






引言
众所周知,NHANES数据库所包含的是横断面数据,但今天分享的这篇一区top文章,学者另辟蹊径,对横断面数据做了出生队列分析!这个研究思路很新奇,怪不得可以发文JAMA子刊(IF=10.5)!
接下来,让我们一起看看这篇文章!
在过去的几十年里,美国人口总胆固醇和空腹甘油三酯的平均水平大幅下降,但新数据表明,这些趋势的下降速度在年轻人群中已经减缓。相反,糖尿病和肥胖的患病率在该阶段内有所增加,特别是在65岁以下的老年人中。
然而,目前尚不清楚胆固醇、甘油三酯和葡萄糖水平的趋势在不同的年龄段中是如何变化的,以及以体重指数(BMI)衡量的肥胖的不良增加趋势是否与这些模式有关。
2024年12月2日,外国学者用NHANES数据库,在顶级期刊JAMA子刊《JAMA Network Open》(医学一区top,IF=10.5)发表题为:“Cholesterol, Triglyceride, and Glucose Levels Across Birth Cohorts in the US”的研究论文,旨在量化1920~1999年的出生队列中总胆固醇、空腹甘油三酯和空腹血糖水平的变化趋势,并评估体重指数 (BMI)与这些变化趋势之间的关联。
研究结果表明,在该项横断面研究中,年龄越小,体内总胆固醇和空腹甘油三酯水平越低、空腹血糖水平越高。此外,BMI水平在该关联中起到一定的中介作用。
本公号回复“ 原文”即可获得文献PDF等资料。想用NHANES发文,看看这个可一键提取和分析数据的NHANES零代码分析平台!如感兴趣请联系郑老师团队,微信号:aq566665
