





对于RandLA来说,它设计的LFA模块,解决了点云局部特征提取的问题,但是它只是学习了一个十维的位置特征向量,并将其和原始进行拼接,这种方法虽然学习到了邻域的局部特征,但是学习到的特征没经过细致的学习(例如通道间的不同、特征间的差异等等),直接利用自注意力池聚合了特征,所以导致分割的效果没有如今的高(其实已经很高了)。LFT-Net采取的思想和大部分点云分割思想一致,它和之前我讲述的一篇叫DLA-Net的很像,都是利用的Transformer的结构去学习,但是那篇文章利用的是特征之间的减法然后拼接学习的位置编码特征去进行softmax得到的权重参数,这篇LFT-Net是学习三个不同的特征然后进行矩阵的乘法得到的权重参数,而且它的聚合模块没采用大部分网络使用的自注意力池,它使用的是模仿的自注意力池,与它的自注意力学习类似,利用学习到的特征进行矩阵乘法进行聚合特征,它的损失函数模块后续说明。

上图是它的LFT模块,前半部分就是学习邻域位置特征(4维向量),结合原始特征,完成一个特征的拼接,然后利用三个MLP(α、β、γ)去学习三组不同的特征,分别进行矩阵乘法,这里我理解的是矩阵乘法,但是它解释的是dot product(点乘),不然它上面的图没办法出来,因为一个(K,dout)和(dout,K)只能矩阵乘法吧,这点欢迎大家来讨论,然后利用softmax组成权重参数,与上述得到的特征进行Add,它在后续采用了一个小型扩展残差模块,防止丢失一些特征。
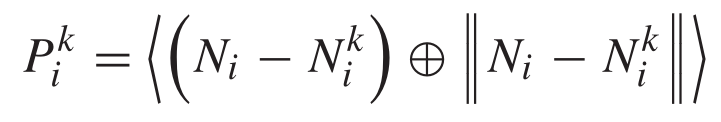


上图是它的TP模块(特征聚合),正如我前文所说的一样,它是与自注意力模块类似,利用η和θ两个共享ML学习特征去乘之前的特征,然后利用求和将特征聚合起来,这点很多算法都不采用max pooling(对称函数)的做法,因为那种方法会丢失很多关键信息,虽然方法简单。
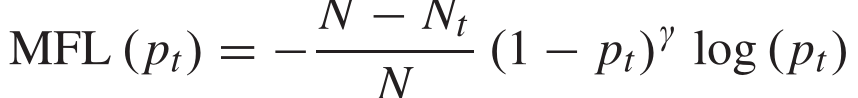
它使用的损失函数是将原有的交叉熵损失进行重塑,目的是为了解决那些样本比较少的类别点云,来平衡数据,因为样本类别数目不一致,导致一些边缘信息提取的不好,上述中的Nt代表的是t类点云的个数,pt代表的为精度,pt越大,损失越小,这样可以让损失大的类别占大部分损失,占主导地位。

LFT-Net的网络结构与RandLA以及其他的网络都类似,都是4层编码层+4层解码层的结构,但是LFT-Net网络使用的是FPS采样,这种方法采样时间比较长,但是从效果来看它的结果是不错的,不知道换成RS采样之后会不会有更好的效果。并且它结合了上下文的信息,分类网络在提取完特征(下采样)之后就利用全局平均池化加上2个全连接层连接特征,分割的话需要利用插值的方法进行上采样还原特征,它的下采样阶段就是搜索邻域,聚合局部特征,自注意力学习特征,然后聚合特征。
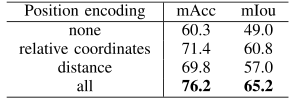
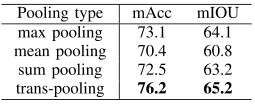
从消融实验上看,编码邻域信息特征时考虑全面效果比较好,这里感觉可以参考RandLA的十维向量特征,可以做一下,聚合特征时,采用注意力的方法明显要好于对称函数的方法,具体的可以看论文。
就是对于邻域特征学习模块那个到底是点乘还是矩阵乘法我有些疑问,如果有知道的小伙伴可以评论区告诉我下。
【计算机视觉】简述对LFT-Net(大场景点云分割)的理解

于 2022-04-14 14:29:47 首次发布















 4123
4123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











