



 本文介绍了差分信号的基本概念,以及在FPGA中如何使用IP核clockingwizard将差分时钟转换为单端时钟并进行分频操作。通过选择MMCM并设置输入输出时钟频率,可以实现差分到单端的转换,并对时钟进行频率调整。此外,还提到了使用原语IBUFDS进行转换但不涉及分频的情况。
本文介绍了差分信号的基本概念,以及在FPGA中如何使用IP核clockingwizard将差分时钟转换为单端时钟并进行分频操作。通过选择MMCM并设置输入输出时钟频率,可以实现差分到单端的转换,并对时钟进行频率调整。此外,还提到了使用原语IBUFDS进行转换但不涉及分频的情况。
今天第一次玩公司的高级板子,确实高级板子比较复杂,一个差分时钟就把我搞的糊里糊涂的,回家查了资料后,进行了如下总结。
1. 差分信号概念
差分传输是一种信号传输的技术,区别于传统的一根信号线一根地线的做法,差分传输在这两根线上都传输信号,这两个信号的幅度相同,相位相反。在这两根线 上传输的信号就是差分信号。
简而言之,差分信号是两个信号,他们幅度相同、相位相反。
2. FPGA差分时钟转换为单端时钟
2.1 IP核(clocking wizard)
在vivado中使用clocking wizard IP核
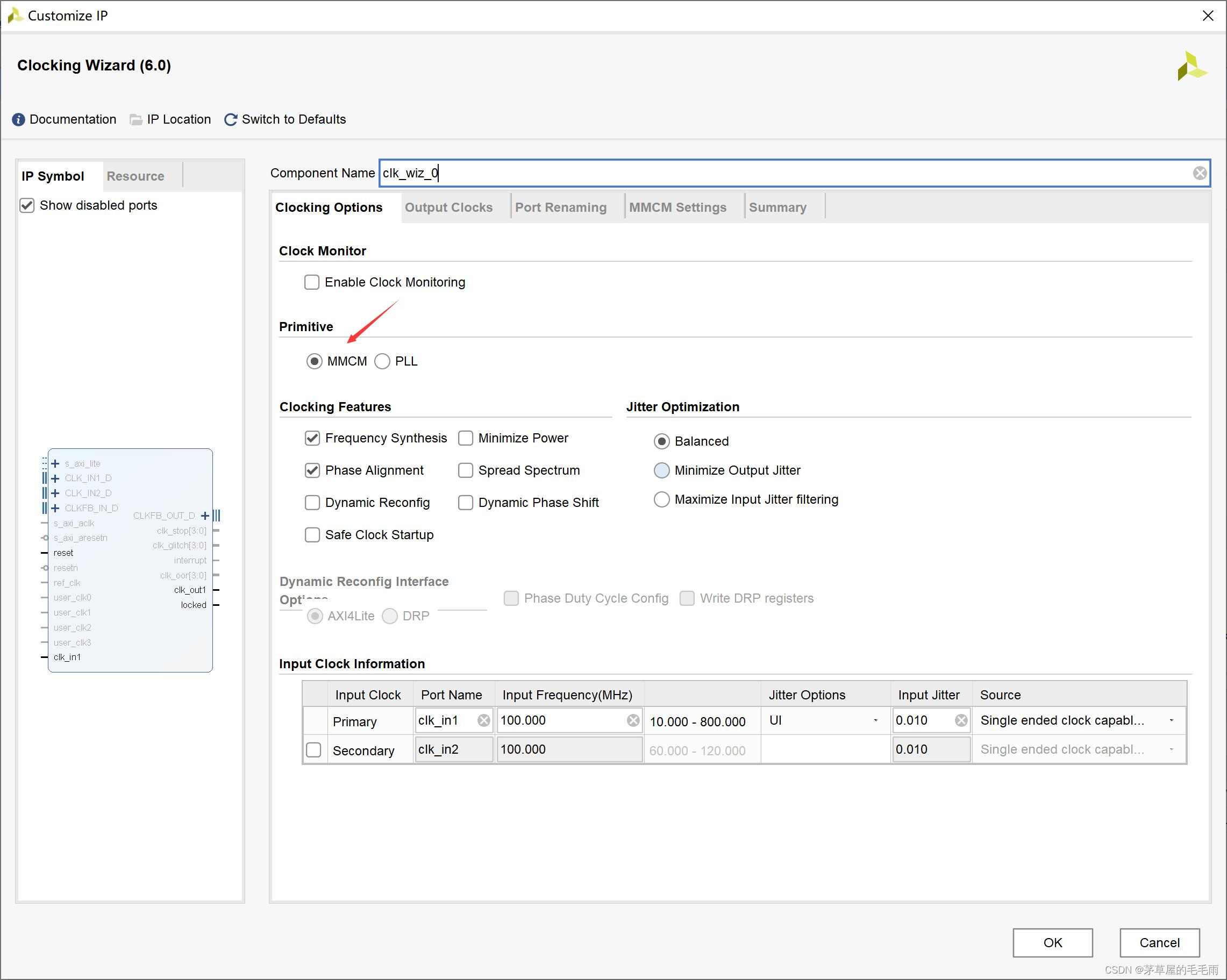
选择MMCM(Mixed-Mode Clock Manager)
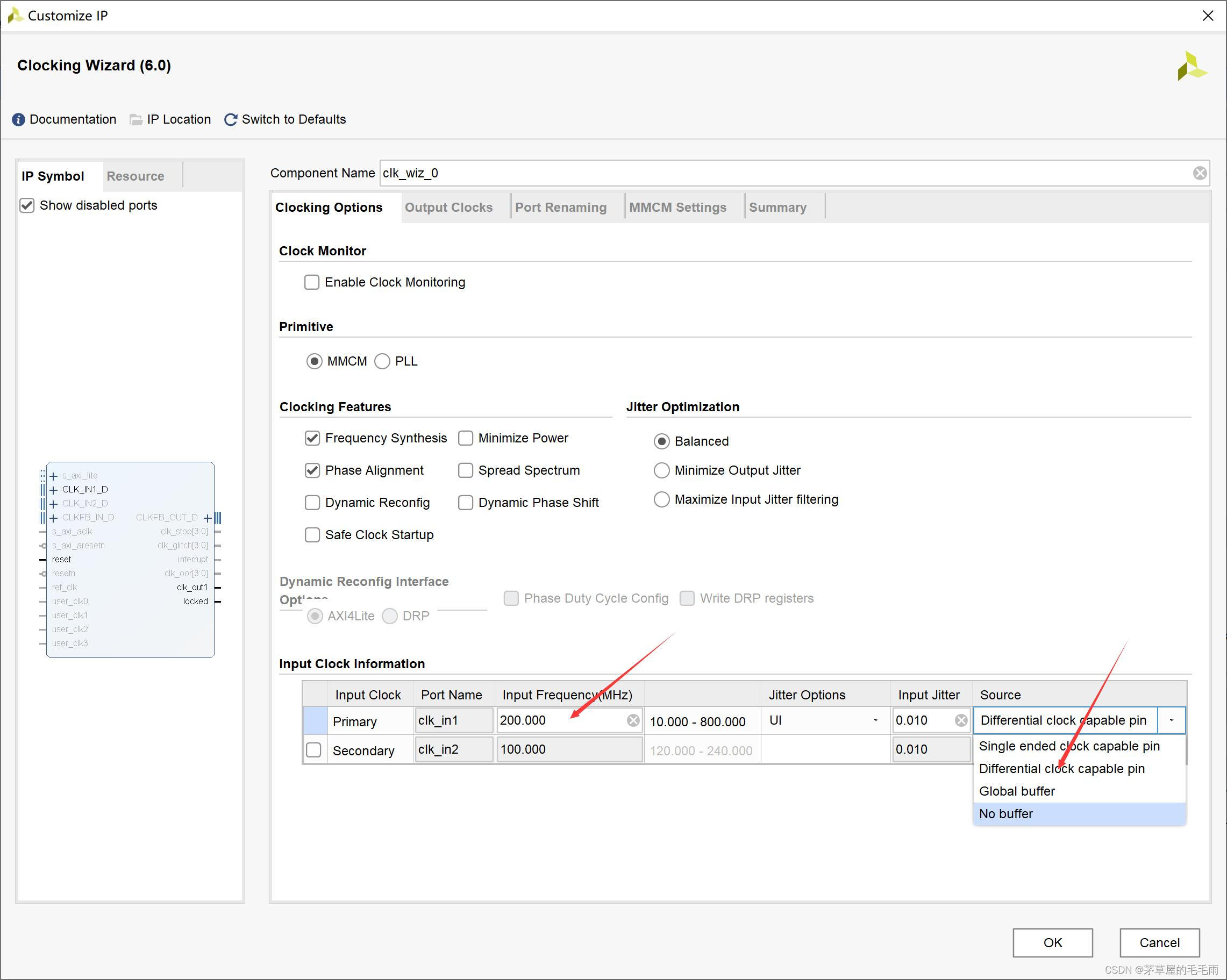
设置输入时钟的频率(所用开发板时钟频率为200MHz);因为输入为差分时钟,故source中选择Differential clock capable pin(差分时钟引脚);
