







 本文详细介绍了事件相机的事件处理方法,包括单个事件处理和事件包处理,重点讨论了事件帧和VoxelGrid两种数据表示形式。事件帧在保留大部分信息的同时简化数据,适合处理一些计算机视觉任务;而VoxelGrid则完整保存时间信息,但数据量大,适用于需要充分利用时间信息的场景。此外,文章还概述了事件相机在特征检测、光流估计、3D重建等领域的应用。
本文详细介绍了事件相机的事件处理方法,包括单个事件处理和事件包处理,重点讨论了事件帧和VoxelGrid两种数据表示形式。事件帧在保留大部分信息的同时简化数据,适合处理一些计算机视觉任务;而VoxelGrid则完整保存时间信息,但数据量大,适用于需要充分利用时间信息的场景。此外,文章还概述了事件相机在特征检测、光流估计、3D重建等领域的应用。
·前言
上一篇文章中,笔者按照综述文章的内容介绍了事件相机的基本概念、类型,并分析了其优劣,并得出结论:目前事件相机的研究主要聚焦于如何处理这样一种新型的数据形式以及如何避开噪声提取出数据中有用的信息(当然,设计专门针对事件流数据的网络也是重要的研究方向),事件处理方法是应用事件相机最重要、最精髓的部分。
上篇文章地址:Event-based Vision: A Survey——从这篇综述开始了解事件相机(一)
原文下载地址:Event-based Vision: A Survey
因此在本篇文章中,笔者将聚焦事件流的处理方法,梳理本篇综述中个人认为最精华最核心的部分——3.Event Processing(p6-p10),在笔者这段时间复现论文的过程中,也确实发现,最耗费时间精力的也正是处理这些事件数据,且处理方法更是大有学问。
3. 怎么用事件相机?
正如作者所说:“One of the key questions of the paradigm shift posed by event cameras is how to extract meaningful information from the event data to fulfifill a given task.” 对于我们这些想利用事件相机潜在优势去解决实际CV问题的研究者来说,关键点便是如何从事件中提取有益于我们项目的信息,并且这种信息还要能够被现有的网络所接收(或是我们能专门设计一种接收这类信息的网络)。
让我们来观察一下事件流形式,第一章中提到,事件相机输出的事件流是一个四元组的序列:![]() ,像素点坐标、时间戳、事件极性包含了一个事件的所有信息,其中像素坐标告诉了我们事件发生的位置,时间戳则是指明了事件发生的事件,事件极性表示了事件的性质。目前,处理事件主要分为两类思想:
,像素点坐标、时间戳、事件极性包含了一个事件的所有信息,其中像素坐标告诉了我们事件发生的位置,时间戳则是指明了事件发生的事件,事件极性表示了事件的性质。目前,处理事件主要分为两类思想:
首先是单个事件独立处理,网络直接读取每个事件的信息,针对每个事件的信息作出相应反应,此时事件可以视为一个个脉冲,来刺激网络产生对应输出。这种处理方式的优势十分明显,那就是最大程度地利用了事件流极高的时间分辨率,不会丢失任何有用信息,延时也极低,不过显然传统的深度神经网络并不能这样处理四元事件点数据,也并不能针对高频输入实时作出反应。然而这也并不意味着我们不能这样处理事件,相反,目前研究人员已经能够通过概率滤波(Probabilistic Filters)、脉冲神经网路(Spike Neural Network,简称SNN)这两种方法有效处理单个事件的输入,它们能够结合过去事件提供的信息以及新到来事件的信息,异步产生输出。笔者认为,这种事件处理的方式尤其是SNN,是最贴近人脑工作模式,在未来很大潜力会成为人工智能领域的主流方法,在解决包括硬件问题在内的一系列问题后,该方法将会是事件处理最科学、最有效的解决方案。但对于笔者来说,实验室目前尚未打算进行该方面的研究,因此本部分内容本人尚未做深入研究,感兴趣的读者可以选择自行阅读论文相关部分,论文中对该部分的介绍还是十分全面的。
接着便是批量处理事件,也即“事件包处理”。上述单个事件处理的方法有一个不得不面对的问题便是噪声,我们在上一篇文章中提到过,噪声对事件相机的影响是极大的,可能微小的扰动便可能造成一个错误的事件发生,而单个处理事件时,网络并没有消除事件噪声的能力,这便对获取的事件的信噪比有极高的要求。这时事件包处理的方式就显出明显的优势了,我们设定一段时间(类似于普通相机的曝光时间),这段时间内包含个事件,然后将这
