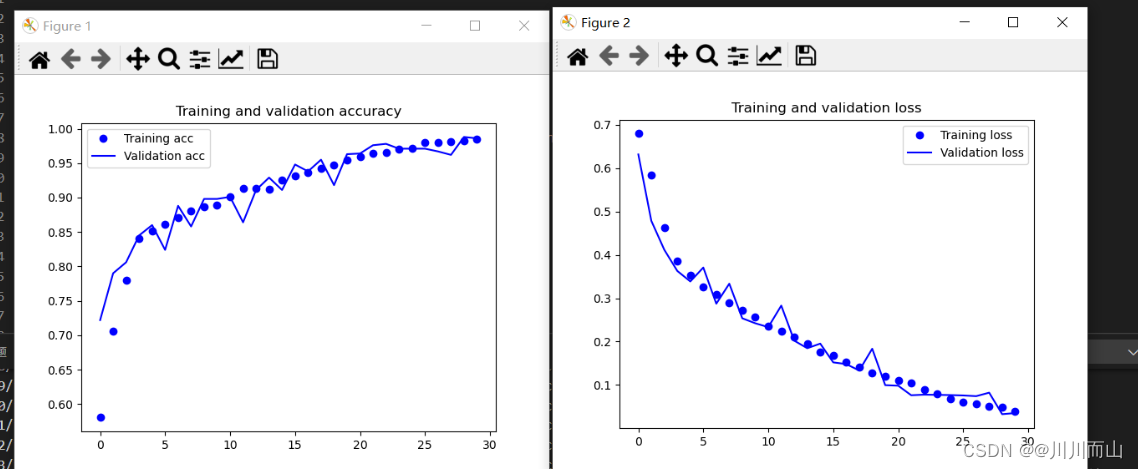
1.8 在培训和验证数据上绘制模型的损失和准确性(可视化界面)
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
1.9 使用数据扩充
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# 这是带有图像预处理实用程序的模块
from keras.preprocessing import image
fnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)]
# 我们选择一个图像来“增强”
img_path = fnames[3]
# 读取图像并调整其大小
img = image.load_img(img_path, target_size=(150, 150))
# 将其转换为具有形状的Numpy数组(150、150、3)
x = image.img_to_array(img)
# 把它改成(1150150,3)
x = x.reshape((1,) + x.shape)
# 下面的.flow()命令生成一批随机转换的图像。
# 它将无限循环,所以我们需要在某个时刻“打破”循环!
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()
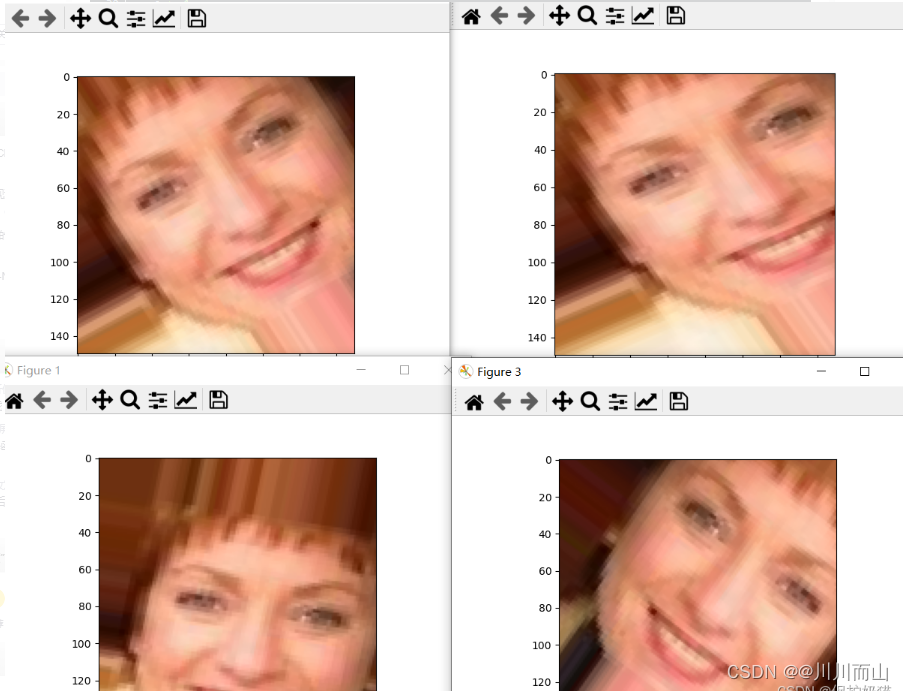
如果我们使用这种数据增强配置训练一个新网络,我们的网络将永远不会看到两次相同的输入。但是,输入它所看到的仍然是高度相关的,因为它们来自于少量的原始图像——我们无法产生新的信息,我们只能重新混合现有的信息。因此,这可能还不足以完全摆脱过度装修。继续战斗过度拟合,我们还将在密连接分类器之前向模型添加一个退出层:
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
1.10 使用数据扩充和退出来训练我们的网络
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
# 请注意,不应增加验证数据!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 这是目标目录
train_dir,
# 所有图像将调整为150x150
target_size=(150, 150),
batch_size=32,
# 因为我们使用二元交叉熵损失,我们需要二元标签
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
1.11保存模型
model.save('D:\\Face——smile\\smile1\\smiles_and_unsmiles_small_2.h5')
1.12 在培训和验证数据上绘制模型的损失和准确性(可视化界面)
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
二、运用训练的模型实现表情识别
2.1 将模型传输到树莓派
将前面训练的模型通过xshell将传输到树莓上,(由于没有摄像头)采用读取图片识别笑脸非笑脸
代码:
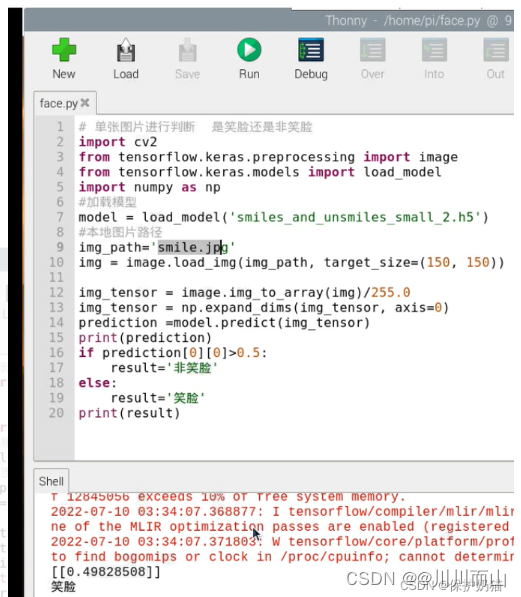
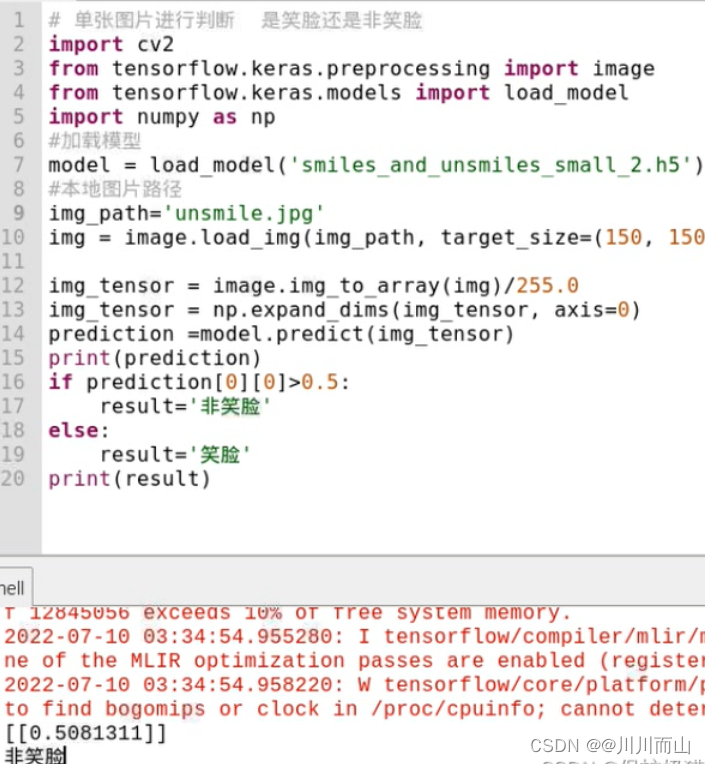
# 单张图片进行判断 是笑脸还是非笑脸
import cv2
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import load_model
