







统计语言模型实际上是一个概率模型,所以常见的概率模型都可以用于求解这些参数
常见的概率模型有:N-gram 模型、决策树、最大熵模型、隐马尔可夫模型、条件随机场、神经网络等
目前常用于语言模型的是 N-gram 模型和神经网络语言模型
一、概率的链式规则(Chain Rule)
朴素贝叶斯中使用的独立性假设为
P
(
x
1
,
x
2
,
x
3
,
.
.
.
,
x
n
)
=
P
(
x
1
)
P
(
x
2
)
P
(
x
3
)
.
.
.
P
(
x
n
)
(1)
P(x_1,x_2,x_3,...,x_n)=P(x_1)P(x_2)P(x_3)...P(x_n) \tag{1}
P(x1,x2,x3,...,xn)=P(x1)P(x2)P(x3)...P(xn)(1)
去掉独立性假设,有下面这个恒等式,即联合概率链规则
P
(
x
1
,
x
2
,
x
3
,
.
.
.
,
x
n
)
=
P
(
x
1
)
P
(
x
2
∣
x
1
)
P
(
x
3
∣
x
1
,
x
2
)
.
.
.
P
(
x
n
∣
x
1
,
x
2
,
.
.
.
,
x
n
−
1
)
(2)
P(x_1,x_2,x_3,...,x_n)=P(x_1)P(x_2|x_1)P(x_3|x_1,x_2)...P(x_n|x_1,x_2,...,x_{n-1}) \tag{2}
P(x1,x2,x3,...,xn)=P(x1)P(x2∣x1)P(x3∣x1,x2)...P(xn∣x1,x2,...,xn−1)(2)
其中,
x
i
x_i
xi代表一个词,联合概率链规则表示句子中每个词都跟前面一个词有关,而独立性假设则是忽略了一个句子中词与词之间的前后关系。
例如:S = 我爱北京天安门,那么此时我们希望知道这句话合理的可能性有多少? 就需要计算 𝑃(我,爱,北,京,天,安,门)
那么上述的概率该如何计算呢?
p ( S ) = p ( 我 ) ⋅ p ( 爱 ∣ 我 ) ⋅ p ( 北 ∣ 爱 , 我 ) ⋅ p ( 京 ∣ 北 , 爱 , 我 ) ⋅ p ( 天 ∣ 京 , 北 , 爱 , 我 ) ⋅ p ( 安 ∣ 天 , 京 , 北 , 爱 , 我 ) ⋅ p ( 门 ∣ 安 , 天 , 京 , 北 , 爱 , 我 ) \begin{aligned} p(S)=&p(我)\\ &·p(爱|我)\\ &·p(北|爱,我)\\ &·p(京|北,爱,我)\\ &·p(天|京,北,爱,我)\\ &·p(安|天,京,北,爱,我)\\ &·p(门|安,天,京,北,爱,我)\\ \end{aligned} p(S)=p(我)⋅p(爱∣我)⋅p(北∣爱,我)⋅p(京∣北,爱,我)⋅p(天∣京,北,爱,我)⋅p(安∣天,京,北,爱,我)⋅p(门∣安,天,京,北,爱,我)
上式中的各个概率的计算方式:
- 可以统计所收集的语料中,总的词语数和“我”出现的次数,计算: p ( 我 ) = 我的次数 所有词语数量 p(我)=\cfrac{我的次数}{所有词语数量} p(我)=所有词语数量我的次数
- p ( 爱 ∣ 我 ) = “我”之后是“爱”的次数 “我”出现的总次数 p(爱|我)=\cfrac{“我”之后是“爱”的次数}{“我”出现的总次数} p(爱∣我)=“我”出现的总次数“我”之后是“爱”的次数
- p ( 北 ∣ 爱 , 我 ) = “我爱”之后是“北”的次数 “我爱”出现的总次数 p(北|爱,我)=\cfrac{“我爱”之后是“北”的次数}{“我爱”出现的总次数} p(北∣爱,我)=“我爱”出现的总次数“我爱”之后是“北”的次数
- … …
语言模型已经训练并计算好了 p ( 我 ) p(我) p(我), p ( 爱 ∣ 我 ) p(爱|我) p(爱∣我), p ( 北 ∣ 爱 , 我 ) p(北|爱,我) p(北∣爱,我), p ( 京 ∣ 北 , 爱 , 我 ) p(京|北,爱,我) p(京∣北,爱,我), p ( 天 ∣ 京 , 北 , 爱 , 我 ) p(天|京,北,爱,我) p(天∣京,北,爱,我), p ( 安 ∣ 天 , 京 , 北 , 爱 , 我 ) p(安|天,京,北,爱,我) p(安∣天,京,北,爱,我), p ( 门 ∣ 安 , 天 , 京 , 北 , 爱 , 我 ) p(门|安,天,京,北,爱,我) p(门∣安,天,京,北,爱,我) 这些概率的值,利用这些已经训练并计算好的概率值来计算输入到语言模型中的一句话是否符合语法的概率值。
我们为什么可以这样来计算概率呢?我们收集的语料可以理解为是对总体的抽样,在不知道总体的情况下,我们可有使用样本的概率来估计总体的概率,这种思想我们把它称为最大似然估计(MLE)。
利用联合概率直接计算一句话符合语法的概率的缺点:很多句子太长了,其概率基本为0,比如: p ( 门 ∣ 安 , 天 , 京 , 北 , 爱 , 我 ) = 0 p(门|安,天,京,北,爱,我)=0 p(门∣安,天,京,北,爱,我)=0
二、 马尔可夫性
马尔可夫性:当一个随机过程在给定当前状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态;换句话说,在给定现在状态时,它与过去状态(即该过程的历史路径)是条件独立的,那么此随机过程即具有马尔可夫性质。具有马尔可夫性质的随机过程通常称之为马尔可夫过程。

三、马尔科夫假设(Markov Assumpton)
联合概率链规则是考虑了句子中每个词之间的前后关系,即第k个词
x
k
x_k
xk与前面 k−1个词
x
1
,
x
2
,
.
.
,
x
k
−
1
x_1,x_2,..,x_{k−1}
x1,x2,..,xk−1 都有关,而马尔科夫假设则是考虑了
n
n
n 个词语之间的前后关系,比如
n
=
2
n=2
n=2 时(2nd Order),第n个词
x
n
x_n
xn 与前面
2
−
1
=
1
2−1=1
2−1=1 个词有关,即:
P
(
x
1
,
x
2
,
x
3
,
.
.
.
,
x
n
)
=
P
(
x
1
)
P
(
x
2
∣
x
1
)
P
(
x
3
∣
x
2
)
.
.
.
P
(
x
n
∣
x
n
−
1
)
(3)
P(x_1,x_2,x_3,...,x_n)=P(x_1)P(x_2|x_1)P(x_3|x_2)...P(x_n|x_{n-1}) \tag{3}
P(x1,x2,x3,...,xn)=P(x1)P(x2∣x1)P(x3∣x2)...P(xn∣xn−1)(3)
比如
n
=
3
n=3
n=3 时(3rd Order),第
n
n
n 个词
x
n
x_n
xn 与前面
3
−
1
=
2
3−1=2
3−1=2 个词有关,即:
P
(
x
1
,
x
2
,
x
3
,
.
.
.
,
x
n
)
=
P
(
x
1
)
P
(
x
2
∣
x
1
)
P
(
x
3
∣
x
1
,
x
2
)
.
.
.
P
(
x
n
∣
x
n
−
2
,
x
n
−
1
)
(4)
P(x_1,x_2,x_3,...,x_n)=P(x_1)P(x_2|x_1)P(x_3|x_1,x_2)...P(x_n|x_{n-2},x_{n-1}) \tag{4}
P(x1,x2,x3,...,xn)=P(x1)P(x2∣x1)P(x3∣x1,x2)...P(xn∣xn−2,xn−1)(4)
公式(3)(4)即马尔科夫假设(Markov Assumption):即下一个词的出现仅依赖于它前面的一个或几个词。

四、语言模型的定义
语言模型的定义:
- 以一个符合语言规律的序列为输入,模型将利用序列间关系等特征,输出一个在所有词汇上的概率分布.这样的模型称为语言模型.
- 为单词序列分配概率的模型就叫做语言模型。即对于单词序列 w 1 , w 2 , w 3 , . . . w n w_1,w_2,w_3,...w_n w1,w2,w3,...wn ,计算 p ( w 1 , w 2 , w 3 , . . . w n ) p(w_1,w_2,w_3,...w_n) p(w1,w2,w3,...wn) 的模型就是语言模型
- 通俗来说,语言模型就是这样一个模型:对于任意的词序列,它能够计算出这个序列是一句话的概率。或者说语言模型能预测单词序列的下一个词是什么。
语言模型能解决哪些问题:
- 根据语言模型的定义,可以在它的基础上完成机器翻译,文本生成等任务,因为我们通过最后输出的概率分布来预测下一个词汇是什么.
- 语言模型可以判断输入的序列是否为一句完整的话,因为我们可以根据输出的概率分布查看最大概率是否落在句子结束符上,来判断完整性.
- 语言模型本身的训练目标是预测下一个词,因为它的特征提取部分会抽象很多语言序列之间的关系,这些关系可能同样对其他语言类任务有效果。因此可以作为预训练模型进行迁移学习.
语言模型的基本思想:句子中下一个词的出现和前面的词是有关系的,所以可以使用前面的词预测下一个词。

用Pre-trained Model 来计算一句话符合语法的概率

用频率估计概率的思想,假设我们可以找到足够大的一个语料(例如网络上的所有中文或者英文网页)。我们计算出单词序列
(
w
1
,
w
2
,
w
3
,
.
.
.
w
n
)
(w_1,w_2,w_3,...w_n)
(w1,w2,w3,...wn) 出现的次数
n
n
n,其中
w
i
∈
V
w_i∈V
wi∈V,
V
=
{
v
1
,
v
2
,
v
3
,
.
.
.
v
∣
V
∣
}
V=\{v_1,v_2,v_3,...v_{|V|}\}
V={v1,v2,v3,...v∣V∣} 表示字典,而所有的序列个数记为
N
N
N,则:
p
(
w
1
,
w
2
,
w
3
,
.
.
.
w
n
)
=
n
N
p(w_1,w_2,w_3,...w_n)=\cfrac{n}{N}
p(w1,w2,w3,...wn)=Nn
可以看出这个模型有一个问题,一旦单词序列没有在训练集中出现过,模型的输出概率就是0,并且我们知道,语言是具有创造性的,所以这样计算相当不合理。并且这样计算一个给定序列的概率也需要语料足够的大才有实际意义。因此我们需要更聪明的方法来计算
p
(
w
1
,
w
2
,
w
3
,
.
.
.
w
n
)
p(w_1,w_2,w_3,...w_n)
p(w1,w2,w3,...wn) ,比如:N-gram语言模型。
五、N-gram语言模型(机器学习)
加入n-gram特征的作用:将n-gram表示作为特征,能够补充特征中没有上下文关联的缺点,将有效帮助模型捕捉上下文的语义关联。
N-gram是一种统计语言模型,它基于马尔科夫假设。使用统计学的方式,来表达文本中词汇分布情况的一种模型。整体文本的分布概率可以使用每个词汇条件概率的连乘来表示。
N-gram优点:
- 基于有限的历史所以效率高;
N-gram缺点:
- 无法体现文本相似度,
- 无法关联更早的信息。
在计算某个单词的概率的时候,不去考虑它的全部历史,而只考虑最接近的N个词语,从而近似的逼近该单词的历史,这就是N-gram的直观的解释。
- 如果对向量 X 采用条件独立假设,就是朴素贝叶斯方法。
- 如果对向量 X 采用马尔科夫假设,就是N-gram语言模型。
- Bigram 在 所有N-gram中使用最多
- N一般不超过5
1、N-gram种类
1.1 Unigram(1-gram):基于朴素贝叶斯假设
假设所有单词都是独立的个体



1.2 Bigram(2-gram):基于 2nd Order 马尔科夫假设
假设所有单词只与前一个单词有关。



1.3 Trigram(3-gram):基于 2nd Order 马尔科夫假设
假设所有单词只与前2个单词有关


2、N-gram语言模型的平滑方法
当我们使用极大似然估计(MLE)来计算某个词语的概率的时候,会出现在语料库中出现的次数太少,或者是没有出现的现象,那么此时该单词算出来的概率就为0,那么会导致整个句子的概率为0(OOV:out of vocabulary)。为了避免这个情况,我们使用平滑的方法,对计算的结果进行修正。
平滑过程中:我们会削减来自高计数的概率,然后去填补0计数的概率。
训练语料库里没有出现的单词有可能在测试集里出现
零概率问题,就是在计算实例的概率时,如果某个量x,在训练集中没有出现过,会导致整个实例的概率结果是0。在语言模型的问题中,当一个词语没有在训练样本中出现,该词语调概率为0,使用连乘计算文本出现概率时也为0。这是不合理的,不能因为一个事件没有观察到就武断的认为该事件的概率是0。
2.1 Add-One Smoothing(加1平滑 / 拉普拉斯平滑,Laplace Smoothing)
该方法在朴素贝叶斯里用的比较多

分母上使用V而不是其他的任意值,是为了让所有概率相加后等于1。

2.2 Add-K Smoothing

如何选择
k
k
k 值:可以通过枚举法尝试哪个
k
k
k 值时最优的;或者通过语言模型在测试集上的优化来得到最优的
k
k
k 值

2.3 Interpolation



2.4 Good-Turning Smoothing
该方法在语言模型里用的比较多




Good-Turning Smoothing 方法的缺点:有些频次的单词数量为0
解决方法:通过机器学习的方法拟合出一条曲线,把缺失值填补上。
3、N-gram语言模型的评估
3.1 Perplexity/PPL(困惑度)
在测试集上,我们经常使用困惑度来判断语言模型的好坏,困惑度是语言模型指派给测试集的概率函数
对于测试集
W
=
w
1
,
w
2
,
.
.
.
,
w
n
W=w_1,w_2,...,w_n
W=w1,w2,...,wn ,困惑度的计算如下(其中的各个概率
p
p
p 都是根据训练集统计得到):

其中:
n
n
n 是句子长度;
对于二元语法模型:

由此可见:如果某个词语的组合困惑度越小,意味着其中单词概率的乘积越大。
例如:我们有一个序列,包含10个词语,每个词语出现的概率都相等为1/10,那么此时序列的困惑度为多少?