研究团队基于美国国家健康与营养调查(NHANES)数据库1999~2000年和 2017~2020年的数据,经过纳排,最终纳入了52,006名年龄≥18岁的非孕期状态的美国成年人,加权中位年龄为46岁,其中50.6%为女性。
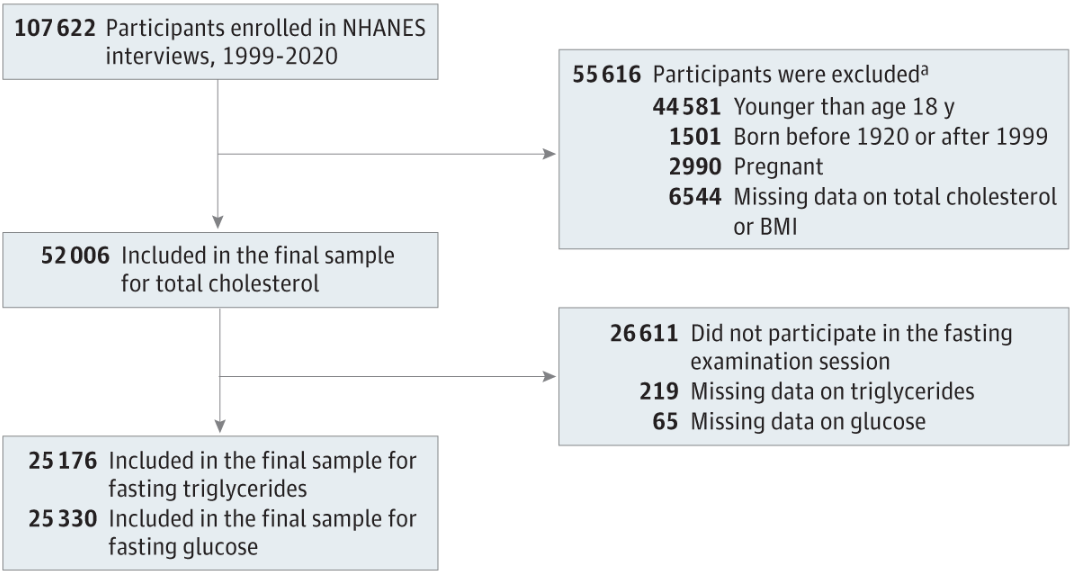
图1 研究人群筛选流程图
主要结果:总胆固醇、空腹甘油三酯、空腹血糖和BMI水平。
研究团队使用分位数回归模型报告了平均边际效应(AME),以量化每相差十年出生的人群,心脏代谢结果指标的平均变化。同时,他们通过参数回归模型估计出生队列与结果的关联,并通过中介分析评估BMI水平在该关联中是否发挥了中介作用。
较晚的出生队列发生心脏代谢疾病的风险更低
研究结果显示,在调整年龄、性别、种族和民族后,相较于较早出生的人群,较晚出生人群的总胆固醇和空腹甘油三酯水平较低、空腹血糖水平较高。
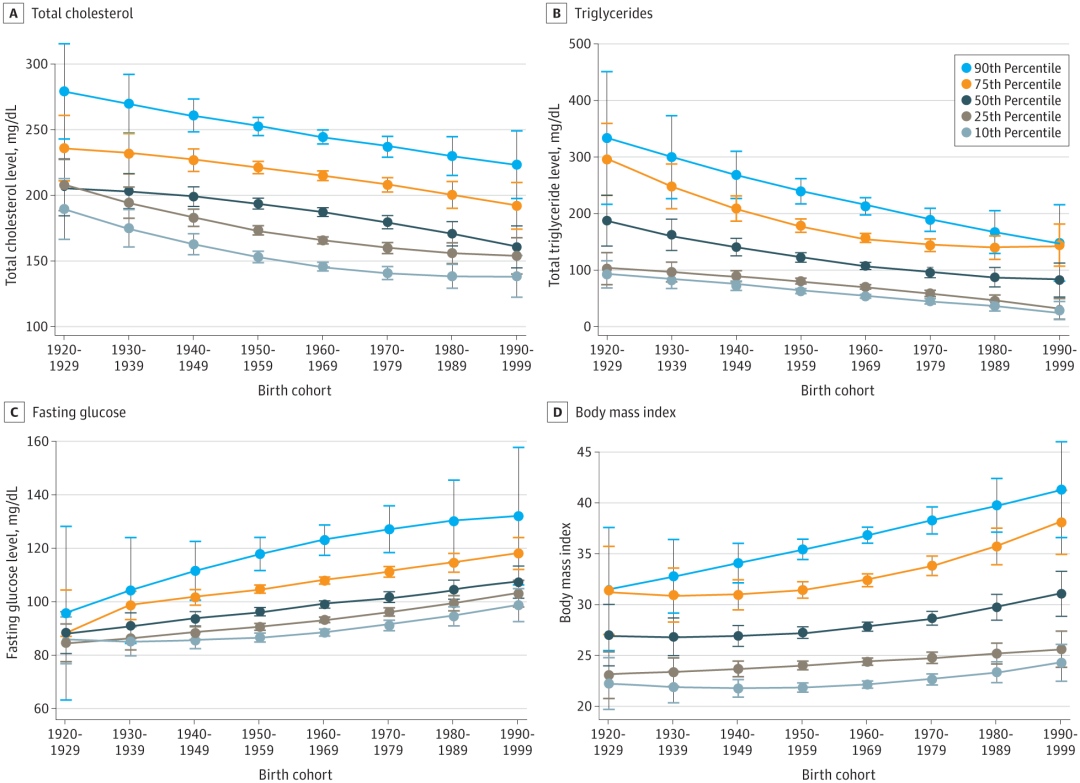
图2 出生队列中总胆固醇、空腹甘油三酯、空腹血糖水平和BMI的趋势
团队采用了五个百分位数(第90、第75、第50、第25和第10个百分位数)来测量各心脏代谢结果指标的水平。其中,以第50个百分位数的测量结果为例,具体表现如下:
总胆固醇水平:每晚10年出生的队列的总胆固醇水平平均降低了7.1mg/dL;
空腹甘油三酯水平:每晚10年出生的队列的空腹甘油三酯水平平均降低13.1mg/dL;
空腹血糖水平:每晚10年出生的队列的空腹血糖水平增加了2.7mg/dL。
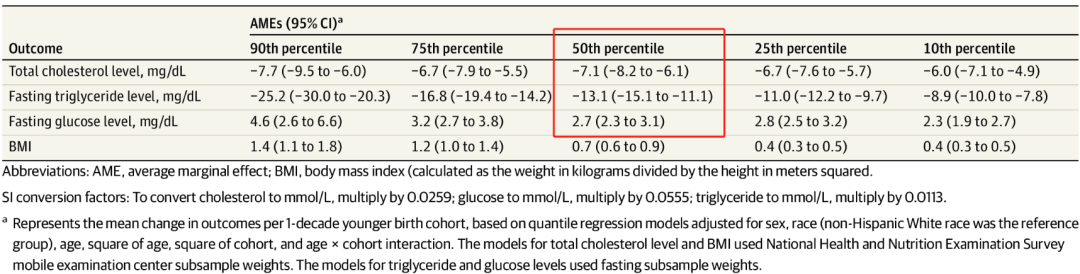
表1 根据总胆固醇、空腹甘油三酯、空腹血糖水平和BMI的分位数调整的出生队列AME
