






适用平台:Matlab 2020及以上
GAN(Generative Adversarial Network)是一种生成模型,其工作原理可以用以下简单的方式来解释:
生成器(Generator):生成器是一个网络,其任务是接受一个随机噪声信号(通常是随机向量)作为输入,然后尝试生成与训练数据相似的新数据样本,如图像、文本或音频等。生成器的目标是生成高质量的伪造数据。
判别器(Discriminator):判别器也是一个网络,它的任务是接受来自生成器和真实数据的样本,然后尝试区分哪些是真实数据,哪些是生成器生成的伪造数据。判别器的目标是尽可能准确地分类数据样本。
对抗训练:GAN的核心思想是生成器和判别器之间进行对抗训练。在每个训练迭代中,生成器尝试生成更逼真的数据以欺骗判别器,而判别器努力提高自己的能力以正确区分真实数据和伪造数据。
平衡过程:随着训练的进行,生成器和判别器之间的竞争会导致一个平衡过程。生成器逐渐改进其生成能力,而判别器逐渐变得更擅长识别伪造数据。最终,生成器希望生成的数据足够逼真,以至于判别器无法轻松区分真伪。
生成高质量数据:一旦训练完成,生成器可以用来生成高质量的伪造数据,这些数据在某种程度上类似于真实数据。这对于许多应用,如图像生成、风格转换、自然语言处理等非常有用。
总结来说,传统GAN是一个生成和判别的博弈过程,通过这种对抗性训练,生成器逐渐提高生成质量,判别器提高辨别能力,最终实现生成高质量的伪造数据。这个模型的灵感来源于博弈论,其中两个对手(生成器和判别器)相互竞争,驱动整个系统向更好的状态演进。
Wasserstein GAN(Wasserstein Generative Adversarial Network,WGAN)是一种生成对抗网络(GAN)的改进模型,旨在解决传统GAN模型中存在的梯度消失、训练不稳定以及模式崩溃等问题。WGAN引入了Wasserstein距离(也称为Earth Mover's Distance,EMD)作为GAN的优化目标,以更稳定和可解释的方式进行训练生成器和判别器。
以下是Wasserstein GAN的一些关键特点和工作原理:
Wasserstein距离:传统GAN使用的JS(Jensen-Shannon)散度或KL(Kullback-Leibler)散度作为损失函数,但这些损失函数存在问题,导致训练不稳定。WGAN引入Wasserstein距离,它被认为更好地度量了两个分布之间的差异,尤其对于高维数据更加有效。Wasserstein距离计算了将一个分布转化成另一个分布的最小代价,通常被称为“运输”成本。
梯度稳定性:WGAN通过使用Wasserstein距离作为损失函数显著提高了梯度稳定性。这意味着在训练过程中,生成器和判别器之间的梯度不会突然消失或爆炸,从而更容易收敛到稳定的解。
Lipschitz连续性:为了确保判别器是Lipschitz连续的(一种数学性质,对Wasserstein距离的计算至关重要),WGAN对判别器的权重进行了剪裁或权重约束,以确保梯度不会变得不稳定。这一步骤被称为权重剪裁。
生成器和判别器平衡:WGAN的训练过程更容易实现生成器和判别器的平衡。这意味着生成器和判别器之间的性能差异不会太大,生成器更容易生成高质量的样本。
生成高质量样本:由于WGAN的稳定性和平衡性,生成器更容易生成高质量的数据样本,这对于图像生成、数据生成等任务非常有用。
综上Wasserstein GAN通过引入Wasserstein距离和一系列改进方法,解决了传统GAN模型中的一些问题,使生成对抗网络更容易训练,生成更高质量的数据。这使得WGAN成为生成模型领域的一项重要进展。
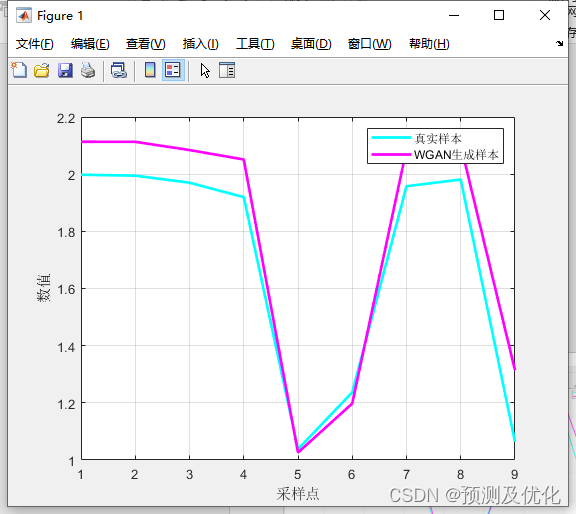
对抗生成样本对比:
部分代码:
%% 训练
iterationG = 0;
iterationD = 0;
start = tic;
%% 循环处理像批量数据
while iterationG < numIterationsG
% 生成器迭代次数 + 1
iterationG = iterationG + 1;
% 训练判别器
for n = 1 : numIterationsDPerG
iterationD = iterationD + 1;
%重置并打乱数据
temp = randperm(size(augimds, 4));
data = augimds(:, : , :, temp);
% 读取批次数据
X = single(data);
% 数据类型转换
[X, ps_output] = mapminmax(X, -1, 1);