向待评估的模型A、B、C分别喂入一句话,计算各个模型的Perplexity,Perplexity越小的模型效果越好。
N-gram中的N越大,语言模型的Perplexity越小,但是该语言模型也越容易过拟合


3.2 BPC(bits-per-character)
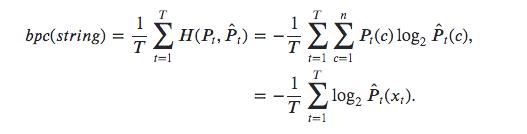
论文:《Generating Sequences With Recurrent Neural Networks》中指出:当以每个单词为一个字符计算bpc时,存在以下关系:
2
B
P
C
=
P
P
L
2^{BPC}=PPL
2BPC=PPL
4、利用N-gram计算字符串间的距离
我们除了可以定义两个字符串之间的“编辑距离”(通常利用Needleman-Wunsch算法或Smith-Waterman算法)之外,还可以定义两个字符串之间的N-Gram距离。N-Gram(有时也称为N元模型)是自然语言处理中一个非常重要的概念。假设有一个字符串 s s s,那么该字符串的N-Gram就表示按长度 N 切分原词得到的词段,也就是 s s s 中所有长度为 N 的子字符串。设想如果有两个字符串,然后分别求它们的N-Gram,那么就可以从它们的共有子串的数量这个角度去定义两个字符串间的N-Gram距离。但是仅仅是简单地对共有子串进行计数显然也存在不足,这种方案显然忽略了两个字符串长度差异可能导致的问题。比如字符串 girl 和 girlfriend,二者所拥有的公共子串数量显然与 girl 和其自身所拥有的公共子串数量相等,但是我们并不能据此认为 girl 和girlfriend 是两个等同的匹配。
为了解决该问题,有学者便提出以非重复的N-Gram分词为基础来定义 N-Gram距离这一概念,可以用下面的公式来表述:
∣
G
N
(
s
)
∣
+
∣
G
N
(
t
)
∣
−
2
×
∣
G
N
(
s
)
∩
G
N
(
t
)
∣
|G_N(s)|+|G_N(t)|−2×|G_N(s)∩G_N(t)|
∣GN(s)∣+∣GN(t)∣−2×∣GN(s)∩GN(t)∣
此处, |G_N(s)| 是字符串 s s s 的 N-Gram集合,N 值一般取2或者3。以 N = 2 为例对字符串Gorbachev和Gorbechyov进行分段,可得如下结果(我们用下画线标出了其中的公共子串)。

结合上面的公式,即可算得两个字符串之间的距离是8 + 9 − 2 × 4 = 9。显然,字符串之间的距离越小,它们就越接近。当两个字符串完全相等的时候,它们之间的距离就是0。
def Ngram_distance(str1, str2, n=2):
tmp = ' ' * (n-1)
str1, str2 = tmp + str1 + tmp, tmp + str2 + tmp #表示以首字母开头和本char结尾
print("\nstr1 = {0}----str2 = {1}".format(str1, str2))
set1, set2 = set([str1[i:i+n] for i in range(len(str1)-(n-1))]), set([str2[i:i+n] for i in range(len(str2)-(n-1))])
setx = set1 & set2 # 并集
print("set1 = {0}----set2 = {1}----并集:setx = {2}".format(set1, set2, setx))
len1, len2, lenx = len(set1), len(set2), len(setx)
print("str1集合大小:len1 = {0}----str2集合大小:len2 = {1}----并集大小:lenx = {2}".format(len1, len2, lenx))
num_dist = len1 + len2 - 2*lenx # N-Gram距离
num_sim = 1 - num_dist / (len1 + len2)
return set1,set2,{'dist': num_dist, 'sim': num_sim}
if __name__=="__main__":
a_set1, a_set2, a_dist = Ngram_distance('girl','girlfriend')
b_set1, b_set2, b_dist = Ngram_distance('Gorbachev', 'Gorbechyov')
print("="*100)
print("a_set1 = {0}\na_set2 = {1}\na_dist = {2}".format(a_set1, a_set2, a_dist))
print("-" * 100)
print("b_set1 = {0}\nb_set2 = {1}\nb_dist = {2}".format(b_set1, b_set2, b_dist))
输出结果:
str1 = girl ----str2 = girlfriend
set1 = {'ir', 'rl', 'gi', ' g', 'l '}----set2 = {'ir', 'rl', 'gi', 'nd', 'd ', 'fr', 'ri', 'en', ' g', 'lf', 'ie'}----并集:setx = {'gi', 'ir', 'rl', ' g'}
str1集合大小:len1 = 5----str2集合大小:len2 = 11----并集大小:lenx = 4
str1 = Gorbachev ----str2 = Gorbechyov
set1 = {'v ', 'Go', 'or', ' G', 'rb', 'he', 'ba', 'ch', 'ev', 'ac'}----set2 = {'be', 'v ', 'Go', 'or', ' G', 'ov', 'rb', 'ec', 'yo', 'hy', 'ch'}----并集:setx = {'v ', 'Go', 'or', ' G', 'rb', 'ch'}
str1集合大小:len1 = 10----str2集合大小:len2 = 11----并集大小:lenx = 6
====================================================================================================
a_set1 = {'ir', 'rl', 'gi', ' g', 'l '}
a_set2 = {'ir', 'rl', 'gi', 'nd', 'd ', 'fr', 'ri', 'en', ' g', 'lf', 'ie'}
a_dist = {'dist': 8, 'sim': 0.5}
----------------------------------------------------------------------------------------------------
b_set1 = {'v ', 'Go', 'or', ' G', 'rb', 'he', 'ba', 'ch', 'ev', 'ac'}
b_set2 = {'be', 'v ', 'Go', 'or', ' G', 'ov', 'rb', 'ec', 'yo', 'hy', 'ch'}
b_dist = {'dist': 9, 'sim': 0.5714285714285714}
Process finished with exit code 0
5、利用N-Gram模型评估语句是否合理
从现在开始,我们所讨论的N-Gram模型跟前面讲过N-Gram模型从外在来看已经大不相同,但是请注意它们内在的联系(或者说本质上它们仍然是统一的概念)。
为了引入N-Gram的这个应用,我们从几个例子开始。
首先,从统计的角度来看,自然语言中的一个句子 ss 可以由任何词串构成,不过概率
P
(
s
)
P(s)
P(s) 有大有小。例如:
- s 1 s_1 s1 = 我刚吃过晚饭
- s 2 s_2 s2 = 刚我过晚饭吃
显然,对于中文而言 s 1 s1 s1 是一个通顺而有意义的句子,而s2s2 则不是,所以对于中文来说, P ( s 1 ) > P ( s 2 ) P(s1)>P(s2) P(s1)>P(s2) 。但不同语言来说,这两个概率值的大小可能会反转。
其次,另外一个例子是,如果我们给出了某个句子的一个节选,我们其实可以能够猜测后续的词应该是什么,例如
- the large green __ . Possible answer may be “mountain” or “tree” ?
- Kate swallowed the large green __ . Possible answer may be “pill” or “broccoli” ?
显然,如果我们知道这个句子片段更多前面的内容的情况下,我们会得到一个更加准确的答案。这就告诉我们,前面的(历史)信息越多,对后面未知信息的约束就越强。
如果我们有一个由 mm 个词组成的序列(或者说一个句子),我们希望算得概率
P
(
w
1
,
w
2
,
⋯
,
w
m
)
P(w1,w2,⋯,wm)
P(w1,w2,⋯,wm) ,根据链式规则,可得
P
(
w
1
,
w
2
,
⋯
,
w
m
)
=
P
(
w
1
)
P
(
w
2
∣
w
1
)
P
(
w
3
∣
w
1
,
w
2
)
⋯
P
(
w
m
∣
w
1
,
⋯
,
w
m
−
1
)
P(w_1,w_2,⋯,w_m)=P(w_1)P(w_2|w_1)P(w_3|w_1,w_2)⋯P(w_m|w_1,⋯,w_{m−1})
P(w1,w2,⋯,wm)=P(w1)P(w2∣w1)P(w3∣w1,w2)⋯P(wm∣w1,⋯,wm−1)
特别地,对于 n n n 取得较小值的情况
- 当 n = 1 n=1 n=1, 一个一元模型(unigram model)即为
P ( w 1 , w 2 , ⋯ , w m ) = ∑ i = 1 m P ( w i ) P(w_1,w_2,⋯,w_m)=\sum_{i=1}^mP(w_i) P(w1,w2,⋯,wm)=i=1∑mP(wi)
- 当 n = 2 n=2 n=2, 一个二元模型(bigram model)即为
P ( w 1 , w 2 , ⋯ , w m ) = ∑ i = 1 m P ( w i ∣ w i − 1 ) P(w_1,w_2,⋯,w_m)=\sum_{i=1}^mP(w_i|w_{i−1}) P(w1,w2,⋯,wm)=i=1∑mP(wi∣wi−1)
- 当 n = 3 n=3 n=3, 一个三元模型(trigram model)即为
P ( w 1 , w 2 , ⋯ , w m ) = ∑ i = 1 m P ( w i ∣ w i − 2 w i − 1 ) P(w_1,w_2,⋯,w_m)=\sum_{i=1}^mP(w_i|w_{i−2}w_{i−1}) P(w1,w2,⋯,wm)=i=1∑mP(wi∣wi−2wi−1)
接下来的思路就比较明确了,可以利用最大似然法来求出一组参数,使得训练样本的概率取得最大值。
- 对于unigram model而言,其中 c ( w 1 , . . , w n ) c(w_1,..,w_n) c(w1,..,wn)表示 n-gram w 1 , . . , w n w_1,..,w_n w1,..,wn 在训练语料中出现的次数, M M M 是语料库中的总字数(例如对于 yes no no no yes 而言, M = 5 M=5 M=5)
P ( w i ) = C ( w i ) M P(w_i)=\cfrac{C(w_i)}{M} P(wi)=MC(wi)
- 对于bigram model而言,
P ( w i ∣ w i − 1 ) = C ( w i − 1 w i ) C ( w i − 1 ) P(w_i|w_{i−1})=\cfrac{C(w_{i−1}w_i)}{C(w_{i−1})} P(wi∣wi−1)=C(wi−1)C(wi−1wi)
- 对于n-gram model而言,
P ( w i ∣ w i − n − 1 , ⋯ , w i − 1 ) = C ( w i − n − 1 , ⋯ , w i ) C ( w i − n − 1 , ⋯ , w i − 1 ) P(w_i|w_{i−n−1},⋯,w_{i−1})=\cfrac{C(w_{i−n−1},⋯,w_i)}{C(w_{i−n−1},⋯,w_{i−1})} P(wi∣wi−n−1,⋯,wi−1)=C(wi−n−1,⋯,wi−1)C(wi−n−1,⋯,wi)
5.1 Unigram Model举例
对于unigram model而言,其中
c
(
w
1
,
.
.
,
w
n
)
c(w_1,..,w_n)
c(w1,..,wn)表示 n-gram
w
1
,
.
.
,
w
n
w_1,..,w_n
w1,..,wn 在训练语料中出现的次数,
M
M
M 是语料库中的总字数(例如对于 yes no no no yes 而言,
M
=
5
M=5
M=5)
P
(
w
i
)
=
C
(
w
i
)
M
P(w_i)=\cfrac{C(w_i)}{M}
P(wi)=MC(wi)
如下表所示,计算Unigram Prior Probability(word总数:404,253,213)

