







作者 北京大学 杨磊
1 问题描述
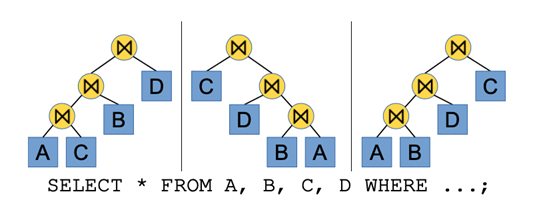
连接顺序选择(Join Order Selection)是数据库系统中非常重要且基本的问题。下图是一个简单的例子来描述这个问题,对于同一个查询有许多种不同的连接顺序,从而就有许多种不同的执行计划。不同的执行计划的查询时间也是千差万别,因此为了能够提升数据库系统的性能,在连接顺序选择问题上,一方面需要最小化枚举的执行计划(搜索开销),另一方面需要最小化最终执行计划的执行时间(执行开销)。传统的方法主要分为两大类,基于动态规划(DP)的算法以及基于贪心策略的算法。基于动态规划的算法是一类穷举型算法,可以得到全局最优解,但是搜索空间会随着关系个数呈指数级增长,因此适用于查询中包含较少关系的搜索,也是PostgreSQL使用的算法。基于贪心策略的算法是一类非穷举型算法,只能得到局部最优解,适用于解决较多关系的搜索,是MySQL中使用的算法。同时,传统方法的执行计划枚举后的代价估计是基于代价估计模型(cost model)的,而代价估计函数会存在不准确的情况,因此传统方法不能够保证最终结果的质量。
2 近来工作
近年来,随着机器学习成为研究的热点,出现了使用深度强化学习(Deep Reinforcement Learning)来解决连接顺序选择问题的方法。首先,之所以使用强化学习,是因为传统方法不能够从历史经验中吸取教训,也就是说传统方法会重复计算出不好的执行计划,而强化学习中的探索和利用策略(exploration and exploitation)既能够利用之前的执行计划中好的选取方式,又可以探索新的可能更好的执行计划。其次,使用深度学习是因为在连接顺序选择问题上想要穷尽所有可能的动作(actions)和奖励(rewards)几乎是不可能的,因此采用神经网络来对它们进行估计。接下来,我们就给大家介绍一下使用上述思路来解决连接顺序选择问题的几个相关工作。
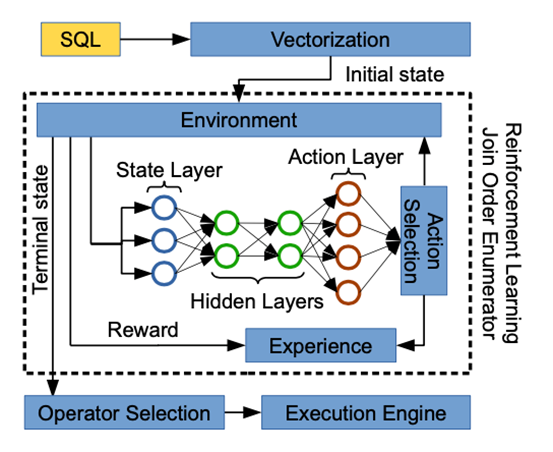
ReJOIN[1]使用了强化学习用于连接顺序的枚举。如下图所示,主要使用了邻近策略优化算法(Proximal Policy Optimization)来指导连接顺序的选择。其中最主要的部分是用于策略选取的神经网络。这个神经网络的输入是向量化的状态信息。主要分为三部分。第一部分是树结构向量,由深度信息和连接信息组成,用于表示连接树的信息;第二部分是连接谓词向量,主要表示在SQL语句中出现的连接谓词对应的查询信息;第三部分是选择性谓词向量,主要表示在SQL语句中出现的选择性谓词对应的表信息和列信息。而神经网络的输出是每一个动作的概率分布,通过概率分布选择下一步的连接动作。对于不同的SQL语句,都会有不同的神经网络参数以及奖励,ReJOIN会根据这些之前的参数和奖励信息,来估计之后的奖励,从而实现对测试集中的SQL也完成连接顺序的枚举。