dlX = dlarray(X, 'SSCB');
% 生成生成器输入样本,并转换格式
Z = randn([numLatentInputs, size(dlX, 4)], 'like', dlX);
dlZ = dlarray(Z, 'CB');
% 得到判别器损失和梯度
[gradientsD, lossD, lossDUnregularized] = dlfeval(@modelGradientsD, dlnetD, dlnetG, dlX, dlZ, lambda);
% 更新判别器参数
[dlnetD, trailingAvgD, trailingAvgSqD] = adamupdate(dlnetD, gradientsD, ...
trailingAvgD, trailingAvgSqD, iterationD, ...
learnRateD, gradientDecayFactor, squaredGradientDecayFactor);
end
% 得到生成器输入样本,并转换格式.
Z = randn([numLatentInputs, size(dlX, 4)], 'like', dlX);
dlZ = dlarray(Z, 'CB');
% 得到生成器梯度
gradientsG = dlfeval(@modelGradientsG, dlnetG, dlnetD, dlZ);
% 更新判别器参数
[dlnetG, trailingAvgG, trailingAvgSqG] = adamupdate(dlnetG, gradientsG, ...
trailingAvgG, trailingAvgSqG, iterationG, ...
learnRateG, gradientDecayFactor, squaredGradientDecayFactor);
%% 更新显示曲线
subplot(1, 1, 1)
% 得到判别器损失函数和未经梯度惩罚的损失函数
lossD = double(gather(extractdata(lossD)));
lossDUnregularized = double(gather(extractdata(lossDUnregularized)));
% 更新曲线
addpoints(lineLossD, iterationG, lossD);
addpoints(lineLossDUnregularized, iterationG, lossDUnregularized);
% 更新标题
D = duration(0, 0, toc(start), 'Format', 'hh:mm:ss');
title( ...
"Iteration: " + iterationG + ", " + ...
"Elapsed: " + string(D))
drawnow
end
%% 生成生成器输入数据
ZNew = randn(numLatentInputs, M, 'single');
dlZNew = dlarray(ZNew, 'CB');
%% 判断是否存在GPU
if (executionEnvironment == "auto" && canUseGPU) || executionEnvironment == "gpu"
dlZNew = gpuArray(dlZNew);
end
%% 生成图片
dlXGeneratedNew = predict(dlnetG, dlZNew);
for i = 1 : M
final_data(1, 1:9, 1, i) = extractdata(dlXGeneratedNew(:, :, :, i));
end
T_sim = mapminmax('reverse', final_data, ps_output);
save ps_output.mat ps_output
for i = 1 : M
final_data_save(i, :) = T_sim(:, :, :, i);
end
%% 保存模型
save dlnetG.mat dlnetG
save dlnetD.mat dlnetD完整代码:
https://mbd.pub/o/bread/ZZaVlp5v欢迎感兴趣的小伙伴关注并获取完整版代码哦~,小编会继续推送更有质量的学习资料、文章程序代码~

















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