5.2 Bigram Model举例
P ( w i ∣ w i − 1 ) = C ( w i − 1 w i ) C ( w i − 1 ) P(w_i|w_{i−1})=\cfrac{C(w_{i−1}w_i)}{C(w_{i−1})} P(wi∣wi−1)=C(wi−1)C(wi−1wi)
假设现在有一个语料库,我们统计了下面一些词出现的数量

下面这个表给出的是基于Bigram模型进行计数之结果

例如,其中第一行,第二列 表示给定前一个词是 “i” 时,当前词为“want”的情况一共出现了827次。因为我们从表1中知道 “i” 一共出现了2533次,而其后出现 “want” 的情况一共有827次,所以:
P ( w a n t ∣ i ) = C ( i w a n t ) C ( i ) = 827 2533 = 0.33 P(want|i)=\cfrac{C(i\ want)}{C(i)}=\cfrac{827}{2533}=0.33 P(want∣i)=C(i)C(i want)=2533827=0.33
据此,我们便可以算得相应的频率分布表如下。

现在设
s
1
s1
s1=“<s>i want english food</s>” ,下面这个概率作为其他一些已知条件给出:

则可以算得

5.3 Trigram Model举例
P ( w i ∣ w i − 2 , w i − 1 ) = C ( w i − 2 w i − 1 w i ) C ( w i − 2 w i − 1 ) P(w_i|w_{i−2},w_{i−1})=\cfrac{C(w_{i−2}w_{i−1}w_i)}{C(w_{i−2}w_{i−1})} P(wi∣wi−2,wi−1)=C(wi−2wi−1)C(wi−2wi−1wi)
来看一个具体的例子,假设我们现在有一个语料库如下,其中 <s1> <s2> 是句首标记, </s1> </s2> 是句尾标记:
<s1> <s2>
y
e
s
n
o
n
o
n
o
n
o
y
e
s
yes \quad no \quad no \quad no \quad no \quad yes
yesnonononoyes </s1> </s2>
<s1> <s2>
n
o
n
o
n
o
y
e
s
y
e
s
y
e
s
n
o
no \quad no \quad no \quad yes \quad yes \quad yes \quad no
nononoyesyesyesno </s1> </s2>
下面我们的任务是来评估如下这个句子的概率:
<s1> <s2> y e s n o n o y e s yes \quad no\quad no\quad yes yesnonoyes </s1> </s2>
我们来演示利用trigram模型来计算概率的结果

所以我们要求的概率就等于:

