






一、核心概念解析
1.1 嵌入模型(Embedding)
作为AI领域的核心基础技术,嵌入模型通过将非结构化数据映射为低维稠密向量,实现语义特征的深度捕捉:
- 文本嵌入:如将语句转换为1536维向量,使"机器学习"与"深度学习"的向量余弦相似度达0.92
- 跨模态嵌入:支持图像与文本的联合向量空间映射,如CLIP模型实现文图互搜
前排提示,文末有大模型AGI-CSDN独家资料包哦!
1.2 向量模型(Vector Model)
作为嵌入技术的下游应用体系,主要包含两大方向:
- 判别式模型:基于SVM/神经网络的分类器(情感分析准确率可达92.3%)
- 检索式模型:利用向量相似度计算(如Faiss索引加速)实现毫秒级语义搜索
二、主流模型性能全景对比
2.1 全球模型排行榜(MTEB基准)
参考地址:MTEB Leaderboard - a Hugging Face Space by mteb
| 排名 | 模型名称 | Zero-shot | 参数量 | 向量维度 | 最大令牌数 | 任务平均得分 | 任务类型平均的愤怒 | 双语挖掘 | 分类 | 聚类 | 指令检索 | 多标签分类 | 成对分类 | 重排序 | 检索 | 语义文本相似度(STS) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | gemini-embedding-exp-03-07 | 99% | Unknown | 3072 | 8192 | 68.32 | 59.64 | 79.28 | 71.82 | 54.99 | 5.18 | 29.16 | 83.63 | 65.58 | 67.71 | 79.40 |
| 2 | Linq-Embed-Mistral | 99% | 7B | 4096 | 32768 | 61.47 | 54.21 | 70.34 | 62.24 | 51.27 | 0.94 | 24.77 | 80.43 | 64.37 | 58.69 | 74.86 |
| 3 | gte-Qwen2-7B-instruct | ⚠️ NA | 7B | 3584 | 32768 | 62.51 | 56.00 | 73.92 | 61.55 | 53.36 | 4.94 | 25.48 | 85.13 | 65.55 | 60.08 | 73.98 |
| 4 | multilingual-e5-large-instruct | 99% | 560M | 1024 | 514 | 63.23 | 55.17 | 80.13 | 64.94 | 51.54 | -0.40 | 22.91 | 80.86 | 62.61 | 57.12 | 76.81 |
| 5 | SFR-Embedding-Mistral | 96% | 7B | 4096 | 32768 | 60.93 | 54.00 | 70.00 | 60.02 | 52.57 | 0.16 | 24.55 | 80.29 | 64.19 | 59.44 | 74.79 |
| 6 | GritLM-7B | 99% | 7B | 4096 | 4096 | 60.93 | 53.83 | 70.53 | 61.83 | 50.48 | 3.45 | 22.77 | 79.94 | 63.78 | 58.31 | 73.33 |
| 7 | text-multilingual-embedding-002 | 99% | Unknown | 768 | 2048 | 62.13 | 54.32 | 70.73 | 64.64 | 48.47 | 4.08 | 22.80 | 81.14 | 61.22 | 59.68 | 76.11 |
| 8 | GritLM-8x7B | 99% | 57B | 4096 | 4096 | 60.50 | 53.39 | 68.17 | 61.55 | 50.88 | 2.44 | 24.43 | 79.73 | 62.61 | 57.54 | 73.16 |