import numpy as np
#加载模型
model = load_model('smiles_and_unsmiles_small_2.h5')
#本地图片路径
img_path='smile.jpg'
img = image.load_img(img_path, target_size=(150, 150))
img_tensor = image.img_to_array(img)/255.0
img_tensor = np.expand_dims(img_tensor, axis=0)
prediction =model.predict(img_tensor)
print(prediction)
if prediction[0][0]>0.5:
result='非笑脸'
else:
result='笑脸'
print(result)
结果:


2.2 采用摄像头测试模型
在window上进行
#检测视频或者摄像头中的人脸
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
import dlib
from PIL import Image
model = load_model(‘D:\Face_smile\smile1\smiles_and_unsmiles_small_2.h5’)
detector = dlib.get_frontal_face_detector()
video=cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
def rec(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dets=detector(gray,1)
if dets is not None:
for face in dets:
left=face.left()
top=face.top()
right=face.right()
bottom=face.bottom()
cv2.rectangle(img,(left,top),(right,bottom),(0,255,0),2)
img1=cv2.resize(img[top:bottom,left:right],dsize=(150,150))
img1=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB)
img1 = np.array(img1)/255.
img_tensor = img1.reshape(-1,150,150,3)
prediction =model.predict(img_tensor)
if prediction[0][0]>0.5:
result=‘unsmile’
else:
result=‘smile’
cv2.putText(img, result, (left,top), font, 2, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow(‘Video’, img)
while video.isOpened():
res, img_rd = video.read()
if not res:
break
rec(img_rd)
if cv2.waitKey(5) & 0xFF == ord(‘q’):
break
video.release()
cv2.destroyAllWindows()
结果展示:
















 1200
1200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