个事件整合起来进行处理,由于包含一定数量的事件,少许噪声事件的影响便会变小,这也使得事件包处理中数据的信噪比显著提高;同时,对于批量事件,可以通过压缩维度等方法,生成深度卷积神经网络可以接受的数据输入格式,最大可能地发挥现有CV算法模型的优势,但压缩维度可能也意味着丢失信息,可能会对结果造成不好的影响。
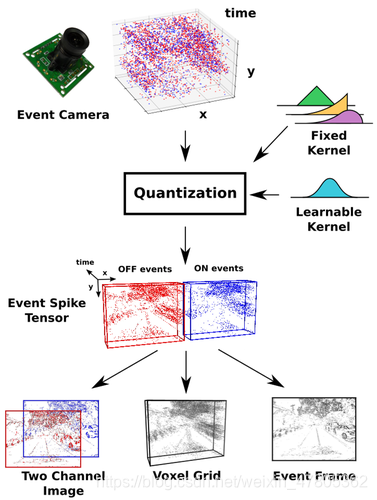
目前,深度卷积神经网络在许多CV项目中都发挥着关键作用,且已经有许多表现出色的网络(例如ResNet、Inception等)可供使用,因此采用事件包处理的方法,将事件数据转化为网络可以处理的图像数据,可以最大程度利用现有的CV研究成果。同时事件转化而来的图像数据,包含了事件所携带的运动、时间等信息,作为一种信息量更多的输入,也能让现有神经网络学到更多特征,提高结果的精确度。因此,笔者将着重介绍该类事件处理的方案,聚焦于将事件数据转化为卷积网络可以接受的图像输入。
3.1 2D事件帧—Event Frame
传统相机拍出的一张图像可以称为一帧,它是一段曝光时间内的平均值,通常类似VGG、Resnet等深度网络接受的输入也都是以帧为单位的2D灰度图像,因此将事件数据转换为2D帧是我们首先考虑的方式,转为为2D图像的事件数据称为事件帧。
我们选取一个时间段内的事件组成事件包,统计这个包中每个像素点发生事件的情况,最终输出一张事件帧,其中每一像素点均有一个值,该值可以表示事件的某些信息。例如将每个像素点所有时间戳的事件的极性叠加,即可得到最简单的事件帧,这样的事件帧可以看作事件包时间段内事件的集合体。
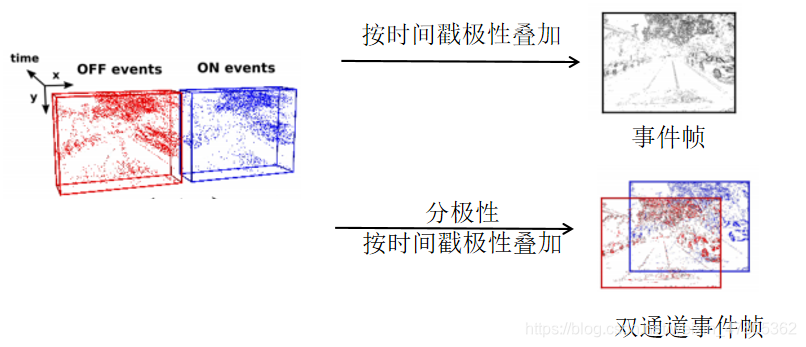
这样的操作虽然简单,但是也带来了许多问题:事件流原本的时间戳和极性携带的信息都被丢弃,事件帧仅记录了每个像素点在特定时间段内事件发生的频率,即表示“这个像素点发生了多少事件”,而具体在什么时间发生的,发生的什么事件这些信息,都无法从中提取。其实读到这一部分的时候笔者就在思考,既然把时间戳信息给压缩了,事件相机高时间分辨率这个最大的优势就被放弃了,那么事件相机又怎么能在一些CV问题中表现得比普通相机出色呢?论文给出了答案,即利用每个像素点可以储存一定信息的特点,将时间戳信息通过一定形式存储到每个像素点中,亦或是在事件叠加时用一些核变换或计量函数来取代简单的加法计算。而针对极性消失的问题,许多研究人员都采用双通道事件帧的数据形式,即正负极性的事件分别生成事件帧,并按照通道拼接起来。
时间平面(Time Surface)便是解决事件帧丢失事件信息的一种解决方案。这种事件数据的表示方式依然是2D图,只不过每个像素会对时间戳信息进行记录,按照作者的说法是记录该像素上一个事件的时间戳。在时间平面中,每个像素的强度表征着该位置的“运动痕迹”,因为产生事件的明暗变化往往和运动相联系,这使得这种事件表示形式在涉及到物体运动的CV问题上表现得尤为出色。
事实上,事件帧作为一种直观、简便的事件数据形式,已经在CV领域中的许多研究方向上得到了应用。即便是压缩了时间戳,只要选取事件包的时间段小于曝光时间,事件相机就依旧具有优于传统相机时间分辨率的优势,而往往相对于传统相机来说,这个时间段是很小的,且可以根据任务需求进行改变。同时,事件帧处理过程中并未影响任何事件流大动态范围的特性,因此在类似汽车转角预测、物体识别等问题上,比传统相机更高的时间分辨率和动态范围使得基于事件帧进行网络训练的模型表现出更高的精确性。
3.2 3D表示法—Voxel Grid
尽管事件帧这种2D数据形式已经能够在一些CV问题上取得出色成果,但我们还是希望能够最大程度利用事件流丰富的时间信息,以取得更加出色的结果。Voxel Grid则是这样一种事件数据的表示方式,我们同样需要选取一段时间间隔来提取事件包,但并不对其时间戳进行压缩,而是构建空间-时间的三维坐标。可以理解为每个时间戳对应一帧,这一帧的各个像素记录该时间戳发生事件的极性和,如此便可生成一种3D形式的事件数据,我们称之为Voxel。当然,Voxel是可以作为现有卷积网络的输入的,无论是将时间轴看作是通道输入2D卷积层还是直接输入3D卷积层,只要根据输入Voxel的维度设置好输入层,便可与现有的深度卷积网络衔接。