| 9 | e5-mistral-7b-instruct | 99% | 7B | 4096 | 32768 | 60.28 | 53.18 | 70.58 | 60.31 | 51.39 | -0.62 | 22.20 | 81.12 | 63.82 | 55.75 | 74.02 |
| 10 | Cohere-embed-multilingual-v3.0 | ⚠️ NA | Unknown | 1024 | Unknown | 61.10 | 53.31 | 70.50 | 62.95 | 47.61 | -1.89 | 22.74 | 79.88 | 64.07 | 59.16 | 74.80 |
| 11 | gte-Qwen2-1.5B-instruct | ⚠️ NA | 1B | 8960 | 32768 | 59.47 | 52.75 | 62.51 | 58.32 | 52.59 | 0.74 | 24.02 | 81.58 | 62.58 | 60.78 | 71.61 |
| 12 | bilingual-embedding-large | 98% | 559M | 1024 | 514 | 60.94 | 53.00 | 73.55 | 62.77 | 47.24 | -3.04 | 22.36 | 79.83 | 61.42 | 55.10 | 77.81 |
| 13 | text-embedding-3-large | ⚠️ NA | Unknown | 3072 | 8191 | 58.92 | 51.48 | 62.17 | 60.27 | 47.49 | -2.68 | 22.03 | 79.17 | 63.89 | 59.27 | 71.68 |
| 14 | SFR-Embedding-2_R | 96% | 7B | 4096 | 32768 | 59.84 | 52.91 | 68.84 | 59.01 | 54.33 | -1.80 | 25.19 | 78.58 | 63.04 | 57.93 | 71.04 |
| 15 | jasper_en_vision_language_v1 | 92% | 1B | 8960 | 131072 | 60.63 | 0.26 | 22.66 | 55.12 | 71.50 | ||||||
| 16 | stella_en_1.5B_v5 | 92% | 1B | 8960 | 131072 | 56.54 | 50.01 | 58.56 | 56.69 | 50.21 | 0.21 | 21.84 | 78.47 | 61.37 | 52.84 | 69.91 |
| 17 | NV-Embed-v2 | 92% | 7B | 4096 | 32768 | 56.25 | 49.64 | 57.84 | 57.29 | 41.38 | 1.04 | 18.63 | 78.94 | 63.82 | 56.72 | 71.10 |
| 18 | Solon-embeddings-large-0.1 | ⚠️ NA | 559M | 1024 | 514 | 59.63 | 52.11 | 76.10 | 60.84 | 44.74 | -3.48 | 21.40 | 78.72 | 62.02 | 55.69 | 72.98 |
| 19 | KaLM-embedding-multilingual-mini-v1 | 93% | 494M | 896 | 512 | 57.05 | 50.13 | 64.77 | 57.57 | 46.35 | -1.50 | 20.67 | 77.70 | 60.59 | 54.17 | 70.84 |
| 20 | bge-m3 | 98% | 568M | 4096 | 8194 | 59.54 | 52.28 | 79.11 | 60.35 | 41.79 | -3.11 | 20.10 | 80.76 | 62.79 | 54.59 | 74.12 |
