







Transformer架构已经成为自然语言处理任务的事实标准,但其在计算机视觉中的应用仍然有限。在视觉中,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构。论文表明,这种对CNN的依赖是不必要的,直接应用于图像块序列的纯变换器可以很好地执行图像分类任务。
在Transformer的基础上,ViT算法中尝试将标准的Transformer结构直接应用于图像,并对整个图像分类流程进行最少的修改。具体来讲,ViT算法中,会将整幅图像拆分成小图像块,然后把这些小图像块的线性嵌入序列作为Transformer的输入送入网络,然后使用监督学习的方式进行图像分类的训练。
参考论文:https://arxiv.org/pdf/2010.11929.pdf
我们将图像分割成固定大小的面片,线性嵌入每个面片,添加位置嵌入,并将生成的向量序列馈送给标准的Transformer编码器。为了执行分类,我们使用标准方法向序列中添加额外的可学习“分类标记”。
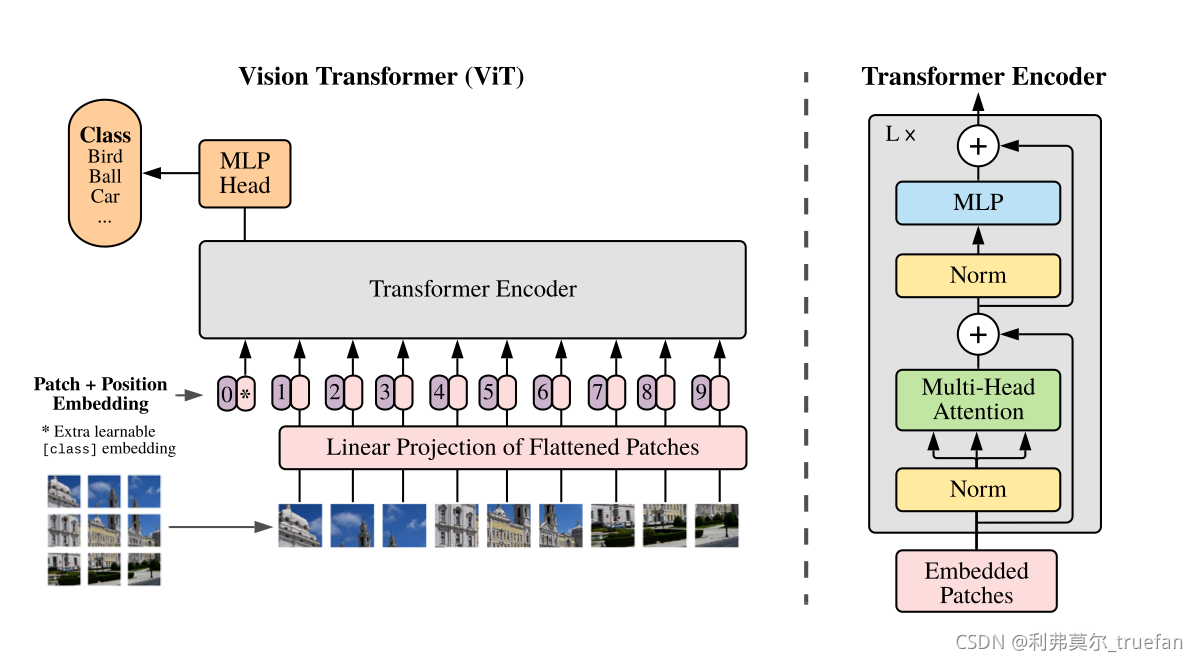
vit 模型结构示意图
作为原始图像块的替代方案,输入序列可以由CNN的特征图形成。在该混合模型中,将面片嵌入投影应用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4647
4647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