6、N-gram 语言模型的局限性
基于最大似然估计的语言模型很容易训练,可解释性强,也可以扩充到大规模语料。但是仍然有几个重要的缺点:
- 人工设计的 N 元模型无法捕捉更长距离的依赖关系。
- 当我们尝试增加 N 去捕捉长依赖的时候,会让参数呈指数级增长。
- 添加N-gram之后的语句即使考虑了句子中词语的顺序,但是也是句子表面上统计的含义,没法表示句子隐含的语义特征,导致泛化能力弱。
- 泛化能力弱,根据现有语料统计出的 黑汽车 和 蓝汽车,假如我们没有看到 红汽车,会导致我们无法计算红汽车的概率。
7、英文单词拼写纠错【考虑N-Gram模型概率、用户常见错词表概率】
import math
import nltk
nltk.download('reuters') # 下载训练数据集【位置:C:\Users\surface\AppData\Roaming\nltk_data】
nltk.download('punkt') # 下载训练数据集【位置:C:\Users\surface\AppData\Roaming\nltk_data】
from nltk.corpus import reuters # reuters路透社语料库
# 读取语料库
categories = reuters.categories() # 路透社语料库的类别
print("len(categories) = {}----categories[:5] = {}".format(len(categories), categories[:5]))
corpus = reuters.sents(categories=categories) # sents()指定分类中的句子
print("len(corpus) = {}----corpus[:5] = {}".format(len(corpus), corpus[:5]))
#==== 加载带有概率的词库 ====
word_freq_list = list(set([line.rstrip() for line in open('vocab.txt')])) #用set效率高一些(时间复杂度)
vocab = {}
for word_freq in word_freq_list:
word, freq = word_freq.split("\t")
vocab[word.strip()] = int(freq)
print("list(vocab.items())[:10] = {0}".format(list(vocab.items())[:10]))
# 生成单词的所有候选集合【给定输入(错误地输入)的单词,由编辑距离的4种操作(insert, delete, replace,transposes),返回该单词所有候选集合。返回所有(valid)候选集合】
def edits1(word): # word: 给定的输入(错误的输入)
# 生成编辑距离不大于1的单词
# 1.insert 2. delete 3. replace 4. transposes
# appl: replace: bppl, cppl, aapl, abpl...
# insert: bappl, cappl, abppl, acppl....
# delete: ppl, apl, app
# transposes:papl
letters = 'abcdefghijklmnopqrstuvwxyz' # 假设使用26个字符
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)] # 将单词在不同的位置拆分成2个字符串,然后分别进行insert,delete你replace操作,拆分形式为:[('', 'apple'), ('a', 'pple'), ('ap', 'ple'), ('app', 'le'), ('appl', 'e'), ('apple', '')]
inserts = [L + c + R for L, R in splits for c in letters] # insert操作
deletes = [L + R[1:] for L, R in splits if R] # delete操作:判断分割后的字符串R是否为空,不为空,删除R的第一个字符即R[1:]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters] # replace操作:替换R的第一个字符,即c+R[1:]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R) > 1] # transposes操作:交换R的第一个字符与第二个字符
edit1_words = list(set(inserts + deletes + replaces + transposes))
return edit1_words
# 给定一个字符串,生成编辑距离不大于2的字符串【在生成的与正确单词编辑距离不大于1的单词的基础上,再次进行insert, delete, replace操作,从而生成编辑距离不大于2的所有候选集合】
def edits2(word):
edit2_words = [e2 for e1 in edits1(word) for e2 in edits1(e1)]
return edit2_words
# 检查单词是否是单词库中的拼写正确的单词【过滤掉不存在于词典库里面的单词】
def known(edit_words):
return list(set(edit_word for edit_word in edit_words if edit_word in vocab))
#==== 根据编辑距离为1返回候选词【在单词库中存在的】 ====
def candidates_1(word):
original_word = [word] # 原单词
edit1_words = edits1(word) # 编辑距离为1的候选字符串
known_original_word = known(original_word) # 过滤掉不存在于词典库里面的单词
known_edit1_words = known(edit1_words) # 过滤掉不存在于词典库里面的单词
candidates = known_original_word + known_edit1_words
# print("len(original_word) = {0}----original_word = {1}".format(len(original_word), original_word))
# print("len(edit1_words) = {0}----edit1_words = {1}".format(len(edit1_words), edit1_words))
# print("len(known_original_word) = {0}----known_original_word = {1}".format(len(known_original_word), known_original_word))
print("len(known_edit1_words) = {0}----known_edit1_words = {1}".format(len(known_edit1_words), known_edit1_words))
return candidates
#==== 根据编辑距离为1、2返回候选词【在单词库中存在的】 ====
def candidates_1_2(word):
original_word = [word] # 原单词
edit1_words = edits1(word) # 编辑距离为1的候选字符串
edit2_words = edits2(word) # 编辑距离为2的候选字符串
known_original_word = known(original_word) # 过滤掉不存在于词典库里面的单词
known_edit1_words = known(edit1_words) # 过滤掉不存在于词典库里面的单词
known_edit2_words = known(edit2_words) # 过滤掉不存在于词典库里面的单词
candidates = list(set(known_original_word + known_edit1_words + known_edit2_words))
# print("len(original_word) = {0}----original_word = {1}".format(len(original_word), original_word))
# print("len(edit1_words) = {0}----edit1_words = {1}".format(len(edit1_words), edit1_words))
# print("len(edit2_words) = {0}----edit2_words = {1}".format(len(edit2_words), edit2_words))
# print("len(known_original_word) = {0}----known_original_word = {1}".format(len(known_original_word), known_original_word))
print("len(known_edit1_words) = {0}----known_edit1_words = {1}".format(len(known_edit1_words), known_edit1_words))
print("len(known_edit2_words) = {0}----known_edit2_words = {1}".format(len(known_edit2_words), known_edit2_words))
return candidates
#==== 输出概率最大的纠正词 ====
def correction(error_word=None,distance=None): # distance为编辑距离参数
if distance==1:
candidates_words = candidates_1(error_word)
print("candidates_words = {}".format(candidates_words))
else:
candidates_words = candidates_1_2(error_word)
print("candidates_words = {}".format(candidates_words))
return candidates_words
# =====================================构建语言模型:unigram、bigram(方式:保存所有训练数据集中的单个单词、相邻2个单词在一起的数量,用于计算条件概率p(a,b|a))=====================================
unigram_count = {}
bigram_count = {}
def build_bigram_model():
for doc in corpus:
doc = ['<s>'] + doc # '<s>'表示开头
for i in range(0, len(doc) - 1):
term = doc[i] # term是doc中第i个单词
bigram = doc[i:i + 2] # bigram为第i,i+1个单词组成的 [i,i+1]
if term in unigram_count:
unigram_count[term] += 1 # 如果term存在unigram_count中,则加1
else:
unigram_count[term] = 1 # 如果不存在,则添加,置为1
bigram = ' '.join(bigram)
if bigram in bigram_count:
bigram_count[bigram] += 1
else:
bigram_count[bigram] = 1
print("len(unigram_count) = {0}----举例:list(unigram_count.items())[:10] = {1}".format(len(unigram_count), list(unigram_count.items())[:10]))
print("len(bigram_count) = {0}----举例:list(bigram_count.items())[:10]= {1}".format(len(bigram_count), list(bigram_count.items())[:10]))
# =====================================用户打错的概率统计 - channel probability=====================================
# 该文件记录了很多用户写错的单词和对应正确的单词,可以通过该文件确定每个正确的单词所对应的错误拼写方式,并计算出每个错误拼写方式出现的概率
channel_prob = {}
def chann_prob():
for line in open('./spell-errors.txt'):
items = line.split(":")
correct = items[0].strip()
mistakes = [item.strip() for item in items[1].strip().split(",")]
channel_prob[correct] = {}
for mis in mistakes:
channel_prob[correct][mis] = math.log(1.0/len(mistakes))
print("len(channel_prob) = {0}----list(channel_prob.items())[:10]= {1}".format(len(channel_prob), list(channel_prob.items())[:10]))
if __name__=="__main__":
build_bigram_model() # 构建 N-Gram 数据模型,保存位置:unigram_count.txt、bigram_count.txt
chann_prob() # 构建 用户写错的单词和对应正确的单词 数据模型,保存位置:channel_prob.txt
# 测试单个单词的拼写纠错功能
# word = "foreigh"
# print("-"*30,"根据编辑距离为1进行纠错","-"*30)
# correction_1_result = correction(word=word, distance=1)
# print('word = {0}----根据词典库词频顺序取最大可能性的候选词:correction_1_result = {1}'.format(word, correction_1_result))
# print("-" * 30, "根据编辑距离为1&2进行纠错", "-" * 30)
# correction_1_result = correction(word=word, distance=2)
# print('word = {0}----根据词典库词频顺序取最大可能性的候选词:correction_1_result = {1}'.format(word, correction_1_result))
# 测试一句话的单词拼写功能
V = len(unigram_count.keys())
line = ['In', 'China', 'English', 'is', 'taken', ' to', ' be', ' a', 'foreigh', ' language ', 'which ', 'many ', 'students ', 'choose ', 'to ', 'learn']
j = 0
for word in line:
if vocab.get(word.strip().lower()) is None:
error_word = word
print("\n","="*40, "当前单词拼写错误(不在给定的vocab词典库中):{}".format(error_word), "="*40)
# 需要替换error_word成正确的单词
# Step1: 生成所有的(valid)候选集合
candidates = correction(error_word=error_word, distance=2)
print("生成所有的(valid)候选集合---->candidates = {0}".format(candidates))
if len(candidates) < 1:
continue
candi_probs = []
# 对于每一个candidate, 计算它的概率值score,返回score最大的candidate 【score = p(correct)*p(mistake|correct) = log p(correct) + log p(mistake|correct)】
for candidate in candidates:
print("-"*30, "candidate = {}".format(candidate), "-"*30)
candi_prob = 0 # 初始化当前候选词的概率
# 1、计算候选词的 channel probability概率,并加入到prob中【如果在spell-errors.txt文件中当前候选词的拼写错误列表中有当前的拼写错误word,则当前候选词加上其概率值】
if candidate in channel_prob and word in channel_prob[candidate]: # candidate: freight; channel_prob[candidate]= frieght, foreign
print("candidate = {0}----channel_prob[candidate] = {1}----channel_prob[candidate][word]={2}".format(candidate, str(channel_prob[candidate]), channel_prob[candidate][word]))
chann_prob = channel_prob[candidate][word]
print("candidate = {0}----chann_prob = {1}".format(candidate, chann_prob))
candi_prob += chann_prob
else:
candi_prob += math.log(0.0001)
# 2、计算候选词的语言模型的概率
# 2.1 考虑前一个词【比如:候选词word=freight,此时计算“a freight”出现的概率】
if j > 0:
forward_word = line[j - 1] + " " + candidate # 考虑前一个单词,出现like playing的概率
print("forward_word = {0}----line[j - 1] = {1}".format(forward_word, line[j - 1]))
if forward_word in bigram_count and line[j - 1] in unigram_count:
forward_prob = math.log((bigram_count[forward_word] + 1.0) / (unigram_count[line[j - 1]] + V)) # 加1平滑计算:在word出现的情况下,forward_word出现的概率。
print("candidate = {0}----forward_prob = {1}".format(candidate, forward_prob))
candi_prob += forward_prob
else:
candi_prob += math.log(1.0 / V)
# 2.2 考虑后一个单词【比如:候选词word=freight,此时计算“freight language”出现的概率】
if j + 1 < len(line):
word_backward = candidate + " " + line[j + 1]
print("word_backward = {0}----line[j + 1] = {1}".format(word_backward, line[j + 1]))
if word_backward in bigram_count and candidate in unigram_count:
backward_prob = math.log((bigram_count[word_backward] + 1.0) / (unigram_count[candidate] + V)) # 加1平滑计算:在word出现的情况下,word_backward出现的概率。
print("candidate = {0}----backward_prob = {1}".format(candidate, backward_prob))
candi_prob += backward_prob
else:
candi_prob += math.log(1.0 / V)
print("该候选词的最终得分:candi_prob = {}".format(candi_prob))
candi_probs.append(candi_prob) # 将当前候选词的得分加入到 candi_probs 列表
print("\n\n所有候选词的最终得分:candi_probs = {}".format(candi_probs))
max_idx = candi_probs.index(max(candi_probs))
print("error_word = {0}----最佳候选词:candidates[max_idx] = {1}".format(error_word, candidates[max_idx]))
j += 1
打印结果:
[nltk_data] Downloading package reuters to
[nltk_data] C:\Users\surface\AppData\Roaming\nltk_data...
[nltk_data] Package reuters is already up-to-date!
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\surface\AppData\Roaming\nltk_data...
[nltk_data] Package punkt is already up-to-date!
len(categories) = 90----categories[:5] = ['acq', 'alum', 'barley', 'bop', 'carcass']
len(corpus) = 54716----corpus[:5] = [['ASIAN', 'EXPORTERS', 'FEAR', 'DAMAGE', 'FROM', 'U', '.', 'S', '.-', 'JAPAN', 'RIFT', 'Mounting', 'trade', 'friction', 'between', 'the', 'U', '.', 'S', '.', 'And', 'Japan', 'has', 'raised', 'fears', 'among', 'many', 'of', 'Asia', "'", 's', 'exporting', 'nations', 'that', 'the', 'row', 'could', 'inflict', 'far', '-', 'reaching', 'economic', 'damage', ',', 'businessmen', 'and', 'officials', 'said', '.'], ['They', 'told', 'Reuter', 'correspondents', 'in', 'Asian', 'capitals', 'a', 'U', '.', 'S', '.', 'Move', 'against', 'Japan', 'might', 'boost', 'protectionist', 'sentiment', 'in', 'the', 'U', '.', 'S', '.', 'And', 'lead', 'to', 'curbs', 'on', 'American', 'imports', 'of', 'their', 'products', '.'], ['But', 'some', 'exporters', 'said', 'that', 'while', 'the', 'conflict', 'would', 'hurt', 'them', 'in', 'the', 'long', '-', 'run', ',', 'in', 'the', 'short', '-', 'term', 'Tokyo', "'", 's', 'loss', 'might', 'be', 'their', 'gain', '.'], ['The', 'U', '.', 'S', '.', 'Has', 'said', 'it', 'will', 'impose', '300', 'mln', 'dlrs', 'of', 'tariffs', 'on', 'imports', 'of', 'Japanese', 'electronics', 'goods', 'on', 'April', '17', ',', 'in', 'retaliation', 'for', 'Japan', "'", 's', 'alleged', 'failure', 'to', 'stick', 'to', 'a', 'pact', 'not', 'to', 'sell', 'semiconductors', 'on', 'world', 'markets', 'at', 'below', 'cost', '.'], ['Unofficial', 'Japanese', 'estimates', 'put', 'the', 'impact', 'of', 'the', 'tariffs', 'at', '10', 'billion', 'dlrs', 'and', 'spokesmen', 'for', 'major', 'electronics', 'firms', 'said', 'they', 'would', 'virtually', 'halt', 'exports', 'of', 'products', 'hit', 'by', 'the', 'new', 'taxes', '.']]
list(vocab.items())[:10] = [('mistletoe', 488055), ('zal', 125039), ('atwood', 828552), ('outdistanced', 141900), ('jes', 457827), ('fathomless', 233620), ('conjugate', 2103565), ('sighing', 1382024), ('silenus', 180905), ('endurable', 279838)]
len(unigram_count) = 41559----举例:list(unigram_count.items())[:10] = [('<s>', 54716), ('ASIAN', 12), ('EXPORTERS', 46), ('FEAR', 2), ('DAMAGE', 13), ('FROM', 208), ('U', 6388), ('.', 45900), ('S', 6382), ('.-', 167)]
len(bigram_count) = 397935----举例:list(bigram_count.items())[:10]= [('<s> ASIAN', 4), ('ASIAN EXPORTERS', 1), ('EXPORTERS FEAR', 1), ('FEAR DAMAGE', 1), ('DAMAGE FROM', 2), ('FROM U', 4), ('U .', 6350), ('. S', 5809), ('S .-', 120), ('.- JAPAN', 8)]
len(channel_prob) = 7841----list(channel_prob.items())[:10]= [('raining', {'rainning': -0.6931471805599453, 'raning': -0.6931471805599453}), ('writings', {'writtings': 0.0}), ('disparagingly', {'disparingly': 0.0}), ('yellow', {'yello': 0.0}), ('four', {'forer': -1.6094379124341003, 'fours': -1.6094379124341003, 'fuore': -1.6094379124341003, 'fore*5': -1.6094379124341003, 'for*4': -1.6094379124341003}), ('woods', {'woodes': 0.0}), ('hanging', {'haing': 0.0}), ('aggression', {'agression': 0.0}), ('looking', {'loking': -2.3025850929940455, 'begining': -2.3025850929940455, 'luing': -2.3025850929940455, 'look*2': -2.3025850929940455, 'locking': -2.3025850929940455, 'lucking': -2.3025850929940455, 'louk': -2.3025850929940455, 'looing': -2.3025850929940455, 'lookin': -2.3025850929940455, 'liking': -2.3025850929940455}), ('eligible', {'eligble': -1.0986122886681098, 'elegable': -1.0986122886681098, 'eligable': -1.0986122886681098})]
======================================== 当前单词拼写错误(不在给定的vocab词典库中):foreigh ========================================
len(known_edit1_words) = 1----known_edit1_words = ['foreign']
len(known_edit2_words) = 5----known_edit2_words = ['forego', 'freight', 'foreach', 'foreign', 'foresight']
candidates_words = ['forego', 'freight', 'foreach', 'foreign', 'foresight']
生成所有的(valid)候选集合---->candidates = ['forego', 'freight', 'foreach', 'foreign', 'foresight']
------------------------------ candidate = forego ------------------------------
forward_word = a forego----line[j - 1] = a
word_backward = forego language ----line[j + 1] = language
该候选词的最终得分:candi_prob = -30.48007913862816
------------------------------ candidate = freight ------------------------------
forward_word = a freight----line[j - 1] = a
word_backward = freight language ----line[j + 1] = language
该候选词的最终得分:candi_prob = -30.48007913862816
------------------------------ candidate = foreach ------------------------------
forward_word = a foreach----line[j - 1] = a
word_backward = foreach language ----line[j + 1] = language
该候选词的最终得分:candi_prob = -30.48007913862816
------------------------------ candidate = foreign ------------------------------
candidate = foreign----channel_prob[candidate] = {'forien': -1.3862943611198906, 'forein': -1.3862943611198906, 'foriegn*2': -1.3862943611198906, 'foreigh': -1.3862943611198906}----channel_prob[candidate][word]=-1.3862943611198906
candidate = foreign----chann_prob = -1.3862943611198906
forward_word = a foreign----line[j - 1] = a
word_backward = foreign language ----line[j + 1] = language
该候选词的最终得分:candi_prob = -22.656033127771867
------------------------------ candidate = foresight ------------------------------
forward_word = a foresight----line[j - 1] = a
word_backward = foresight language ----line[j + 1] = language
该候选词的最终得分:candi_prob = -30.48007913862816
所有候选词的最终得分:candi_probs = [-30.48007913862816, -30.48007913862816, -30.48007913862816, -22.656033127771867, -30.48007913862816]
error_word = foreigh----最佳候选词:candidates[max_idx] = foreign
Process finished with exit code 0
六、神经网络语言模型
神经网络语言模型和传统的语言模型相似,依然是一个概率语言模型。但是对于输入和输出有些额外的操作:
- 使用一个可训练的向量代表一个词语,整个句子是其中词语的向量的拼接。
- 根据应用场景的不同,输出可以是一个词语的概率或者是其他
神经网络语言模型先给每个词赋予一个初始化词向量(该初始化词向量是即:具有初始化参数 θ θ θ 的模型的“隐层输出”),然后构建神经网络模型,建模当前词出现的概率与其前 n-1 个词之间的约束关系(特征值与目标值的关系),通过神经网络的损失函数的梯度下降去学习词的最优向量表示(具有最优参数 θ θ θ 的模型的“隐层输出”)。结构如下图所示:

图中:
index for w t − n + 1 w_{t-n+1} wt−n+1表示单词 w t − n + 1 w_{t-n+1} wt−n+1 在总词汇表中的索引值。- C ( w t ) C(w_t) C(wt)表示第 t 个词 w t w_t wt的对应的特征向量(词向量)。
具体而言,假设当前词出现的概率只依赖于前 n−1个词。即:
p
(
w
t
∣
w
1
…
w
t
−
1
)
=
p
(
w
t
∣
w
t
−
n
+
1
…
w
t
−
1
)
p(w_t|w_1\ldots w_{t-1}) = p(w_t|w_{t-n+1}\ldots w_{t-1})
p(wt∣w1…wt−1)=p(wt∣wt−n+1…wt−1)
假设V表示所有N个词的集合, w t ∈ V w_t \in V wt∈V,存在一个 ∣ V ∣ × m |V|\times m ∣V∣×m的参数矩阵C,矩阵的每一行代表每一个词的特征向量,m代表每个特征向量由m个维度。 C ( w t ) C(w_t) C(wt)表示第 t 个词 w t w_t wt的对应的特征向量。
如上图所示,将句子的前 n-1 个词特征对应的向量
C
(
w
t
−
n
+
1
)
…
C
(
w
t
−
1
)
C(w_{t-n+1})\ldots C(w_{t-1})
C(wt−n+1)…C(wt−1)作为神经网络的输入,输出当前的词是
w
t
w_t
wt的概率。计算过程如下:
y
=
W
⋅
x
+
U
⋅
t
a
n
h
(
d
+
H
⋅
x
)
+
b
y = W·x + U·tanh(d+H·x) + b
y=W⋅x+U⋅tanh(d+H⋅x)+b
其中:
- x = ( C ( w t − 1 ) , C ( w t − 2 ) , … , C ( w t − n + 1 ) ) x = (C(w_{t-1}),C(w_{t-2}),\ldots ,C(w_{t-n+1})) x=(C(wt−1),C(wt−2),…,C(wt−n+1)), x x x表示由各个词向量组成的句子。 C ( w t ) C(w_t) C(wt)表示第 t 个词 w t w_t wt的对应的特征向量(词向量)。 C C C 表示将“词汇索引”转为“词向量”的模型参数。
- d + H ⋅ x d+H·x d+H⋅x 表示 x x x 进行一次Linear层操作。.
- t a n h ( d + H ⋅ x ) tanh(d+H·x) tanh(d+H⋅x) 表示 x x x 经过一次Linear层操作后再经过 t a n h tanh tanh 激活函数。
- U ⋅ t a n h ( d + H ⋅ x ) + b U·tanh(d+H·x) + b U⋅tanh(d+H⋅x)+b 表示 t a n h ( d + H x ) tanh(d+Hx) tanh(d+Hx) 的输出再经过一次Linear层操作。.
- W ⋅ x W·x W⋅x 表示 x x x 进行一次Linear层操作。.
经过上式得到 y w = ( y w , 1 , y w , 2 , … , y w , N ) T y_w = (y_{w,1},y_{w,2},\ldots,y_{w,N})^T yw=(yw,1,yw,2,…,yw,N)T ,其中,将 y w y_w yw 进行softmax后, y w i y_{w_i} ywi 表示当上下文为 c o n t e x t ( w ) context(w) context(w)时,下一个词恰好是词典中第 i i i 个词的概率,即:
P ^ ( w i ∣ c o n t e x t ( w i ) ) = e y w i ∑ k = 1 N e y w k N 表示词汇表总词汇数量 \hat{P}(w_i|context(w_i)) = \cfrac{e^{y_{w_i}}}{\sum_{k=1}^N e^{y_{w_k}}} \qquad N\text{表示词汇表总词汇数量} P^(wi∣context(wi))=∑k=1NeywkeywiN表示词汇表总词汇数量
计算集中在隐藏层和输出层之间的矩阵向量运算,以及输出层上的softmax归一化运算。该模型的参数是:
θ
=
(
b
,
d
,
W
,
U
,
H
,
C
)
θ=(b,d,W,U,H,C)
θ=(b,d,W,U,H,C)
损失函数是:
L = − 1 T ∑ t log p ^ ( w t = i ∣ w t − n + 1 … w t − 1 ) + R ( θ ) L = -\frac{1}{T} \sum_t \log \hat p(w_t=i|w_{t-n+1}\ldots w_{t-1}) + R(\theta) L=−T1t∑logp^(wt=i∣wt−n+1…wt−1)+R(θ)
其中: R ( θ ) R(\theta) R(θ)是正则化项,用于控制过拟合。
有了损失函数,我们可以用梯度下降法,在给定学习率
η
η
η 的条件下,进行参数更新:
θ
←
θ
−
η
∂
L
∂
θ
\theta \leftarrow \theta - \eta \cfrac{\partial L}{\partial \theta}
θ←θ−η∂θ∂L
直至收敛,得到一组最优参数
θ
θ
θ。



1、神经网络语言模型的优点、缺点
1.1 优点
- 可以获取更长距离的依赖,同时没有让参数呈指数级增长
- 使用了词向量的技术,让模型具有更好的泛化能力
1.2 缺点
- 训练时间长
- 可解释性差
1.3 神经网络语言模型(NNLM)与 N-gram 模型相比
共同点:都是计算语言模型,将句子看作一个词序列,来计算句子的概率
不同点:
- 计算概率方式不同,N-gram基于马尔可夫假设只考虑前n个词,NNLM要考虑整个句子的上下文。
- 循环神经网络可以将任意长度的上下文信息存储在隐藏状态中,而不仅限于n-gram模型中的窗口限制
- 训练模型的方式不同,n-gram基于最大似然估计来计算参数,nnlm基于RNN的优化方法来训练模型,并且这个过程中往往会有word embedding作为输入,这样对于相似的词可以有比较好的计算结果,但n-gram是严格基于词本身的。
- NNLM中相似的词具有相似的向量。对于 n-gram 模型而言,如果语料中S1=“A dog is running in the room”出现了10000次,而S2=“A cat is running in the room”只出现了1次,p(S1)肯定会远大于p(S2)。而实际上,dog 和 cat 是相似的存在,神经网络语言模型所得到的词向量距离会比较近,表示两个词十分相似。
- NNLM中用向量表示的词自带平滑化功能(由 p ( w ∣ C o n t e x t ( w ) ) ∈ ( 0 , 1 ) p(w∣Context(w))∈(0,1) p(w∣Context(w))∈(0,1)不会为零),不再需要像 n-gram 那样进行额外处理了。
七、N-gram神经网络语言模型
N-gram神经网络语言模型,就是将N-gram的思想与神经网络结合起来,根据上下文信息预测当前词的一套网络模型。前面我们所说的基于统计的N-gram有一些缺点,属于机器学习的范畴。那么基于深度学习的神经网络会是什么样的呢?
请看下面这张网络示意图,简单说就是把上下文信息输入模型,预测词表中每一个词出现的概率,概率最大的作为我们的预测值。这就是一个非常简单的四层神经网络,我们来结识一些关键点。首先将context中的每一个词进行one-hot编码,然后通过词向量表(该词向量表也是通过训练得到)找到对应词的词向量,使用一个projection(投影层)将所有上下文向量拼接起来,然后经过隐层使用tanh非线性激活,最后输出为softmax多分类。