DQ[2]将连接顺序选择问题抽象为一个马尔可夫决策过程(MarkovDecision Process)。状态G表示为目前还未被连接的关系;动作c表示为在未被连接的关系中任意可能的连接;下一个状态G’表示为原来的状态G去除动作c连接的两个关系加上动作c对应的连接;奖励则表示为新的连接的估计代价。DQ使用了DQN作为强化学习模型来指导连接顺序的选择,由于DQN中的代价估计函数Q-function计算代价过高,因此使用一个两层的MLP来学习Q-function。神经网络的输入是当前的连接状态,包括了SQL语句中的查询信息以及通过连接左侧右侧状态表示的连接操作信息。DQ的设计更加简单更加灵活,方便和不同的数据库系统以及代价模型进行结合。
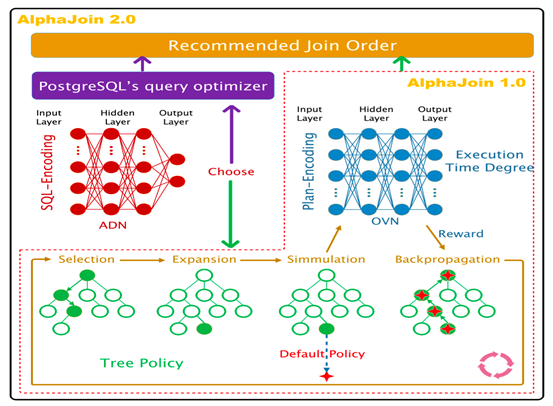
AlphaJoin[3]不同于上述两种方法(使用DRL做连接顺序枚举,代价估计函数做决策),直接对连接顺序的选择做决策。如下图所示,AlphaJoin使用蒙特卡洛树搜索(Monte Carlo Tree Search)来指导连接顺序的选择,这是解决棋类等零和博弈问题(AlphaGO)的常用策略。蒙特卡洛树搜索主要分为以下四步:选择,在当前树中通过某种算法进行选择(比较常见的是UCT算法);扩展,给当前路径增加一个子节点;模拟,使用某种策略(随机、快速)将当前路径补充成为一个完整的路径(从根节点到叶子结点);反向传播,在树上更新模拟次数和模拟结果信息。与DQ类似,在得到一个连接顺序之后,需要通过一个神经网络来估计奖励,神经网络的输入包括了连接次序信息和选择性谓词信息。上述方法被称为Alpha Join 1.0,但是由于直接对连接顺序做了决策,因此决策结果并不完美(接近一般的执行计划结果不如PostgreSQL),因此又增加了一个神经网络用于选择更好的执行计划生成器。
RTOS[4]进一步提出了ReJOIN和DQ方法存在的一些不足,包括(1)向量化编码的神经网络输入信息丢失了一些连接树的结构信息;(2)定长的编码在数据库的模式发生变化时,需要对模型进行重新训练,代价非常高。
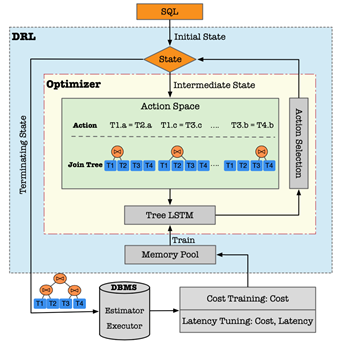
为了解决提出的问题,他们设计了上图所示的RTOS。他们的状态表示分为三部分:通过神经网络表示的SQL语句中的查询信息;通过神经网络表示的表和列信息;以及通过多种Tree-LSTM组合表示的连接树和连接状态信息。前两种信息包含了之前方法提到的三类信息,而后一种则保留了连接顺序以及完整的连接树信息。通过神经网络表示的状态信息的好处在于当需要新增加一列或者一个表时,直接申请新的参数来表示,而不需要完全重新训练。另外,在模型训练方面,RTOS使用了两阶段训练的方法。具体来说,先用cost作为反馈来训练得到cost较低的模型;再用真实执行的latency作为反馈来调整模型参数。
3 实验结果
在实验结果部分,我们使用的是RTOS中的实验结果,因为在实验部分,他们和传统方法以及ReJOIN和DQ都进行了比较实验。
实验采用的benchmark是JOB(Join Order Benchmark)和TPC-H。除了上述我们提到的baseline以外,还比较了SkinnerDB[5](一种基于强化学习策略的方法)和QuickPick(一种贪心算法)。实验结果如下:
-
Cost实验
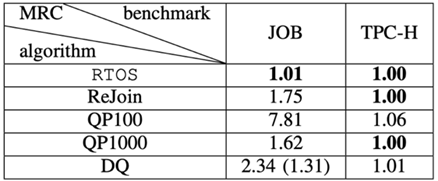
-
Latency实验