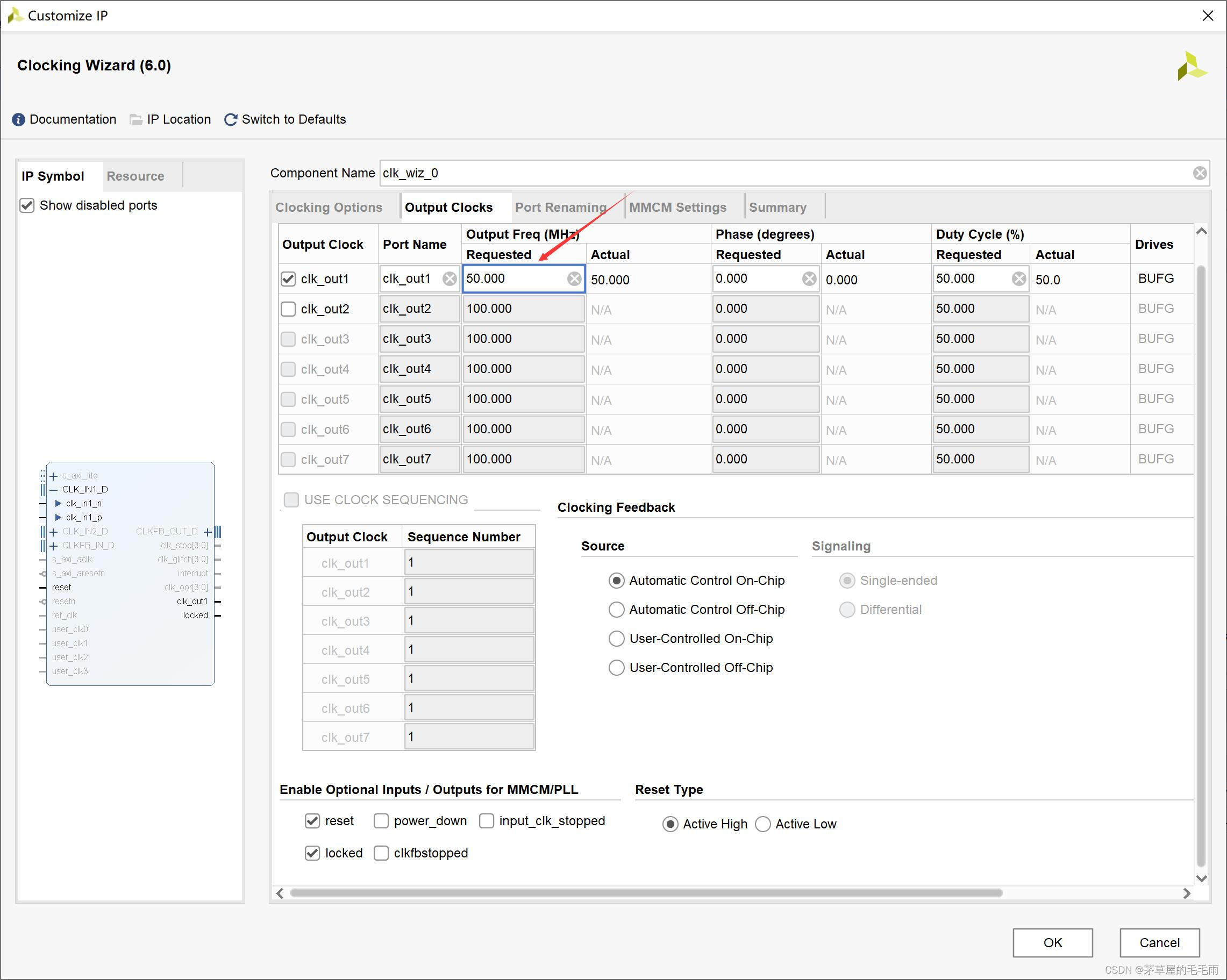
设置输出时钟的频率(50MHz),其他端口根据自己需求设置
生成IP后可以找到他的例化模板

以上操作实现了差分时钟转换为单端时钟,并进行了分频操作。
2.2 Language Templates(原语)
要单纯的实现差分时钟转单端时钟,使用IBUGDS可以轻松搞定,但此时的单端时钟频率与差分时钟频率相同,要想对时钟进行分频,还需使用MMCM进行分频,此时的source不再选择Differential clock capable pin,应选择Single ended capable pin(单端引脚)。


















 1382
1382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