训练好的模型可以干的事情就是,给一个上下文,就会预测出来当前的词是什么。然后还会得到模型的副产品-词向量表。各参数描述:输入层V(context(W))的数量跟上下文中的词数量一致;词向量表的形状为(词表中词的数量*词向量长度);
1、N-gram特征添加
句子可以用单个字,词来表示,但是有的时候,我们可以用2个、3个或者多个词来表示。
N-gram: 用连续的N个token作为一个特征。N往往取2、3。这样考虑了句子中词汇的顺序。
N-gram一组一组的词语,其中的N表示能够被一起使用的词的数量。
给定一段文本序列, 其中n个词或字的相邻共现特征即n-gram特征, 常用的n-gram特征是bi-gram和tri-gram特征, 分别对应n为2和3。
如果n≥4,将极大地增加计算压力,即使是大集群也无法处理4元以上的n-gram特征处理,这是世界性难题。
举个栗子:
假设给定分词列表: ["是谁", "敲动", "我心"]
对应的数值映射列表为: [1, 34, 21]
我们可以认为数值映射列表中的每个数字是词汇特征.
除此之外, 我们还可以把"是谁"和"敲动"两个词共同出现且相邻也作为一种特征加入到序列列表中,
假设1000就代表"是谁"和"敲动"共同出现且相邻
此时数值映射列表就变成了包含2-gram特征的特征列表: [1, 34, 21, 1000]
这里的"是谁"和"敲动"共同出现且相邻就是bi-gram特征中的一个.
"敲动"和"我心"也是共现且相邻的两个词汇, 因此它们也是bi-gram特征.
假设1001代表"敲动"和"我心"共同出现且相邻
那么, 最后原始的数值映射列表 [1, 34, 21] 添加了bi-gram特征之后就变成了 [1, 34, 21, 1000, 1001]
提取n-gram特征:
# 一般n-gram中的n取2或者3, 这里取2为例
ngram_range = 2
def create_ngram_set(input_list):
"""
description: 从数值列表中提取所有的n-gram特征
:param input_list: 输入的数值列表, 可以看作是词汇映射后的列表,
里面每个数字的取值范围为[1, 25000]
:return: n-gram特征组成的集合
eg:
create_ngram_set([1, 4, 9, 4, 1, 4]) >>> {(4, 9), (4, 1), (1, 4), (9, 4)}
"""
return set(zip(*[input_list[i:] for i in range(ngram_range)]))
input_list = [1, 3, 2, 1, 5, 3]
# 调用create_ngram_set
res = create_ngram_set(input_list)
print("res = {0}".format(res))
输出结果:
# 该输入列表的所有bi-gram特征
res = {(3, 2), (1, 3), (2, 1), (1, 5), (5, 3)}
在传统的机器学习中,使用N-gram方法往往能够取得非常好的效果,但是在深度学习比如RNN中会自带N-gram的效果。
2、神经网络模型:特征处理
特征处理过程的四步曲:
- 第一步: 进行词汇映射
- 第二步: 将向量进行合适的截断对齐
- 第三步: 加入n-gram特征
- 第四步: 将向量进行最长补齐
2.1进行词汇映射、将向量进行合适的截断对齐
进行词汇映射作用
- 将分词列表中的每个词映射成数字.
举个栗子
分词(词汇)列表: ["有时", "我想", "放弃", "挣扎", "也放下", "我", "写字的手"]
把每个词映射成数字, 得到序列列表: [1, 2, 3, 4, 5, 6, 7]
分词列表: ["可是", "我已经", "放弃", "太多", "还坚持", "着说", "还坚持", "着走"]
得到序列列表: [8, 9, 3, 10, 11, 12, 11, 13]
将向量进行合适截断对齐作用
- 将映射后的句子向量进行截断/补齐,以降低模型输入的特征维度,来防止过拟合.
举个栗子:
序列列表: [[1, 2, 3, 4, 5, 6], [1, 3, 9], [2, 4, 6], [2, 3]]
以长度3进行截断对齐后得到
新的序列列表: [[1, 2, 3], [1, 3, 9], [2, 4, 6], [2, 3, 0]]
import joblib # 导入用于对象保存与加载的joblib
from keras.preprocessing.text import Tokenizer # 导入keras中的词汇映射器Tokenizer
from data_analysis import get_data_labels # 导入从样本csv到内存的get_data_labels函数
from collections import Counter
from keras.preprocessing import sequence
# ================================================================================== 获取正负样本分词列表和对应的标签:开始 ==================================================================================
import pandas as pd
import jieba
# 获得训练数据和对应的标签, 以正负样本的csv文件路径为参数
def get_data_labels(csv_path):
df = pd.read_csv(csv_path, header=None, sep="\t") # 使用pandas读取csv文件至内存
x_train = list(map(lambda x: list(filter(lambda x: len(x) > 1, jieba.lcut(x))), df[1].values)) # 对句子进行分词处理并过滤掉长度为1的词
y_train = df[0].values # 取第0列的值作为训练标签
return x_train, y_train
# ================================================================================== 获取正负样本分词列表和对应的标签:结束 ==================================================================================
# ====================================================== 第一步: 进行词汇映射:开始 ======================================================
# 进行词汇映射【将分词列表中的每个词映射成数字】,以训练数据的csv路径和映射器存储路径以及截断数为参数, 使用get_data_labels函数获取简单处理后的训练数据和标签
def word_map(csv_path, tokenizer_path, cut_num):
x_train, y_train = get_data_labels(csv_path)
x_train = x_train[:-cut_num] # 进行正负样本均衡切割, 使其数量比例为1:1
y_train = y_train[:-cut_num]
t = Tokenizer(num_words=None, char_level=False) # 实例化一个词汇映射器对象
t.fit_on_texts(x_train) # 使用映射器拟合现有文本数据
joblib.dump(t, tokenizer_path) # 使用joblib工具保存映射器
x_train = t.texts_to_sequences(x_train) # 使用映射器转化现有文本数据
return x_train, y_train
# ====================================================== 第一步: 进行词汇映射:结束 ======================================================
# ====================================================== 第二步: 将向量进行合适截断:开始 ======================================================
# max_len根据数据分析中句子长度分布,覆盖90%语料的最短长度.
def padding(x_train, max_len):
return sequence.pad_sequences(x_train, max_len)
# ====================================================== 第二步: 将向量进行合适截断:结束 ======================================================
if __name__ == "__main__":
# 词汇映射【将分词列表中的每个词映射成数字】
csv_path_list = ["./beauty/sample.csv", "./fashion/sample.csv", "./movie/sample.csv", "./star/sample.csv"] # 对应的样本csv路径
tokenizer_path_list = ["./beauty/Tokenizer", "./fashion/Tokenizer", "./movie/Tokenizer", "./star/Tokenizer"] # 词汇映射器保存的路径
path_tuple_list = zip(csv_path_list, tokenizer_path_list)
for csv_path, tokenizer_path in path_tuple_list:
print("-"*50, csv_path, "-"*50)
x_train, y_train = get_data_labels(csv_path)
print("x_train[:2] = {0}".format(x_train[:2]))
class_dict = dict(Counter(y_train))
print("class_dict = {0}".format(class_dict)) # {1: 3995, 0: 4418}
cut_num = class_dict[0] - class_dict[1]
x_train, y_train = word_map(csv_path, tokenizer_path, cut_num)
print("x_train[:2] = {0}".format(x_train[:2]))
class_dict = dict(Counter(y_train))
print("class_dict = {0}".format(class_dict))
# 将向量进行合适的截断对齐
x_train = padding(x_train, 60)
print("将向量进行合适的截断对齐---->x_train.shape = {0}----y_train.shape = {1}".format(x_train.shape, y_train.shape))
print("将向量进行合适的截断对齐---->x_train[:2] = {0}".format(x_train[:2]))
打印结果:
-------------------------------------------------- ./beauty/sample.csv --------------------------------------------------
x_train[:2] = [
['最近', '新品', '很大', '这不娇兰', '日本', '上市', '限定', '粉饼', '真的', '橘子', '君萌', '一萌', '确实', '有点', '可爱'],
['就是', '娇兰家', '日本', '上市', '粉饼', '两只', '胖鹅', '一只', '一只', '可爱', '有木有', '粉饼', '本身', '不是', '很大', '放在', '包包', '随身携带', '刚刚']
]
class_dict = {1: 2367, 0: 6045}
x_train[:2] = [
[387, 95, 733, 9388, 307, 198, 560, 3508, 402, 9, 9389, 9390, 1258, 451, 452],
[16, 9391, 307, 198, 3508, 3509, 6427, 2204, 2204, 452, 4970, 3508, 760, 103, 733, 2205, 909, 4971, 1339]
]
class_dict = {1: 2367, 0: 2367}
将向量进行合适的截断对齐---->x_train.shape = (4734, 60)----y_train.shape = (4734,)
将向量进行合适的截断对齐---->x_train[:2] = [
[ 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 387 95 733 9388 307
198 560 3508 402 9 9389 9390 1258 451 452]
[ 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 16 9391 307 198 3508 3509 6427 2204 2204
452 4970 3508 760 103 733 2205 909 4971 1339]
]
-------------------------------------------------- ./fashion/sample.csv --------------------------------------------------
x_train[:2] = [
['春天', '橘子', '发现', '街头', '妹子', '轻装', '不少', '感觉', '新一轮', '换装', '正在', '悄无声息', '开始', '什么', '这个', '课题', '有句', '这么', '时尚', '潮人', '季节', '总是', '来得', '很早', '今天', '咱们', '看看', '那些', '已经', '早春', '人们', '什么', '单品', 'look1', '低调', '灰色', '针织', '高领', '外套', '一件', '红色', '连体', '米色', '黑色', '平底鞋', '足够', '闪亮', '街头'],
['推荐', '单品', '红色', '连体', 'look2', '灰色', '针织衫', '搭配', '一套', '牛仔', '单品', '拼接', '短靴', '夸张', '耳环', '更是', '增添', '几分', '帅气']
]
class_dict = {1: 1399, 0: 7013}
x_train[:2] = [[767, 7, 242, 384, 1563, 6589, 415, 75, 3444, 4454, 977, 6590, 114, 92, 55, 6591, 6592, 202, 10, 2021, 638, 978, 6593, 6594, 158, 2778, 342, 2022, 95, 1773, 362, 92, 51, 4455, 363, 979, 639, 364, 76, 253, 197, 2349, 3445, 29, 1774, 2023, 1254, 384], [293, 51, 197, 2349, 4456, 979, 1775, 6, 365, 273, 51, 399, 4457, 673, 485, 59, 640, 980, 159]]
class_dict = {1: 1399, 0: 1399}
将向量进行合适的截断对齐---->x_train.shape = (2798, 60)----y_train.shape = (2798,)
将向量进行合适的截断对齐---->x_train[:2] = [[ 0 0 0 0 0 0 0 0 0 0 0 0 767 7
242 384 1563 6589 415 75 3444 4454 977 6590 114 92 55 6591
6592 202 10 2021 638 978 6593 6594 158 2778 342 2022 95 1773
362 92 51 4455 363 979 639 364 76 253 197 2349 3445 29
1774 2023 1254 384]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 293
51 197 2349 4456 979 1775 6 365 273 51 399 4457 673 485
59 640 980 159]]
-------------------------------------------------- ./movie/sample.csv --------------------------------------------------
x_train[:2] = [['今日', '捉妖', '北京', '举办', '全球', '首映礼', '发布会', '导演', '许诚毅', '各位', '主演', '亮相', '现场', '各位', '演员', '大家', '讲述', '自己', '拍摄', '过程', '发生', '趣事', '大家', '分享', '自己', '过年', '计划', '现场', '布置', '十分', '喜庆', '放眼望去', '一片', '红彤彤', '颜色', '感受', '浓浓的', '年味'], ['胡巴', '遭遇', '危险', '全民', '追击', '发布', '预告片', '当中', '胡巴', '遭到', '追杀', '流落', '人间', '梁朝伟', '收留', '与此同时', '李宇春', '饰演', '钱庄', '老板', '通缉', '胡巴', '胡巴', '处境', '可谓', '四面楚歌', '不过', '胡巴', '幸运', '孩子', '逃避', '追捕', '过程', '胡巴', '跟着', '朋友', '逃跑', '专家', '笨笨', '几次', '死里逃生', '没有', '落到', '起来', '关进', '笼子', '下场', '虽然', '如此', '几次', '惊险', '场面', '还是', '人们', '不禁', '电影', '胡巴', '捏一把汗']]
class_dict = {1: 3995, 0: 4417}
x_train[:2] = [[968, 4104, 28, 215, 101, 292, 31, 4, 9317, 1053, 124, 139, 7, 1053, 22, 19, 236, 2, 43, 127, 800, 2819, 19, 81, 2, 1552, 361, 7, 3052, 183, 9318, 13498, 1477, 13499, 509, 66, 7324, 7325], [2283, 1717, 1634, 2436, 9319, 264, 1718, 935, 2283, 9320, 13500, 13501, 4583, 3694, 13502, 1803, 3360, 198, 9321, 3695, 13503, 2283, 2283, 9322, 936, 13504, 338, 2283, 1478, 274, 13505, 9323, 127, 2283, 1998, 416, 13506, 567, 13507, 3361, 13508, 32, 13509, 199, 13510, 13511, 9324, 195, 547, 3361, 2617, 580, 52, 478, 2284, 1, 2283, 9325]]
class_dict = {1: 3995, 0: 3995}
将向量进行合适的截断对齐---->x_train.shape = (7990, 60)----y_train.shape = (7990,)
将向量进行合适的截断对齐---->x_train[:2] = [[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 968 4104
28 215 101 292 31 4 9317 1053 124 139 7 1053
22 19 236 2 43 127 800 2819 19 81 2 1552
361 7 3052 183 9318 13498 1477 13499 509 66 7324 7325]
[ 0 0 2283 1717 1634 2436 9319 264 1718 935 2283 9320
13500 13501 4583 3694 13502 1803 3360 198 9321 3695 13503 2283
2283 9322 936 13504 338 2283 1478 274 13505 9323 127 2283
1998 416 13506 567 13507 3361 13508 32 13509 199 13510 13511
9324 195 547 3361 2617 580 52 478 2284 1 2283 9325]]
-------------------------------------------------- ./star/sample.csv --------------------------------------------------
x_train[:2] = [['最近', '汪小菲', '大S', '一家', '四口', '出去玩', '汪小菲', '还给', '大S', '照片', '照片', '大S', '宛如', '少女', '般的', '美貌', '完全', '看不出', '年纪', '橘子', '君一', '起来', '看看', '不得不', '大S', '真的', '瘦下来', '弯弯的', '眼笑', '起来', '可真甜', '浑身', '透露', '妈妈', '味道', '这样', '迷人', '再来', '看看', '别人', '大S', '汪小菲', '有木有', '看到', '汪小菲', '痴汉', '般的', '眼神', '哈哈哈哈', '简直', '就是', '老婆', '向日葵', '无疑', '..', '网友', '纷纷', '赞扬', '大S', '脸好', '瘦下来', '太美', '杉菜', '本人', '橘子', '记忆', '..', '真正', '开心', '幸福', '笑容', '果然', '大家', '感受', '还有', '网友', '汪小菲', '眼里', '真的', '幸福', '这话', '毛病', '..', '就是', '嫁给', '爱情', '样子', '开心', '对方', '开心', '看到', '大S', '这么', '甜美', '笑容', '感受', '他们', '一家人', '多么', '幸福', '欢乐', '橘子', '觉得', '能力', '满满', '希望', '大家', '找到', '属于', '自己', '幸福', '最后', '一句', '早上', '就让', '我们', '甜蜜', '消息', '开始', '....'], ['昨天', '娱姬', '小妖', '爆料', '杜志国', '杨姓', '女子', '疑似', '婚外恋', '消息']]