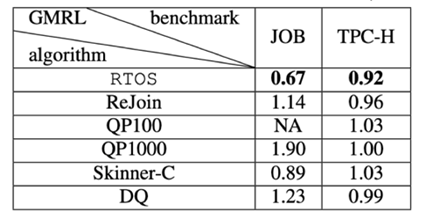
-
案例分析
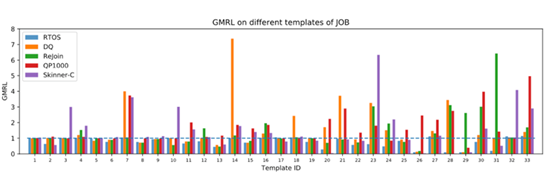
4 总结与思考
除了上述使用DRL来解决连接顺序选择问题的方法外,还有一类基于代价估计函数的方法的,主要是使用机器学习方法来预测基数,从而实现更好的代价估计模型。[6][7]
通过上述介绍,我们可以得出以下结论:
-
基于深度强化学习的方法比传统的算法更加稳定,同时能够适配各种不同的数据、工作负载和数据库环境。
-
在深度强化学习方法中,如果能够很好的设计和实现,进行连接顺序最终决策的这类方法的结果是好于连接顺序枚举+代价估计函数这类方法的。
-
学习类的方法需要很长的训练时间,以及对于不同的工作负载和数据库环境都可能需要重新进行训练,这样在和传统方法的比较中会处于劣势。
-
目前的方法应对的问题还是比较基本的情况,在应对更多新的场景(比如join类型的变化,数据库类型的变化等)会出现新的挑战。
参考文献 :
[1] Marcus R ,Papaemmanouil O . Deep Reinforcement Learning for Join Order Enumeration[C].aiDM. 2018.
[2] Krishnan S ,Yang Z , Goldberg K , et al. Learning to Optimize Join Queries With DeepReinforcement Learning[J]. 2018.
[3] Zhang J. AlphaJoin:Join Order Selection `a la AlphaGo. VLDB Ph.D Workshop, 2020.
[4] Yu X , Li G ,Chai C , et al. Reinforcement Learning with Tree-LSTM for Join OrderSelection[C]// 2020 IEEE 36th International Conference on Data Engineering(ICDE). IEEE, 2020.
[5] Trummer I , WangJ , Maram D , et al. SkinnerDB: Regret-Bounded Query Evaluation viaReinforcement Learning[J]. 2019.
[6] Kipf A , Kipf T, Radke B , et al. Learned Cardinalities: Estimating Correlated Joins with DeepLearning[J]. CIDR 2019.
[7] Yang Z ,Kamsetty A , Luan S , et al. NeuroCard: one cardinality estimator for alltables. Proceedings of the VLDB Endowment, 2020.




















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