2.2 细分领域冠军模型
中文场景TOP3
- BGE-M3:支持8192长文本,金融领域语义相似度达87.2%
- M3E-base:轻量级模型推理速度达2300 QPS
- Ernie-3.0:百度知识图谱融合模型,摘要生成ROUGE-L值72.1
跨语言模型TOP3
- BGE-M3:支持108种语言混合检索,跨语言映射准确率82.3%
- Nomic-ai:8192 tokens长文本处理能力,合同解析效率提升40%
- Jina-v2:512维轻量化设计,边缘设备内存占用<800MB
2.3 企业级选型策略
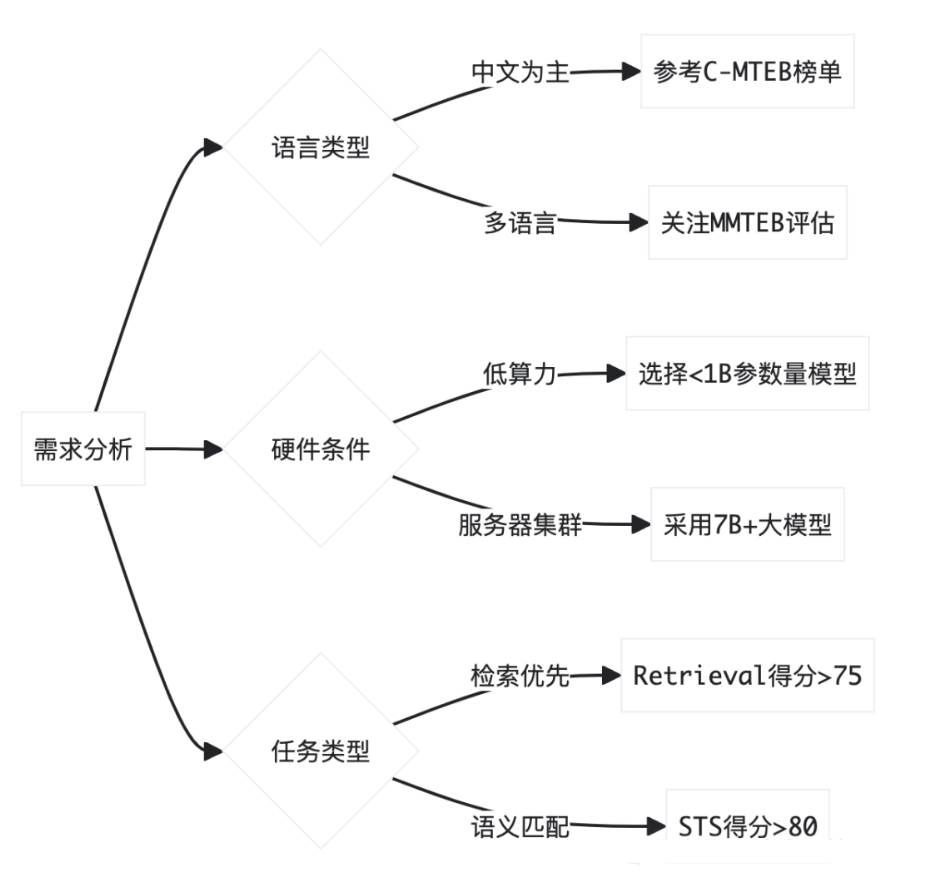
三、技术架构创新趋势
3.1 动态维度输出技术
- Matryoshka嵌套向量:通过训练模型输出256-1792维的灵活向量(如BGE-M3模型),实现不同精度需求的按需裁剪,资源利用率提升40%
- 稀疏注意力机制:NV-Embed采用潜在注意力层替代传统均值池化,使关键语义捕获效率提升58%
3.2 跨模态统一空间构建
- 多模态对齐架构:CLIP-like模型(如阿里云M6)实现文本-图像-音频的联合嵌入,医疗影像报告分析准确率提升至89%
- 层次化表征学习:分层编码器将对象拆解为原子特征(颜色/形状/纹理),支持组合式生成(如AI绘画中的风格迁移)
3.3 上下文理解增强
- 双向时序建模:在Transformer架构中引入时间戳嵌入,实现动态上下文感知(如金融合同版本差异识别)
- 因果推理嵌入:通过因果图网络构建因果向量空间,解决传统相似度计算的逻辑谬误问题
四、如何学习AI大模型 ?
“最先掌握AI的人,将会晚掌握AI的人有竞争优势,晚掌握AI的人比完全不会AI的人竞争优势更大”。 在这个技术日新月异的时代,不会新技能或者说落后就要挨打。
老蓝我作为一名在一线互联网企业(保密不方便透露)工作十余年,指导过不少同行后辈。帮助很多人得到了学习和成长。
我是非常希望可以把知识和技术分享给大家,但苦于传播途径有限,很多互联网行业的朋友无法获得正确的籽料得到学习的提升,所以也是整理了一份AI大模型籽料包括:AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、落地项目实战等 免费分享出来。
- AI大模型学习路线图
- 100套AI大模型商业化落地方案
- 100集大模型视频教程
- 200本大模型PDF书籍
- LLM面试题合集
- AI产品经理资源合集

大模型学习路线
想要学习一门新技术,你最先应该开始看的就是学习路线图,而下方这张超详细的学习路线图,按照这个路线进行学习,学完成为一名大模型算法工程师,拿个20k、15薪那是轻轻松松!

视频教程
首先是建议零基础的小伙伴通过视频教程来学习,其中这里给大家分享一份与上面成长路线&学习计划相对应的视频教程。文末有整合包的领取方式

技术书籍籽料
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,这里也分享一份我学习期间整理的大模型入门书籍籽料。文末有整合包的领取方式

大模型实际应用报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。文末有整合包的领取方式

大模型落地应用案例PPT
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。文末有整合包的领取方式

大模型面试题&答案
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。文末有整合包的领取方式

领取方式
这份完整版的 AI大模型学习籽料我已经上传CSDN,需要的同学可以微⭐扫描下方CSDN官方认证二维码免费领取!

















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