class_dict = {1: 651, 0: 7761}
x_train[:2] = [[1173, 1174, 832, 1175, 3908, 3909, 1174, 1912, 832, 995, 995, 832, 2545, 147, 516, 3910, 573, 2546, 1176, 21, 2547, 470, 1177, 635, 832, 224, 2548, 3911, 3912, 470, 3913, 3914, 718, 574, 1178, 186, 719, 3915, 1177, 2549, 832, 1174, 2550, 332, 1174, 3916, 516, 1913, 2551, 1476, 50, 3917, 3918, 1179, 18, 187, 1914, 3919, 832, 3920, 2548, 3921, 3922, 1915, 21, 1477, 18, 225, 1916, 996, 1180, 2552, 13, 70, 204, 187, 1174, 3923, 224, 996, 3924, 3925, 18, 50, 3926, 636, 2553, 1916, 1917, 1916, 332, 832, 575, 1478, 1180, 70, 47, 3927, 2554, 996, 3928, 21, 428, 576, 833, 104, 13, 834, 577, 1, 996, 56, 105, 1918, 1479, 6, 517, 1919, 170, 578], [1480, 2555, 2556, 835, 720, 3929, 1181, 3930, 3931, 1919]]
class_dict = {1: 651, 0: 651}
将向量进行合适的截断对齐---->x_train.shape = (1302, 60)----y_train.shape = (1302,)
将向量进行合适的截断对齐---->x_train[:2] = [[2548 3921 3922 1915 21 1477 18 225 1916 996 1180 2552 13 70
204 187 1174 3923 224 996 3924 3925 18 50 3926 636 2553 1916
1917 1916 332 832 575 1478 1180 70 47 3927 2554 996 3928 21
428 576 833 104 13 834 577 1 996 56 105 1918 1479 6
517 1919 170 578]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 1480 2555 2556 835 720 3929
1181 3930 3931 1919]]
2.2 加入n-gram特征、将向量进行最长补齐
加入n-gram特征的作用
- 将n-gram表示作为特征,能够补充特征中没有上下文关联的缺点,将有效帮助模型捕捉上下文的语义关联.
将向量进行最长补齐的作用
- 为了不损失n-gram特征,使向量能够以矩阵形式作为模型输入.
最终得到的 x_train
- x_train.shape = (4734, 119)
- x_train = [[ 2548 3921 3922 … 46329 39545 49056]
[ 0 0 0 … 43063 29750 28773]
[ 0 0 0 … 41483 45159 47931]
…
[ 0 0 0 … 32232 43068 31449]
[ 0 0 0 … 39657 46993 51850]
[ 0 0 0 … 30709 44030 43943]] - 每行代表一句文本句子,长度为119
- 一共有4734句句子文本。
经过此步骤后的数据即是可以喂给模型的输入数据
import joblib # 导入用于对象保存与加载的joblib
from keras.preprocessing.text import Tokenizer # 导入keras中的词汇映射器Tokenizer
from data_analysis import get_data_labels # 导入从样本csv到内存的get_data_labels函数
from collections import Counter
from keras.preprocessing import sequence
import tensorflow as tf
# ================================================================================== 获取正负样本分词列表和对应的标签:开始 ==================================================================================
import pandas as pd
import jieba
# 获得训练数据和对应的标签, 以正负样本的csv文件路径为参数
def get_data_labels(csv_path):
df = pd.read_csv(csv_path, header=None, sep="\t") # 使用pandas读取csv文件至内存
x_train = list(map(lambda x: list(filter(lambda x: len(x) > 1, jieba.lcut(x))), df[1].values)) # 对句子进行分词处理并过滤掉长度为1的词
y_train = df[0].values # 取第0列的值作为训练标签
return x_train, y_train
# ================================================================================== 获取正负样本分词列表和对应的标签:结束 ==================================================================================
# 特征处理过程的四步曲:
# 第一步: 进行词汇映射
# 第二步: 将向量进行合适截断
# 第三步: 加入n-gram特征
# 第四步: 将向量进行最长补齐
# ================================================================================== 特征处理 ==================================================================================
# =========================== 第一步: 进行词汇映射:开始 ===========================
# 进行词汇映射【将分词列表中的每个词映射成数字】,以训练数据的csv路径和映射器存储路径以及截断数为参数, 使用get_data_labels函数获取简单处理后的训练数据和标签
def word_map(csv_path, tokenizer_path, cut_num):
x_train, y_train = get_data_labels(csv_path)
x_train = x_train[:-cut_num] # 进行正负样本均衡切割, 使其数量比例为1:1
y_train = y_train[:-cut_num]
t = Tokenizer(num_words=None, char_level=False) # 实例化一个词汇映射器对象
t.fit_on_texts(x_train) # 使用映射器拟合现有文本数据
joblib.dump(t, tokenizer_path) # 使用joblib工具保存映射器
x_train = t.texts_to_sequences(x_train) # 使用映射器转化现有文本数据
return x_train, y_train
# =========================== 第一步: 进行词汇映射:结束 ===========================
# =========================== 第二步: 将向量进行合适截断:开始 ===========================
# max_len根据数据分析中句子长度分布,覆盖90%语料的最短长度.
def padding(x_train, max_len):
return sequence.pad_sequences(x_train, max_len)
# =========================== 第二步: 将向量进行合适截断:结束 ===========================
# =========================== 第三步: 加入n-gram特征:开始 ===========================
import numpy as np
max_features = 27000 # 根据样本集最大词汇数选择最大特征数,应大于样本集最大词汇数【词汇表大小】
ngram_value = 2 # n-gram特征的范围,一般选择为2
# 从列表中提取n-gram特征 create_ngram_set([1, 4, 9, 4, 1, 4], ngram_value=2) >>> {(4, 9), (4, 1), (1, 4), (9, 4)}
def create_ngram_set(input_list, ngram_value):
return set(zip(input_list, input_list[ngram_value-1:]))
# 从训练数据x_train中获得token_indice和新的max_features >>> token_indice = {(1, 3): 1337, (9, 2): 42, (4, 5): 2017,......}
def get_token_indice_and_new_max_features(x_train, ti_path, ngram_value):
ngram_set = set() # 创建一个盛装n-gram特征的集合.
for input_list in x_train: # 遍历每一个数值映射后的列表
set_of_ngram = create_ngram_set(input_list, ngram_value) # 获得每句文本对应的n-gram表示【(0, 0)组合只会出现一次】
ngram_set.update(set_of_ngram) # 更新n-gram集合【update() 方法用于修改当前集合,可以添加新的元素或集合到当前集合中,如果添加的元素在集合中已存在,则该元素只会出现一次,重复的会忽略。】
ngram_set.discard(tuple([0] * ngram_value)) # 去除掉(0, 0)这个2-gram特征
start_index = max_features + 1 # 将n-gram特征映射成整数.【为了避免和之前的词汇特征冲突,n-gram产生的特征将从max_features+1开始】
token_indice = {v: k + start_index for k, v in enumerate(ngram_set)} # 得到对n-gram表示与对应特征值的字典【token_indice = {(1, 3): 1337, (9, 2): 42, (4, 5): 2017,......}】
with open(ti_path, "w", encoding="utf-8") as f: # 将token_indice写入文件以便预测时使用
f.write(str(token_indice))
indice_token = {token_indice[k]: k for k in token_indice} # token_indice的反转字典,为了求解新的最大特征数【indice_token = {1337: (1, 3), 42: (9, 2), 2017: (4, 5),......}】
new_max_features = np.max(list(indice_token.keys())) + 1 # 获得加入n-gram之后训练数据 x_train 的最大特征数【词汇总数量】
print("添加ngram后更新的词汇表大小---->new_max_features = {0}【更新前的手动定义的词汇表大小: max_features = 27000】".format(new_max_features))
return token_indice, new_max_features # new_max_features:新的词汇表大小
def add_ngram(x_train, token_indice, ngram_value=2):
"""
将n-gram特征加入到训练数据中
如: adding bi-gram
>>> x_train = [[1, 3, 4, 5], [1, 3, 7, 9, 2]]
>>> token_indice = {(1, 3): 1337, (9, 2): 42, (4, 5): 2017}
>>> add_ngram(x_train, token_indice, ngram_value=2) >>> [[1, 3, 4, 5, 1337, 2017], [1, 3, 7, 9, 2, 1337, 42]]
"""
new_sequences = []
for input_list in x_train: # 遍历序列列表中的每一个元素作为input_list, 即代表一个句子的列表
new_list = input_list[:].tolist() # copy一个new_list
for i in range(len(new_list) - ngram_value + 1): # 遍历各个可能的n-gram长度
ngram = tuple(new_list[i:i + ngram_value]) # 获得input_list中的n-gram表示
if ngram in token_indice: # 如果在token_indice中,则追加相应的数值特征
new_list.append(token_indice[ngram])
new_sequences.append(new_list)
return np.array(new_sequences)
# =========================== 第三步: 加入n-gram特征:结束 ===========================
# =========================== 第四步: 将向量进行最长补齐:开始 ===========================
# 用于向量按照最长长度进行补齐, 获得所有句子长度的最大值
def align(x_train):
maxlen = max(list(map(lambda x: len(x), x_train)))
x_train = padding(x_train, maxlen) # 调用padding函数
return x_train, maxlen
# =========================== 第四步: 将向量进行最长补齐:结束 ===========================
if __name__ == "__main__":
# 词汇映射【将分词列表中的每个词映射成数字】
csv_path_list = ["./beauty/sample.csv", "./fashion/sample.csv", "./movie/sample.csv", "./star/sample.csv"] # 对应的样本csv路径
tokenizer_path_list = ["./beauty/Tokenizer", "./fashion/Tokenizer", "./movie/Tokenizer", "./star/Tokenizer"] # 词汇映射器保存的路径
ti_path_list = ["./beauty/token_indice", "./fashion/token_indice", "./movie/token_indice", "./star/token_indice"] # token_indice的保存路径
path_tuple_list = zip(csv_path_list, tokenizer_path_list, ti_path_list)
for csv_path, tokenizer_path, ti_path in path_tuple_list:
print("-"*50, csv_path, "-"*50)
x_train, y_train = get_data_labels(csv_path)
print("x_train[:2] = {0}".format(x_train[:2]))
class_dict = dict(Counter(y_train))
print("class_dict = {0}".format(class_dict)) # {1: 3995, 0: 4418}
cut_num = class_dict[0] - class_dict[1]
x_train, y_train = word_map(csv_path, tokenizer_path, cut_num)
print("x_train[:2] = {0}".format(x_train[:2]))
class_dict = dict(Counter(y_train))
print("class_dict = {0}".format(class_dict))
# 将向量进行合适的截断对齐
x_train = padding(x_train, 60)
print("将向量进行合适的截断对齐---->x_train.shape = {0}----y_train.shape = {1}".format(x_train.shape, y_train.shape))
print("将向量进行合适的截断对齐---->x_train[:2] = {0}".format(x_train[:2]))
# 加入n-gram特征
token_indice, new_max_features = get_ti_and_nmf(x_train, ti_path, ngram_range) # token_indice = {(1286, 4723): 27001, (3052, 2324): 27002, (883, 1574): 27003, (953, 255): 27004, (382, 1955): 27005,...}
print("new_max_features = {0}".format(new_max_features))
x_train = add_ngram(x_train, token_indice, ngram_range)
print("x_train.shape = {0}".format(x_train.shape))
print("x_train[:2] = {0}".format(x_train[:2]))
# 将向量进行最长补齐
x_train, maxlen = align(x_train)
print("maxlen = {0}".format(maxlen))
print("将向量进行最长补齐---->x_train = {0}".format(x_train))
print("将向量进行最长补齐---->x_train.shape = {0}".format(x_train.shape))
打印结果:
-------------------------------------------------- ./beauty/sample.csv --------------------------------------------------
x_train[:2] = [
['最近', '新品', '很大', '这不娇兰', '日本', '上市', '限定', '粉饼', '真的', '橘子', '君萌', '一萌', '确实', '有点', '可爱'],
['就是', '娇兰家', '日本', '上市', '粉饼', '两只', '胖鹅', '一只', '一只', '可爱', '有木有', '粉饼', '本身', '不是', '很大', '放在', '包包', '随身携带', '刚刚']
]
class_dict = {1: 2367, 0: 6045}
x_train[:2] = [
[387, 95, 733, 9388, 307, 198, 560, 3508, 402, 9, 9389, 9390, 1258, 451, 452],
[16, 9391, 307, 198, 3508, 3509, 6427, 2204, 2204, 452, 4970, 3508, 760, 103, 733, 2205, 909, 4971, 1339]
]
class_dict = {1: 2367, 0: 2367}
将向量进行合适的截断对齐---->x_train.shape = (4734, 60)----y_train.shape = (4734,)
将向量进行合适的截断对齐---->x_train[:2] = [
[ 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 387 95 733 9388 307
198 560 3508 402 9 9389 9390 1258 451 452]
[ 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 16 9391 307 198 3508 3509 6427 2204 2204
452 4970 3508 760 103 733 2205 909 4971 1339]
]
添加ngram后更新的词汇表大小---->new_max_features = 107994【更新前的手动定义的词汇表大小: max_features = 27000】
x_train.shape = (4734,)
x_train[:2] = [
list([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 387, 95, 733, 9388, 307, 198, 560, 3508, 402, 9, 9389, 9390, 1258, 451, 452, 37726, 68897, 105694, 102389, 43213, 28119, 28467, 99479, 35721, 61896, 27957, 81559, 81452, 52763, 41131])
list([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 16, 9391, 307, 198, 3508, 3509, 6427, 2204, 2204, 452, 4970, 3508, 760, 103, 733, 2205, 909, 4971, 1339, 58988, 57042, 52932, 28119, 49152, 65577, 38699, 43147, 41719, 68098, 104752, 79460, 107398, 66153, 38660, 70480, 50898, 60479, 58089])
]
maxlen = 119