此外,研究结果还表明,BMI在出生队列与总胆固醇、空腹甘油三酯和空腹血糖水平的关联中均起到中介作用。具体结果如下:
BMI减弱了出生队列与体内总胆固醇以及空腹甘油三酯水平的关联;
BMI增强了出生队列与空腹血糖水平之间的关联。
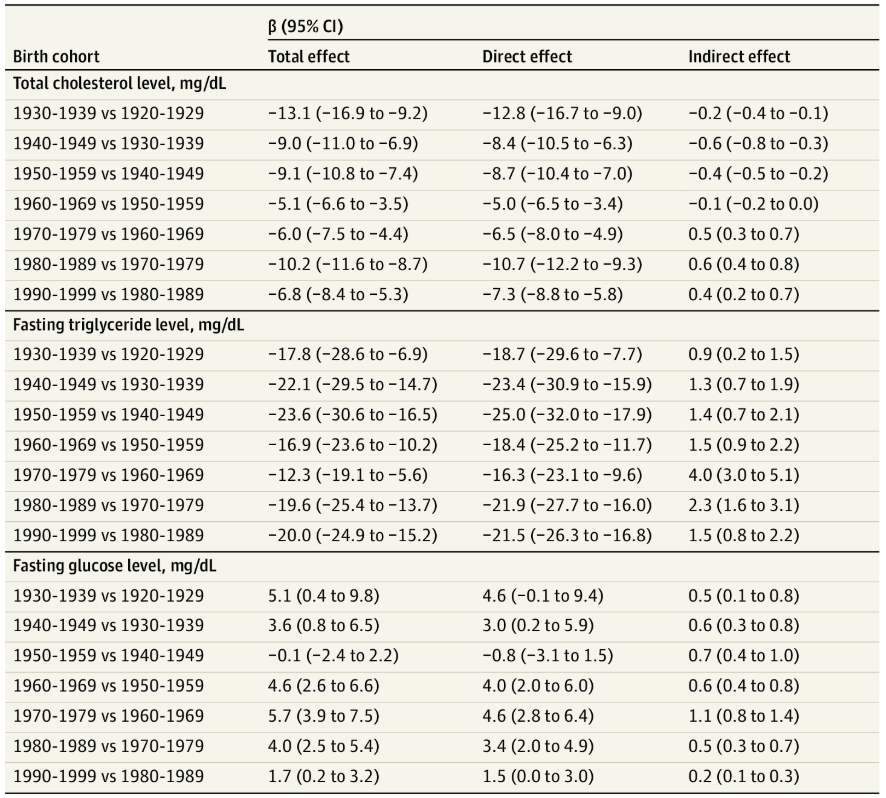
表2 BMI在出生队列与总胆固醇、空腹甘油三酯和空腹血糖水平之间的中介作用
综上所述,相较于较早出生的人群,较晚出生人群的总胆固醇和空腹甘油三酯水平较低,但空腹血糖水平较高。此外,随着BMI水平的升高,这一人群中的总胆固醇和甘油三酯水平的下降趋势减缓,而空腹血糖水平的上升趋势则加速。
今天分享的这篇文章的研究主题非常新颖,很少能看到用NHANES数据做出生队列研究!如果你也对该思路感兴趣但是对选题还有些迷茫,郑老师的NHANES一对一统计服务课程绝对能帮上大忙!专业统计师为你提供个性化选题+统计分析方法指导!现在报名还会送一年的NHANES平台使用权哦!
欢迎关注“公共数据库与孟德尔随机化”公众号,我们将持续为你提供NHANES指标的发文思路和统计分析方法解读!
郑老师统计团队及公众号
全国较大的线上医学统计服务平台,专注于医学生、医护工作者学术研究统计支持,我们是你们统计助理!
我们提供以医学数据数据挖掘统计服务
同时我们提供上述数据库的挖掘的一对一指导
联系助教陈老师咨询(微信号sas555777)


















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