Voxel虽然完整地保存了事件流所有的时间信息,但是也同样丢失了事件极性,不过这可以采取和双通道事件帧同样的思想,对不同极性的事件生成不同的Voxel再拼接。那既然Voxel这么好,岂不是可以所有问题都能用这种数据形式去解决吗?显然,Voxel保留所有信息的代价是庞大的数据量,这给数据处理带来了更多的计算成本,同时,密集的时间戳意味着卷积层需要作更多次的计算,这就引入了更多的参数,使得网络十分庞大,这对要求轻量化的工业应用是极为不利的。即便抛开计算成本不谈,Voxel这种根据时间戳直接呈现事件的表示方式,是否真的能给所有卷积网络提供更多的特征、优化学习结果还是个未知数。
总之,数据形式并非一成不变,需要我们根据不同的问题进行选择,往往在初次尝试时,可以选取数据量压缩了的事件帧作为事件表示形式(同时也要注意事件包大小的选取—即时间间隔的选取,这不仅影响到数据处理的计算成本,甚至还影响到训练结果的好坏,这在将来笔者分享的论文中会有体现);当事件帧难以取得理想效果时,我们便可采用Voxel的形式再进行尝试(Voxel其实是个宽泛的概念,多个Event Frame拼接起来也可以当作是Voxel,因此,Voxel时间戳的单位并非一定是事件相机的最小时间精度,可以小规模的事件包为单位,减少数据量)。
除了介绍的两类事件批量处理的表示形式外,其实针对不同CV任务,还有更多优秀的方法去提取事件流中有价值的信息,笔者不才,仅对这两种简单易懂的方法有所了解与实践,读者可根据自己需求阅读论文第三章部分。
最后值得一提的是,Daniel等人在2019年ICCV中提出的一种可端对端学习的事件处理表示方法,能够有效针对不同应用场景,由机器学习得到对应的事件表示方法,这相当于是提供了一种数据转换的框架,是十分有价值的工作,这篇论文笔者在将来也会进行分享(论文名:End-to-End Learning of Representations for Asynchronous Event-Based Data )
4. 事件相机能做什么?
在弄清楚如何处理事件数据后,我们便可利用这样一种时间分辨率高、动态范围大的数据去处理一些CV问题。正如笔者之前所说,事件流数据可以看作是对原灰度图的信息补充,让原有的深度网络能够学到更多特征,以获取更精确的结果。如在特征检测与跟踪的任务中,传统灰度帧的时间间隔是很大的,两帧之间存在“盲区”,这使得许多特征丢失,而事件数据就能补足这些“盲区”,让网络学习到各帧之间的内在联系,做到异步、高精度的检测和跟踪。同时,利用事件是反映像素点明暗变化特性的这一性质,我们可以通过事件叠加计算实现从一帧到另一帧的映射过程,这给去模糊工作提供了理论模型基础(即EDI去模糊模型,本人将来也将分享、复现相关论文)。总之,即便是进行批量事件处理,用传统深度网络去处理事件,事件相机在许多CV领域都能有超越传统相机的出色表现;更不用说运用SNN或是概率滤波的仿生处理系统,将会在更多领域发挥关键作用。
笔者在此仅简单列举论文中提到的事件相机的应用场景,读者可以根据需求阅读相关部分并查阅更多参考文献进行深入调研,笔者认为综述只是起到引进门的作用,跟着综述去研读复现一些相关方向近些年的论文才是学习的重点。事件相机目前常用的领域如下:
特征检测与跟踪(Feature Detection and Tracking)
光流估计(Optical Flow Estimation)
3D重建与深度估计(3D reconstruction. Monocular and Stereo)
姿态估计与SLAM(Pose Estimation and SLAM)
视觉惯性测距(Vision-Inertial Odometry--VIO)
图像重建(Image Reconstruction)
运动分割(Motion Segmentation)
物体识别(Recognition)
———————————————————————————————————————————
最后,这篇冗长的综述总结终于要结束了,由于笔者第一次写CSDN博客,文章结构、排版、言辞有许多不妥,内容可能也有许多冗余、错误的部分,望大家批评指正。本人写文章的初心在于总结自己近期所学,顺带分享给那些同样和我一样入门这个领域的新人,也希望能在分享过程中发现自己理解上的错误,不断提升自己。正如本人博客介绍所说,我是一个初入CV行业的新人,希望记录自己学习过程的点滴,见证自己从小白到大佬的过程。

















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