将向量进行最长补齐---->x_train = [
[ 0 0 0 ... 81452 52763 41131]
[ 0 0 0 ... 50898 60479 58089]
[ 0 0 0 ... 31780 36454 58860]
...
[ 0 0 0 ... 35306 89038 57862]
[ 0 0 0 ... 67755 60015 29796]
[ 0 0 0 ... 100931 41760 82362]]
将向量进行最长补齐---->x_train.shape = (4734, 119)
-------------------------------------------------- ./fashion/sample.csv --------------------------------------------------
x_train[:2] = [['春天', '橘子', '发现', '街头', '妹子', '轻装', '不少', '感觉', '新一轮', '换装', '正在', '悄无声息', '开始', '什么', '这个', '课题', '有句', '这么', '时尚', '潮人', '季节', '总是', '来得', '很早', '今天', '咱们', '看看', '那些', '已经', '早春', '人们', '什么', '单品', 'look1', '低调', '灰色', '针织', '高领', '外套', '一件', '红色', '连体', '米色', '黑色', '平底鞋', '足够', '闪亮', '街头'], ['推荐', '单品', '红色', '连体', 'look2', '灰色', '针织衫', '搭配', '一套', '牛仔', '单品', '拼接', '短靴', '夸张', '耳环', '更是', '增添', '几分', '帅气']]
class_dict = {1: 1399, 0: 7013}
x_train[:2] = [[767, 7, 242, 384, 1563, 6589, 415, 75, 3444, 4454, 977, 6590, 114, 92, 55, 6591, 6592, 202, 10, 2021, 638, 978, 6593, 6594, 158, 2778, 342, 2022, 95, 1773, 362, 92, 51, 4455, 363, 979, 639, 364, 76, 253, 197, 2349, 3445, 29, 1774, 2023, 1254, 384], [293, 51, 197, 2349, 4456, 979, 1775, 6, 365, 273, 51, 399, 4457, 673, 485, 59, 640, 980, 159]]
class_dict = {1: 1399, 0: 1399}
将向量进行合适的截断对齐---->x_train.shape = (2798, 60)----y_train.shape = (2798,)
将向量进行合适的截断对齐---->x_train[:2] = [[ 0 0 0 0 0 0 0 0 0 0 0 0 767 7
242 384 1563 6589 415 75 3444 4454 977 6590 114 92 55 6591
6592 202 10 2021 638 978 6593 6594 158 2778 342 2022 95 1773
362 92 51 4455 363 979 639 364 76 253 197 2349 3445 29
1774 2023 1254 384]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 293
51 197 2349 4456 979 1775 6 365 273 51 399 4457 673 485
59 640 980 159]]
添加ngram后更新的词汇表大小---->new_max_features = 76635【更新前的手动定义的词汇表大小: max_features = 27000】
x_train.shape = (2798,)
x_train[:2] = [list([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 767, 7, 242, 384, 1563, 6589, 415, 75, 3444, 4454, 977, 6590, 114, 92, 55, 6591, 6592, 202, 10, 2021, 638, 978, 6593, 6594, 158, 2778, 342, 2022, 95, 1773, 362, 92, 51, 4455, 363, 979, 639, 364, 76, 253, 197, 2349, 3445, 29, 1774, 2023, 1254, 384, 48435, 34858, 32162, 64692, 36901, 76472, 43075, 34640, 67757, 47796, 51712, 32340, 29615, 69185, 52634, 55825, 75222, 71172, 53488, 36064, 74001, 33848, 69973, 27640, 40186, 68384, 31778, 76602, 46800, 28273, 71245, 40756, 54411, 61092, 28467, 45081, 58067, 56955, 49864, 32430, 67417, 62631, 36641, 49309, 62621, 31090, 72931, 66992])
list([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 293, 51, 197, 2349, 4456, 979, 1775, 6, 365, 273, 51, 399, 4457, 673, 485, 59, 640, 980, 159, 44086, 30616, 61989, 62631, 43522, 55557, 54583, 62080, 69652, 75933, 56840, 47506, 64609, 76073, 32900, 28531, 38489, 61520, 76221])]
maxlen = 119
将向量进行最长补齐---->x_train = [[ 0 0 0 ... 31090 72931 66992]
[ 0 0 0 ... 38489 61520 76221]
[ 0 0 0 ... 38258 30515 42697]
...
[ 0 0 0 ... 45327 73207 30709]
[ 0 0 0 ... 69518 28198 36364]
[ 0 0 0 ... 57538 70539 43303]]
将向量进行最长补齐---->x_train.shape = (2798, 119)
-------------------------------------------------- ./movie/sample.csv --------------------------------------------------
x_train[:2] = [['今日', '捉妖', '北京', '举办', '全球', '首映礼', '发布会', '导演', '许诚毅', '各位', '主演', '亮相', '现场', '各位', '演员', '大家', '讲述', '自己', '拍摄', '过程', '发生', '趣事', '大家', '分享', '自己', '过年', '计划', '现场', '布置', '十分', '喜庆', '放眼望去', '一片', '红彤彤', '颜色', '感受', '浓浓的', '年味'], ['胡巴', '遭遇', '危险', '全民', '追击', '发布', '预告片', '当中', '胡巴', '遭到', '追杀', '流落', '人间', '梁朝伟', '收留', '与此同时', '李宇春', '饰演', '钱庄', '老板', '通缉', '胡巴', '胡巴', '处境', '可谓', '四面楚歌', '不过', '胡巴', '幸运', '孩子', '逃避', '追捕', '过程', '胡巴', '跟着', '朋友', '逃跑', '专家', '笨笨', '几次', '死里逃生', '没有', '落到', '起来', '关进', '笼子', '下场', '虽然', '如此', '几次', '惊险', '场面', '还是', '人们', '不禁', '电影', '胡巴', '捏一把汗']]
class_dict = {1: 3995, 0: 4417}
x_train[:2] = [[968, 4104, 28, 215, 101, 292, 31, 4, 9317, 1053, 124, 139, 7, 1053, 22, 19, 236, 2, 43, 127, 800, 2819, 19, 81, 2, 1552, 361, 7, 3052, 183, 9318, 13498, 1477, 13499, 509, 66, 7324, 7325], [2283, 1717, 1634, 2436, 9319, 264, 1718, 935, 2283, 9320, 13500, 13501, 4583, 3694, 13502, 1803, 3360, 198, 9321, 3695, 13503, 2283, 2283, 9322, 936, 13504, 338, 2283, 1478, 274, 13505, 9323, 127, 2283, 1998, 416, 13506, 567, 13507, 3361, 13508, 32, 13509, 199, 13510, 13511, 9324, 195, 547, 3361, 2617, 580, 52, 478, 2284, 1, 2283, 9325]]
class_dict = {1: 3995, 0: 3995}
将向量进行合适的截断对齐---->x_train.shape = (7990, 60)----y_train.shape = (7990,)
将向量进行合适的截断对齐---->x_train[:2] = [[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 968 4104
28 215 101 292 31 4 9317 1053 124 139 7 1053
22 19 236 2 43 127 800 2819 19 81 2 1552
361 7 3052 183 9318 13498 1477 13499 509 66 7324 7325]
[ 0 0 2283 1717 1634 2436 9319 264 1718 935 2283 9320
13500 13501 4583 3694 13502 1803 3360 198 9321 3695 13503 2283
2283 9322 936 13504 338 2283 1478 274 13505 9323 127 2283
1998 416 13506 567 13507 3361 13508 32 13509 199 13510 13511
9324 195 547 3361 2617 580 52 478 2284 1 2283 9325]]
添加ngram后更新的词汇表大小---->new_max_features = 159617【更新前的手动定义的词汇表大小: max_features = 27000】
x_train.shape = (7990,)
x_train[:2] = [list([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 968, 4104, 28, 215, 101, 292, 31, 4, 9317, 1053, 124, 139, 7, 1053, 22, 19, 236, 2, 43, 127, 800, 2819, 19, 81, 2, 1552, 361, 7, 3052, 183, 9318, 13498, 1477, 13499, 509, 66, 7324, 7325, 123363, 108201, 37050, 54574, 101084, 41419, 111878, 96131, 53862, 155653, 152281, 148628, 43515, 27201, 47122, 133782, 131364, 142276, 40696, 133687, 149479, 98519, 83048, 87137, 150459, 50569, 31730, 157961, 118428, 39340, 27116, 37343, 64054, 108904, 135929, 112382, 110644, 77466])
list([0, 0, 2283, 1717, 1634, 2436, 9319, 264, 1718, 935, 2283, 9320, 13500, 13501, 4583, 3694, 13502, 1803, 3360, 198, 9321, 3695, 13503, 2283, 2283, 9322, 936, 13504, 338, 2283, 1478, 274, 13505, 9323, 127, 2283, 1998, 416, 13506, 567, 13507, 3361, 13508, 32, 13509, 199, 13510, 13511, 9324, 195, 547, 3361, 2617, 580, 52, 478, 2284, 1, 2283, 9325, 32977, 36469, 35085, 52825, 36856, 89842, 87678, 88206, 98373, 60632, 71344, 108336, 143941, 110760, 99727, 109706, 70985, 73704, 61153, 148291, 76307, 116089, 120710, 95010, 82732, 122927, 67559, 101064, 139642, 33076, 69076, 125372, 148185, 66124, 93857, 125395, 81539, 106415, 48853, 54933, 44258, 103012, 71207, 112589, 55545, 156658, 114761, 107155, 52617, 52140, 129805, 83391, 64404, 43999, 117250, 148919, 58245, 112218])]
maxlen = 119
将向量进行最长补齐---->x_train = [[ 0 0 0 ... 112382 110644 77466]
[ 0 0 0 ... 148919 58245 112218]
[ 0 0 0 ... 134317 63886 139483]
...
[ 0 0 0 ... 123851 114878 44572]
[ 0 0 0 ... 119286 35700 115453]
[ 0 0 0 ... 120497 32958 127096]]
将向量进行最长补齐---->x_train.shape = (7990, 119)
-------------------------------------------------- ./star/sample.csv --------------------------------------------------
x_train[:2] = [['最近', '汪小菲', '大S', '一家', '四口', '出去玩', '汪小菲', '还给', '大S', '照片', '照片', '大S', '宛如', '少女', '般的', '美貌', '完全', '看不出', '年纪', '橘子', '君一', '起来', '看看', '不得不', '大S', '真的', '瘦下来', '弯弯的', '眼笑', '起来', '可真甜', '浑身', '透露', '妈妈', '味道', '这样', '迷人', '再来', '看看', '别人', '大S', '汪小菲', '有木有', '看到', '汪小菲', '痴汉', '般的', '眼神', '哈哈哈哈', '简直', '就是', '老婆', '向日葵', '无疑', '..', '网友', '纷纷', '赞扬', '大S', '脸好', '瘦下来', '太美', '杉菜', '本人', '橘子', '记忆', '..', '真正', '开心', '幸福', '笑容', '果然', '大家', '感受', '还有', '网友', '汪小菲', '眼里', '真的', '幸福', '这话', '毛病', '..', '就是', '嫁给', '爱情', '样子', '开心', '对方', '开心', '看到', '大S', '这么', '甜美', '笑容', '感受', '他们', '一家人', '多么', '幸福', '欢乐', '橘子', '觉得', '能力', '满满', '希望', '大家', '找到', '属于', '自己', '幸福', '最后', '一句', '早上', '就让', '我们', '甜蜜', '消息', '开始', '....'], ['昨天', '娱姬', '小妖', '爆料', '杜志国', '杨姓', '女子', '疑似', '婚外恋', '消息']]
class_dict = {1: 651, 0: 7761}
x_train[:2] = [[1173, 1174, 832, 1175, 3908, 3909, 1174, 1912, 832, 995, 995, 832, 2545, 147, 516, 3910, 573, 2546, 1176, 21, 2547, 470, 1177, 635, 832, 224, 2548, 3911, 3912, 470, 3913, 3914, 718, 574, 1178, 186, 719, 3915, 1177, 2549, 832, 1174, 2550, 332, 1174, 3916, 516, 1913, 2551, 1476, 50, 3917, 3918, 1179, 18, 187, 1914, 3919, 832, 3920, 2548, 3921, 3922, 1915, 21, 1477, 18, 225, 1916, 996, 1180, 2552, 13, 70, 204, 187, 1174, 3923, 224, 996, 3924, 3925, 18, 50, 3926, 636, 2553, 1916, 1917, 1916, 332, 832, 575, 1478, 1180, 70, 47, 3927, 2554, 996, 3928, 21, 428, 576, 833, 104, 13, 834, 577, 1, 996, 56, 105, 1918, 1479, 6, 517, 1919, 170, 578], [1480, 2555, 2556, 835, 720, 3929, 1181, 3930, 3931, 1919]]
class_dict = {1: 651, 0: 651}
将向量进行合适的截断对齐---->x_train.shape = (1302, 60)----y_train.shape = (1302,)
将向量进行合适的截断对齐---->x_train[:2] = [[2548 3921 3922 1915 21 1477 18 225 1916 996 1180 2552 13 70
204 187 1174 3923 224 996 3924 3925 18 50 3926 636 2553 1916
1917 1916 332 832 575 1478 1180 70 47 3927 2554 996 3928 21
428 576 833 104 13 834 577 1 996 56 105 1918 1479 6
517 1919 170 578]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 1480 2555 2556 835 720 3929
1181 3930 3931 1919]]
添加ngram后更新的词汇表大小---->new_max_features = 52094【更新前的手动定义的词汇表大小: max_features = 27000】
x_train.shape = (1302,)
x_train[:2] = [list([2548, 3921, 3922, 1915, 21, 1477, 18, 225, 1916, 996, 1180, 2552, 13, 70, 204, 187, 1174, 3923, 224, 996, 3924, 3925, 18, 50, 3926, 636, 2553, 1916, 1917, 1916, 332, 832, 575, 1478, 1180, 70, 47, 3927, 2554, 996, 3928, 21, 428, 576, 833, 104, 13, 834, 577, 1, 996, 56, 105, 1918, 1479, 6, 517, 1919, 170, 578, 49459, 38641, 41922, 30944, 41706, 36556, 39490, 44343, 34548, 48176, 44296, 34472, 46676, 27191, 35134, 32986, 38208, 30008, 51474, 29641, 39285, 27355, 47419, 37896, 43711, 46192, 51404, 32179, 29772, 28273, 37191, 48214, 28632, 46512, 49861, 38251, 43019, 35193, 28504, 34983, 33193, 32488, 36258, 36770, 45540, 49370, 32990, 32942, 27044, 51427, 33278, 28763, 47041, 35280, 28053, 46014, 46329, 39545, 49056])
list([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1480, 2555, 2556, 835, 720, 3929, 1181, 3930, 3931, 1919, 30354, 28449, 35898, 31242, 28698, 39007, 46671, 43063, 29750, 28773])]
maxlen = 119
将向量进行最长补齐---->x_train = [[ 2548 3921 3922 ... 46329 39545 49056]
[ 0 0 0 ... 43063 29750 28773]
[ 0 0 0 ... 41483 45159 47931]
...
[ 0 0 0 ... 32232 43068 31449]
[ 0 0 0 ... 39657 46993 51850]
[ 0 0 0 ... 30709 44030 43943]]
将向量进行最长补齐---->x_train.shape = (1302, 119)
参考资料:
NLP基础:n-gram语言模型和神经网络语言模型
N-gram模型和神经语言模型
理解n-gram及神经网络语言模型

















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









